







目录
3.2 什么叫 有统计学意义? (一般= p概率很小= 拒绝原假设h0)
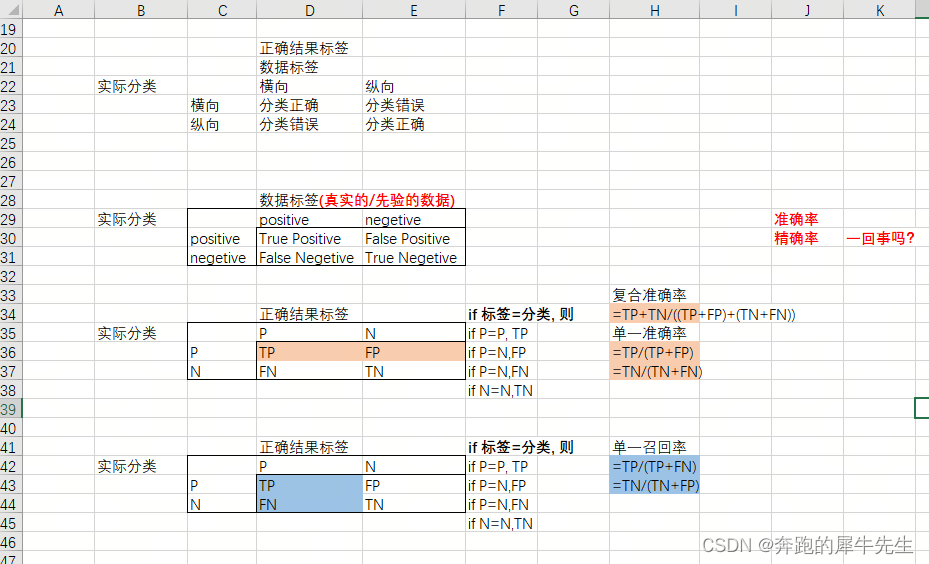
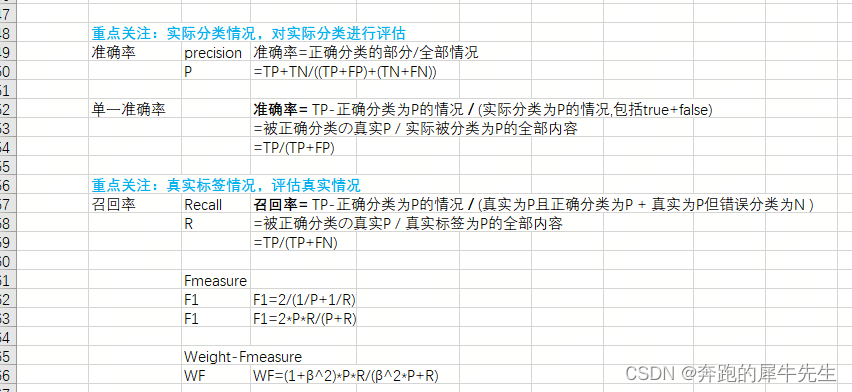
4.2.3 和机器学习理的准确率,召唤率虽然很像,但是不是一回事。
5.3 相比自然语言,根据第一类弃真概率更重要这个原则来设计一些检验,特别是有价值判断的那些
5.3.2 所以我从这些例子总结:做假设检验时需要根据第一类弃真概率更重要这个原则来设计,尤其是有价值判断的时候
前言:
之前想直接跳过这些基础知识,直接学习F检验,Z检验,T检验之类的,但是过程中发现自己很多内容,理解的很偏颇,这些基础知识很重要。现在回头来补习。
目标
- 关于假设检验的各种基础知识
- 理解假设检验的反证法
- H0是怎么设计的
- 什么时候用单侧检验或双侧检验
1 什么叫假设检验
1.1 假设检验的定义
- 假设检验(hypothesis testing),又称统计假设检验,是用来判断样本与样本、样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。
- 显著性检验是假设检验中最常用的一种方法,也是一种最基本的统计推断形式,其基本原理是先对总体的特征做出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受做出推断。
- 一般是小样本下的
- 因为很难普查知道总体分布,先定性假设总体符合某一种分布。
- 试图用样本的分布数据去推断整体的分布“参数”的具体数值。
1.1.1 来自百度百科
- 假设检验,也称为统计假设检验,是一种统计推断方法,其目的是根据样本数据对总体做出推断。
- 假设检验的基本思想是先对总体的某个特征(如总体参数)提出一个假设,然后利用样本数据来检验这个假设是否合理。
- 如果样本数据表明假设不合理,则可以拒绝这个假设;如果样本数据表明假设合理,则可以接受这个假设。
- 这个过程基于“小概率事件”原理,认为如果一个事件发生的概率很小,那么这个事件在一次试验中几乎不可能发生。
- 因此,如果样本数据表明 原假设不成立,则这个假设可以被认为是“小概率事件”,不应该被接受。相反,如果样本数据表明原假设成立,则这个假设可以被认为是一个“大概率事件”,应该被接受。
- 假设检验的步骤通常分为以下三个阶段:
- 核心都是针对原假设,备择假设因为不好证明,才去用反证法去判断好判断的原假设
- 提出假设。这包括一个原假设(通常用H0表示)和一个备择假设(通常用H1表示)。原假设通常是我们要检验的假设,而备择假设则是如果原假设不成立时所接受的假设。
- 计算统计量。根据样本数据计算一个统计量,这个统计量可以用来衡量样本数据与假设之间的差异。常用的统计量包括t统计量、z统计量和卡方统计量等。
- 判断假设是否合理。根据统计量的值和对应的p值来判断假设是否合理。如果p值小于预先设定的显著性水平(如0.05),则可以拒绝假设;否则,可以接受假设。

1.1.2 维基百科
1.2 假设检验的最底层逻辑:是反证法思想
换句话说,备择假设通常才是研究者最想证明的。因此才使用反证法
假设检验也就是反证法思想,想证明这个H1对,那么只要证明H0错误就可以了。
一般统计学默认潜规则就是: 验证者都是想(预期)证明H1是对的,通过反证法故意希望去证明H0是错的
(当然结果不一定能达到预期,但是证明h0是否是对的,比证明h1是否是对的更容易是一定的!)
- 如果确实证明H0大概率(如1-α=95%)是对的,就接受H0,承认自己最初构想H1是错的
- 如果确实证明H0只有小概率如 1%是对的,那么就拒绝H0,证明了自己最初构想H1是对的。
1.3 假设检验的底层构造:小概率反证法思想
假设检验----底层思想是反证法思想,而且是小概率反证法思想
小概率思想是指小概率事件(P<0.01或P<0.05或0.1)在一次试验中基本上不会发生。
反之:大概率是不是一定发生呢?好确定吗?这个是个问题,估计前者好判定,后者难。
- 在原假设的前提下,如果在一次观察中小概率事件发生了,则认为假设不成立,
- 反之,如果小概率事件没有发生,则没有理由否定原假设。
2 什么叫反证法
2.1 反证法的概念
2.1.1 来自百度百科
- 反证法,亦称“逆证”,是间接论证的方法之一,是通过断定与论题相矛盾的判断(即反论题)的虚假来确立论题的真实性的论证方法。
- 反证法的论证过程如下:首先提出论题:然后设定反论题,并依据推理规则进行推演,证明反论题的虚假;最后根据排中律,既然反论题为假,原论题便是真的。
- 在进行反证中,只有与论题相矛盾的判断才能作为反论题,论题的反对判断是不能作为反论题的,因为具有反对关系的两个判断可以同时为假。
- 反证法中的重要环节是确定反论题的虚假,常常要使用归谬法。
- 反证法是一种有效的解释方法,特别是在进行正面的直接论证或反驳比较困难时,用反证法会收到更好的效果。
2.2.2 维基百科
2.2 别名
- 反证法
- 背理法
2.3 相近概念
- 反正法是间接证明法之一
- 归谬法:反证法与归谬法相似,但归谬法不仅包括推理出矛盾结果,也包括推理出不符事实的结果或显然荒谬不可信的结果
- 归谬法(拉丁语:Reductio ad absurdum)是一种论证方式。首先归就是顺着他的意思,谬就是反驳错误的。
- 归谬法与反证法相似,差别在于反证法只限于推理出逻辑上矛盾的结果
2.4 为什么要用反证法
也就是反证法思想,想证明这个H1对,如果证明H1对有点麻烦,那么只要证明H0错误就可以了(有时候反而更简单)。比如一般情况下,证明两者相等比证明不相等更简单。
- 直接证明比较困难的时候
- 加强说服力,如果矛盾事件是错误的,那么更显得这个说法更有说服力
- ..等等
2.5 反证法的内核
2.5.1 国内的一个文章
感觉有点道理,但是实际推了下不如 维基百科的推导更好理解,可能是我学艺不精 ^ ^
百度安全验证![]() https://baijiahao.baidu.com/s?id=1779622576482381633&wfr=spider&for=pc
https://baijiahao.baidu.com/s?id=1779622576482381633&wfr=spider&for=pc


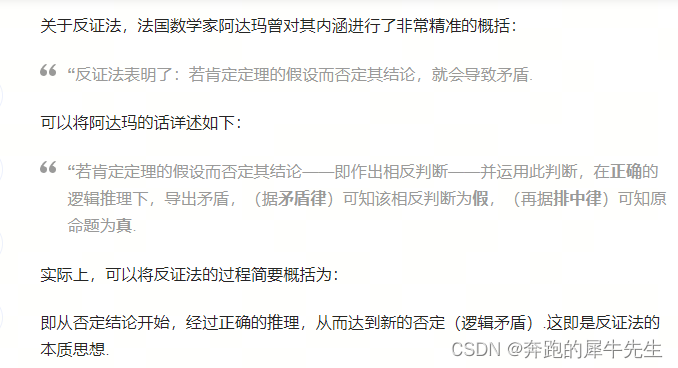
2.5.2 维基百科的反证法逻辑内核
1.7 用反证法的内核 梳理一遍假设检验的逻辑
- 我们想证明H1是对的 (但是直接证明h1有点难) →
- 我们找到H1的矛盾假设H0 →
- 我们先假设H0是对的 →从H0经过逻辑推导 →得到一个错误结论
- →根据否定后件律(我自己试了下这里用否定后见律才能推通顺,用矛盾律推导不通),如果我们推论过程符合逻辑是对的,我们从一个假设为正确的假设,推出结论却是错的,这样就前后矛盾了,因为假设真+推导正确=结论应该真,现在结论不真,只能反推假设
- →而根据排中律,如果H0是对的,那么和H0矛盾的H1,不能也是错的,因此H1是对的。
3 原假设和备择假设
3.1 原假设和备择假设
做假设检验时会设置两个假设:
- 一种叫原假设,也叫零假设,用H0表示。
- 原假设一般是统计者想要拒绝的假设。
H0 原假设的设置一般为:某个值等于多少
- 另外一种叫备择假设,用H1表示。
- 备则假设是统计者想要接受的假设。
- 也就是反证法思想,想证明这个H1对,那么只要证明H0错误就可以了.
H1 备择假设的设置一般为:某个值不等于、大于或者小于多少。
3.2 什么叫 有统计学意义? (一般= p概率很小= 拒绝原假设h0)
- 一句话:就是在统计学上来说是两者得差异是有意义的,显著的。但不一定就是实际情况 结果可能有5%或1%的可能是由误差导致
- 在统计学中,有统计学意义的结果意味着经过适当的统计分析后,某个观察到的效应不是由于偶然因素所造成的。
- 换句话说,有统计学意义的结果意味着在置信水平和误差范围内,观察到的效应真实存在,而不仅仅是由抽样误差或其他随机因素所造成的。
- 然而,需要注意的是,有统计学意义并不一定意味着观察到的效应是真实存在的。在许多情况下,我们需要进行进一步的验证和研究来确认观察到的效应是否真实存在。
3.3 有统计学意义和实际有意义不是一回事
- 比如在显著度/置信区间5%, F检验拒绝了原假设
- 但是还是有α=5%等概率并不是,有可能是随机误差造成的。也就是第一类错误。
- 所以,统计学有意义只能说,大概率是(假设模型本身都正确的前提下)
- 而实际有意义是一定是 100%是,两者不能等同。
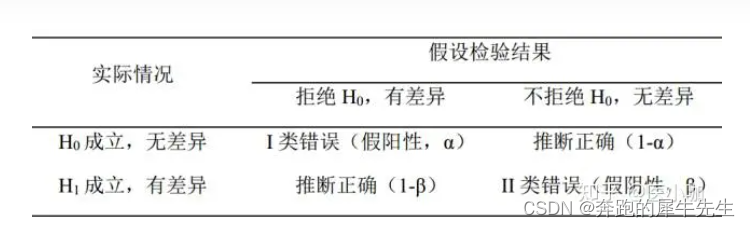
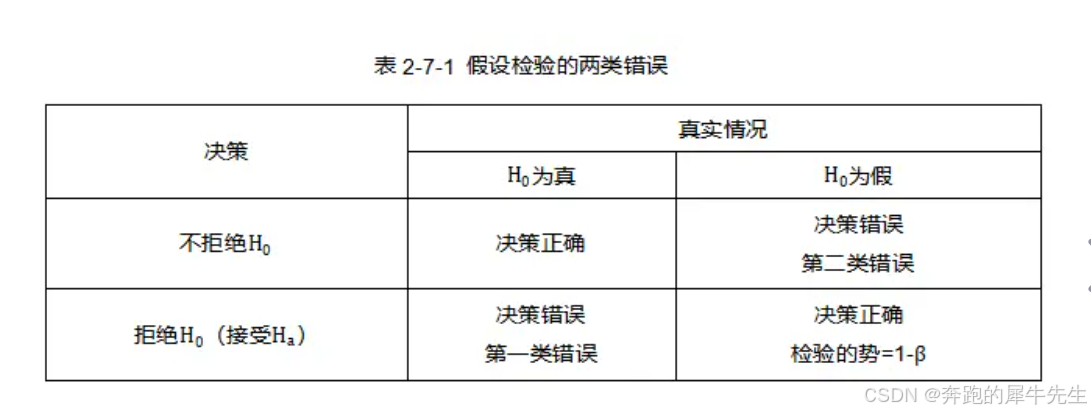
4 两类错误
4.1 2类错误
- 但是在检验的过程中,我们通过样本数据来判断总体参数的假设是否成立,但样本是随机的,因而有可能出现小概率的错误。这种错误分两种,一种是弃真错误,另一种是取伪错误。
4.1.1 第1类错误
- 弃真错误也叫第I类错误或α错误:它是指原假设实际上是真的,但通过样本估计总体后,拒绝了原假设。明显这是错误的,我们拒绝了真实的原假设,所以叫弃真错误,这个错误的概率我们记为α。
4.1.2 第2类错误
- 取伪错误也叫第II类错误或β错误:它是指原假设实际上假的,但通过样本估计总体后,接受了原假设,这个错误的概率我们记为β。
4.2 这两类错误的计算公式
4.2.1 计算公式
- 第1类错误 / 弃真错误 / 假阳性:
- 其概率p=α
- 第2类错误/ 取伪错误 / 假阴性:
- 其概率p=β

4.2.2 下面这个医学图来源
- 他们假设h0是阴性,而H1成立是阳性
- 和我画的图,横轴,纵轴是相反的
- 一般的医学的假设检验理
- h0阴性正常, 相等正常普通等标签 ( 和其他统计喜欢假设H0相等一个意思)
- h1阳性不正常
问题1
医学的假设检验,经常是把阴性(阴性/ 不是/ 无效果 /否)等作为H0假设,这没错
- 所以本来TT的地方,会写成假阳性,这个地方要注意,注意日常语言的混淆
- 要是避免错误,反正叫成TT,true-true 不会引起什么误解的。
- 国内的文字翻译滥用确实是个学习障碍。
问题2:
小心这个矩阵表格的两种写法差异,别看错
- 一种是,横轴是实际情况标签,纵轴是检验结果
- 一种是,横轴是检验结果,纵轴是实际情况标签
4.2.3 和机器学习理的准确率,召唤率虽然很像,但是不是一回事。
4.2.4 第1类错误和第2类错误谁更重要?
理论上,自然希望犯这两类错误的概率都很小。当样本容量n固定时,α、β不能同时都小,即α变小时,β就变大;而β变小时,α就变大。
一般只有当样本容量n增大时,才有可能使两者变小。
在实际应用中,一般原则是:控制犯第一类错误的概率,即给定α,然后通过增大样本容量n来减小B。这种着重对第一类错误的概率α加以控制的假设检验称为显著性检验。
举例有这样3个假设检验
- 假设X1,X2两个样本的方差相同,实际希望方差不同。
- 假设一种药没有效果H0,实际希望有效果
- 用一个试剂去检查某人群,假设H0是阴性(药物不起作用),实际希望是阳性
- 这里的阴性是指(药物不起作用)
如果我们假设检验后,发现得到的概率p很小,要拒绝H0
(但开了上帝视角的我们实际发现我们的假设检验结果是错的,那会如何呢?)
- X1,X2 确实来自一个总体,但是因为假设检验,被我们认为来自不同的整体
- 假设我们确实知道真实的情况!
- 新药真实标签没有效果
- 这个人真实标签是阴性
- 这个新药真实标签没有效果(h0正确),但是因为假设检验认为H0错了,被我们认为药物有用,这就犯了1类错误
- 这个人真实标签是阴性(h0正确),但是因为假设检验认为H0错了,被我们认为此人是个阳性,这就犯了1类错误
这么看起来,第1类错误,比第2类错误更危险
- 第1类错误 =弃真错误 =TF/(TT+FT)
- 第2类错误 =取伪错误 =FT/(FF+TF)
- 注:TT,TF的写法为 前:数据的真实标签/ 后:数据的检测判断
所以我们主要目标是减少第1类错误α的概率!如果只能选1个的话
注意语言混淆:
α= FT/(TT+FT) !=假阳性 !=错杀好人?
β= TF/(FF+TF) !=假阴性 !=错杀好人?
第1类错误更重要吗? 这是我全文的基础,如果不是,我写的就有问题
- 第一类错误是不该拒绝结果拒绝了,弃真,reject the null when it is true.
- 第二类错误是应该拒绝结果没拒绝,取伪accept the null when it is false.
一种说法
在AB测试中,第一类错误是指拒绝了一个实际上是真实的假设,而第二类错误是指接受了一个实际上是错误的假设。在AB测试中,第一类错误是更为严重的错误,因为它会导致我们错误地认为一种变化是有效的,从而采取错误的行动。而第二类错误则意味着我们可能会错过一些真正有效的变化,但这种错误相对来说不太严重,因为我们可以在以后的测试中发现并纠正这些错误。因此,在AB测试中,更应该关注第一类错误。
相反说法
我觉得应该是第二类错误吧。第一类错误是弃真,就是拒绝正确零假设,可以理解成A和B没有差别,但是你认为有差别选择了其中一个,这个从业务上来说问题不大,反正没差别也不会影响收益,最多增加迭代成本。第二类取伪,就是AB有差别,你认为没差别,放弃迭代,如果迭代之后是更优的,那从业务上来说会影响后面不少收益。具体还是要看迭代成本和迭代可能收益,不过一般来看未来长期的收益应该比短期的迭代成本要重要,所以我倾向于第二类错误。一家之言,仅供参考。。。
Ai回答:第1类错误和第2类错误的严重性取决于具体的研究场景和后果,无法一概而论。 在某些情况下,第1类错误可能更为严重,因为它会导致错误的结论和行动,可能对人们的生命、健康或资源产生负面影响。在其他情况下,第2类错误可能更为严重,因为它可能导致错失重要的发现和进展,使我们无法获得有价值的信息12。
第1类错误(Type I error)是拒绝了真实的原假设,即错误地认为存在效应或差异。这可能导致错误的结论和决策,浪费资源和时间。在某些情况下,第1类错误可能带来严重的后果,例如在医学领域中,错误地认为一种治疗方法有效可能导致患者接受不必要的治疗或药物副作用13。
第2类错误(Type II error)是接受了错误的原假设,即未能发现实际存在的效应或差异。这可能导致错失重要的发现和机会,延误进一步的研究或采取必要的措施。在某些情况下,第2类错误可能带来严重的后果,例如在医学领域中,未能发现一种有效的治疗方法可能导致患者无法获得适当的治疗13。
问题写错了把?下面答题的人也真是瞎起劲。。。
第一类错误根本无法避免,因为第一类错误的概率就是显著性水平,你会用显著性水平为零的test吗?一般你都会选择一个显著性水平把?比如5%、1%,不管你选择多少,肯定是大于零的,这就意味着第一类错误是可以发生的,发生概率就是你选择的显著性水平,这和你换个test没有关系。
真正可控的是第二类错误,为了尽量阻止第二类错误发生(其实也不能避免),如果你有两个或者两个以上的不同tests可以选择,你会倾向于选择power最大的那个,power越大说明第二类错误发生概率越小。
归纳一下,如果有好几个不同的tests,你选择一个固定的显著性水平,也就是第一个错误发生的概率是固定的,然后选择一个power最好的test,也就是说让第二类错误发生概率尽可能降到最低。
也许有人会问,就不能把显著性水平无限接近于零的降低来达到避免第一类错误吗?根本没人会这么干!因为你的test会一点点power都没有。。。
另外,没有人认为第一类错误更严重。
作者:那罗延
链接:https://www.zhihu.com/question/37437658/answer/519055859
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
感觉这个才是真理解的。。。。。。。。。。。。。。。
很多话题都争论很厉害,其实大家都没理解深刻吧,值得深思
https://www.zhihu.com/question/20993864/answer/81244176
在抽取更多样本以后,样本均值的分布会更集中,也就意味着同样的一个均值,在两个分布中的相对位置已经不一样了,比如原来在95%区间以外,现在已经在99%区间以外了。所以大家在讲到提升样本量可以降低两类错误的时候,锚定的是样本的均值,而非置信度水平

看到某些回答提到“增大样本容量会同时降低一二类错误概率”,居然还一堆人给点赞,真有点莫名其妙。随便翻开任意一本统计学或者数理统计书籍的假设检验章节在谈一类和二类错误的时候都会说:假设检验的一二类错误概率互相制约,不能同时降低。任何一个假设检验,样本容量必然是具体的某个值,比如100,200,1000等,在这个具体的样本容量下,随着你定义的一类错误概率的不同会导致不同的二类错误概率,你大我小,你小我大。基于保护零假设的原则, Neyman-Pearson建议首先确定一个很小的数(即显著性水平),让一类错误概率不超过它(也就是说实际一类错误概率会可能低于显著性水平,因为有些实验我们无法精确计算出它的实际一类错误概率,比如方差分析中进行P值矫正的多重比较方法就无法确切知道其真实整体一类错误概率,但是我们能保证实际一类错误概率低于并接近我们设定的显著性水平,虽然我们不知道实际一类错误概率,但是它是一个确确实实存在的固定值,只是我们暂时不知道而已)这种检验我们把它称为“显著水平为alpha的检验”。看到没,一类错误概率一旦设定,犯一类错误概率就是一个固定值,是一个小于或者等于显著性水平的固定值。
为了叙述的方便,现在假设实际检验犯一类错误概率正好等于显著性水平,下文都基于这个假设来阐述。
样本量100,设定一类错误概率为0.05,会有5%比例检验会犯一类错误;样本量1000,设定一类错误概率为0.05,会有5%比例检验会犯一类错误;样本量10000,设定一类错误概率为0.05,会有5%比例检验会犯一类错误;...。增大样本容量会同时降低一二类错误概率的说法是不是很荒唐。
一类错误概率0.05,意思是:如果零假设为真,做无限次检验(为了方便说明,我假设这个无限次是n。不要和我说无限次不能说成是n,请不要抬杠),会有0.05*n次是拒绝零假设的。每次抽样得到的数据一般不一样,意味着每次抽样做同一个检验得到的检验统计量不一样,做无限次抽样及其检验,就会得到无限个检验统计量,这些检验统计量会有一个分布,我们把它叫做检验统计量的抽样分布。假设检验的拒绝域和P值都是基于这个抽样分布计算得到。设定一类错误概率0.05,意味着我们人为规定了有0.95*n个检验统计量在“接受域”内(抽样分布中“接受域”的概率为95%),有0.05*n个检验统计量在“接受域”外(抽样分布中“拒绝域”概率为5%)。如果P值小于0.05,等同于检验统计量落在了“拒绝域”内(也就是“接受域”外)。很显然,一类错误概率和样本容量无关,不管样本容量为多少,一旦设定一类错误概率0.05,就已经人为把抽样分布分为了接受域(占抽样分布累积概率的95%)和拒绝域(占抽样分布累积概率的5%)两个部分,那么必然会有5%的概率拒绝真实零假设。
真实总体参数和一类错误概率固定的情况下:二类错误概率会随样本容量的增大而降低,样本容量的变小而变大。真实总体参数和样本容量固定的情况下:二类错误概率会随一类错误概率增大而变小,一类错误概率减小而变大。
事实上你永远都无法知道自己犯没犯一类错误或者二类错误,因为,总体参数真实值你是不知道的。既然如此,那么可以首先认为零假设就是真实的,零假设通常来自我们日常生活的经验,接近真实。比如厂家说它的薯片重量是200克,那么这个200克基本就是真实的,因为厂家没有必要撒谎,但是会存在个别无良厂家说产品是200克,其实要低于200克。为了检验厂家是否撒谎,我们会随机抽取不同批次的产品进行测量,然后检验是否接受厂家的说法(零假设):产品重量不低于200克。如果不能拒绝零假设,则认为厂家没有撒谎,如果拒绝了零假设,那么就暂时认为厂家撒谎了。
假设检验倾向于保护零假设,也就是零假设一般很难被拒绝,除非你有非常充分的证据。就像上面例子提到的,一旦我们拒绝了零假设,意味着厂家的产品重量低于200克,则这个厂家有可能直接破产,这是一个非常严重的事件。如果犯二类错误会比犯一类错误导致更严重的灾难,则必须优先关注二类错误,并且你一定要首先确定二类错误的概率和总体参数的范围,然后调整你的样本容量 和/或 一类错误概率。也就是说我们也可以先固定住二类错误概率,让一类错误概率随样本容量而变化。
最后再强调一遍,一类错误概率是人为规定的,一旦规定就不会变(虽然会出现实际一类错误概率小于规定的显著性水平的情况,但它依然是一个确定的固定值,只不过我们不知道它的具体值而已),如果会随样本容量而改变,那你人为去规定有何意义,逗自己玩么!是嫌自己还不够蠢吗!
首先,统计检验的方法有很多,其关键问题是找到一个检验法则(testing rule)使得犯一、二类错误的概率尽可能小。这也就是说,我们需要让功效函数(power function)在被检验参数处于H0H_0 的参数子空间时小,而处于H1H_1的参数子空间时大。不幸的是,在观测量给定的情况下,这两个目标通常无法同时实现。
我们完全可以找一个检验法则使得无论观测到什么数据H0H_0 从来都不被拒绝,此时犯第一类错误的概率为00,但这也意味着犯第二类错误的概率为11;反过来,我们也可以找一个检验法则使得H0H_0 总是被拒绝,此时犯第二类错误的概率为00,但是犯第一类错误的概率为11。正因为如此,我们才会使用一些平衡犯一、二类错误概率的方法。
一种常见的做法是事先给定显著性水平,接着找一个检验使得功效函数在被检验参数处于H1H_1的参数子空间时尽可能大。然而这种检验方法本身定义了我们对待H0H_0 和H1H_1是不平等的,所以并不能作为“某一类错误更有价值”的理由。
事实上,我们也可以采用其他的检验方法,如最小化犯一、二类错误概率的线性组合。这样做的优点是随着观测量的增加我们可以迫使犯一、二类错误的概率同时减小。学过贝叶斯统计检验的人对此应该不会陌生。
第一类容易衡量,显性,第二类难以衡量,隐形,是机会成本。普通人和企业第一类更严重,顶尖人和企业第二类可能更严重。
第二类错误没有第一类错误可怕。因为,如果效应真的存在,随着研究者努力设计出更精巧的实验,采用更敏感的观测值,发现实际存在的效应一般只是时间问题,而不会将整个研究导向错误的道路。
显著性检验中的第一类错误是指:原假设事实上正确,可是检验统计量的观测值却落入拒绝域,因而否定了本来正确的假设.这是弃真的错误.发生第一类错误的概率在双侧检验时是两个尾部的拒绝域面积之和;在单侧检验时是单侧拒绝域的面积.
\x09显著性检验中的第二类错误是指:原假设事实上不正确,而检验统计量的观测值却落入了不能拒绝域,因而没有否定本来不正确的原假设,这是取伪的错误.发生第二类错误的概率是把来自θ=θ1(θ1≠θ0)的总体的样本值代入检验统计量所得结果落入接受域的概率.
根据不同的检验问题,对于和大小的选择有不同的考虑.
在样本容量不变的条件下,犯两类错误的概率常常呈现反向的变化,要使和都同时减小,除非增加样本的容量.在控制犯第一类错误的概率情况下,尽量使犯第二类错误的概率小.在实际问题中,往往把要否定的陈述作为原假设,而把拟采纳的陈述本身作为备择假设,只对犯第一类错误的概率加以限制,而不考虑犯第二类错误的概率.
这就是说,在假设检验中,相对而言,当原假设被拒绝时,能够以较大的把握肯定备择假设的成立.而当原假设未被拒绝时,并不能认为原假设确实成立.
第1类错误和第2类错误的严重性取决于具体的研究场景和后果,无法一概而论。 在某些情况下,第1类错误可能更为严重,因为它会导致错误的结论和行动,可能对人们的生命、健康或资源产生负面影响。在其他情况下,第2类错误可能更为严重,因为它可能导致错失重要的发现和进展,使我们无法获得有价值的信息12。
第1类错误(Type I error)是拒绝了真实的原假设,即错误地认为存在效应或差异。这可能导致错误的结论和决策,浪费资源和时间。在某些情况下,第1类错误可能带来严重的后果,例如在医学领域中,错误地认为一种治疗方法有效可能导致患者接受不必要的治疗或药物副作用13。
第2类错误(Type II error)是接受了错误的原假设,即未能发现实际存在的效应或差异。这可能导致错失重要的发现和机会,延误进一步的研究或采取必要的措施。在某些情况下,第2类错误可能带来严重的后果,例如在医学领域中,未能发现一种有效的治疗方法可能导致患者无法获得适当的治疗13。
第一类错误是不该拒绝结果拒绝了,第二类错误是应该拒绝结果没拒绝

https://www.zhihu.com/question/20993864/answer/81244176
H0是一个空假设,在英文术语表示为null hypothesis,倾向于“没有”“不”的假设。
0假设就是,认为参数是0。两者没有关系,不互相影响,自变量---和因变量,互相不相干
这个例子个人认为不太恰当。原因在于混淆了统计学中第一类和第二类错误的控制问题和我们常说机器学习中,错误代价不均等的问题。这个例子中,判断要控制第一类 还是第二类错误,用的是假定条件,即我们控制哪一类错误是出于哪一类代价更大,这其实是机器学习中错误代价不均等问题。但是统计学中之所以我们首先控制第一类错误的最大原因是,我们可以知道犯第一类错误的概率(或者说可以接受的最大概率),通常是0.05没并且我们可以控制它。而对于第二类错误,我们也可以让它更小,例如加大样本量,但是我们却不能确切知道我们犯第二类错误的概率是多少。
一个去真存伪,四个字概括了
假设任意分布都是类正太分布这种长尾分布,自然分布
去真:对原假设要苛刻,如果低于了设定的显著度α=第1类错误概率,就拒绝h0,即使h0是对的也拒绝,弃真!因为这么低的显著度,宁愿相信是其他的分布中间,而不是这个H0假设分布的尾巴部分。
存伪:
第1类错误是需要控制的目标,能低就低。第一类错误不能高,比如最高5%,那就是可以容忍有5%的样本是低于这个比例的,但是实际测出来的如果更低,入3%<5% 那就绝不接受,拒绝h0. 但是统计方法告诉我们,这不是100%的,我们至于95%的把握,有5%的风险我们不该弃真,不该拒绝H0
在严格要求第一类错误很低的前提下,比如0.05,0.01等,降低第2类错误。
首先要定义清楚原假设。原假设是已知的,狭窄的,可以应用中心极限定理变成正态分布的(或者其他轻尾分布)。第一类错误可控,第二类错误控制不了。
逻辑判断的起点是小概率事件不可能发生。假设在科学实验中我们观测到了某个正态分布的尾巴,与其说小概率事件发生了,不如说观测到了别的分布的中间。于是可以拒绝这次观测来源于这个正态分布,也就是拒绝原假设。
作者:郑重
链接:https://www.zhihu.com/question/37437658/answer/149447255作者:郑重
链接:https://www.zhihu.com/question/37437658/answer/149447255
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先要定义清楚原假设。原假设是已知的,狭窄的,可以应用中心极限定理变成正态分布的(或者其他轻尾分布)。第一类错误可控,第二类错误控制不了。
逻辑判断的起点是小概率事件不可能发生。假设在科学实验中我们观测到了某个正态分布的尾巴,与其说小概率事件发生了,不如说观测到了别的分布的中间。于是可以拒绝这次观测来源于这个正态分布,也就是拒绝原假设。
原假设的分布是已知的,我们知道怎样的观测结果属于小概率事件。但备择假设的分布一般未知,不能确定小概率事件的范围。比如观察一组新产品是否比老产品有提升。可能这组没提升的产品运气爆表,各个性能良好,会产生第一类错误。也可能它们本身有提升但运气太差表现不好,产生第二类错误。是否属于原假设的小概率是知道的,在备择假设里是多大的概率谁知道呢?
所以控制第一类错误就是把原假设的小概率设定的非常严苛,概率越小越理直气壮。有些实验做起来很贵,不能做很多次,或者本来就只能做一次,防止犯第一类错误是可控的,可以严苛要求。下面举几个例子。
对于嫌犯审判的原假设是无罪,假如嫌犯真的犯罪了,一定会做出一系列不寻常的事,这些事同时发生在清白人身上的概率非常低(清白人的独立事件同时发生才能用乘法)。没犯罪的可能运气太差,比如肖申克的救赎,被误判了。为了防止误判,把alpha值调低,才能过滤掉普通人,留下罪犯。疑罪从无,真罪犯没有疑点。但狡猾罪犯也会清理干净某些线索,改变概率,误导法官让自己处在无罪的概率范围内。这可以用刑侦技术来弥补,不冤枉好人更重要。
看一个女孩爱不爱你,原假设是她不爱你。爱你的人会做出一系列让你怦然心动的事,不爱你的人凭真性情做不出这些事。要求高的人会避免第一类错误--哪怕找不到对象也要找到真爱,不能保证对方爱不爱,但清楚自己要什么样的爱。也有人宁可要求低一点,就算不爱自己也比错过了真爱好,姑娘的正常举动落入了小伙子感受的极值,万一是真爱呢?
有答案提到胃病检查,无病是原假设,为了保守起见就是放宽第一类错误,宁可多相信人正常而指标不幸运的不正常,也不错过治疗的机会。
结论是第一类错误可控,会尽量避免,但也有可能会放宽。第二类错误不可控,就不去管了。
4.2.5 两类错误不能同时消除,存在此消彼长的关系
所以我们主要目标是减少第1类错误α的概率!是否可以同时降低第2类错误β的概率呢?不能
因为当想要犯α错误的机会变小的时候,也就是更有可能认同原假设是对的。但这就容易导致原假设本身其实是错的,却更有可能接受而犯β错误。
- type 1 error和type 2 error的概率相加不为1但存在此消彼长的关系。
- type 1 error和type 2 error的概率相加肯定远远比1=100%要小,不可能错误率这么高。只是存在一个此消彼长的一个关系。
- 特殊:可是在一些情况下,会共同上升或下降
- 毕竟是error,越精准,error就越少
4.2.6 为什么存在这种关系?
现在还没搞清楚原理

5 如何设计H0的一些例子和思考
5.1 对H0原假设的理论思考
- H0 原假设,一般都是假设两者是相同分布 的这种 理想假设。
- 为什么说是理想假设,因为现实的样本里往往一定存在误差,不可能相同。因此这个H0假设是一个理想假设
- 虽然永远无法认识总体,但现实中的我们总是一厢情愿的希望,样本从总体里来是无误差的
- 理想状态:和之前说的,真实值,观测值,预测值这3种基础数据关系里的真实值一样,本质是永远无法观测到的,只存在于我们的大脑的理想国之中,所以我认为这里是需要懂一点哲学形而上的东西的。
- 一般的h0假设,总是假设2者相等,而不相等的就是h1假设
- 一般的医学的假设检验理
- h0阴性正常, 相等正常普通等标签 ( 和其他统计喜欢假设H0相等一个意思)
- h1阳性不正常
当没有价值判断时
h0 假设相等正常普通等标签
h0 假设 两个东西无差异h0 假设 并不存在误差
。。。
这几个标准的统一背后的思想是:科研人员实际希望是不同的,希望发生小概率事件从而反证法H0错误!从而H1正确
为什么呢
当没有价值判断时,我们一般假设,概率50%,两个东西没有差异 等等,我们对未知的东西一般做这种假设
H0假设就是认为是“正常的世界。没有小概率事件发生的正常情况”
这里H0假设没差异,而实际上,科研人员实际希望是不同的,希望发生了小概率事情,希望发生小概率事件从而证明H0是错的,人类就是研究差异和变化,这个就是科研人员的动机,也可以认为是一种价值判断,其实这个比较个人
if 当现实社会里有价值判断时
科研人员的判断需要给社会价值让路,个人价值判断要给集体价值判断让路
研究新药的人当然希望有用,但是社会要保证的必须是 假药不能被判断为有用,因为这更加恶劣!
最可靠的依据是,我们设计的弃真概率,是更重要的
比如
我们更能接受,阴性的人被错误判断为阳性,还是阳性的人被错误判断为阴性?
后者对社会更危险,后者就当成第1类错误
阴性的人被错误判断为阳性再检测一次就行,成本不高
阳性的人被错误判断为阴性,更不能接受,那就 h0假设为每个人都阳性,这样假设h0=阳性,实际检验时如果判断为阴性,这个就是第1类错误。
我们更能接受,无罪的人被错误判断为有罪,还是有罪的人被错误判断为无罪?
前者对社会更危险,前者就当成第1类错误
[无罪,有罪]
无罪的人被错误判断为有罪,更不能接受,那就 h0假设为每个人都无罪,这样假设h0=无罪,实际检验时如果判断为有罪,这个就是第1类错误。
我们更能接受,假药被错误判断为真有用,还是真药被错误判断为阴没有用
前者对社会更危险,前者就当成第1类错误
假药被错误判断为有用,更不能接受,那就 h0假设为新药都无效,这样假设h0=无效,实际检验时如果判断为有效,这个就是第1类错误。
银行更能接受,假币错误判断为真币,还是真币被错误判断为假币
前者对社会更危险,前者就当成第1类错误
假币被错误判断为真币,更不能接受,那就 h0假设为放进来的是假币,这样假设h0=是假币,实际检验时如果判断为是真币,这个就是第1类错误。
5.2 具体的例子
记住:备择假设通常才是研究者最想证明的。
举例
- 假设X1,X2两个样本的方差相同,实际希望方差不同。
- 假设一种药没有效果H0,实际希望有效果
- 用一个试剂去检查某人群,假设H0是阴性,实际希望是阳性
- 也就是
- 举例子:均匀骰子是1/6, 均匀硬币是0.5,我们认为抽样的人群能代表世界上所有人,这都是理想值(所谓的“真实值”,只存在于彼岸的真实值。即使有时候算出来刚好相等,那也应该是恰好相等而已)
5.3 相比自然语言,根据第一类弃真概率更重要这个原则来设计一些检验,特别是有价值判断的那些
5.3.1 现实的自然语言很不严谨
- 比如我们经常说,无罪推定更重要。我们更愿意容忍坏人被放跑,但是不愿意被容忍好人被误判。
- 疫情检测时,倾向于宁愿假阳性更多,可以二次筛,一定要假阴性少,放跑阳性危害大,所以h0假设是人是阳性,第一类错误就是=被检查为阴性/此人是阳性,要努力降低这个第一类错误。
- 新药测试时,更愿意容忍,有效药被认为无效的误差,而不是无效药被认为有效
- 新药测试副作用时,更愿意容忍 没有副作用被认为是有副作用的错误,而不愿意容忍有副作用的被认为没有副作用的错误
5.3.2 所以我从这些例子总结:做假设检验时需要根据第一类弃真概率更重要这个原则来设计,尤其是有价值判断的时候
比如我们经常说,无罪推定更重要。我们更愿意容忍坏人被放跑,但是不愿意被容忍好人被误判。
- 假设人人无罪推定,那么第一类错误就是人无罪但是被拒绝了无罪的假设被误判了,所以h0就应该是 此人无罪的推定。
- 无罪的被判有罪算是弃真 还是纳伪?算弃真概率,让这个尽量低,这个社会成本太高了
- 有罪的暂时被判无罪,这个社会成本是相对低的
疫情检测时,倾向于宁愿假阳性更多,可以二次筛,一定要假阴性少,放跑阳性危害大
体检时也应该是相同的思路把,不过这样确实会造成假阳性很多(因为目的是降低假阴性),而且因为即使一个准确率很高的检测,也会因为检查健康人群而非等比例人群而出现大量的假阳性误判。这个其他地方也讨论过。
- 错误的思路,先确定H0,这是碰运气
- H0假设人是阴性
- 第1类错误,弃真错误,把阴性的人当成了阳性,
- 这个是因为思考的次序错了
- 正确思考的次序,先思考什么是最不能接受的,把这个当成第1类弃真错误,再去设计H0
- 第1类错误/弃真错误,把阴性的人当成了阳性更能接受-二次检查可排除,成本较低,不能接受把阳性的人当成阴性,会造成更大危害,成本太高。
- 所以H0应该是此人为阳性
- 第1类错误,弃真错误成本太高,是他是阳性被误认为阴性,这个要尽量的低。
H0=阳性,第1类错误就是弃真错误,是阳性但是被跑走,这个社会成本较高。
我的标准是第一类错误更重要。
但是如果不纠结第一类错误更重要。那也可以H0=阴性,而设置第2类错误的显著度更重要,也是一样,让H0的纳维错误很小,H0为假实际为真,也是阳性跑走概率更重要。
新药测试是否有效
- 这两种误差,我们思考下:有效药被认为无效的误差,而不是无效药被认为有效,哪个成本更高?
- 无效药被认为有效,这个成本太高,我们更不愿意接受,我们把这个当第1类错误
- 那么H0就是 这个新药是无效的
新药测试副作用时
- 先比较没有副作用被认为是有副作用的错误,有副作用的被认为没有副作用的错误,哪个更严重?成本更高?
- 有副作用的被认为没有副作用的错误更严重,所以这个是第1类错误
- 那么H0就应该是 新药有副作用
银行的ATM存款纸币识别的思路
- 1 先考虑,ATM接受假币错误的成本,ATM拒绝真币的错误成本
- 2 显然,ATM接受假币,把假币当真币错误的成本很高,错误严重
- 3 所以 H0就是假设钱币为假币
- 从这个例子看,这个第1类错误的 弃真概率,是把 假币当真币的概率,用日常语言来说,反而是 纳伪的概率。所以日常语言是不准确的。
- 而第2类错误,把真币当假币给拒绝,这个再假设检验这里是第2类错误, 纳伪错误,但对应到真实日常生活的语言,这应该是“弃真”
- 所以要警惕日常语言对我们的误导。
- 在什么语言环境就用当下语境更精确的语言来说话!比如这里就要在统计学假设检验的语言环境下考虑弃真,纳伪。而不是口语化的“弃真,纳伪”。
5.4 总结(社会价值性的)
非社会价值的,一般都是原假设是无差异,而希望有差异!
- step1:先确定第1类错误。
- 先根据能接受的两类错误里,考虑哪一类错误是我们更不愿意接受的,更严重的,成本更高的,先确定第1类错误。
- step2: 确定H0 零假设
- 确定了第1类错误后,就可以顺势确定H0的假设了。
- step3: 根据H0,确定与之矛盾的H1假设
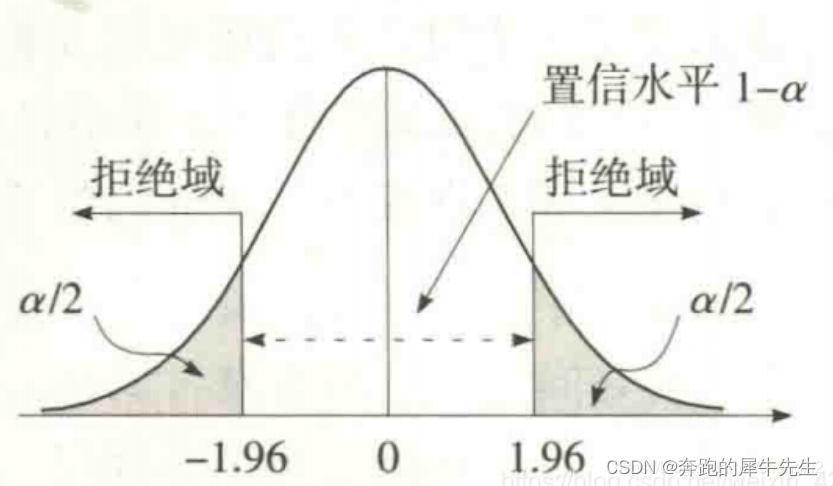
6 双侧检验
双侧检验/双边检验
- 值过大过小都异常的:H1和H0相等的假设,双侧检验
- H0: 假设两者相等
- H1: 假设两者不相等。
- 很少有反过来,H0假设两者不相等的,这只能说算一个统计学惯例了
- 相等假设一般都是设计在H0内,无论是 X1=X2,甚至X1>=X2,
- 也就是说即使是单侧检验,一般都是H0 X1>=X2, 而不是X1>X2
7 左侧检验和右侧检验
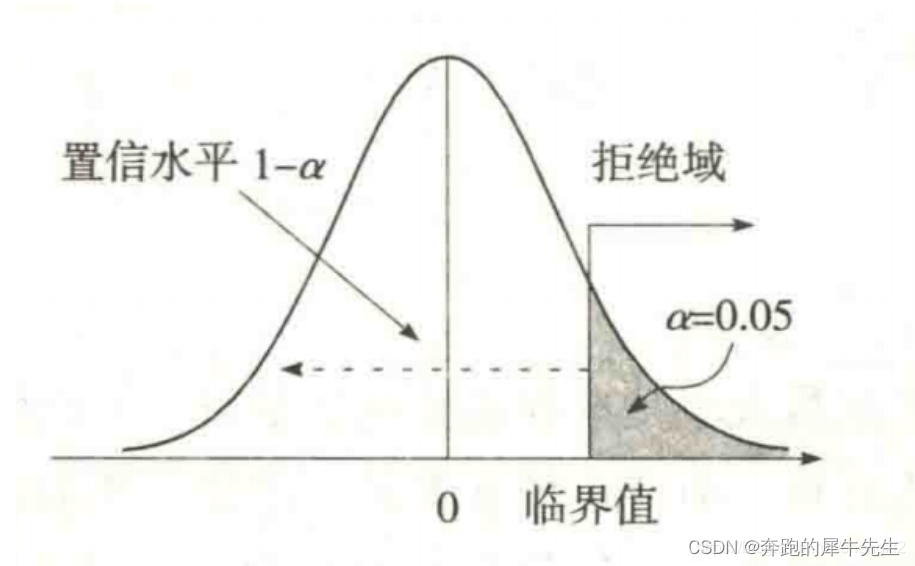
7.1 右侧检验
右侧检验(相对左侧检验偏多一些,也不是一定的)
可能有一些检验是偏态的,比如F分布就一般情况下右偏。
- 上限检验
- 右侧检验关注总体参数是否明显增加
- 值大是异常的:H1大于H0,单侧检验,右侧检验
- 也就是主要关注H1, 因为统计的潜规则就是H1才是检测者想要的,那么H1是X1>X0 (对应的h0是X1<=X)就是右侧检验。
- 右侧检验,比然拒绝域也是在右边
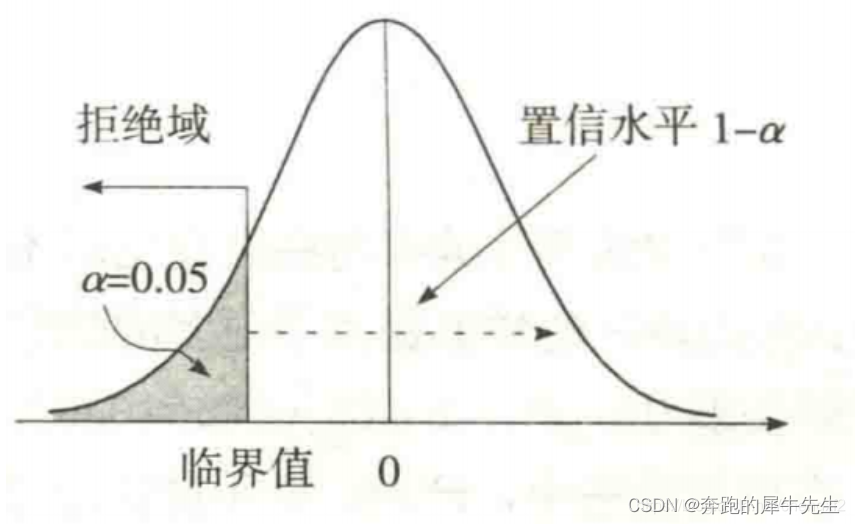
7.2 左侧检验(下限检验)
左侧检验
- 下限检验
- 我们的预设目的是,认为H1是对的,但是反正H0是错的(这是我们的出发点,不是事实)
- 这时候我们不关注是不是更大更多,我们只关心是不是检测值会很小!越小我们就越可以拒绝H0,而接受H1
- 左侧检验关注总体参数是否明显减少/小。
- 值小是异常的:H1小于H0,单侧检验,左侧检验
- 也就是主要关注H1, 因为统计的潜规则就是H1才是检测者想要的, H1是X1<X0 (h0是X1>=X)就是左侧检验
- 左侧检验,比然拒绝域也是在左边
而单侧检验是左侧是右测,要看拒绝域的位置;而拒绝域在左侧还是右侧,要看备择假设是大于(对应右侧检验)还是小于(对应左侧检验)某个数。
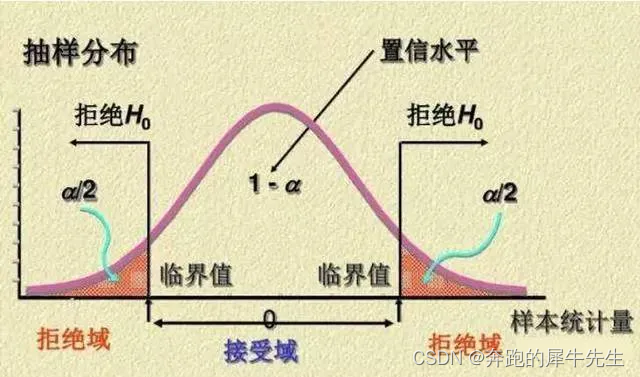
8 拒绝域
- 拒绝域就是,在指定的显著度水平下,拒绝H0的区间
- 只要p落在拒绝域就拒绝H0,接受H1
8.1 双边拒绝域
8.2 右边拒绝域
8.3 左边拒绝域
9 假设检验和机器学习的区别
- 大神们网上吵得很厉害
- 不明觉厉’
- 暂时得收获就是
- 假设检验是小样本,90多就算很大通量了 ,主要关注推断,inferential modeling
- ML机器学习都是大数据大样本 ,主要关注预测,predictive modeling

9 显著度
10 EXCEL里用函数做
11 python里做

















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









