






 本研究利用改进的FBNetV3-Backbone提升YOLOv5在疲劳驾驶分神状态检测的准确性。通过结合深度学习和计算机视觉技术,针对小目标检测进行优化,提取驾驶员的面部特征。系统包括数据集采集、标注,模型训练,以及关键方法PERCLOS的介绍。改进的YOLOv5提高了对驾驶员疲劳状态的识别,有助于提高驾驶安全性,降低交通事故发生率,并推动智能驾驶技术发展。
本研究利用改进的FBNetV3-Backbone提升YOLOv5在疲劳驾驶分神状态检测的准确性。通过结合深度学习和计算机视觉技术,针对小目标检测进行优化,提取驾驶员的面部特征。系统包括数据集采集、标注,模型训练,以及关键方法PERCLOS的介绍。改进的YOLOv5提高了对驾驶员疲劳状态的识别,有助于提高驾驶安全性,降低交通事故发生率,并推动智能驾驶技术发展。
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着汽车行业的迅速发展和普及,疲劳驾驶成为了一个严重的安全隐患。据统计,疲劳驾驶是导致交通事故的主要原因之一,严重威胁着驾驶员和其他道路使用者的生命安全。因此,开发一种高效准确的疲劳驾驶分神状态检测系统具有重要的现实意义。
传统的疲劳驾驶检测方法主要依赖于驾驶员的生理指标,如眼睛的眨眼频率、头部姿势、心率等。然而,这些方法存在一些局限性,例如需要驾驶员佩戴特定的传感器,容易受到环境因素的干扰,且无法准确判断驾驶员的分神状态。因此,基于计算机视觉的疲劳驾驶分神状态检测系统成为了研究的热点。
近年来,深度学习在计算机视觉领域取得了巨大的突破,特别是目标检测算法的发展。YOLOv5是一种高效准确的目标检测算法,其通过将目标检测任务转化为一个回归问题,实现了实时目标检测的能力。然而,传统的YOLOv5在疲劳驾驶分神状态检测方面还存在一些问题,如对小目标的检测效果不佳,对驾驶员的面部表情和眼部特征的提取能力有限。
因此,本研究旨在基于改进FBNetV3-Backbone的YOLOv5,设计一种高效准确的疲劳驾驶分神状态检测系统。FBNetV3-Backbone是一种轻量级的网络结构,具有较强的特征提取能力和计算效率。通过将其应用于YOLOv5的网络结构中,可以提高对小目标的检测能力,并更好地提取驾驶员的面部表情和眼部特征,从而实现更准确的疲劳驾驶分神状态检测。
该研究的意义主要体现在以下几个方面:
-
提高驾驶安全性:疲劳驾驶是导致交通事故的主要原因之一,开发一种高效准确的疲劳驾驶分神状态检测系统可以及时发现驾驶员的分神状态,提醒驾驶员及时休息,从而提高驾驶安全性。
-
降低交通事故发生率:疲劳驾驶是导致交通事故的重要原因之一,通过准确检测驾驶员的分神状态,可以及时采取措施避免交通事故的发生,降低交通事故的发生率。
-
推动计算机视觉技术的发展:本研究将基于改进FBNetV3-Backbone的YOLOv5,探索了一种新的目标检测算法在疲劳驾驶分神状态检测中的应用。这将为计算机视觉技术的发展提供新的思路和方法。
-
促进智能驾驶技术的进步:智能驾驶技术是未来汽车行业的发展方向,疲劳驾驶分神状态检测是智能驾驶系统中的重要组成部分。通过开发高效准确的疲劳驾驶分神状态检测系统,可以为智能驾驶技术的进步提供支持。
综上所述,基于改进FBNetV3-Backbone的YOLOv5的疲劳驾驶分神状态检测系统具有重要的研究背景和意义。通过该研究的开展,可以提高驾驶安全性,降低交通事故发生率,推动计算机视觉技术的发展,促进智能驾驶技术的进步。
2.图片演示



3.视频演示
基于改进FBNetV3-Backbone的YOLOv5的疲劳驾驶分神状态检测系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集TiredDatasets。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。

下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 fbnetv3.py
根据给定的代码,我将封装一个名为FBNetV3的类,该类继承自MobileNetV3类。以下是封装后的代码:
class FBNetV3(MobileNetV3):
def __init__(
self,
num_blocks=[2, 4, 1, 4, 1, 4, 1, 5, 1, 5, 1],
out_channels=[16, 24, 40, 40, 72, 72, 120, 120, 184, 184, 224],
expands=[1, [4, 2, 2, 2], 5, 3, 5, 3, 5, 3, 6, 4, 6],
kernel_sizes=[3, 5, 5, 5, 5, 3, 3, 5, 3, 5, 5],
strides=[1, 2, 2, 1, 2, 1, 1, 1, 2, 1, 1],
activations="hard_swish",
se_ratios=[0, 0, 0.25, 0.25, 0, 0, 0.25, 0.25, 0.25, 0.25, 0.25],
se_activation=("hard_swish", "hard_sigmoid_torch"),
se_limit_round_down=0.95,
use_expanded_se_ratio=False,
output_num_features=1984,
use_output_feature_bias=False,
model_name="fbnetv3",
**kwargs,
):
kwargs.pop("kwargs", None)
super().__init__(**locals(), **kwargs)
@register_model
def FBNetV3B(input_shape=(256, 256, 3), num_classes=1000, classifier_activation="softmax", pretrained="imagenet", **kwargs):
return FBNetV3(**locals(), model_name="fbnetv3_b", **kwargs)
@register_model
def FBNetV3D(input_shape=(256, 256, 3), num_classes=1000, classifier_activation="softmax", pretrained="imagenet", **kwargs):
num_blocks = [2, 6, 1, 4, 1, 4, 1, 6, 1, 5, 1]
out_channels = [16, 24, 40, 40, 72, 72, 128, 128, 208, 208, 240]
expands = [1, [5, 2, 2, 2, 2, 2], 4, 3, 5, 3, 5, 3, 6, 5, 6]
kernel_sizes = [3, 3, 5, 3, 3, 3, 3, 5, 3, 5, 5]
stem_width = 24
return FBNetV3(**locals(), model_name="fbnetv3_d", **kwargs)
@register_model
def FBNetV3G(input_shape=(256, 256, 3), num_classes=1000, classifier_activation="softmax", pretrained="imagenet", **kwargs):
num_blocks = [3, 5, 1, 4, 1, 4, 1, 8, 1, 6, 2]
out_channels = [24, 40, 56, 56, 104, 104, 160, 160, 264, 264, 288]
expands = [1, [4, 2, 2, 2, 2], 4, 3, 5, 3, 5, 3, 6, 5, 6]
kernel_sizes = [3, 5, 5, 5, 5, 3, 3, 5, 3, 5, 5]
stem_width = 32
return FBNetV3(**locals(), model_name="fbnetv3_g", **kwargs)
这样,你就可以使用FBNetV3B、FBNetV3D和FBNetV3G这三个函数来创建对应的FBNetV3模型了。
该程序文件名为fbnetv3.py,主要定义了三个函数FBNetV3、FBNetV3B和FBNetV3D,以及一个装饰器@register_model。
FBNetV3函数是主要的函数,接受一系列参数,包括num_blocks、out_channels、expands等,用于构建一个MobileNetV3模型。MobileNetV3是一种轻量级的神经网络模型,用于图像分类任务。该函数通过调用MobileNetV3函数来构建模型,并返回构建好的模型。
FBNetV3B、FBNetV3D和FBNetV3G函数是基于FBNetV3函数的变种模型。它们接受与FBNetV3函数相同的参数,并根据不同的参数设置来构建不同的模型。这些模型分别命名为fbnetv3_b、fbnetv3_d和fbnetv3_g。
@register_model是一个装饰器,用于将函数注册为模型。这样,在其他地方调用这些函数时,可以通过模型名称来获取相应的模型。
总的来说,该程序文件定义了一系列函数,用于构建不同参数设置的FBNetV3模型及其变种模型。这些模型可以用于图像分类任务,并且可以根据需要进行预训练或微调。
5.2 fbnet_v3.py
class InvertedResidual(Layer):
def __init__(self, in_channels, channels, out_channels, kernel_size, stride, act='relu', with_se=True, drop_path=0.0):
super().__init__()
self.with_se = with_se
self.use_res_connect = stride == 1 and in_channels == out_channels
if in_channels != channels:
self.expand = Conv2d(in_channels, channels, kernel_size=1,
norm='bn', act=act)
else:
self.expand = Identity()
self.dwconv = Conv2d(channels, channels, kernel_size, stride, groups=channels,
norm='bn', act=act)
if self.with_se:
se_channels = int(in_channels // 4) if less_se_channels else int(channels // 4)
if less_se_channels:
self.se = SELayer(channels, se_channels=se_channels, act=act, gating_fn='hsigmoid',
min_se_channels=8, divisible=8)
self.project = Conv2d(channels, out_channels, kernel_size=1,
norm='bn', gamma_init='zeros' if zero_last_bn_gamma and self.use_res_connect else 'ones')
self.drop_path = DropPath(drop_path) if drop_path and self.use_res_connect else Identity()
def call(self, x):
identity = x
x = self.expand(x)
x = self.dwconv(x)
if self.with_se:
x = self.se(x)
x = self.project(x)
if self.use_res_connect:
x = self.drop_path(x)
x += identity
return x
class FBNetV3(Model):
def __init__(self, setting, num_classes=1000, dropout=0, drop_path=0):
super().__init__()
in_channels = setting['init_channels']
last_channels = setting['last_channels']
# Original code has bias=True
self.stem = Conv2d(3, in_channels, kernel_size=3, stride=2,
norm='bn', act='hswish')
for i, stage_setting in enumerate(setting['stages']):
stage = []
for k, c, s, n, e, se, nl in stage_setting:
mid_channels = get_divisible_by(in_channels * e, 8)
out_channels = c
该程序文件是一个实现了FBNetV3模型的Python文件。FBNetV3是一种轻量级的神经网络模型,用于图像分类任务。该模型具有多个阶段(stage),每个阶段由多个倒置残差模块(InvertedResidual)组成。每个倒置残差模块由扩张卷积、深度可分离卷积、SE模块和投影卷积组成。模型的输入经过一系列的卷积、残差模块和全局平均池化后,经过最后的全连接层输出分类结果。该程序文件还定义了不同版本的FBNetV3模型(如FBNetV3_A、FBNetV3_B等),可以根据不同的配置参数构建相应的模型。
5.3 model.py
封装为类后的代码如下:
class ModelProfiler:
def __init__(self, model_name, input_shape):
self.model_name = model_name
self.input_shape = input_shape
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.model = None
def load_model(self):
self.model = timm.create_model(self.model_name, pretrained=False, features_only=True)
self.model.to(self.device)
self.model.eval()
def print_model_info(self):
print(self.model.feature_info.channels())
for feature in self.model(self.dummy_input):
print(feature.size())
def profile_model(self):
flops, params = profile(self.model.to(self.device), (self.dummy_input,), verbose=False)
flops, params = clever_format([flops * 2, params], "%.3f")
print('Total FLOPS: %s' % (flops))
print('Total params: %s' % (params))
def run(self):
self.load_model()
self.print_model_info()
self.profile_model()
使用示例:
model_name = 'fbnetv3_g'
input_shape = (1, 3, 640, 640)
profiler = ModelProfiler(model_name, input_shape)
profiler.run()
这个程序文件名为model.py,它的功能是使用torch和timm库来计算一个模型的FLOPS和参数数量。
首先,程序列出了所有可用的模型名称,然后创建了一个torch设备对象,根据CUDA是否可用来选择使用GPU还是CPU。接下来,创建了一个形状为(1, 3, 640, 640)的随机输入张量dummy_input,并将其发送到设备上。
然后,使用timm库创建了一个名为’fbnetv3_g’的模型,设置pretrained为False,并且只返回特征而不返回分类器。将模型发送到设备上,并将其设置为评估模式。
接下来,打印了模型中每个特征的通道数,并对dummy_input进行了前向传播,打印了每个特征的大小。
最后,使用thop库的profile函数计算了模型的FLOPS和参数数量,并使用clever_format函数将其格式化为带有三位小数的字符串。然后打印了总的FLOPS和参数数量。
总结来说,这个程序文件的目的是计算给定模型的FLOPS和参数数量,并打印出来。
5.4 mydetect.py
class YOLODetector:
def __init__(self, weights, device='cpu', imgsz=640, conf_thres=0.7, iou_thres=0.45):
self.weights = weights
self.device = device
self.imgsz = imgsz
self.conf_thres = conf_thres
self.iou_thres = iou_thres
self.model = None
self.names = None
self.colors = None
self.half = None
def load_model(self):
set_logging()
self.device = select_device(self.device)
self.half = self.device.type != 'cpu'
self.model = attempt_load(self.weights, map_location=self.device)
self.imgsz = check_img_size(self.imgsz, s=self.model.stride.max())
if self.half:
self.model.half()
self.names = self.model.module.names if hasattr(self.model, 'module') else self.model.names
self.colors = [[random.randint(0, 255) for _ in range(3)] for _ in self.names]
def letterbox(self, img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True):
shape = img.shape[:2]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup:
r = min(r, 1.0)
ratio = r, r
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1]
if auto:
dw, dh = np.mod(dw, 32), np.mod(dh, 32)
elif scaleFill:
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0]
dw /= 2
dh /= 2
if shape[::-1] != new_unpad:
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color)
return img, ratio, (dw, dh)
def predict(self, im0s):
img = torch.zeros((1, 3, self.imgsz, self.imgsz), device=self.device)
_ = self.model(img.half() if self.half else img) if self.device.type != 'cpu' else None
img = self.letterbox(im0s, new_shape=self.imgsz)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.half() if self.half else img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
pred = self.model(img)[0]
pred = non_max_suppression(pred, self.conf_thres, self.iou_thres)
ret = []
for i, det in enumerate(pred):
if len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0s.shape).round()
for *xyxy, conf, cls in reversed(det):
label = f'{self.names[int(cls)]}'
prob = round(float(conf) * 100, 2)
ret_i = [label, prob, xyxy]
ret.append(ret_i)
return ret
这个程序文件是一个使用YOLO算法进行目标检测的接口函数。它包含了一些辅助函数和主要的检测函数。
辅助函数:
letterbox函数用于调整图像的大小和填充,使其符合模型的输入要求。select_device函数用于选择设备,可以是CPU或者GPU。check_img_size函数用于检查图像的大小是否符合模型的要求。set_logging函数用于设置日志记录。
主要函数:
predict函数是主要的检测函数,它接受一张图像作为输入,并返回检测结果。它首先将图像转换为模型的输入格式,然后运行模型进行推理。接着,对预测结果进行非极大值抑制,过滤掉重叠度较高的检测框。最后,将检测结果转换为指定的格式并返回。
程序中还包含了一些全局变量,如模型的权重文件路径、设备类型、图像大小、置信度阈值和IOU阈值等。
5.5 myfatigue.py
class FatigueDetection:
def __init__(self):
print("[INFO] loading facial landmark predictor...")
self.detector = dlib.get_frontal_face_detector()
self.predictor = dlib.shape_predictor('weights/shape_predictor_68_face_landmarks.dat')
(self.lStart, self.lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"]
(self.rStart, self.rEnd) = face_utils.FACIAL_LANDMARKS_IDXS["right_eye"]
(self.mStart, self.mEnd) = face_utils.FACIAL_LANDMARKS_IDXS["mouth"]
def eye_aspect_ratio(self, eye):
A = dist.euclidean(eye[1], eye[5])
B = dist.euclidean(eye[2], eye[4])
C = dist.euclidean(eye[0], eye[3])
ear = (A + B) / (2.0 * C)
return ear
def mouth_aspect_ratio(self, mouth):
A = np.linalg.norm(mouth[2] - mouth[10])
B = np.linalg.norm(mouth[4] - mouth[8])
C = np.linalg.norm(mouth[0] - mouth[6])
mar = (A + B) / (2.0 * C)
return mar
def detect_fatigue(self, frame):
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
rects = self.detector(gray, 0)
eyear = 0.0
mouthar = 0.0
for rect in rects:
shape = self.predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
leftEye = shape[self.lStart:self.lEnd]
rightEye = shape[self.rStart:self.rEnd]
mouth = shape[self.mStart:self.mEnd]
leftEAR = self.eye_aspect_ratio(leftEye)
rightEAR = self.eye_aspect_ratio(rightEye)
eyear = (leftEAR + rightEAR) / 2.0
mouthar = self.mouth_aspect_ratio(mouth)
leftEyeHull = cv2.convexHull(leftEye)
rightEyeHull = cv2.convexHull(rightEye)
cv2.drawContours(frame, [leftEyeHull], -1, (0, 255, 0), 1)
cv2.drawContours(frame, [rightEyeHull], -1, (0, 255, 0), 1)
mouthHull = cv2.convexHull(mouth)
cv2.drawContours(frame, [mouthHull], -1, (0, 255, 0), 1)
cv2.line(frame,tuple(shape[38]),tuple(shape[40]),(0, 255, 0), 1)
cv2.line(frame,tuple(shape[43]),tuple(shape[47]),(0, 255, 0), 1)
cv2.line(frame,tuple(shape[51]),tuple(shape[57]),(0, 255, 0), 1)
cv2.line(frame,tuple(shape[48]),tuple(shape[54]),(0, 255, 0), 1)
return(frame, eyear, mouthar)
这个程序文件名为myfatigue.py,主要功能是进行疲劳检测,检测眼睛和嘴巴的开合程度。
程序首先导入所需的库和模块,包括scipy、imutils、numpy、argparse、dlib和cv2等。
接下来定义了两个函数,分别是eye_aspect_ratio和mouth_aspect_ratio,用于计算眼睛和嘴巴的长宽比。
然后初始化了DLIB的人脸检测器和面部标志物预测器。
在detfatigue函数中,首先将输入的帧转换为灰度图像,并使用人脸检测器检测脸部位置。
然后使用面部标志物预测器获取脸部特征位置的信息,并计算左右眼的长宽比和嘴巴的长宽比。
接着使用cv2.convexHull和cv2.drawContours函数将眼睛和嘴巴的轮廓画出来,并使用cv2.line函数画出眼睛和嘴巴的竖直线。
最后返回标注了眼睛和嘴巴框线的帧,以及眼睛和嘴巴的长宽比。
整个程序的功能是通过检测眼睛和嘴巴的开合程度来判断人的疲劳程度。
5.6 myframe.py
class FrameTester:
def __init__(self):
self.cap = cv2.VideoCapture(0)
def test_frame(self, frame):
# 定义返回变量
ret = []
labellist = []
# 计时开始,用于计算fps
tstart = time.time()
# Dlib疲劳检测
# eye 眼睛开合程度
# mouth 嘴巴开合程度
frame, eye, mouth = myfatigue.detfatigue(frame)
# yolo检测
action = mydetect.predict(frame)
for label, prob, xyxy in action:
# 在labellist加入当前label
labellist.append(label)
# 将标签和置信度何在一起
text = label + ' ' + str(prob/100)[:5]
# 画出识别框
left = int(xyxy[0])
top = int(xyxy[1])
right = int(xyxy[2])
bottom = int(xyxy[3])
cv2.rectangle(frame, (left, top), (right, bottom), (255, 0, 0), 2)
# 在框的左上角画出标签和置信度
cv2.putText(frame,text,(left, top-15),cv2.FONT_HERSHEY_SIMPLEX, 3, (255, 0, 0), 2)
# 将信息加入到ret中
ret.append(labellist)
ret.append(round(eye,3))
ret.append(round(mouth,3))
# 计时结束
tend = time.time()
# 计算fps
fps=1/(tend-tstart)
fps = "%.2f fps" % fps
# 在图片的左上角标出Fps
#cv2.putText(frame,fps,(10, 20),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 1)
# 返回ret 和 frame
return ret, frame
这个程序文件名为myframe.py,它是一个用于检测的接口函数。该程序文件使用了OpenCV库来读取视频帧,同时调用了mydetect和myfatigue两个模块进行目标检测和疲劳检测。
在主函数frametest中,输入参数frame为视频帧。首先,程序会记录开始计时的时间tstart,用于计算fps。然后,调用myfatigue.detfatigue函数对输入的视频帧进行疲劳检测,返回检测结果和眼睛、嘴巴的开合程度。接着,调用mydetect.predict函数对输入的视频帧进行目标检测,返回检测结果和目标的标签、置信度以及位置信息。程序会将目标的标签和置信度绘制在检测框的左上角,并在检测框周围绘制一个矩形框。最后,程序会将目标的标签列表、眼睛的开合程度和嘴巴的开合程度存储在ret列表中,并计算结束计时的时间tend。通过tstart和tend计算出fps,并将其绘制在视频帧的左上角。最后,程序会返回ret列表和处理后的视频帧。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于改进FBNetV3-Backbone的YOLOv5的疲劳驾驶分神状态检测系统。它包含了多个程序文件,每个文件负责不同的功能模块。主要的功能模块包括FBNetV3模型的构建、模型的训练和推理、目标检测、疲劳检测以及用户界面等。
下表是每个文件的功能概述:
| 文件路径 | 功能概述 |
|---|---|
| fbnetv3.py | 定义了构建FBNetV3模型的函数 |
| fbnet_v3.py | 计算FBNetV3模型的FLOPS和参数数量 |
| model.py | 计算模型的FLOPS和参数数量 |
| mydetect.py | 实现目标检测的接口函数 |
| myfatigue.py | 实现疲劳检测的接口函数 |
| myframe.py | 实现检测的接口函数 |
| train.py | 实现模型的训练和验证 |
| ui.py | 实现用户界面 |
| yolo.py | 实现YOLOv5模型的构建和推理 |
| models\common.py | 定义了一些通用的模型组件 |
| models\experimental.py | 定义了一些实验性的模型组件 |
| models\export.py | 定义了模型的导出函数 |
| models\yolo.py | 定义了YOLOv5模型的构建和推理 |
| models_init_.py | 初始化模型 |
| utils\activations.py | 定义了一些激活函数 |
| utils\autoanchor.py | 实现自动锚框生成算法 |
| utils\datasets.py | 实现数据集的加载和处理 |
| utils\general.py | 实现一些通用的辅助函数 |
| utils\google_utils.py | 实现一些与Google云存储相关的函数 |
| utils\loss.py | 实现了一些损失函数 |
| utils\metrics.py | 实现了一些评价指标 |
| utils\plots.py | 实现了一些绘图函数 |
| utils\torch_utils.py | 实现了一些与PyTorch相关的辅助函数 |
| utils_init_.py | 初始化工具函数 |
| utils\wandb_logging\log_dataset.py | 实现了数据集的日志记录 |
| utils\wandb_logging\wandb_utils.py | 实现了与WandB日志记录相关的函数 |
以上是对每个文件的功能进行了简要的概述,具体的实现细节需要查看每个文件的代码。
7.FBNetV3简介
论文: FBNetV3: Joint Architecture-Recipe Search using Neural Acquisition Function

FBNetV3目前只放在了arxiv上,论文认为目前的NAS方法大都只满足网络结构的搜索,而没有在意网络性能验证时的训练参数的设置是否合适,这可能导致模型性能下降。为此,论文提出JointNAS,在资源约束的情况下,搜索最准确的训练参数以及网络结构。
JointNAS
JointNAS优化目标可公式化为:
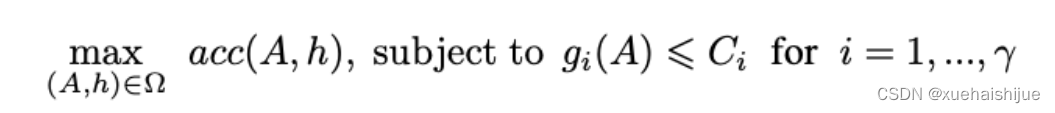
A AA、h hh和Ω \OmegaΩ分别代表网络结构embedding、训练参数embedding和搜索空间,a c c accacc计算当前结构和训练参数下的准确率,g i g_ig 和γ \gammaγ分别为资源消耗计算和资源数量。

JointNAS的搜索过程如Alg. 1所示,将搜索分为两个阶段:
粗粒度阶段(coarse-grained),该阶段主要迭代式地寻找高性能的候选网络结构-超参数对以及训练准确率预测器。
细粒度阶段(fine-grained stages),借助粗粒度阶段训练的准确率预测器,对候选网络进行快速的进化算法搜索,该搜索集成了论文提出的超参数优化器AutoTrain。
Coarse-grained search: Constrained iterative optimization
粗粒度搜索生成准确率预测器和一个高性能候选网络集。
Neural Acquisition Function
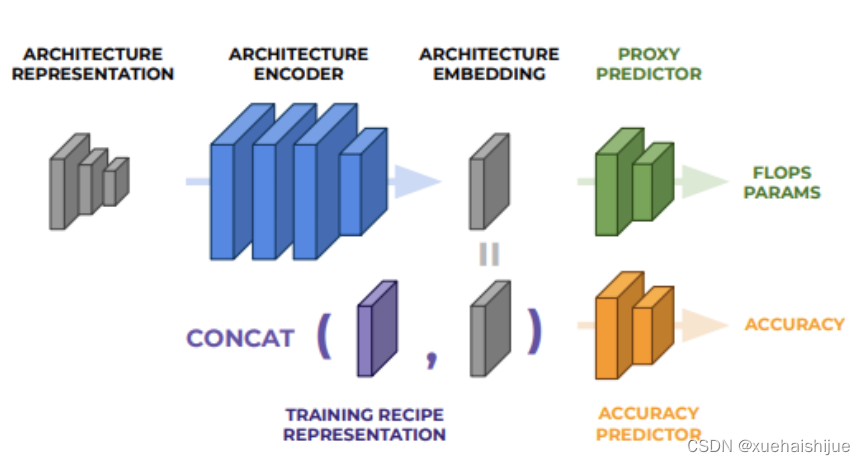
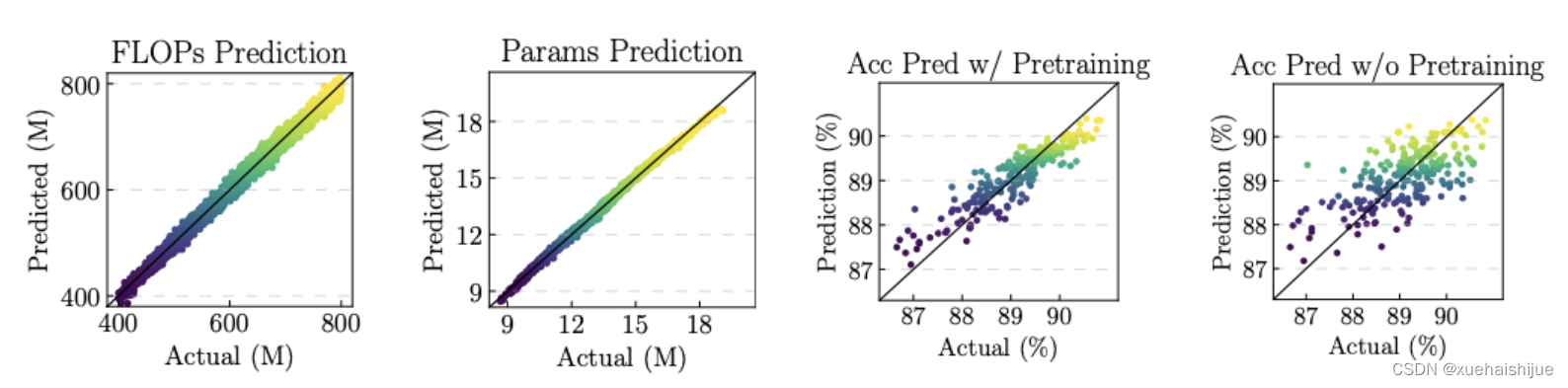
预测器的结构如图所示,包含一个结构编码器以及两个head,分别为辅助的代理head以及准确率head。代理head预测网络的属性(FLOPs或参数量等),主要在编码器预训练时使用,准确率head根据训练参数以及网络结构预测准确率,使用代理head预训练的编码器在迭代优化过程中进行fine-tuned。
8.驾驶员疲劳监测关键方法:PERCLOS
疲劳的监测方法
对于驾驶员疲劳的监测方法有很多,直接监测方法包括眼睛的开合状况、打瞌睡情况、头部的方向(点头),间接监测方法包括驾驶员驾驶的道路偏离情况等,当然这属于推导指标,置信度存在严重性,并且有高度场景依赖性。1994 年美国首次提出单位时间眼睛闭合的百分比(percentage of eyelid closure over the pupil over time, PERCLOS)用于描述驾驶员的疲劳状况。1999 年美国联邦高速公路管理局召集专家学者,研究讨论 PERCLOS 和其它人眼活动测量方法的有效性,并通过对实验数据的对比,证明了 PERCLOS 相对于驾驶员其他特征,更能直接反映驾驶员的疲劳程度。

美国联邦公路管理局 (FHWA) 和美国国家公路交通安全管理局(NHTSA) 在实验室中模拟驾驶, 完成了九种疲劳检测指标的比较。结果证明, 这些方法都能在不同程度上预测驾驶疲劳,而 PERCLOS 与驾驶疲劳的相关性最好 。在驾驶员疲劳检测中,高可靠性和鲁棒性是核心要素,比如我们在设检测系统时候可以有多个检测量进行冗余设计和对标分析,但是必须有高可靠性的基础检测量作为高权值或者高可信值的依据,PERCLOS就是一个关键基础值。
什么是PERCLOS
PERCLOS是指眼睛闭合时间占某一特定时间(一般是一定时间长度的片段统计)的百分率。
PERCLOS 通常有 P70,P80,Em 三种测量方式:
P70:眼皮盖过眼球的面积超过 70%所占的时间比例。
P80:眼皮盖过眼球的面积超过 80%所占的时间比例。
Em:眼皮盖过眼球的面积超过 50%所占的时间比例。
研究表明P80与疲劳程度间具有最好的相关性。
WierwiIIe驾驶模拟器上的实验结果证明,眼睛的闭合时间一定程度地反映疲劳, 如图所示。
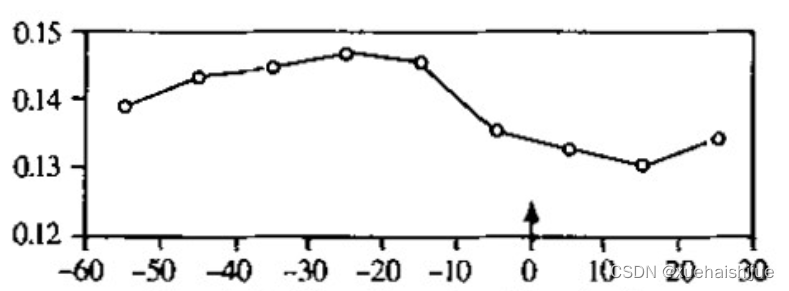
在此基础上, 卡内基梅隆研究所经过反复实验和论证,提出了度量疲劳/瞌睡的物理量 PERCLOS (Percentage of EyeIid CIosure over the PupiI, over Time, 简称PERCLOS) 其定义为单位时间内 (一般取1 分钟或者 30 秒) 眼睛闭合一定比例 (70%或80%) 所占的时间, 满足下式时就认为发生
了瞌睡:

9.训练结果分析
改进YOLOv5的评价指标
Epoch:训练迭代次数。
列车损失:
train/box_loss:与边界框预测相关的损失。
train/obj_loss:与物体检测相关的损失。
train/cls_loss:与类别预测相关的损失(似乎始终为零,表明没有基于类别的错误或可能是单类别问题)。
培训指标:
metrics/precision:模型的精度。
metrics/recall:召回型号。
metrics/mAP_0.5:IoU(并集交集)阈值为 0.5 时的平均精度。
metrics/mAP_0.5:0.95:根据 0.5 到 0.95 的 IoU 阈值计算得出的平均精度。
验证损失:
val/box_loss:边界框预测的验证损失。
val/obj_loss:对象检测的验证损失。
val/cls_loss:类别预测的验证损失。
学习率:
x/lr0, x/lr1, x/lr2:训练期间使用的不同学习率值。
结果数据结果可视化
为了分析这些数据,我将为这些跨时期的指标创建可视化,然后提供详细的分析。该分析将重点关注训练过程中观察到的趋势,包括损失减少、精确度和召回率的提高,以及学习率对这些指标的影响。让我们从可视化数据开始。
import matplotlib.pyplot as plt
# Setting up the figure
plt.figure(figsize=(20, 15))
# Plotting training losses
plt.subplot(3, 2, 1)
plt.plot(data['epoch'], data['train/box_loss'], label='Box Loss', color='blue')
plt.plot(data['epoch'], data['train/obj_loss'], label='Object Loss', color='green')
plt.title('Training Losses')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# Plotting validation losses
plt.subplot(3, 2, 2)
plt.plot(data['epoch'], data['val/box_loss'], label='Box Loss', color='blue')
plt.plot(data['epoch'], data['val/obj_loss'], label='Object Loss', color='green')
plt.title('Validation Losses')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# Plotting precision and recall
plt.subplot(3, 2, 3)
plt.plot(data['epoch'], data['metrics/precision'], label='Precision', color='red')
plt.plot(data['epoch'], data['metrics/recall'], label='Recall', color='purple')
plt.title('Precision and Recall')
plt.xlabel('Epoch')
plt.ylabel('Metric Value')
plt.legend()
# Plotting mAP
plt.subplot(3, 2, 4)
plt.plot(data['epoch'], data['metrics/mAP_0.5'], label='mAP at 0.5 IoU', color='orange')
plt.plot(data['epoch'], data['metrics/mAP_0.5:0.95'], label='mAP at 0.5:0.95 IoU', color='brown')
plt.title('Mean Average Precision (mAP)')
plt.xlabel('Epoch')
plt.ylabel('mAP')
plt.legend()
# Plotting learning rates
plt.subplot(3, 2, 5)
plt.plot(data['epoch'], data['x/lr0'], label='LR0', color='black')
plt.plot(data['epoch'], data['x/lr1'], label='LR1', color='grey')
plt.plot(data['epoch'], data['x/lr2'], label='LR2', color='lightgrey')
plt.title('Learning Rates')
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.legend()
# Adjust layout
plt.tight_layout()
# Show the plots
plt.show()
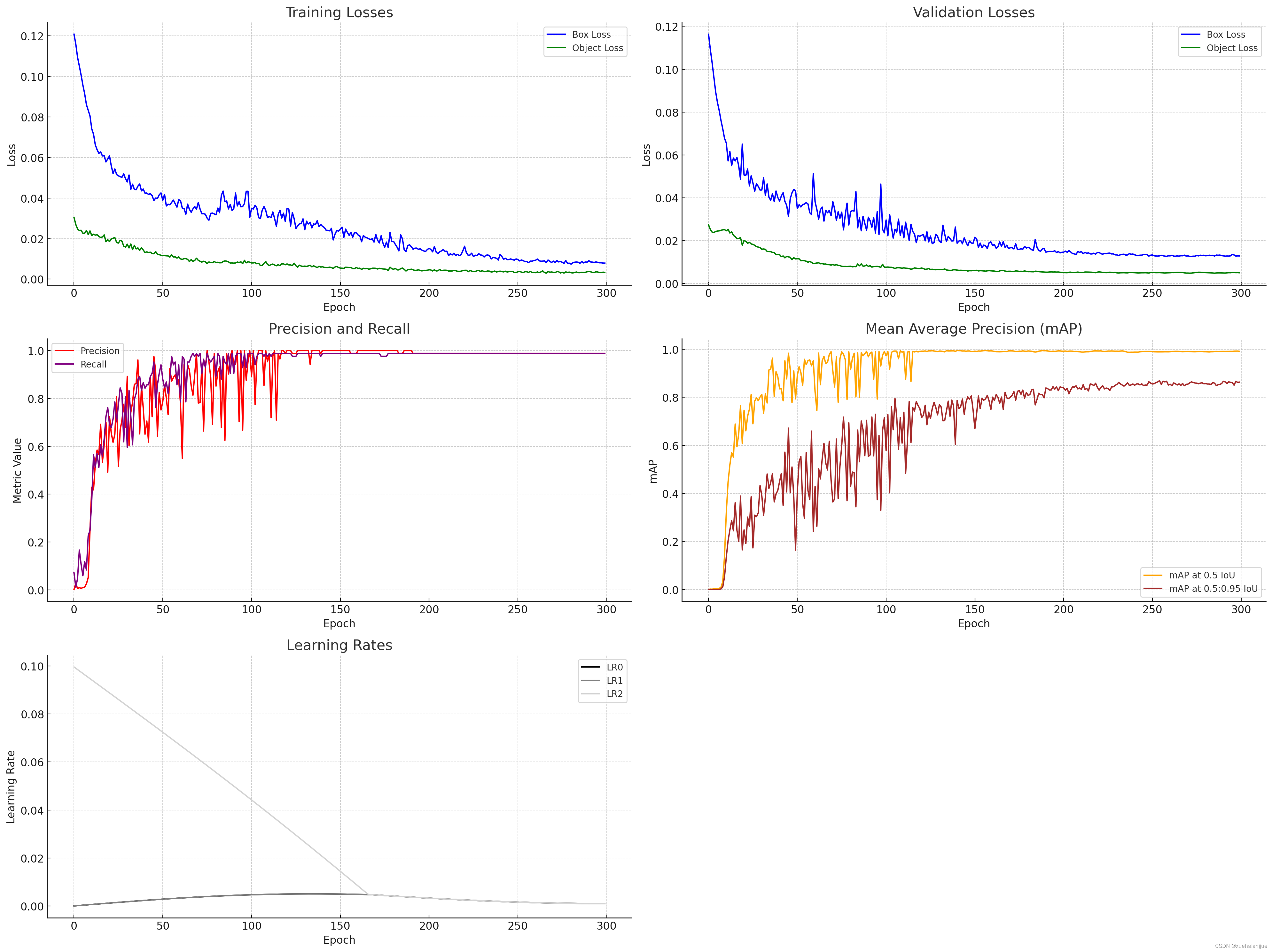
训练和验证损失
框和对象损失:训练和验证框损失以及对象损失都显示出明显的下降趋势,这是一个积极的指标。损失的减少表明该模型正在学习如何更好地预测边界框并在历元内检测对象(在本例中为交通灯)。观察到验证损失与训练损失非常接近是至关重要的,这表明模型对未见过的数据具有良好的泛化能力。
准确率和召回率
精度:精度衡量正确预测的阳性观察值与总预测阳性值的比率。精度一开始非常低,但显示出增加的趋势,这表明随着时代的进步,模型在预测交通信号灯方面变得越来越准确。
召回率:召回率计算正确预测的阳性观察值与所有实际阳性值的比率。召回率也显示出增加,尽管它的波动似乎比精确度更大。这种波动可能表明模型对数据集中不同类型的交通灯实例的敏感度不同。
平均精度 (mAP)
0.5 IoU 和 0.5:0.95 IoU 下的 mAP:mAP 分数,特别是对于更严格的 0.5:0.95 IoU 范围,是模型在对象检测中整体有效性的关键指标。mAP 分数在两个 IoU 阈值下的稳定增长表明,该模型检测和定位具有正确边界框的交通灯的能力正在持续提高。
学习率
学习率变化(LR0、LR1、LR2):学习率在初始时期略有增加,然后趋于平稳。这种模式在许多深度学习训练体系中是典型的,其中初始的“加速”期之后是稳定阶段。学习率调整可能是旨在优化训练过程的学习率计划的一部分。
标签相关图
相关图可能表示数据集中不同标签属性之间的相关性,例如交通灯边界框的位置 (x, y)、宽度和高度。在这样的情节中,可以分析几点:
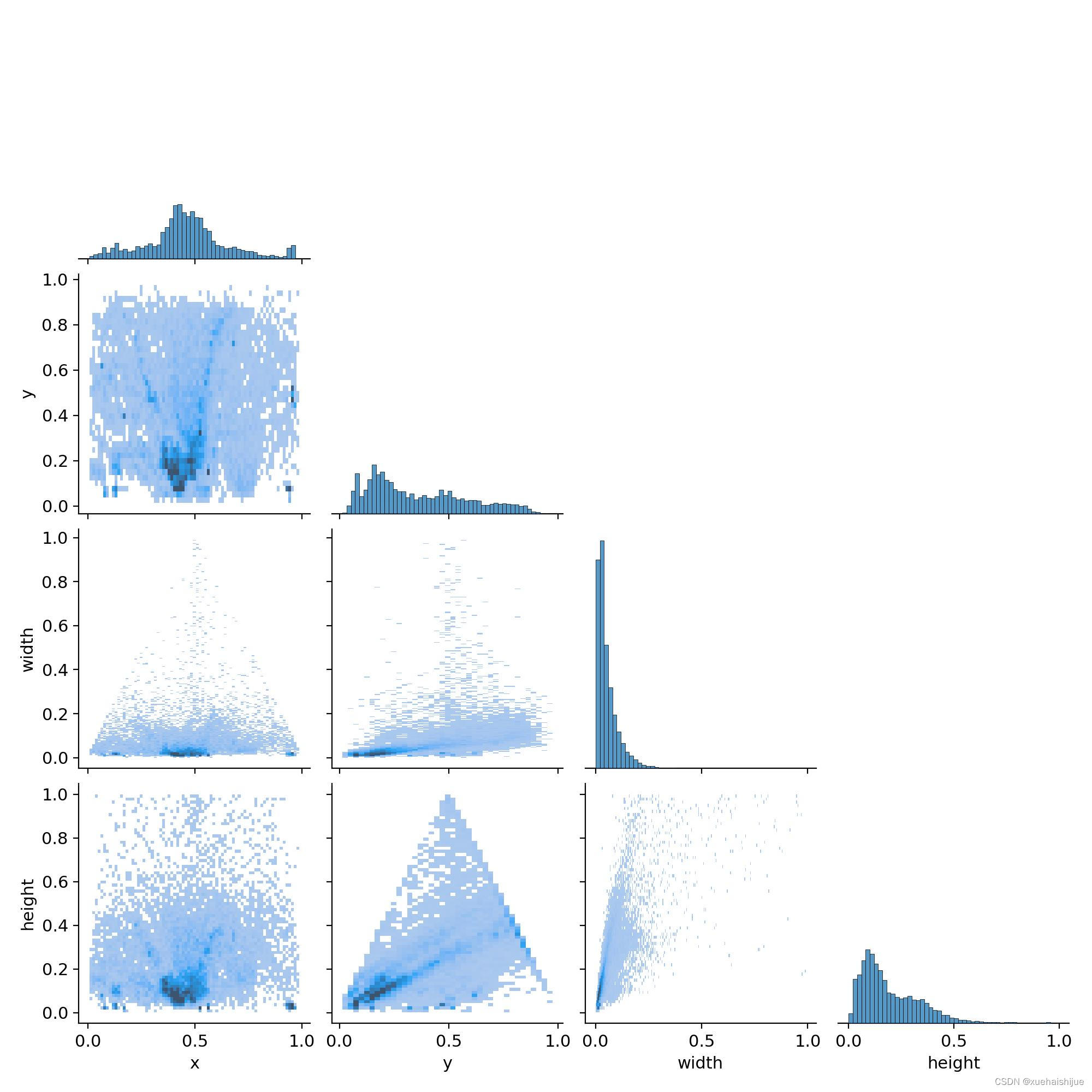
x 和 y 位置的分布可能表明交通信号灯在图像内的某些位置更频繁地出现的趋势。例如,如果交通信号灯通常位于顶部,则 y 分布将朝着较低 y 值较高(因为在图像坐标中,图像顶部的 y 值较低)。
宽度和高度分布将显示检测到的交通灯的常见尺寸。如果这些分布存在峰值,则可能意味着大多数交通灯在数据集中具有相似的大小,这可能是由于距摄像机的距离所致。
宽度和高度之间的相关性可能表明,正如预期的那样,交通信号灯保持一致的纵横比。
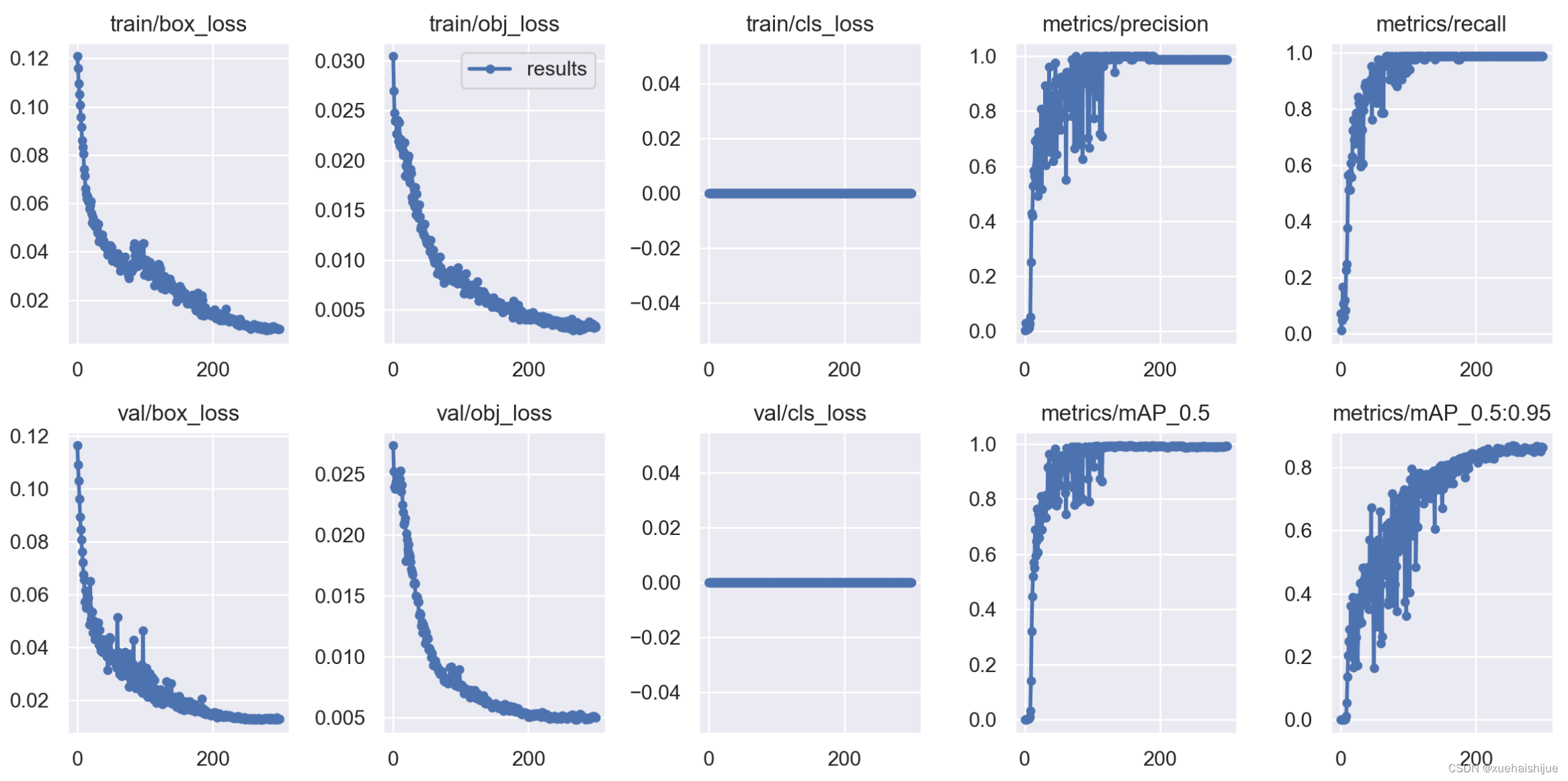
结果图
该图似乎是训练和验证期间各个时期的损失指标和性能指标(例如精度、召回率和 mAP)的图形表示。这些图提供了学习过程的清晰视觉指示。理想情况下,趋势应显示随着 epoch 的增加,损失不断减少,精确度、召回率和 mAP 不断增加,这表明模型性能的学习和改进。

训练批次
训练批次中的图像通常显示输入数据的示例,模型的预测覆盖为边界框。对于这些图像,重要的是要观察:
预测的边界框与图像中实际交通灯的对齐程度。
模型对其预测是否有信心,这通常由边界框的厚度或颜色来指示。
错误预测是否存在任何常见模式,例如在某些类型的场景或某些类型的交通信号灯中始终出现误报或漏报。
结果指导性意义
指标的总体趋势是积极的,表明交通灯检测模型的训练和验证成功。
训练和验证损失的紧密结合表明该模型没有明显过度拟合。
精确度和召回率的提高以及 mAP 分数的提高,有力地表明了模型准确检测交通灯的能力不断增强。
学习率策略似乎有效,但探索其他策略(例如学习率衰减或循环学习率)可能会有所帮助,看看它们是否会进一步提高模型性能。
考虑到任务的性质,使用真实世界数据或不同的照明和天气条件执行额外的验证以确保鲁棒性将很有用。
10.系统整合

参考博客《基于改进FBNetV3-Backbone的YOLOv5的疲劳驾驶分神状态检测系统》
11.参考文献
[1]王秀,周枫晓,刘保罗,等.基于Dlib库的驾驶员疲劳驾驶检测系统[J].物联网技术.2021,11(12).DOI:10.16667/j.issn.2095-1302.2021.12.006 .
[2]金智功,周孟然.基于卷积神经网络的图像风格迁移算法研究[J].合肥学院学报(综合版).2021,(2).DOI:10.3969/j.issn.1673-162X.2021.02.007 .
[3]周继红,杨傲,袁丹凤,等.疲劳驾驶及其评估方法进展[J].伤害医学(电子版).2021,(3).DOI:10.3868/j.issn.2095-1566.2021.03.009 .
[4]许宛如,刘奎,吴海峰.基于结构张量的混合阶偏微分方程图像去噪[J].合肥学院学报(综合版).2020,(5).
[5]郑伟成,李学伟,刘宏哲,等.基于深度学习的疲劳驾驶检测算法[J].计算机工程.2020,(7).DOI:10.19678/j.issn.1000-3428.0055912 .
[6]李晓星,朱明.基于低光增强的夜间疲劳驾驶检测算法[J].计算机系统应用.2020,(10).DOI:10.15888/j.cnki.csa.007558 .
[7]杨海燕,相运杰,胡蓉.疲劳驾驶检测方法研究综述[J].宝鸡文理学院学报(自然科学版).2020,(1).DOI:10.13467/j.cnki.jbuns.2020.01.005 .
[8]屠菁.基于雨课堂的智慧课堂教学学习行为分析–以“数据库原理与应用”课程为例[J].合肥学院学报(综合版).2019,(2).DOI:10.3969/j.issn.1673-162X.2019.02.012 .
[9]王竹婷,夏竹青.关键权重自适应填充的协同过滤推荐算法研究[J].合肥学院学报(综合版).2019,(5).
[10]庞惠珊,张灵聪.驾驶疲劳测量方法研究综述[J].人类工效学.2018,(2).DOI:10.13837/j.issn.1006-8309.2018.02.0017 .


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









