1.机器学习
1.机器学习理论&常见任务
1. 机器学习特征
- 什么是特征:事物可供识别的特殊的征象或标志。
- 典型的图像特征:常用的特征有:Harris角点特征,Canny边缘特征,直方图特征等。
- 典型的文本特征:常用的特征有:词属性,词频TF-IDF,词向量,Bag of Words等。
- 机器学习数据库:
1)UCI:UCI数据库是加州大学欧文分校(University of CaliforniaIrvine)提出的
数据库,目前共有585个数据集,其数目还在不断增加。
2)Iris数据库:可能是模式识别文献中最著名的数据库,数据集包含3个类,每个类有50个实例,每个类指的是一种鸢尾植物。
3)Adult数据库:从人口普查数据库中抽取,使用以下条件进行提取:(AAGE>16) &&
(AGI>100) && (AFNLWGT>1)&& (HRSWK>0)。 - 什么是特征编码:任务拿到的初始数据通常比较脏乱,可能会带有各种非数字特殊符号,
需要将其转换为可计算的数字,采用编码量化等方法。
常见的编码方式有:序号编码、独热编码、标签编码、频数编码等。
1)序号编码:序号编码(Ordinal Encoding),通常用于处理类别间具有内在大小顺序关系的数据,对于一个具有m个类别的特征,可以将其对应地映射到[0,m-1] 的整数。
2)独热编码:独热编码(one-hot encoding),又称一位有效编码,使用N位状态向量对N个状态进行编码,每个状态都有独立的位置,并且只有一位有效。 - 什么是特征选择:原始未经过滤过的特征可能包含很多无关特征,不同特征对问题的贡献
大小程度也不相同,往往需要选取一个包含重要信息的特征子集。
常见的特征选择方法:过滤式方法、包裹式方法、嵌入式方法。
1)过滤式特征选择方法:先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续
训练无关。
方差选择法:计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征
相关系数法:计算各个特征对目标值的相关系数
卡方检验法:检验自变量对因变量的相关性。假设自变量有N种取值,因变量
有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距
2)包裹式特征选择方法:直接以最终学习器的性能作为特征子集的评价准则,目的是为给定学
习器选择最有利于其性能的特征子集。
递归特征消除法:使用一个基模型进行多轮训练,每轮训练后,根据权值系数消除若干特征,再基于新的特征集进行下一轮训练。
3)嵌入式特征选择方法:将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程
中完成。
基于惩罚项的特征选择法:使用L1等惩罚项对不同维度的特征进行惩罚,除了筛选出特征外,也进行了降维。
基于树模型的特征选择法:使用决策树、随机森林、Boosting、XGBoost等算法进行特征选择。
2.机器学习模型种类
- 常见的机器学习问题分类:有监督学习、无监督学习、半监督与弱监督学习 、强化学习。
- 有监督学习模型:经典的有监督机器学习模型包括分类与回归模型。
分类 :线性判别分析(LDA) 、逻辑回归、贝叶斯分类器 、K近邻、感知器、决策树、随机森林、支撑向量机(SVM) 、Adaboost 。
回归:线性回归、局部加权回归、套索回归、K近邻回归、弹性网络回归、回归树、岭回归、支撑向量回归(SVR)、多项式回归。 - 分类任务:将物理或抽象对象的集合分成多个不同的指定类别,标签为离散类别数值。
- 回归任务: 将输入的数据拟合成连续的输出结果,标签为连续数值。
- 无监督学习模型:经典的无监督机器学习模型包括降维、聚类与生成模型。
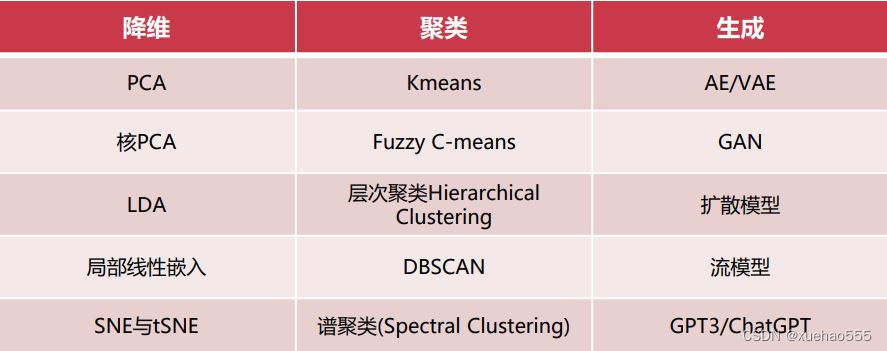 降维任务:采用某种映射方法,将原高维空间中的数据点映射到低维度空间中,对特征进行降维与可视化。
降维任务:采用某种映射方法,将原高维空间中的数据点映射到低维度空间中,对特征进行降维与可视化。
聚类任务:将集合分成由类似的对象组成的多个类的过程,是分类问题,但没有训练过程。
生成任务:估计特定集合的概率密度函数,生成高质量文本、图像、语音、代码等数据。
2. 评估目标与优化目标
1. 机器学习评估指标
- 样本集划分: 训练集,验证集,测试集3个不相交的子集。以训练集训练模型;以验证集评估模型,寻找最佳的参数;以测试集测试模型一次,其误差近似为泛化误差。
- N折交叉验证技术:将样本集均匀的分成N份,轮流用其中的N-1份作为训练集,剩下的
1份作为测试集。 - 什么是评测指标:机器学习算法的性能评测指标用于衡量算法的优劣,作为各种方法比较的基准,指导我们对模型进行选择与优化。
- 两类常见的评测指标: 分类任务评测指标与回归任务评测指标。
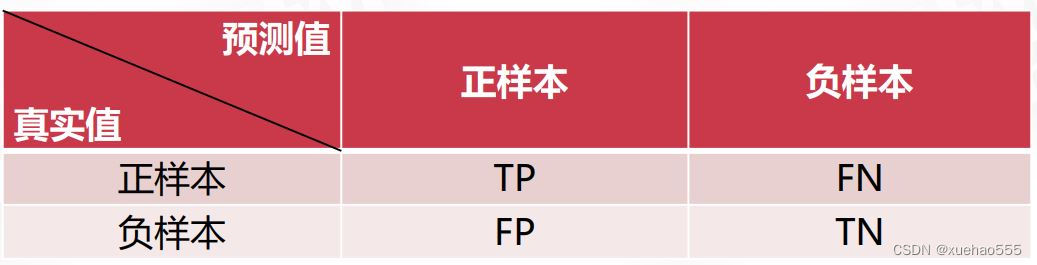
- 正负样本划分:
标签为正样本,分类为正样本的数目为True Positive,简称TP。
标签为正样本,分类为负样本的数目为False Negative,简称FN。
标签为负样本,分类为正样本的数目为False Positive,简称FP。
标签为负样本,分类为负样本的数目为True Negative,简称TN。
- 准确率,精度,召回率计算:
准确率:Accuracy(TP+TN)/(TP+FP+TN+FN),被判定为正样本的测试样本中,真正的正样本所占的比例。
正样本精度:Precision=TP/(TP+FP),召回的正样本中有多少是真正的正样本。
正样本召回率:Recall=TP/(TP+FN),被判定为正样本的正样本占所有正样本的比例。 - PR曲线和F1 score:精度与召回率是一对相互矛盾的指标,对正负样本不均衡问题敏感。
PR曲线:随着召回率增加,精度下降曲线与坐标值面积越大,性能越好。
F1 score综合考虑了精度与召回率,其值越大则模型越好:F1=(2PR)/(P+R)。 - ROC曲线:分类算法在不同假阳率下对应的真阳率。
假阳率false positive rate(FPR):FPR=FP/(FP+TN)
负样本被分类器判定为正样本的比例。
真阳率true positive rate(TPR):TPR=TP/(TP+FN)
正样本被分类器判定为正样本的比例。
正负样本的分布比例变化时,ROC曲线保持不变,对正负样本不均衡问题不敏感,PR曲线不能。 - AUC:AUC(Area Under Curve)为ROC曲线下的面积,表示随机挑选一个正样本以及一个负样本,分类器会对正样本给出的预测值高于负样
本的概率。 - 混淆矩阵:对于k分类问题,混淆矩阵为k × k的矩阵,元素cij表示第i类样本被分类器判定为第j类的数量。
主对角线的元素之和为正确分类的样本数,其他元素之和为错误分类的样本数。对角线的值越大,分类器准确率越高; - IoU: IoU(Intersection over Union),边界框/掩膜正确性的度量指标。AUB/A并B。
- PSNR:Peak Signal to NoiseRatio,有真值参考的质量评估指标,在信号处理领域被广泛使用,计算复杂度小。
2.机器学习优化目标
- 优化目标:机器学习用有限训练集上的期望损失作为优化目标(即代理损失函数loss function),损失代表预测值f(x)与真实值Y的不一致程度。
一般损失函数越小,模型的性能就越好,观察训练集和测试集的误差就能知道模型的收敛情况,估计模型的性能。 - 过拟合与欠拟合状态:模型在训练集和测试集上的不同表现。
 欠拟合(under-fitting)也称为欠学习,指模型在训练集上精度差。
欠拟合(under-fitting)也称为欠学习,指模型在训练集上精度差。
过拟合(over-fitting)也称为过学习,指模型在训练集上精度高,但
在测试集上精度低,泛化性能差。 - 过拟合的原因:模型过大,数据太少。模型本身过于复杂,拟合了训练样本集中的噪声 。训练样本太少或者缺乏代表性。
- 两类常见的优化目标:分类任务优化目标与回归任务优化目标。

- 常见优化目标
分类任务
1)0-1损失:只看分类的对与错,当标签与预测类别相等时,损失为0,否则为1。真实的优化目标,但是无法求导和优化,只有理论意义。
2)熵与交叉熵(cross entropy):熵表示热力学系统的无序程度,在信息学中用于表示信息多少,不确定性越大,概率越低,则信息越多,熵越高。
熵函数是概率的单调递减的函数,概率越低,熵越高。
3)交叉熵损失(cross entropy loss):衡量两个概率分布的相似性。
4)Softmax loss:交叉熵损失(cross entropy loss)与softmax loss,𝑙 (𝑓, 𝑦 )是softmax loss,为交叉熵的特例。
回归任务
5)L1 Loss:L1损失即Mean absolute loss(MAE loss) ,以绝对误差作为距离。主要问题:梯度在零点不平滑。
6)L1/L2-loss:L2损失即Mean Squared Loss(MSE loss),也被称为欧氏距离,以误差的平方和作为距离。
当预测值与目标值相差很大(异常值)时, 梯度容易爆炸,因为梯度里有两者差值。
7)Smooth L1 loss:解决L1 loss梯度不平滑,L2 loss梯度爆炸的问题。
在x比较小时,等价于L2 loss,保持平滑。
在x比较大时,等价于L1 loss,可以限制数值的大小。
3.逻辑回归
1.逻辑回归原理
- 逻辑回归模型: 又被称为对数回归模型,实际上是一种二分类算法,从一个样本的特征向量x,预测出它是正样本的概率值p(y=1|x)。
- logistic函数是一种sigmoid函数(S函数)。
- 如何使用逻辑回归模型进行分类:对数似然比,样本属于正样本和负样本概率值比的对数。如果属于正样本的概率大于负样本的概率则样本被判定为正样本,即
w
T
x
>
0
w^Tx>0
wTx>0
- sklearn机器学习库:一个著名的Python机器学习库,实现了绝大多数经典机器学习算法。
- 安装命令:pip install scikit-learn。
- 逻辑回归模型:
import numpy as np
import matplotlib.pyplot as plt
import sys
from sklearn.linear_model import LogisticRegression
lines = open('iris.txt').readlines()
x_features = []
y_label = []
table = {"setosa":0,"versicolor":1,"virginica":2}
for i in range(1,len(lines)):
line = lines[i].strip().split(' ')
feature = line[1:-1]
label = table[str(line[-1].split('\"')[1])]
x_features.append(feature)
y_label.append(label)
lr_clf = LogisticRegression()
lr_clf = lr_clf.fit(x_features, y_label)
print('the weight of Logistic Regression:',lr_clf.coef_)
print('the intercept(w0) of Logistic Regression:',lr_clf.intercept_)























 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









