







 本文介绍了强化学习的基础概念,包括智能体与环境的交互、奖励机制。重点阐述了马尔科夫决策过程(MDP)及其与强化学习的关系,MDP的五元组表示以及在强化学习中的核心三要素:Policy、Value和Model。强化学习的目标是通过与环境的互动找到最优策略,以最大化长期奖励。
本文介绍了强化学习的基础概念,包括智能体与环境的交互、奖励机制。重点阐述了马尔科夫决策过程(MDP)及其与强化学习的关系,MDP的五元组表示以及在强化学习中的核心三要素:Policy、Value和Model。强化学习的目标是通过与环境的互动找到最优策略,以最大化长期奖励。
以下文章摘录自:
《机器学习观止——核心原理与实践》
京东: https://item.jd.com/13166960.html
当当:http://product.dangdang.com/29218274.html
(由于博客系统问题,部分公式、图片和格式有可能存在显示问题,请参阅原书了解详情)
1.1 强化学习(Reinforcement Learning)和MDP
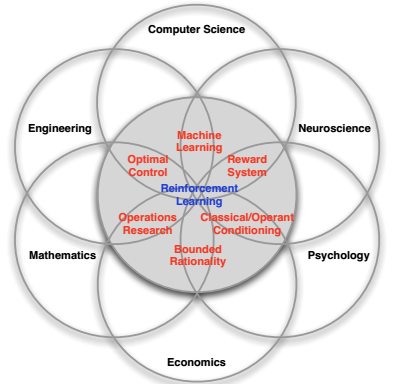
图 ‑ 强化学习的多面性(David Silver)
简单而言,深度强化学习是深度学习和强化学习的“融合体”。因而在学习DRL之前,我们有必要先了解一下强化学习。
强化学习虽然已经有几十年的历史,但它在最近几年突然火起来则要归功于DeepMind。这家建立于英国的小公司在2013年开始就不断地在实现着各种突破——从Atari游戏打败人类,并将成果发表于Nature上;再到开发出AlphaGO系列围棋智能程序,一次次挑战人类智慧巅峰,这些爆炸性的消息一遍遍地刷新着每天的热点榜单,也就直接带火了深度强化学习(以及强化学习)。关于AlphaGO的内部实现原理,本书后续章节有详细解析。
强化学习和有监督学习/无监督学习类似,是Machine Learning的一种类型。与后两者的不同之处在于,它强调的是从环境的交互中来寻求最优解。如下图所示:

图 ‑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









