







1. Python入门与进阶
1. 环境搭建
1. Anaconda软件
作用:1)提供了包管理与环境管理的功能;2)解决了多版本python并存问题;3)解决了第三方包安装问题。
安装完Anaconda后,需要软件换源,在Anaconda Powershell Prompt中:
- conda换源:
(1)清华大学的conda镜像源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
(2) 如果需要使用conda-forge,也可以添加清华的conda-forge镜像:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
(3)设置搜索优先级:
conda config --set show_channel_urls yes - pip换源:
(1)临时使用:使用 -i 参数可以临时指定镜像源进行安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package-name
(2)永久更换:
法一:修改配置文件:1.创建或修改pip的配置文件;Linux/macOS修改~/.pip/pip.conf;Windows修改C\Users\Your_username\pip\pip.ini。2.在该配置文件中写入以下内容:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
法二:使用命令行:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
2. Anaconda环境管理
- 查看环境:(在Anaconda Powershell Prompt中)conda env list
- 创建新环境:打开命令行:conda create --name myenv
若想指定python版本:conda create -n myenv python=3.10 - 切换(激活)环境:conda activate myenv
退出当前环境:conda deactivate - 删除环境:conda remove --name myenv --all
- 重命名环境:首先,克隆当前环境到新环境:conda create --name newname --clone oldname
删除旧环境:conda remove --name oldname --all - 程序包的安装:pip:pip install package-name
conda:conda install package-name
使用conda list可以查看有哪些包是用conda进行安装的。
3. Jupyter Notebook
- 安装:pip install jupyter
- 打开:命令行输入:jupyter notebook
- 改变路径:cd D:\skye\学习\AI人工智能算法\第2周\代码
- 如何使用:New—>Notebook。Code/Markdown自由切换。若想在上面插入代码:A。下面插代码:B。代码#:注释。markdown# :一级标题。导出别的格式:file–>save and export notebook as。
- 当项目经常要可视化,项目文件较少时,使用jupyter。
4. pycharm
(1)配置环境:文件–设置–项目:–python解释器–添加解释器–conda环境–Scripts/conda.exe–加载环境。
(2)自由调节字体大小的设置:设置–按键映射–搜索中输入font–双击减小/增加字体大小–选中间–设置快捷键。
(3)若环境直接装到C盘,可以改:右键anaconda–安全–编辑–将system权限都勾上。
5.vscode修改虚拟环境
- 设置 — 命令面板— 在弹出的命令行中搜索Python: Select Interpreter。
2. python基础与程序控制
- 转为浮点数:float(num);
- 转为字符串:
#1)使用str()转为字符串:
name = "Alice"
age=30
print("My name is %s and I'm %d years old."%(name,age))
print("My name is {} and I'm {} years old.".format(name,age))
print(f"My name is {name} and I'm {age} years old.")
# 2)输出时控制精度
number=12.3456
print("%.2f"%number)
print("{:.2f}".format(number))
print(f"{number:.2f}")
- for循环
#1)可指定循环次数
epoch=5
for i in range(epoch):
print(f"第{i}个数据处理完毕")
#2)可指定迭代对象
optimizers=["SGD","Adam","Mo","Ada"]
for i in optimizers:
print("正在使用",i,"进行优化")
#3)可对数据进行枚举
img_list = ["img_1.png", "img_2.png", "img_3.png"]
for index, img_i in enumerate(img_list):
print(f"索引 {index} 对应的数据是 {img_i}")
- while循环
# 当不清楚应该循环多少次时,用while
command = ""
while command != "end":
command = input("请输入命令:")
print("正在执行命令:",command)
- break打破循环:使用break可以停止循环,跳出整个循环。
- continue跳过当前回合:continue跳过当前回合,仍在循环中。
3. python列表、元组、字典和集合
1.序列
- 序列的通用操作:索引(num[-1]:取最后一个值),切片,序列相加,序列乘法,序列是否包含元素,序列长度、最大值、最小值。
- 序列切片:
numbers=[10,11,12,13,14]
print(numbers[1:3]) #[11,12]
print(numbers[2:]) #[12,13,14]
print(numbers[:2]) #[10,11]
print(numbers[:-2]) #[10,11,12]
print(numbers[0:4:2]) #[10,12]
- 序列相加: 两个序列前后拼在一起
numbers = [1,2,3,4,5]
data = ["a", "b", 3, 4.0, 5]
result = numbers + data
print(result)
#[1, 2, 3, 4, 5, 'a', 'b', 3, 4.0, 5]
- 序列乘法:序列中的内容重复出现多次
numbers = [1, 2, 3]
result = numbers * 3
print(result)
#[1, 2, 3, 1, 2, 3, 1, 2, 3]
- 序列是否包含元素:查看元素是否在序列中。
numbers = [1,2,3]
if 1 in numbers:
print("1 在 numbers 里面")
else:
print("1 不在 numbers 里面")
#1 在 numbers 里面
- 序列长度、最大值、最小值:对序列做简单的统计
numbers = [1,2,3, 4, 5]
print(len(numbers))
print(max(numbers))
print(min(numbers))
2.列表:
- 创建列表:列表是最常用的序列。
list_empty = []
list_a = [1,2,3]
list_b = list(range(10))
print(list_empty)
print(list_a)
print(list_b)
- 访问列表元素:列表属于序列,可以用索引访问。
- 遍历列表:对列表遍历的两种方式。
#1)使用 for … in … 遍历列表
data_list = ['a', 'b', 'c', 'd', 'e']
for data_i in data_list:
print(data_i)
#2)使用 enumerate遍历列表
data_list = ['a', 'b', 'c', 'd', 'e']
for index, data_i in enumerate(data_list):
print(index, data_i)
- 添加、修改、删除列表元素:列表可以进行增删改查。
list_a = [1,2,3,4,5]
print(list_a)
list_a.append(6)
print(list_a)
list_a[0] = 0
print(list_a)
list_a.remove(4)
print(list_a)
- 列表元素统计计算:列表的简单统计
list_a = [1,2,3,4,5]
result = sum(list_a)
print(result)
- 列表排序:对列表进行排序
score = [50,60,20,40,30,80,90,55,100]
print("原列表:",score)
score.sort()
print("升序后:",score)
score.sort(reverse=True)
print("降序后:",score)
- 列表推导式:可以快速创建一个有序列表
x_list = [i for i in range(10)]
print(x_list)
3. 元组
- 创建元组:列表是方括号,元组是小括号。
tuple_1 = ()
tuple_2 = tuple(range(10, 20, 2))
print(tuple_1)
print(tuple_2)
- 访问元组元素:元组的数据可以索引和切片。
tuple_1 = (1, 2, 3, 4, 5)
print(tuple_1[2])
print(tuple_1[-1])
- 元组推导式:像创建列表那样创建元组。
tuple_a = tuple(i for i in range(10))
print(tuple_a)
-
列表和元组的差异
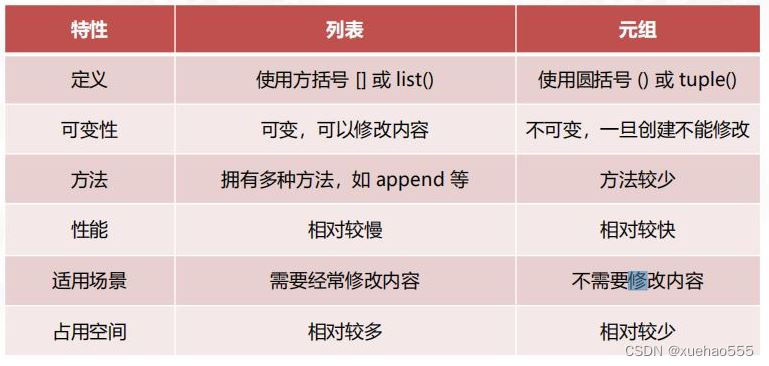
列表(list)和元组(tuple)是 Python 中两种不同的数据类型,它们都可以用来存储一组数据。以下是它们的异同点:
(1)相同点:
1)存储多个元素
列表和元组都可以存储多个元素。
2)有序
列表和元组都是有序的,即它们的元素都有一个唯一的索引,从0开始。
3)支持多种数据类型
列表和元组都可以存储不同类型的数据,比如字符串、整数、浮点数等。
4)支持嵌套
列表和元组都可以嵌套其他的列表、元组或其他数据类型。
5)可迭代
列表和元组都是可迭代的,可以使用循环来遍历它们的元素。
(2)不同点:
1)可变性
列表是可变的(Mutable):
您可以修改列表的元素(添加、删除或更改)。
元组是不可变的(Immutable):一旦创建了元组,您就不能修改它(不能添加、删除或更改元素)。
# 示例
list_example = [1, 2, 3]
list_example[0] = 0 # 可以修改列表的元素
tuple_example = (1, 2, 3)
# tuple_example[0] = 0 # 这会引发错误,因为不能修改元组的元素
2) 语法
列表使用方括号([]);
元组使用圆括号(());
3)性能
元组的性能通常比列表更好:因为元组是不可变的,所以它们在执行速度和内存使用方面通常比列表更高效。
4) 使用场景
列表:
当您需要一个可以修改的数据集时使用。
元组:
当您需要一个不可修改的数据集时使用。
4.字典
- 创建字典:字典存放的信息以键值对形式出现。
info_xiaoming = {'name':'小明',
'age':14,
'score':60}
info_zhangsan = {'name':'张三',
'age':15,
'score':79}
print(info_xiaoming)
print(info_xiaoming['age'])
print(info_zhangsan['score'])
# 创建一个字典来存储神经网络的配置参数
neural_network_config = {
"layer_1": {"units": 64, "activation": "relu"},
"layer_2": {"units": 128, "activation": "relu"},
"output_layer": {"units": 10, "activation": "softmax"}
}
print(neural_network_config)
- 通过键值对访问字典:可以通过键访问到值。
# 创建一个字典来存储神经网络的配置参数
neural_network_config = {
"layer_1": {"units": 64, "activation": "relu"},
"layer_2": {"units": 128, "activation": "relu"},
"output_layer": {"units": 10, "activation": "softmax"}
}
# 访问字典中的特定键值对
layer_1_units = neural_network_config["layer_1"]["units"]
print(f"Number of units in layer 1: {layer_1_units}")
- 遍历字典:对字典遍历的方式。
info_xiaoming = {'name':'小明',
'age':14,
'score':60}
# 遍历字典
print("以下为 xiaoming 的信息:")
for key, value in info_xiaoming.items():
print(f"{key} 为 {value}")
# 2)
neural_network_config = {
"layer_1": {"units": 64, "activation": "relu"},
"layer_2": {"units": 128, "activation": "relu"},
"output_layer": {"units": 10, "activation": "softmax"}
}
# 遍历字典,打印每一层的配置信息
for layer, config in neural_network_config.items():
print(f"{layer}: {config['units']} units, activation = {config['activation']}")
- 添加、修改和删除字典元素:可以对字典元素进行增删改查。
neural_network_config = {
"layer_1": {"units": 64, "activation": "relu"},
"layer_2": {"units": 128, "activation": "relu"},
"output_layer": {"units": 10, "activation": "softmax"}
}
# 添加一个新的层到字典
neural_network_config["layer_3"] = {"units": 256, "activation": "relu"}
# 修改第一层的单元数
neural_network_config["layer_1"]["units"] = 128
# 删除输出层的激活函数键值对
del neural_network_config["output_layer"]["activation"]
# 输出修改后的字典
print(neural_network_config)
5.集合
- 创建集合:集合的标值是大括号,具有去重复作用。
set_1 = set()
set_2 = {}
set_3 = {1,2,3,3, 4,5}
print(set_1)
print(set_2)
print(set_3)
- 元素添加与删除:集合支持增删改查,同时里面的元素会自动去重复。
# 初始化一个空集合
my_set = set()
# 添加元素
my_set.add(1) # {1}
my_set.add(2) # {1, 2}
my_set.add(3) # {1, 2, 3}
# 删除元素
my_set.remove(2) # {1, 3}
print(my_set)
- 集合的交集、并集与差集:使用集合完成数学当中的集合运算。
# 定义两个集合
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
# 交集运算
intersection = set1.intersection(set2)
# 或者
# intersection = set1 & set2
print(f"交集: {intersection}")
# 并集运算
union = set1.union(set2)
# 或者
# union = set1 | set2
print(f"并集: {union}")
# 差集运算
difference1 = set1.difference(set2)
# 或者
# difference1 = set1 - set2
print(f"set1 和 set2 的差集: {difference1}")
difference2 = set2.difference(set1)
# 或者
# difference2 = set2 - set1
print(f"set2 和 set1 的差集: {difference2}")
6.字符串
- 字符串索引
# 示例字符串
string = "this_is_a_file.jpg"
# 获取字符串的第2到第5个字符(索引从0开始)
substring = string[1:5] # 结果: "his_"
print(substring)
# 获取字符串的第2到最后一个字符
substring = string[1:] # 结果: "his_is_a_file.jpg"
print(substring)
# 获取字符串的开始到第5个字符
substring = string[:5] # 结果: "this_"
print(substring)
# 获取整个字符串
substring = string[:] # 结果: "this_is_a_file.jpg"
print(substring)
# 获取字符串的最后3个字符
substring = string[-3:] # 结果: "jpg"
print(substring)
# 获取字符串的第2到倒数第3个字符,每隔2个字符取一个
substring = string[1:-2:2] # 结果: "hsi__iej"
print(substring)
# 反转字符串
substring = string[::-1] # 结果: "gpj.elif_a_si_siht"
print(substring)
- 字符串比较
# 定义两个字符串
string1 = "Hello"
string2 = "hello"
string3 = "Hello"
# 使用 == 操作符比较字符串
is_equal = string1 == string2 # 结果: False
print(f"string1 is equal to string2: {is_equal}")
is_equal = string1 == string3 # 结果: True
print(f"string1 is equal to string3: {is_equal}")
# 使用 != 操作符比较字符串
is_not_equal = string1 != string2 # 结果: True
print(f"string1 is not equal to string2: {is_not_equal}")
# 使用 <, > 操作符比较字符串(基于字典顺序)
is_less_than = string1 < string2 # 结果: True (因为大写字母在字典顺序中排在小写字母之前)
print(f"string1 is less than string2: {is_less_than}")
# 不区分大小写的字符串比较
is_equal_ignore_case = string1.lower() == string2.lower() # 结果: True
print(f"string1 is equal to string2 (ignore case): {is_equal_ignore_case}")
4. python函数、模块,文件与文件夹操作
1.函数
- 函数:参数传递、函数返回值、变量作用域、 匿名函数。
- 参数传递:
1)形参与实参
# 形参是函数定义时的参数,实参是函数调用时的参数
def create_model(layers, units): # layers和units是形参
print(f"Creating a model with {layers} layers and {units} units in each layer.")
# 调用函数
create_model(3, 128) # 3和128是实参
2)位置参数
# 位置参数的顺序很重要
def create_model(layers, units):
print(f"Creating a model with {layers} layers and {units} units in each layer.")
# 调用函数
create_model(3, 128)
create_model(128, 3)
3)关键字参数
# 使用关键字参数调用函数
def create_model(layers, units):
print(f"Creating a model with {layers} layers and {units} units in each layer.")
# 调用函数
create_model(units=128, layers=3) # 使用关键字参数,顺序不重要
create_model(layers=3, units=128)
4)默认参数
# 使用默认参数值
def create_model(layers=3, units=128):
print(f"Creating a model with {layers} layers and {units} units in each layer.")
# 调用函数
create_model() # 使用默认值
5)可变参数
# 使用可变参数接收多个参数值
def add_layers(model, *layers):
for layer in layers:
print(f"Adding layer {layer} to model {model}.")
# 调用函数
add_layers("Model1", "conv", "relu", "softmax")
- 函数返回值:通过 return 返回。
# 函数返回模型的信息
def create_model(layers, units):
info = f"Creating a model with {layers} layers and {units} units in each layer."
return info
# 调用函数
model_info = create_model(3, 128)
print(model_info)
- 变量作用域:
1)全局变量
# 全局变量
MODEL_NAME = "CNN"
def print_model_name():
print(f"The model name is {MODEL_NAME}.")
# 调用函数
print_model_name()
2)局部变量
# 局部变量
def create_model():
model_name = "RNN" # 局部变量
print(f"Creating a model named {model_name}.")
# 调用函数
create_model()
print(model_name) # 此行代码会报错
- 匿名函数:冒号前面是输入,冒号后面是输出。
# 使用lambda创建匿名函数
calculate_units = lambda layers: layers * 128
# 调用函数
units = calculate_units(3)
print(f"Total units: {units}")
2.模块
- 模块:
1)使用 pip list 查看已安装的模块
2)使用 pip install 安装想要的模块,安装时可以指定想要安装的版本
3)使用 import 导入模块
4)如果模块名很长,可以用 import … as … 给模块起一个别名
5)from .py名 import */add:导入.py的所有方法/add方法。
3.文件与文件夹操作
- 文件操作
1)复制单个文件
import shutil
file_1_loc = './resources/保存目录1/fire.jpg'
file_1_save_loc = './resources/保存目录2/fire_copy.jpg'
shutil.copyfile(file_1_loc, file_1_save_loc)
2) 复制多个文件
import shutil
# 源目录和目标目录
src = 'resources/fire_yolo_format'
dst = 'resources/fire_yolo_format_new'
# 使用copytree复制目录
shutil.copytree(src, dst)
print(f"Directory copied from {src} to {dst}")
#还可以复制时忽略特定格式
import shutil
# 源目录和目标目录
src = 'resources/fire_yolo_format'
dst = 'resources/fire_yolo_format_new_2'
# 使用copytree复制目录
shutil.copytree(src, dst, ignore=shutil.ignore_patterns("*.txt"))
print(f"Directory copied from {src} to {dst}")
3)移动文件
import shutil
file_1_loc = './resources/保存目录1/fire_label.txt'
file_1_save_loc = './resources/保存目录2/fire_label.txt'
shutil.move(file_1_loc, file_1_save_loc)
4)删除文件
import os
file_loc = r'./resources/保存目录1/fire.jpg'
os.remove(file_loc)
- 文件夹操作
1)创建文件夹
#文件或文件夹是否已经存在 os.path.exists
#创建一级文件夹
import os
dir_name = "my_dir"
if os.path.exists(dir_name):
print("文件夹已经存在!")
else:
os.mkdir(dir_name)
print("文件夹已经创建完毕!")
#创建多级文件夹
import os
os.makedirs("my_dir_1\\my_dir_2\\my_dir_3")
2)遍历文件夹
#路径拼接 os.path.join
#路径遍历 os.walk
import os
root_dir = "dir_loc"
file_full_path_list = []
# os.walk():函数用于遍历一个目录及其所有子目录,并可以生成一个包含每个目录路径、
# 该目录下所有文件夹的名称和该目录下所有文件的名称的迭代器。(对文件夹进行遍历)
for root, dirs, files in os.walk(root_dir):
for file_i in files:
file_i_full_path = os.path.join(root, file_i)
file_full_path_list.append(file_i_full_path)
print(file_full_path_list)
3)删除空白文件夹
#os.rmdir 只能删除空的文件夹
import os
dir_path = 'my_dir'
if os.path.exists(dir_path):
print("删除文件夹"+dir_path)
os.rmdir('my_dir')
print("删除完成")
else:
print("文件夹"+dir_path+"不存在")
4)删除非空文件夹
import os
import shutil
dir_name = "my_dir"
if os.path.exists(dir_name):
shutil.rmtree(dir_name) # 文件夹里有东西也一并删除
print("文件夹已经删除!")
else:
os.mkdir(dir_name)
print("文件夹不存在!")
4.综合案例
- YOLO标注文件清洗
训练一个人工智能算法需要一个庞大的数据集,这个数据集需要进行人为标注。但由于出现意外,造成部分数据丢失,使得标注文件和图片文件的文件名前缀不能一一对应。需要写一段代码,将可以文件名前缀一一对应的文件保存到一个新的文件夹中,以完成数据的清洗。
# 文件清洗
# 将 'resources/fire_yolo_format' 当中标签名和图片名匹配的文件,按原排放顺序保存到新的文件夹 'resources/clean_data'
# 需要用代码创建文件夹
import os
import shutil
def get_files(root_path):
file_full_path_list = []
file_name_list = []
for root, dirs, files in os.walk(root_path):
for file_i in files:
file_i_full_path = os.path.join(root, file_i)
file_full_path_list.append(file_i_full_path)
file_name_list.append(os.path.splitext(file_i)[0]) # 使用os.path.splitext获取文件名
return file_full_path_list, file_name_list
root_path_from = r'resources/fire_yolo_format'
root_path_save = r'resources/clean_data'
root_images_from = os.path.join(root_path_from, 'images')
root_labels_from = os.path.join(root_path_from, 'labels')
root_images_save = os.path.join(root_path_save, 'images')
root_labels_save = os.path.join(root_path_save, 'labels')
# 创建保存的文件夹
for dir_path in [root_images_save, root_labels_save]:
if not os.path.exists(dir_path):
os.makedirs(dir_path)
image_file_full_path_list, image_file_name_list = get_files(root_images_from)
labels_file_full_path_list, labels_file_name_list = get_files(root_labels_from)
intersection_set = set(image_file_name_list) & set(labels_file_name_list)
# 复制交集中的文件到新的文件夹
for file_name in intersection_set:
image_index = image_file_name_list.index(file_name)
label_index = labels_file_name_list.index(file_name)
shutil.copy(image_file_full_path_list[image_index], root_images_save)
shutil.copy(labels_file_full_path_list[label_index], root_labels_save)















 672
672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









