






 本文介绍了一种基于深度网络的石油生产异常识别系统,用于实时监测和识别人员跌倒及安全帽佩戴情况。通过结合SENet注意力机制改进的YOLOv5,提高识别准确性。系统包括数据集的采集、标注和整理,以及多标签分类网络和动态不安全行为识别实验。训练结果分析显示模型在识别动态和静态不安全行为方面表现良好,具有提高生产安全性和效率的实际意义。
本文介绍了一种基于深度网络的石油生产异常识别系统,用于实时监测和识别人员跌倒及安全帽佩戴情况。通过结合SENet注意力机制改进的YOLOv5,提高识别准确性。系统包括数据集的采集、标注和整理,以及多标签分类网络和动态不安全行为识别实验。训练结果分析显示模型在识别动态和静态不安全行为方面表现良好,具有提高生产安全性和效率的实际意义。
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
近年来,随着石油工业的快速发展,石油生产过程中的安全问题也日益凸显。在石油生产现场,人员跌倒和安全帽佩戴不当等问题经常发生,给工人的生命安全和身体健康带来了巨大的威胁。因此,开发一种基于深度网络的石油生产异常识别系统,能够实时监测和识别人员跌倒和安全帽佩戴情况,对于提高石油生产过程中的安全性和效率具有重要意义。
首先,人员跌倒是石油生产现场常见的安全隐患之一。在高温、高压等恶劣的工作环境下,工人们往往需要长时间站立或进行重体力劳动,容易出现疲劳和不稳定的情况,从而导致跌倒事故的发生。这些事故不仅会给工人的生命安全带来威胁,还会对石油生产过程造成中断和损失。因此,通过基于深度网络的异常识别系统,能够实时监测工人的姿态和动作,及时发现跌倒行为并采取相应的预警和救援措施,可以有效减少人员跌倒事故的发生,保障工人的安全。
其次,安全帽佩戴不当也是石油生产现场常见的安全问题之一。在石油生产过程中,工人们需要佩戴安全帽来保护头部免受可能的伤害。然而,由于工作环境的复杂性和工人的疏忽,安全帽佩戴不当的情况时有发生。例如,有的工人可能没有佩戴安全帽,或者佩戴不正确,导致头部暴露在危险的环境中。这种情况不仅会增加工人头部受伤的风险,还会对石油生产过程中的其他工人和设备造成潜在的威胁。因此,通过基于深度网络的异常识别系统,能够实时监测工人的头部状态和安全帽佩戴情况,及时发现佩戴不当的行为并进行预警和纠正,可以有效提高石油生产过程中的安全性和稳定性。
此外,基于深度网络的石油生产异常识别系统还具有以下几个方面的意义:
-
提高生产效率:通过实时监测和识别人员跌倒和安全帽佩戴情况,可以及时发现和处理潜在的安全隐患,减少事故的发生,从而提高石油生产过程的效率和稳定性。
-
降低人力成本:传统的人工监测和识别方式需要大量的人力投入,不仅费时费力,而且容易出现疏漏。而基于深度网络的异常识别系统可以实现自动化监测和识别,减少人力成本,提高工作效率。
-
推动技术创新:基于深度网络的异常识别系统是将人工智能技术与石油生产领域相结合的创新尝试,可以为其他行业和领域的安全监测和识别提供借鉴和参考,推动技术的进步和应用。
综上所述,基于深度网络的石油生产异常识别系统在提高石油生产过程中的安全性和效率方面具有重要意义。通过实时监测和识别人员跌倒和安全帽佩戴情况,可以及时发现和处理潜在的安全隐患,减少事故的发生,保障工人的生命安全和身体健康。同时,该系统还可以降低人力成本,推动技术创新,为其他行业和领域的安全监测和识别提供借鉴和参考。因此,开展基于深度网络的石油生产异常识别系统的研究具有重要的实际意义和应用价值。
2.图片演示



3.视频演示
基于深度网络的石油生产异常识别系统_哔哩哔哩_bilibili
4.基于注意力机制改进的 YOLOv5
安全帽佩戴检测技术主要是应用于工地、厂房等场合,用于保护工人的安全。在此类复杂环境下,由于受到拍摄设备、拍摄角度、天气、人员数量多等影响,安全帽佩戴检测存在需要检测模糊目标或者小目标的问题。而 YOLOv5在处理模糊或小目标的图像时,可能会出现误检或漏检的情况。
为了解决上述问题,本章提出了一种新改进的注意力机制MSENet结合到YOLOv5中。MSENet是一种多尺度注意力机制,其可以帮助模型对现场环境中的复杂因素进行有效的过滤。例如,在建筑工地上,存在许多干扰因素,如机器设备、人员、材料等,这些因素可能会干扰模型对工人是否佩戴安全帽的判断。通过使用多尺度注意力机制,模型可以在处理输入时对不同的区域进行不同程度的关注,从而忽略掉一些无关的信息,更准确地判断工人是否佩戴安全帽。
YOLOv5的中间层结构输出具有三种不同尺度和不同语义级别的特征图,这些特征图可以包含不同的特征信息。因此,在中间层的输出后使用MSENet模块可以帮助模型在不同的尺度下的特征图中都能更好地关注有用的特征,并削减无用信息的干扰,并把信息送给对应的检测头。YOLOv5网络融合了MSENet模块的网络结构如下图所示:
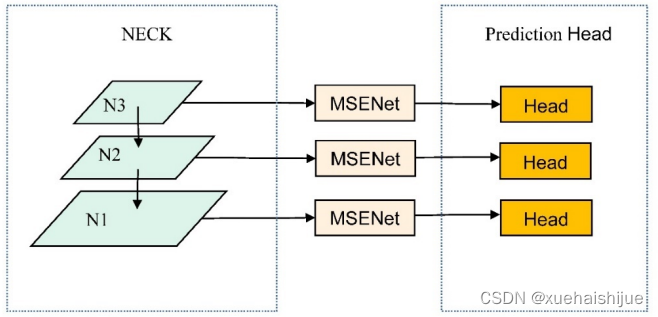
SENet注意力机制
SENet (Squeeze-and-Excitation Network)[44]是一种基于注意力机制的神经网络。其中,注意力机制的作用是帮助模型在处理序列数据时关注于当前任务最相关的信息,而不是均匀地对待所有输入。这样,注意力机制可以帮助模型更有效地学习和理解输入数据,从而提高预测的准确性。而SENet通过引入注意力机制来适应不同任务对于特征图的不同侧重点,从而提升深度神经网络的性能。在卷积神经网络中,特征映射是在整个网络中共享的,因此需要将输入的所有信息都考虑在内,但这样会导致网络计算量大、容易出现过拟合等问题。为了解决这些问题,SENet引入了注意力机制,以自适应地学习每个通道的重要性,并在不丢失重要信息的情况下削减输入数据的维度。其网络结构图如下图所示:
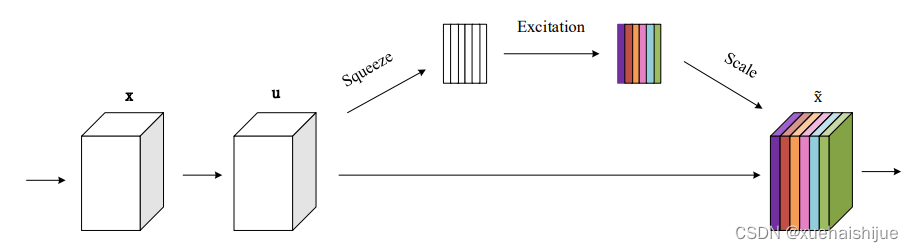
5.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集ConstructionDatasets。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:

(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。

下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
6.基于多标签分类网络的静态不安全行为识别
本文采用的多标签分类网络相较于单标签分类网络只在编码格式和最后层的激活函数上有区别。多标签分类网络的编码格式由单标签分类网络的one-hot编码格式改为multi-hot编码格式。激活函数由softmax激活改为sigmoid激活,特征提取部分保留原有的结构不做改变。这样能使得单标签分类网络的所有类别置信度和为1变为每个类别为0到1的数值回归,相当于同时完成了多个二分类训练而只保存一个模型,相比训练多个二分类网络,多标签分类网络可同时检测多种工业环境中的静态不安全行为,更符合实际情况。多标签分类网络结构如图所示。
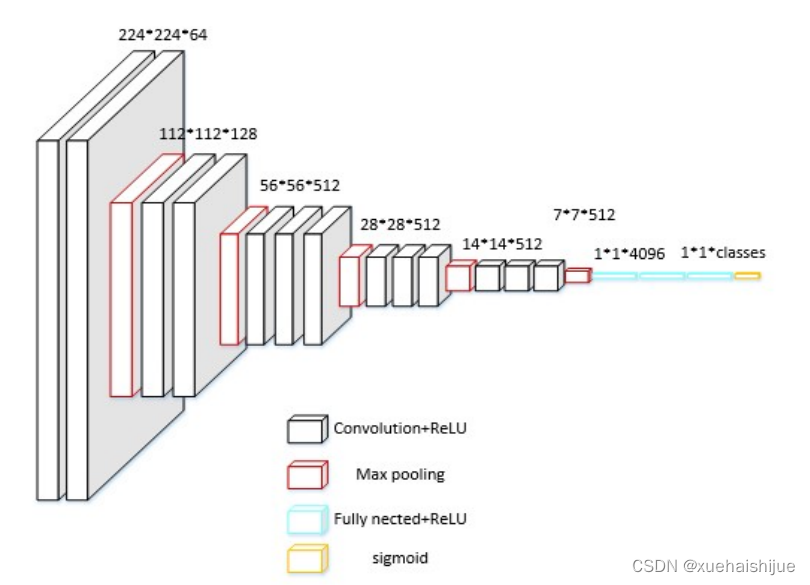
本文提出的动静态不安全行为混合识别模型主要基于两点考虑。一、在实际的工业环境中都面临着多个监控相机对应一台服务器的情况,当需要同时分析多个监控摄像头拍摄的画面时不能满足实时处理,需要以轮询的方式解决。而在轮询时无法保证每一次的轮询都是在行为发生的起始时刻或是行为正在发生时刻。因此如果仅以增加训练数据集的方式解决如此多运动历史图像的情况显然是不切实际的。二、整合上文提到的静态不安全行为识别模型和动态不安全行为识别模型为统一框架,满足单一监控相机下实时分析不安全行为的需求。因此本文提出了如下的动静态不安全行为混合识别算法。
以目标区域运动历史图像中高亮像素个数占比为依据区分区域的运动状态,将高亮像素占比较低的区域归类为静止区域送入静态不安全行为模型识别行为。将高亮像素占比较高的区域归类为动态区域送入动态不安全行为模型识别行为。整合YOLO目标检测网络后整体的算法结构流程图如图所示。对输入的视频流数据一路经过目标检测网络,获取视频中的多个目标位置,另一路计算视频对应的运动历史图像。在得到多目标位置和运动历史图像后,裁剪对应位置的运动历史图像和原图,得到crop_mhi和 crop_rgb,经过判断每个区域的crop_mhi动静态情况送入后续对应的不安全行为识别模型,实现多目标的动静态不安全行为识别。

7.动态不安全行为识别实验
动态行为识别模型采用改进双流网络,在目前检测网络的基础上得出人员位置区域,通过获取的人员位置裁剪对应运动历史图像后送入改进双流网络识别行为。改进双流网络的两路卷积神经网络都采用vgg16基础网络提取对应特征,加载Imagenet的预训练权重加快网络的训练速度,最后全连接层的输出类别微调为6类,采用softmax激活函数。两路网络得出的激活结果采用平均值的方式作为行为识别的最终结果。模型训练过程中使用多分类交叉嫡损失函数,并采用Adagrad优化算法对网络进行参数更新,Batchsize设为8,初始学习率为0.001并采用学习率衰减的办法优化网络。

实验测试结合Faster R-CNN目标检测网络和改后双流网络实现对工业环境中的多目标的动态不安全行为识别。测试结果如图所示,分别展示了常规动态识别(走,坐)和不安全动态识别(跌倒)两种。左侧区域为对应的人员运动历史图像,右侧框出区域是经过YOLO目标检测网络识别到的人员位置区域,框出的区域上侧结果为改进双流网络识别的动态不安全行为结果。通过图的实验结果表明,本节提出的动态行为识别模型能够正确的预测行为类别,验证了本文提出的改进双流网络对工业环境下动态不安全行为识别的有效性。

动静态不安全行为混合识别数据集采用的自行采集的测试视频,主要测试本文提出的算法流程在工业环境下的识别效果,尤其是实时分析工人在动静态切换下的识别效果。动静态判断阈值设定为0.05,测试工人在工业环境下的6种动态行为和6种静态行在工业环境下人员的动态识别结果如上图所示,识别结果为走,常规动态行为。左侧为当前该工人对应的运动历史图像信息,通过计算该位置区域的高亮像素占比高于设定的0.05阈值,因此采用动态行为识别模型,即改进双流网络判断行为分类,可以看到模型能够准确预测出动态行为。

当工人由站到坐的过程中,目标位置的运动历史区域图像的高亮像素占比值高于设定的0.05阈值,划分为动态行为,送入动态行为识别模型即改进双流网络。当工人坐下后静止时左侧对应的运动历史图像区域高亮像素占比阈值小于设定阈值0.05,判断该区域为静态区域,送入静态不安全行为识别模型中,并正确识别出了该区域目标的结果为穿戴安全帽和工作服且未发生静态不安全行为的工人。从上图可以看出本文提出的混合识别模型可以根据阈值切换模型的动静态不安全行为分析,避免由于监控摄像头轮转所造成了行为抓取不准确的问题。下面列举了一些其他的动静态混合识别结果,可以看出无论是动态不安全行为还是静态不安全行为,本文提出的动静态不安全行为混合识别模型均能较好的识别。

8.训练结果可视化分析
评价指标
(1)train/box_loss训练 (train/obj_loss、train/cls_loss) 和验证 ( val/box_loss、val/obj_loss、val/cls_loss)期间框检测、对象检测和类检测的损失。
(2)不同IoU 阈值 ( , )下的性能指标,例如精度 ( metrics/precision)、召回率 ( )、平均精度 (mAP)。metrics/recallmetrics/mAP_0.5metrics/mAP_0.5:0.95
(3)学习率 ( x/lr0, x/lr1, x/lr2)。
训练结果数据可视化
为了可视化这些数据,我们可以为这些时期的这些指标创建图表。这将帮助我们了解模型的性能和学习在训练过程中是如何演变的。让我们首先绘制训练和验证损失,然后绘制精度、召回率和 mAP 指标。可视化之后,我将提供数据的详细分析。
import matplotlib.pyplot as plt
# Setting up the plot layout
fig, axes = plt.subplots(3, 2, figsize=(15, 15))
fig.suptitle('Training and Validation Metrics Over Epochs')
# Plotting training and validation losses
axes[0, 0].plot(data['epoch'], data['train/box_loss'], label='Train Box Loss')
axes[0, 0].plot(data['epoch'], data['val/box_loss'], label='Validation Box Loss')
axes[0, 0].set_title('Box Loss')
axes[0, 0].set_xlabel('Epoch')
axes[0, 0].set_ylabel('Loss')
axes[0, 0].legend()
axes[0, 1].plot(data['epoch'], data['train/obj_loss'], label='Train Object Loss')
axes[0, 1].plot(data['epoch'], data['val/obj_loss'], label='Validation Object Loss')
axes[0, 1].set_title('Object Loss')
axes[0, 1].set_xlabel('Epoch')
axes[0, 1].set_ylabel('Loss')
axes[0, 1].legend()
axes[1, 0].plot(data['epoch'], data['train/cls_loss'], label='Train Class Loss')
axes[1, 0].plot(data['epoch'], data['val/cls_loss'], label='Validation Class Loss')
axes[1, 0].set_title('Class Loss')
axes[1, 0].set_xlabel('Epoch')
axes[1, 0].set_ylabel('Loss')
axes[1, 0].legend()
# Plotting precision, recall, and mAP
axes[1, 1].plot(data['epoch'], data['metrics/precision'], label='Precision', color='green')
axes[1, 1].set_title('Precision')
axes[1, 1].set_xlabel('Epoch')
axes[1, 1].set_ylabel('Precision')
axes[1, 1].legend()
axes[2, 0].plot(data['epoch'], data['metrics/recall'], label='Recall', color='red')
axes[2, 0].set_title('Recall')
axes[2, 0].set_xlabel('Epoch')
axes[2, 0].set_ylabel('Recall')
axes[2, 0].legend()
axes[2, 1].plot(data['epoch'], data['metrics/mAP_0.5'], label='mAP@0.5', color='orange')
axes[2, 1].plot(data['epoch'], data['metrics/mAP_0.5:0.95'], label='mAP@0.5:0.95', color='purple')
axes[2, 1].set_title('Mean Average Precision (mAP)')
axes[2, 1].set_xlabel('Epoch')
axes[2, 1].set_ylabel('mAP')
axes[2, 1].legend()
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
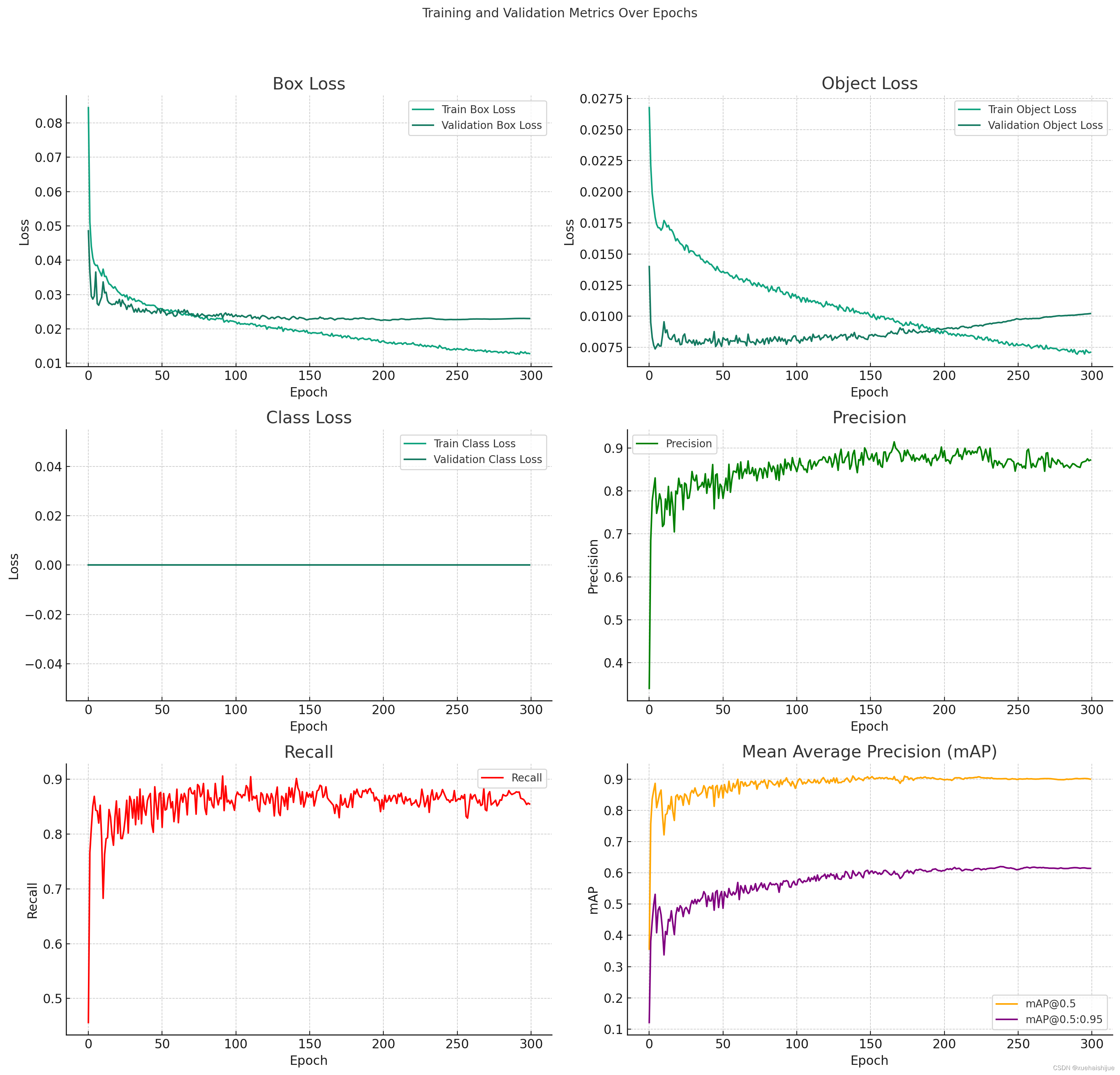
训练和验证损失(Loss)
盒损失(Box Loss) : 盒损失是直观检测模型中预测的边界框与实际边界框之间差异的焦点。在您的实验中,训练和验证的盒损失都随着时间的流逝而显着下降,这表明模型在学习如何更准确地定位图像中的物体。这对于确保模型能够准确识别异常事件(如人员跌倒和安全未佩戴)至关重要。
对象损失(Object Loss) : 对象损失反应了模型在判别图像中是否存在对象方面的性能。您的数据显示,对象损失在训练和验证过程中逐渐下降,这意味着模型用于检测图像中是否有目标对象(例如人员或安全帽)变得更加精确。
类别损失(Class Loss):类别损失涉及模型对不同类别(例如人员跌倒和安全帽)的识别。从数据中可以看出,类别损失在训练过程中下降,这表示模型在区分不同类别方面的网格更加有效。
性能指标
精确度(Precision):精确度是预测为正类的样本中实际为正类的比例。您的模型在训练过程中显示出不断提高的精确度,这意味着它在减少误差报告(错误标记正常)情况为异常)方面变得更加有效。
召回率(Recall) : 召回率是实际为正类的样本中被正确预测为正类的比例。随着召回率的提高,模型在检测到所有潜在异常(如人员跌倒和安全帽未佩戴)方面表现更好。
平均精度均值(mAP) : mAP是模型性能的综合指标,反映了不同置信度阈值下的精确度和反应率的控制。您的模型在mAP@0.5和mAP@0.5:0.95上都表现出稳定的提升,这表明模型整体上在检测和分类方面表现良好。
学习率(Learning Rate)
学习率调整:学习率是影响模型训练效率和成绩的关键参数。在您的实验中,学习率似乎是逐渐增加的,这可能采用某种形式的学习率调度策略,例如温度均衡或梯度提升。正确的学习率调整是避免过度或不足、加快收敛速度关键。
总体分析
模型收敛性:根据您提供的数据,模型在训练过程中表现出良好的收敛性,损失函数持续下降,性能指标逐渐提高。
过对称与泛化:较低的验证损失和相关的验证性能指标表明模型具有良好的泛化能力,且没有出现明显的过对称现象。
实用性分析:对于石油生产中的异常识别(如人员安全),模型需要在保持位置的同时,尽量减少漏检。您的模型在这方面都表现出了良好的性能,这意味着它在实际应用中可能非常有效。
改进空间:尽管模型整体表现良好,但进一步优化了空间。例如,可以通过调整超参数、使用更复杂的网络架构或增加数据增强来进一步提升模型性能。
应用与挑战
场景预见:需要考虑模型在不同环境(如灯光变化、眼前等)下的鲁棒性。可能需要进一步的测试和调整,以确保在实际应用场景中的效果。
实时处理能力:对于石油生产环境,模型的实时处理能力至关重要。需要评估模型在实际设备上的运行速度和响应时间。
9.系统整合

参考博客《基于深度网络的石油生产异常识别系统(人员跌倒、安全帽佩戴检测)》
10.参考文献
[1]高腾,张先武,李柏.深度学习在安全帽佩戴检测中的应用研究综述[J].计算机工程与应用.2023,59(6).DOI:10.3778/j.issn.1002-8331.2207-0434 .
[2]周华平,郭依文,孙克雷.基于改进YOLOv5的安全帽佩戴检测算法[J].安徽理工大学学报(自然科学版).2022,42(3).DOI:10.3969/j.issn.1672-1098.2022.03.014 .
[3]王运辉,王景龙,权雪祺,等.基于颜色阈值分割的安全帽检测方法研究[J].电力系统装备.2021,(8).
[4]郑学远.基于YOLOv3的行人检测方法研究[J].现代信息科技.2020,(10).DOI:10.19850/j.cnki.2096-4706.2020.10.026 .
[5]张亚倩.卷积神经网络研究综述[J].信息通信.2018,(11).DOI:10.3969/j.issn.1673-1131.2018.11.010 .
[6]薛明华,艾春美,律慧瑾,等.电厂安全帽佩戴安全性监控的智能图像处理方法[J].中国电机工程学报.2022,42(9).DOI:10.13334/j.0258-8013.pcsee.210629 .
[7]丁田,陈向阳,周强,等.基于改进YOLOX的安全帽佩戴实时检测[J].电子测量技术.2022,45(17).DOI:10.19651/j.cnki.emt.2209425 .
[8]吴静,刘桂法,江虹.加强安全帽等特种劳动防护用品监管促进应急产业发展[J].中国安全生产.2019,(6).36-37.
[9]施辉.基于深度学习的工地安全帽佩戴检测算法研究[D].2019.
[10]Goodfellow, Ian,Pouget-Abadie, Jean,Mirza, Mehdi,等.Generative Adversarial Networks[J].Communications of the ACM.2020,63(11).139-144.DOI:10.1145/3422622 .

















 1446
1446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









