







1.系统平均响应时间
响应时间就是用户感受软件系统为其服务所耗费的时间。 响应时间可细分为:
(1)服务器端响应时间,这个时间指的是服务器完成交易请求执行的时间,不包括客户端到服务器端的反应(请求和耗费在网络上的通信时间),这个服务器端响应时间可以度量服务器的处理能力。
(2)网络响应时间,这是网络硬件传输交易请求和交易结束所耗费的时间。
(3)客户端响应时间,这是客户端在构建请求和展现交易结果时所耗费的时间。
客户感受的响应时间其实是等于客户端响应时间+服务器端响应时间+网络响应时间,本系统应满足的系统平均响应时间如下表所示:

2.用户并发数
并发用户数用来度量服务器并发容量和同步协调能力。在客户端指一批用户同时执行一个操作。并发数反映了软件系统的并发处理能力。
本系统采用QPS(Quest Per Second每秒请求数)对用户并发数进行约束:
系统QPS: 大于50QPS。
qps标准:(引用http://www.cnblogs.com/yiwd/内容)
50QPS以下——小网站
没什么好说的,简单的小网站而已,就如同本站这样,你可以用最简单的方法快速搭建,短期没有太多的技术瓶颈,只要服务器不要太烂就好。
50~100QPS——DB极限型
大部分的关系型数据库的每次请求大多都能控制在0.01秒左右,即便你的网站每页面只有一次DB请求,那么页面请求无法保证在1秒钟内完成100个请求,这个阶段要考虑做Cache或者多DB负载。无论那种方案,网站重构是不可避免的。
300~800QPS——带宽极限型
目前服务器大多用了IDC提供的“百兆带宽”,这意味着网站出口的实际带宽是8M Byte左右。假定每个页面只有10K Byte,在这个并发条件下,百兆带宽已经吃完。首要考虑是CDN加速/异地缓存,多机负载等技术。
500~1000QPS——内网带宽极限+Memcache极限型
由于Key/value的特性,每个页面对memcache的请求远大于直接对DB的请求,Memcache的悲观并发数在2w左右,看似很高,但事实上大多数情况下,首先是有可能在次之前内网的带宽就已经吃光,接着是在8K QPS左右的情况下,Memcache已经表现出了不稳定,如果代码上没有足够的优化,可能直接将压力转嫁到了DB层上,这就最终导致整个系统在达到某个阀值之上,性能迅速下滑。
1000~2000QPS——FORK/SELECT,锁模式极限型
好吧,一句话:线程模型决定吞吐量。不管你系统中最常见的锁是什么锁,这个级别下,文件系统访问锁都成为了灾难。这就要求系统中不能存在中央节点,所有的数据都必须分布存储,数据需要分布处理。总之,关键词:分布
2000QPS以上——C10K极限
尽管现在很多应用已经实现了C25K,但短板理论告诉我们,决定网站整体并发的永远是最低效的那个环节。我承认我生涯中从未遇到过2000QPS以上,甚至1.5K以上的网站,希望有此经验的哥们可以一起交流下3.软件可靠性
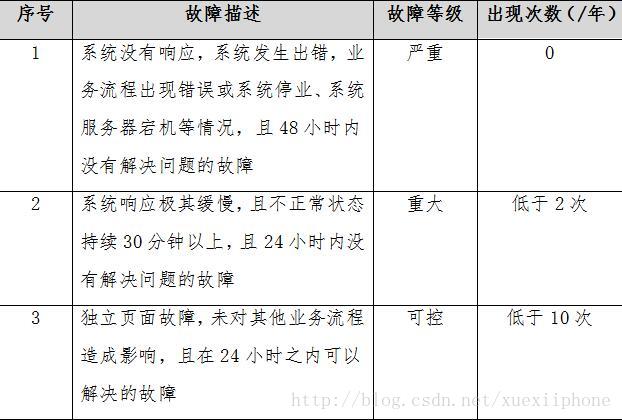
软件可靠性是软件产品在规定的条件下和规定的时间区间完成规定功能的能力。规定的条件是指直接与软件运行相关的使用该软件的计算机系统的状态和软件的输入条件,或统称为软件运行时的外部输入条件;规定的时间区间是指软件的实际运行时间区间;规定功能是指为提供给定的服务,软件产品所必须具备的功能。软件可靠性不但与软件存在的缺陷和(或)差错有关,而且与系统输入和系统使用有关。软件可靠性的概率度量称软件可靠度。
本系统按照系统故障等级,对相应的系统故障次数进行约束,从而使软件可靠性有据可依,具体可靠性标准如下表所示:














 7978
7978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









