1.神经网络
1. 单层神经网络原理与实践
1.感知机与梯度反向传播
- MP模型:1943年心理学家W.S.McCulloch和数理逻辑学家W.Pitts提出人工神经元,称为M-P模型。
1)MP模型是一个基于阈值逻辑算法的神经网络计算模型,由固定的结构和权重构成,输入是0或者1。
2)调整权重与偏置实现不同的数学逻辑。
逻辑与:2X1+2X2-3、逻辑或2X1+2X2-1、逻辑非-2X+1。 - 单层感知器: 1957年,Frank Rosenblatt发明了感知器(Perceptron),结构与MP模型类似,一般视为最简单的人工神经网络。
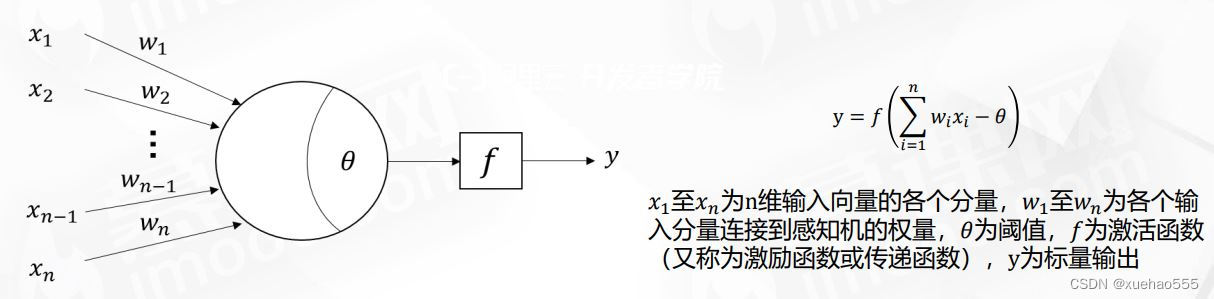
- 感知器与MP模型区别:输入不是离散型0/1,激活函数不一定是阈值函数。
- 感知器权重参数更新方法:梯度下降法。
- 梯度下降法:对于函数𝑓(𝑥),以x的梯度反方向进行更新,就能够减小𝑓(𝑥),这个方向还是减小𝑓 𝑥 的最快的方向,也被称为“最速下降法”。
- 梯度更新重要参数:学习率。
- 学习率(Learning Rate),用于控制参数更新的步长。
2.单层神经网络案例实践
- 单层感知器作为线性分类器被广泛应用。
- 单层感知器求解

- 基于Python求解单层感知器算法
import numpy as np
import matplotlib.pyplot as plt
n = 0
lr = 0.10
X = np.array([[1,2,3],
[1,4,5],
[1,1,1],
[1,5,3],
[1,0,1]])
Y = np.array([1,1,-1,1,-1])
W = (np.random.random(X.shape[1])-0.5)*2
def get_show():
all_positive_x = [2,4,5]
all_positive_y = [3,5,3]
all_negative_x = [1,0]
all_negative_y = [1,1]
k = -W[1] / W[2]
b = -(W[0])/ W[2]
xdata = np.linspace(0, 5)
plt.figure()
plt.plot(xdata,xdata*k+b,'r')
plt.plot(all_positive_x, all_positive_y,'bo')
plt.plot(all_negative_x, all_negative_y, 'yo')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
def get_update():
global X,Y,W,lr,n
n += 1
new_output = np.sign(np.dot(X,W.T))
new_W = W + lr*((Y-new_output.T).dot(X))
W = new_W
def main():
for _ in range(100):
get_update()
new_output = np.sign(np.dot(X, W.T))
if (new_output == Y.T).all():
print("迭代次数:", n)
break
get_show()
if __name__ == "__main__":
main()
2.多层神经网络原理与实践
1.多层感知器与反向传播算法
- 单层感知器的缺陷:马文·明斯基在1969年出版《感知器》书中证明单层感知器无法解决异或问题。
- 多层感知器Multi Layer Perceptron:简称MLP:在单层神经网络基础上引入一个或多个隐藏层,使网络有多个网络层,被称为多层感知器,或前馈神经网络。
- 多层感知器表达能力:1)多层感知机解决异或问题;2)万能逼近定理;
- 1986年,Rummelhart、McClelland、Hinton等人改进了反向传播算法(Backpropagation,缩写为BP)用于多层神经网络学习。
- 反向传播:损失函数开始从后向前,梯度逐步传递至第一层。
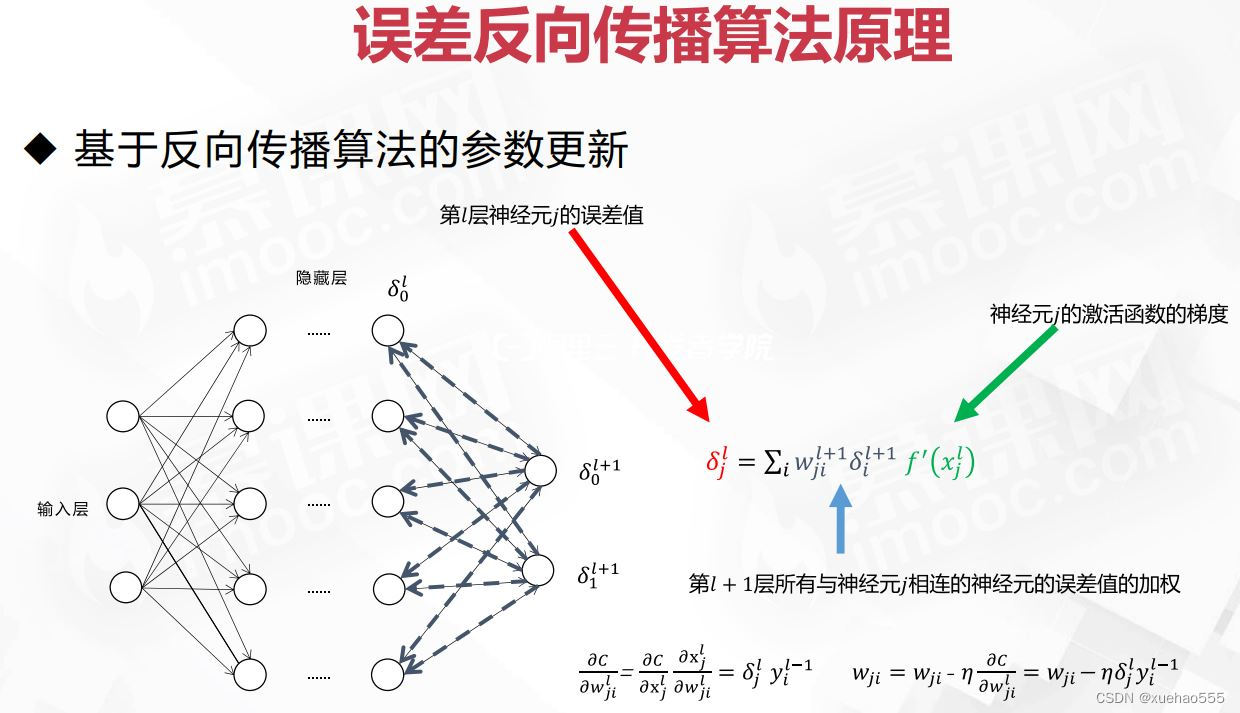
- 误差反向传播算法原理:1)反向传播中的误差δ,令𝛿𝑗𝑙表示第𝑙层第𝑗个神经元上的误差。2)前向计算时,神经元的输入是上一层神经元输出的线性组合,类似地,反向计算时,可通过下层神经元的误差来计算当前层的误差。3)基于反向传播算法的参数更新。
2.多层神经网络案例实践
- 异或问题:多层感知器可以解决单层感知器无法解决的异或问题。
- 误差反向传播算法原理
- 基于Python求解多层感知器算法
import numpy as np
import matplotlib.pyplot as plt
n = 0
lr = 0.10
X = np.array([[1,2,3],
[1,4,5],
[1,1,1],
[1,5,3],
[1,0,1]])
Y = np.array([1,1,-1,1,-1])
W = (np.random.random(X.shape[1])-0.5)*2
def get_show():
all_positive_x = [2,4,5]
all_positive_y = [3,5,3]
all_negative_x = [1,0]
all_negative_y = [1,1]
k = -W[1] / W[2]
b = -(W[0])/ W[2]
xdata = np.linspace(0, 5)
plt.figure()
plt.plot(xdata,xdata*k+b,'r')
plt.plot(all_positive_x, all_positive_y,'bo')
plt.plot(all_negative_x, all_negative_y, 'yo')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
def get_update():
global X,Y,W,lr,n
n += 1
new_output = np.sign(np.dot(X,W.T))
new_W = W + lr*((Y-new_output.T).dot(X))
W = new_W
def main():
for _ in range(100):
get_update()
new_output = np.sign(np.dot(X, W.T))
if (new_output == Y.T).all():
print("迭代次数:", n)
break
get_show()
if __name__ == "__main__":
main()
3. 序列神经网络
1. 序列预测问题与循环神经网络
- 典型序列预测问题-分类:1)输入不定长序列,给出类别预测,常采用Sequence-to-vector结构。如:情感分类、视频分类、语音分类。
- 典型序列预测问题-同步序列预测:输入不定长序列,输出同样长度的标注结果,常采用Sequenceto-sequence结构。如:中文分词、词性标注。
- 典型序列预测问题-异步序列预测:输入不定长序列,输出不同长度的预测结果,常采用EncoderDecoder结构。如:机器翻译。
- 典型序列预测问题-序列生成: 预测不定长的输出序列, 常采用vector-to-Sequence结构。如:语音生成、图像标注、文本生成。
- 循环神经网络:Recurrent Neural Networks,简称RNN,一种带自反馈的神经网络,能够处理任意长度的时序数据。
- 循环神经网络比前馈神经网络更加符合生物神经网络的结构,被广泛应用在语音识别、语言模型等任务上。
- RNN模型展开:将RNN按照时间维度展开。
- RNN内部结构单元的计算:令𝑥是长度为𝐼的向量,ℎ𝑡是长度为𝐻的向量,将其拼接成(𝐼 +𝐻)的向量作为输入,对应权重系数W的维度是𝐻(𝐼 + 𝐻)。
- 深层RNN模型:包含了多个隐藏层,获得更复杂的表达能力。每个隐藏状态不断传递到当前层的下一个时间步以及当前时间步的下一层。
- 双向RNN模型:不仅包括正向过程,也包含反向过程。双向的RNN获得更加完整的“上下文”信息,具有更强大的表达能力,在语音识别,机器翻译任务中都得到了比单向RNN更好的性能。
- RNN的参数学习:随时间反向传播算法BPFT(backpropagation through time),误差不仅依赖于当前时刻t,也依赖于之前时k,0<k<t。
- RNN梯度问题:存在长距离依赖问题(梯度爆炸或消失),参数更新主要依靠当前时刻的相邻状态。
(1) 连乘存在Wℎℎ的t次幂,如果矩阵特征值远大于1,多次连乘会造成梯度爆炸;如果远小于1,会造成梯度消失;
(2) Tanh激活函数如果进入饱和区间,连乘后数值变得很小;
2.长短时记忆网络与门控循环单元
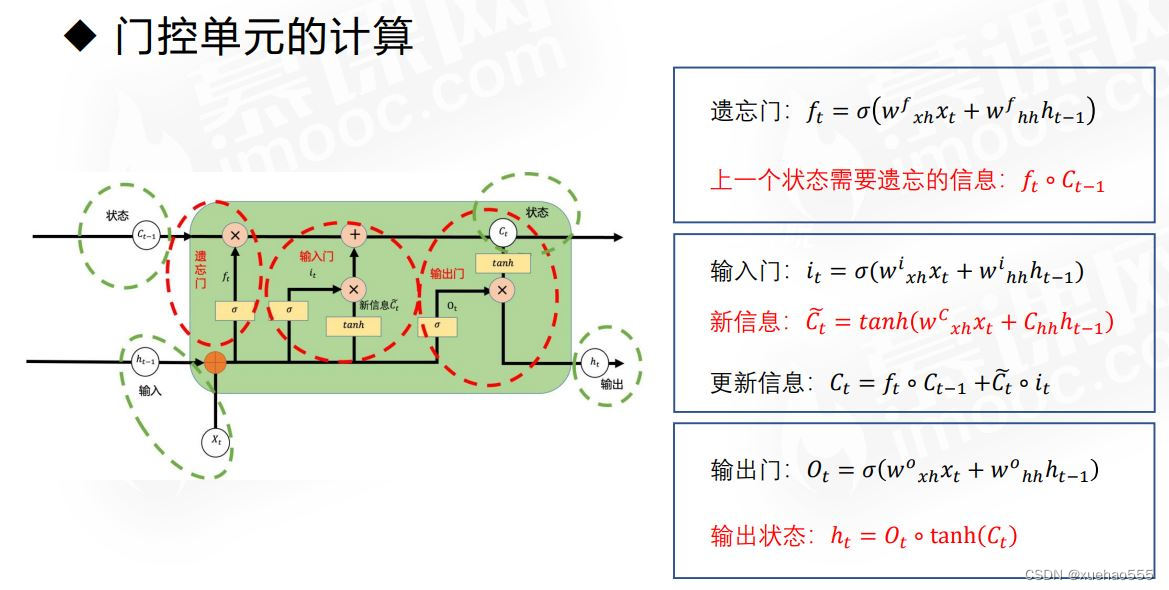
- 长短时记忆网络(Long Short-Term Memory Network):简称LSTM,主要是为了解决RNN训练过程中的长距离依赖问题。
- 引入新的内部状态cell state,它记忆重要时刻信息,生命周期介于长期与短期记忆之间。cell state状态更新是缓慢的,隐藏层h的更新是迅速的。
- 包含了三个门控单元,遗忘门、输入门与输出门,决定每一个时刻要舍弃什么旧的信息以及添加什么新的信息。
• 遗忘门决定了要从cell state中舍弃什么信息
• 输入门决定了要往当前状态中保存什么新的信息
• 输出门决定了要从cell state中输出什么信息 - 门控单元的计算:
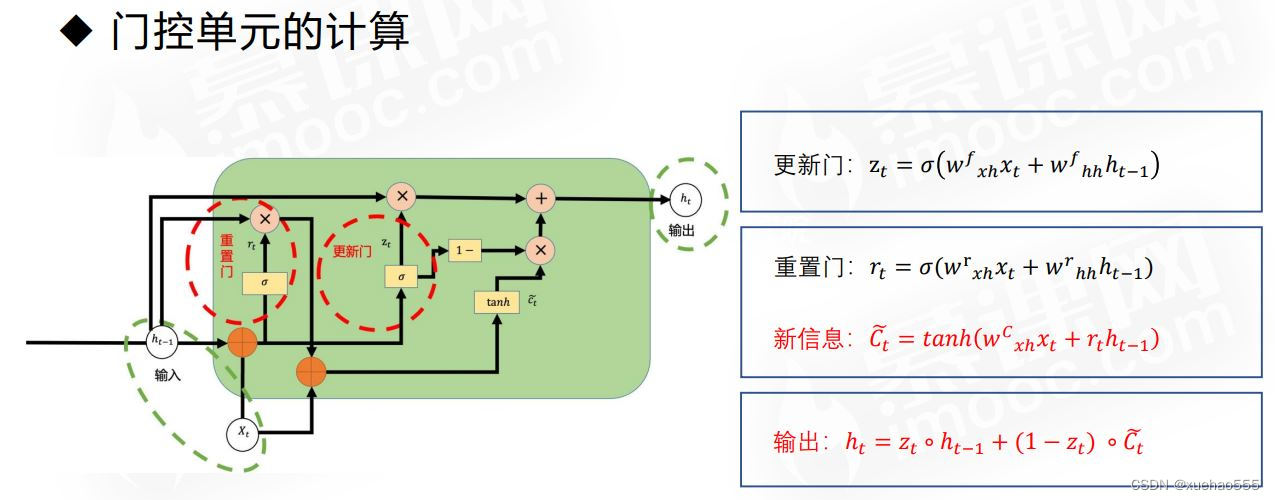
- 门控循环单元:Gated Recurrent Unit(GRU):对LSTM结构的简化,由更新门和重置门组成。
• 更新门决定了要从历史信息中保留多少信息,捕捉长程依赖关系。
• 重置门用于控制候选状态𝐶~𝑡是否依赖于上一状态ℎ𝑡−1 ,可以用来丢弃与预测无关的历史信息。 - 门控单元的计算:























 2665
2665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









