







【强化学习】强化学习基础教程:基本概念、强化学习的定义,要素,方法分类 以及 Rollout、episode回合、transition转移、trajectory轨迹的概念
- 1.基础概念
- 2.强化学习分类
- 2.1 根据agent学习方式分为基于策略的强化学习Policy based RL ,基于价值的强化学习Value based RL以及Actor-Critic方法
- 2.2 根据理不理解所处的环境(agent有无学习环境的模型)分为model-based与model-free
- 2.3 根据agent是否与环境交互分为在线强化学习Online RL与离线强化学习Offline RL
- 2.4 根据如何使用已有的数据进行学习和决策划分为在线策略(on-policy)和离线策略(off-policy)
- 2.5 根据更新方式分为回合更新(Monte-Carlo update)与单步更新(Temporal-DIfference update)
- 3.Rollout的含义
- 4.episode回合、transition转移、trajectory轨迹的概念
1.基础概念
1.1 强化学习的定义
- 实现序贯决策的机器学习方法—强化学习(reinforcement learning)
- 强化学习定义:机器通过与环境进行交互,不断尝试,从错误中学习,做出正确决策从而实现目标的方法。
- 强化学习是与有监督学习方法和无监督学习方法并列的一类机器学习方法
- 强化学习是机器通过与环境交互来实现目标的一种计算方法。机器和环境的一轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器,交互是迭代进行
- 在每一轮交互中,智能体感知到环境目前所处的状态,经过自身的计算给出本轮的动作,将其作用到环境中;环境得到智能体的动作后,产生相应的即时奖励(注意是即时奖励)信号并发生相应的状态转移。智能体则在下一轮交互中感知到新的环境状态,依次类推。
- 强化学习(Reinforcement learning,RL)讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的环境(environment) 里面去极大化它能获得的奖励。通过感知所处环境的状态(state) 对动作(action) 的反应(reward),来指导更好的动作,从而获得最大的收益(return),这被称为在交互中学习,这样的学习方法就被称作强化学习

1.2 强化学习的基本要素
动作(action):智能体作出的决策行为
智能体(agent):学习器与决策者,作出动作的主体
状态(state):智能体从环境中获得到的信息
奖励(reward):环境根据状态与智能体做出的动作产生的反馈信号,用R或r表示
回报(return):未来的累积奖励,用Ut表示从t时刻到结束时的累积奖励
策略(policy):一般用π表示,由观测到的状态根据策略决定作出动作

2.强化学习分类
2.1 根据agent学习方式分为基于策略的强化学习Policy based RL ,基于价值的强化学习Value based RL以及Actor-Critic方法
-
Policy based RL :学习一个策略函数π(a|s),无需构造价值函数,如REINFORCE算法
-
Value based RL:学习最优动作价值函数 Q ∗ Q^* Q∗,无需策略函数,如Q-learning,Sarsa,DQN方法
-
Actor-Critic方法:一种特别的方法,上述两者的结合,Actor会基于概率作出动作,Critic会根据作出的动作打分,是一类结合了策略评估(Critic)和策略改进(Actor)的强化学习算法。它们通过同时学习一个策略函数(Actor)和一个值函数(Critic),从而可以更有效地学习到优秀的策略;A2C (Advantage Actor-Critic)、A3C (Asynchronous Advantage Actor-Critic)、DDPG (Deep Deterministic Policy Gradient)、TD3 (Twin Delayed Deep Deterministic Policy Gradient)、PPO (Proximal Policy Optimization)等算法均是Actor-Critic方法

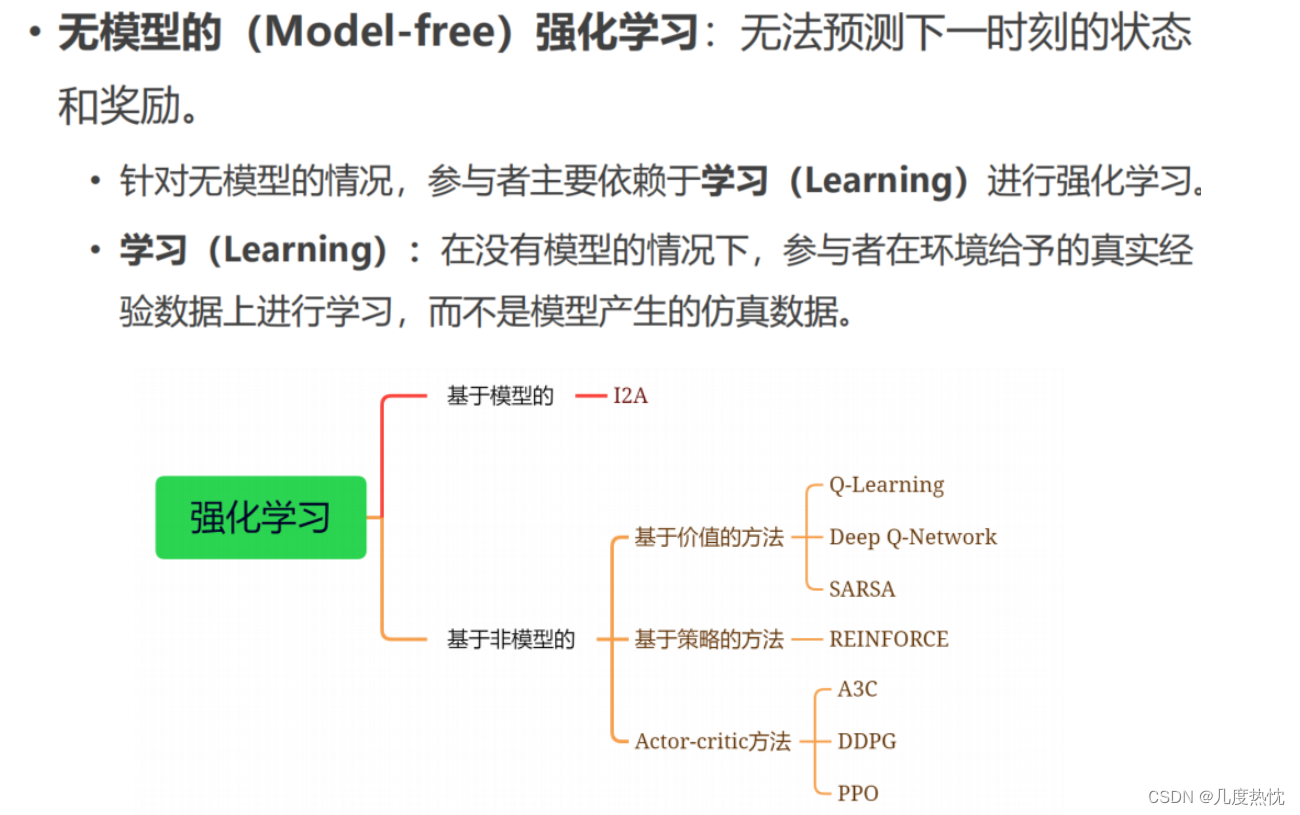
2.2 根据理不理解所处的环境(agent有无学习环境的模型)分为model-based与model-free
- model-based:学习环境的模型,通过学习状态转移概率 P ( s , s ′ ) P(s,s') P(s,s′)采取行动
- model-free:无环境的模型,通过学习价值函数 V π ( s ) V_\pi(s) Vπ(s)与策略函数进行决策。Q-learning,Sarsa,Policy Gradients都是model-free方法,从环境中得到反馈从而学习,智能体只能和环境进行交互,通过采样到的数据来学习,这类学习方法统称为无模型的强化学习(model-free reinforcement learning
2.3 根据agent是否与环境交互分为在线强化学习Online RL与离线强化学习Offline RL
-
Online RL:学习过程中,agent除了从数据集中学习,还需要与环境进行交互。
-
Offline RL:学习过程中,agent不与环境进行交互,只从数据集中直接学习一套策略来完成相关任务。
2.4 根据如何使用已有的数据进行学习和决策划分为在线策略(on-policy)和离线策略(off-policy)
- 称采样数据的策略为行为策略(behavior policy),称用这些数据来更新的策略为目标策略(target policy)
- 在线策略(on-policy)算法表示行为策略和目标策略是同一个策略,agent根据当前的策略来选择动作,并且学习的目标是优化当前正在执行的策略(要求必须本人在场,边玩边学习);
- 离线策略(off-policy)算法表示行为策略和目标策略不是同一个策略,学习算法可以利用从其他策略生成的数据来进行学习,而不局限于当前执行的策略(可以自己玩也可以看着别人玩,通过看着别人玩来学习其他人的行为准则)
- 离线策略学习使用经验回放池将之前采样得到的样本收集起来再次利用,就好像使用脸盆接水后洗手。因此,离线策略学习往往能够更好地利用历史数据,并具有更小的样本复杂度(算法达到收敛结果需要在环境中采样的样本数量)。
2.5 根据更新方式分为回合更新(Monte-Carlo update)与单步更新(Temporal-DIfference update)
- 回合更新:游戏有开始和结束,回合更新只有等待一局游戏从开始到结束,然后才能更新行为准则
- 单步更新:在游戏过程中,每一步都可以更新,不用等待游戏的结束,边玩边学习,学习效率更好
3.Rollout的含义
Rollouts通常指的是在执行策略梯度或其他基于模拟的强化学习方法时,智能体在环境中进行的一系列模拟交互步骤。这些步骤用于收集数据,以评估或改进当前的策略。
在强化学习中,rollout指的是在训练过程中,智能体根据当前的策略在环境中进行一系列的模拟交互步骤,模拟并收集样本数据的过程。 在每个rollout中,智能体从环境中观测当前状态,然后根据选择的策略采取一个动作。接下来,智能体与环境进行交互,执行该动作,并观察到下一个状态和获得的奖励。此后,智能体根据新的状态更新其策略,并在下一个步骤中选择下一个动作。这个过程会持续进行,直到满足某个停止条件,比如达到最大步数或达到终止状态。
Rollout的目的是通过与环境的交互来生成样本数据,用于策略优化和价值函数估计。这些样本数据将被用于更新策略参数或进行价值函数的拟合,以改善智能体的性能。通常,rollout会在训练过程中进行多次,以收集足够的样本数据来训练和优化智能体。
Rollout的长度可以根据具体任务进行调整,可以是固定长度,也可以是变长的。在一些连续控制任务中,rollout可能会持续进行数百或数千个时间步。然而,在一些离散决策任务中,rollout可能会在有限步数内完成。 总而言之,rollout是强化学习中一种通过与环境进行交互并收集样本数据的过程,用于训练智能体的策略和价值函数。
4.episode回合、transition转移、trajectory轨迹的概念
4.1 episode回合
- 一个完整的任务执行过程被称为一个回合或一个episode,强调任务从开始到终止的全部过程 ;
- 一个episode可以包含多个trajectory。在某些情况下,一个episode可以被视为一个完整的trajectory,而在其他情况下,一个trajectory可能只是episode中的一部分;
- 在每个回合中,智能体从环境中接收状态(state),然后执行动作(action),环境根据智能体的动作和当前状态返回奖励(reward)和新的状态。这个过程一直持续,直到任务结束或达到某个终止条件。例如,在玩棋盘游戏时,一个回合可能是一整局游戏的过程,从游戏开始到游戏结束。

4.2 transition转移
- 在强化学习中,一个状态到另一个状态的变化被称为转移。
- 转移通常由三元组表示:(state, action, next_state)。即在某个状态下,智能体执行了一个动作后,环境的响应将导致状态从当前状态转移到下一个状态。
- 转移还可以包括奖励信号,可以表示为四元组:(state, action, next_state, reward)。
- transition数据
(
s
t
,
a
t
,
r
t
,
s
t
+
1
)
(s_t,a_t,r_t,s_{t+1})
(st,at,rt,st+1)

4.3 trajectory(轨迹): 多条transition
- 一个轨迹是智能体与环境之间相互作用的一个序列,通常包括一系列状态、动作和奖励。
- 轨迹是一连串的状态-动作对,描述了智能体是如何在环境中移动并与环境互动的。
- 轨迹可以由一系列转移组成,而一个回合中的所有转移组合在一起就形成了整个轨迹。
- trajectory可以是从一个episode中抽取的,也可以是多个episode的组合
- trajectory可以跨越多个episode,或者是一个episode中的一个子序列。
- trajectory数据
(
s
0
,
a
0
,
r
0
,
s
1
)
,
(
s
1
,
a
1
,
r
1
,
s
2
)
,
.
.
.
,
(
s
t
,
a
t
,
r
t
,
s
t
+
1
)
(s_0,a_0,r_0,s_1),(s_1,a_1,r_1,s_2),...,(s_t,a_t,r_t,s_{t+1})
(s0,a0,r0,s1),(s1,a1,r1,s2),...,(st,at,rt,st+1)

4.4 回合、转移、轨迹三者的区别与联系

-
Episode(回合)通常由一系列Transition(转移)组成
-
episode是整个学习任务的执行过程,trajectory是一个序列,而transition是轨迹中的单一步骤
-
个人理解:多个transition构成一个trajectory,一个或多个trajectory构成一个episode
-
举个例子,考虑一个机器人学习走迷宫的任务。一个回合可以包含机器人从迷宫的入口走到出口的整个过程。在这个回合中,机器人可能经历了多个轨迹,每个轨迹对应于机器人在迷宫中的不同路径选择。每个轨迹可以被看作是一次特定的路径规划过程。
4.5 范围(horizon)
- 范围(horizon) 是指一个回合的长度(每个回合最大的时间步数)
4.6 自举(bootstrapping)
- 在统计学中,自举(Bootstrapping)是一种通过对原始数据集进行重复采样(有放回的抽样)来估计统计量分布的方法。
- 在强化学习中,“自举”通常是指利用现有的估计(如当前的Q值或价值函数)来改进未来的估计。这种方法是基于递归的思想,其中估计值会根据自己的估计来进行更新,逐步逼近正确的值。


















 2626
2626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











