







引言
本次接单是在qq群里面有人有需求,我了解了一下之后觉得能接之后接的。下面是微信的聊天记录
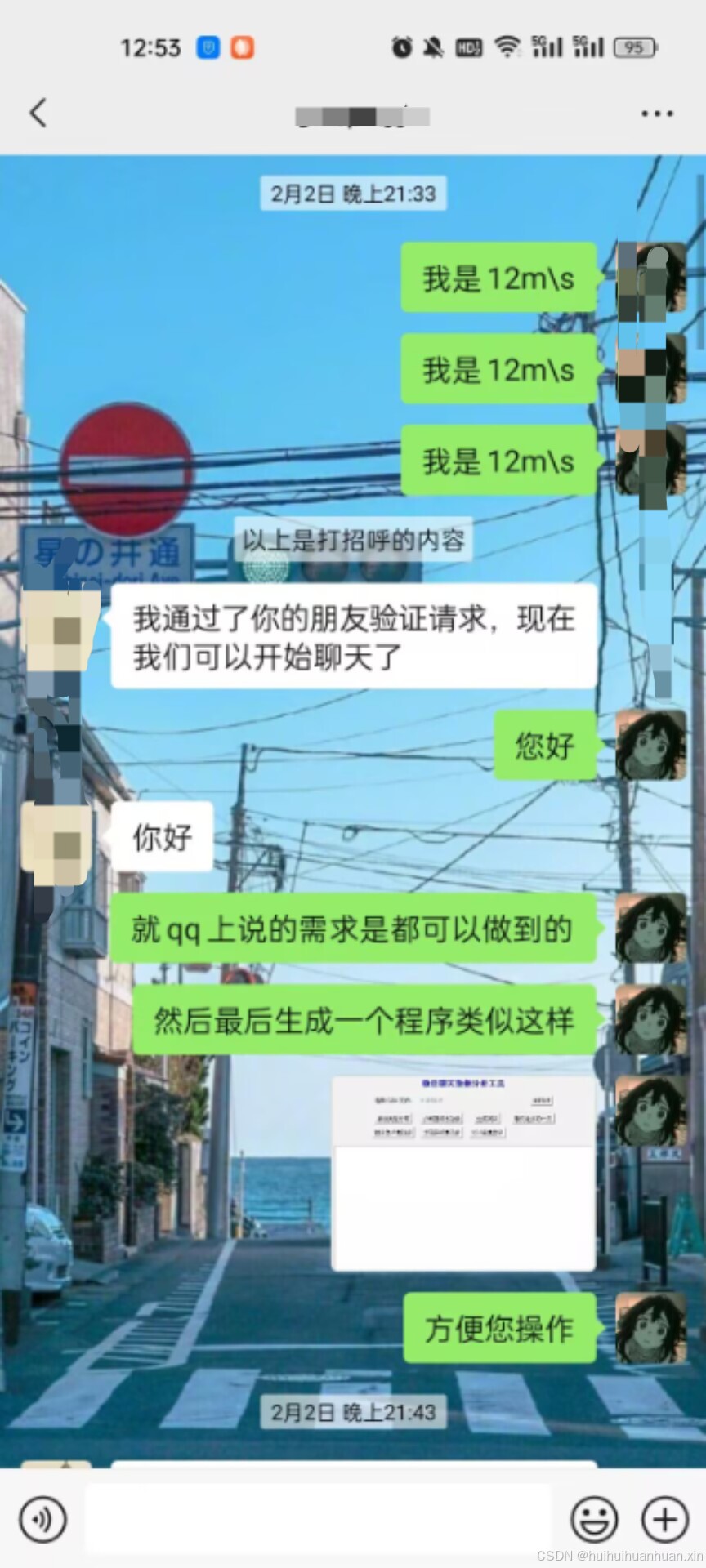

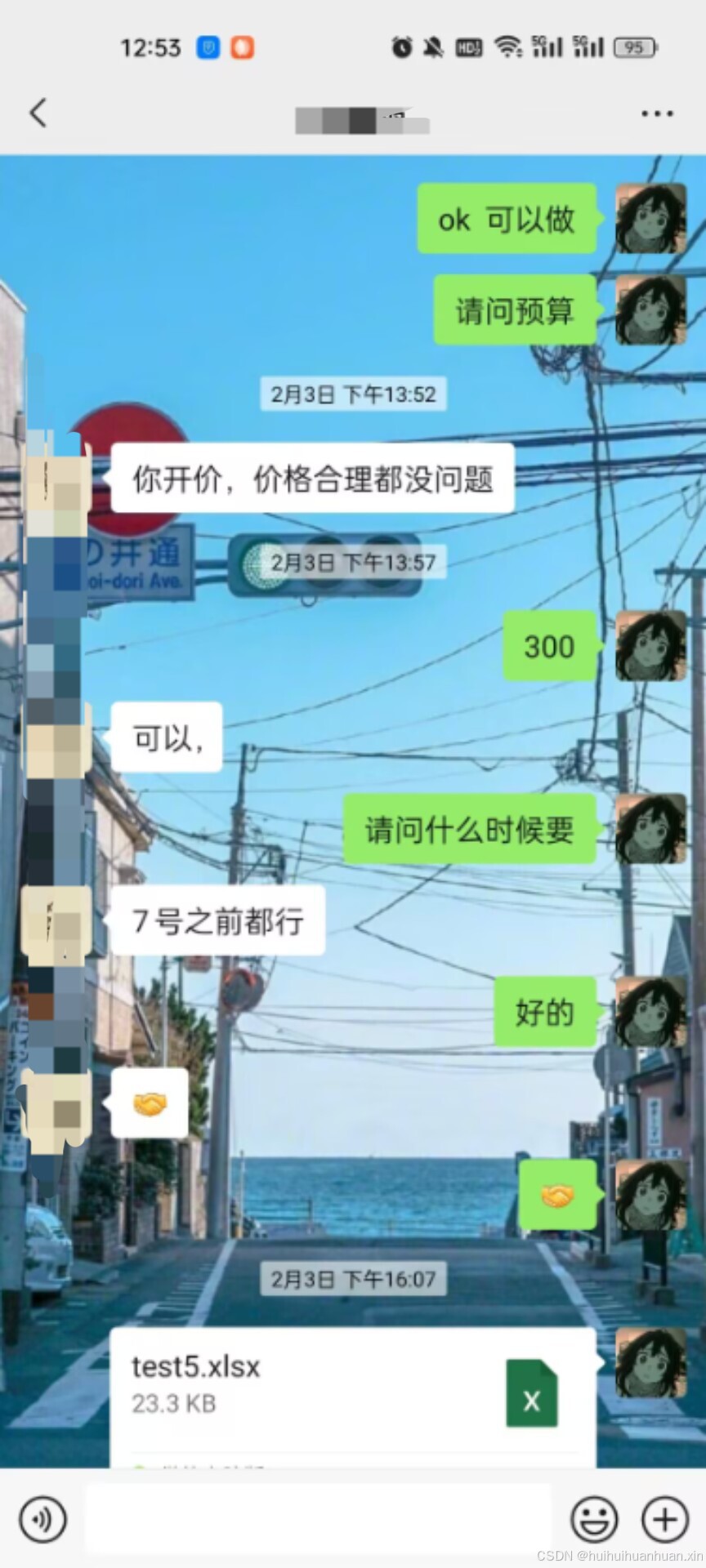
 在这个过程中更多的是在qq上聊的。
在这个过程中更多的是在qq上聊的。
接单过程中的问题
第一点
顾客的需求可能不是很明确,我先做出来数据样例格式给他看看确认之后再补全,然后我理解了顾客的意思,但是他还是觉得我不懂,我做好后给他个样品看看。
第二点
顾客的电脑版本太低了,win7的系统,并且ddl缺失,这个淘宝上10块钱让别人搞得,但是同时因为系统版本低,python版本要用3.8及其以下的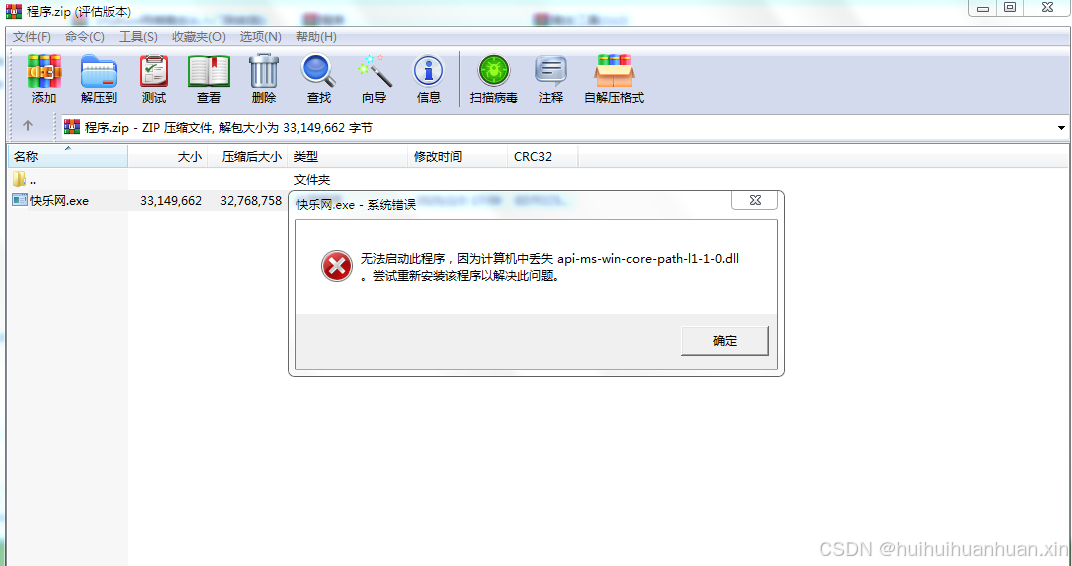
因为客户不会代码操做,我就是写好版本之后,让ai生成一个tkiner界面。
第三点
顾客在我基本上做完了之后说那个只是样例,要适用好几种形式,但是在沟通之前没有提到,我提出要加钱,顾客不同意,辛亏要改代码的少,在做之前一定要全部沟通完,并且要提到如果增加一些难的需求要加钱。
第四点
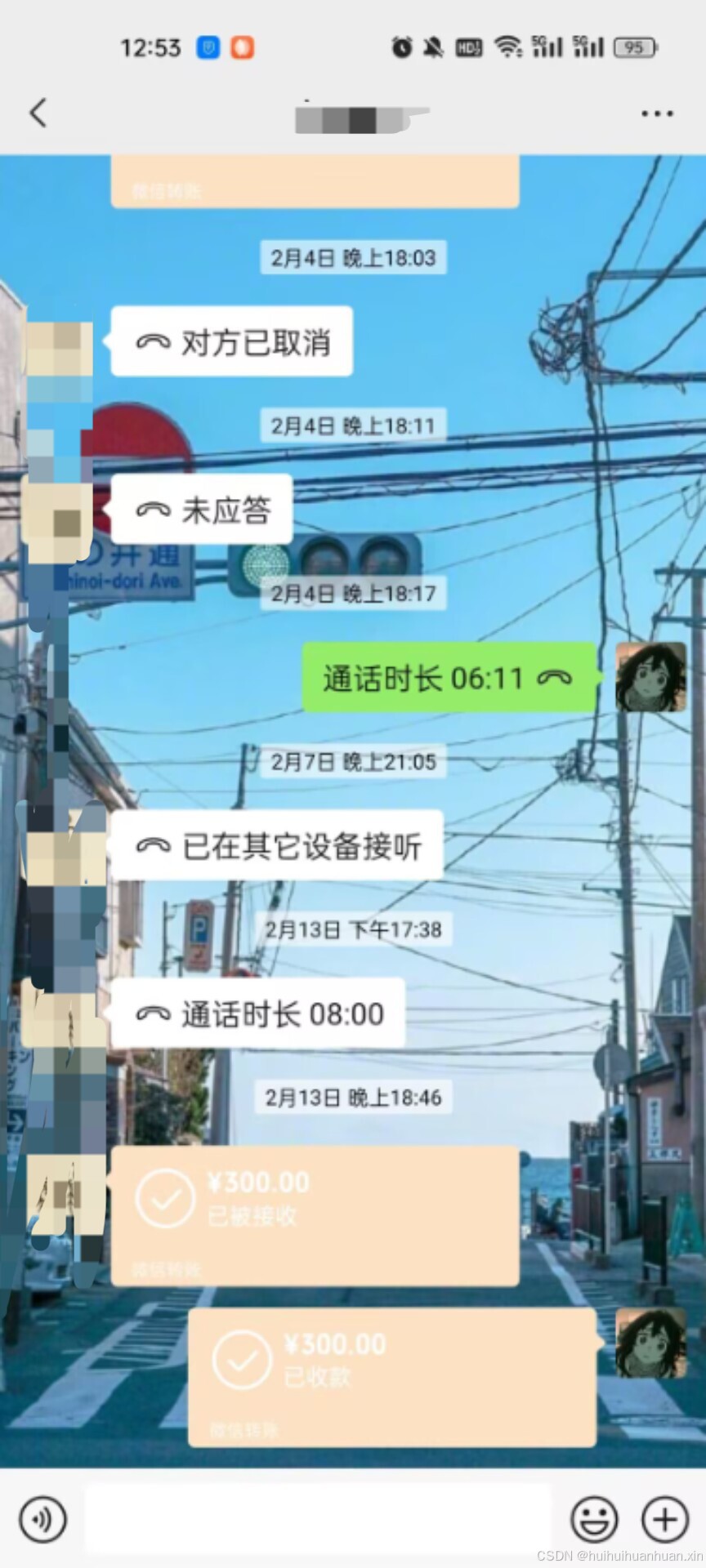
我是先把我做好的exe给顾客用的,为什么放心?因为是发给顾客封装好的程序,我在其中增加了代码如果几天后还不给钱打开程序电脑就自动关机,我没有给他自动全部文件设置密码我真是太善良了,如果顾客正常付款之后就给顾客说我优化了一下上一个程序,发给他一个完全的版本。
接单内容
要采集的网址是乐彩网乐币点播_彩票预测_免费预测_专家推荐_专家排行_彩研师_民间高手_特邀名人_乐币分析_特推榜就是把里面的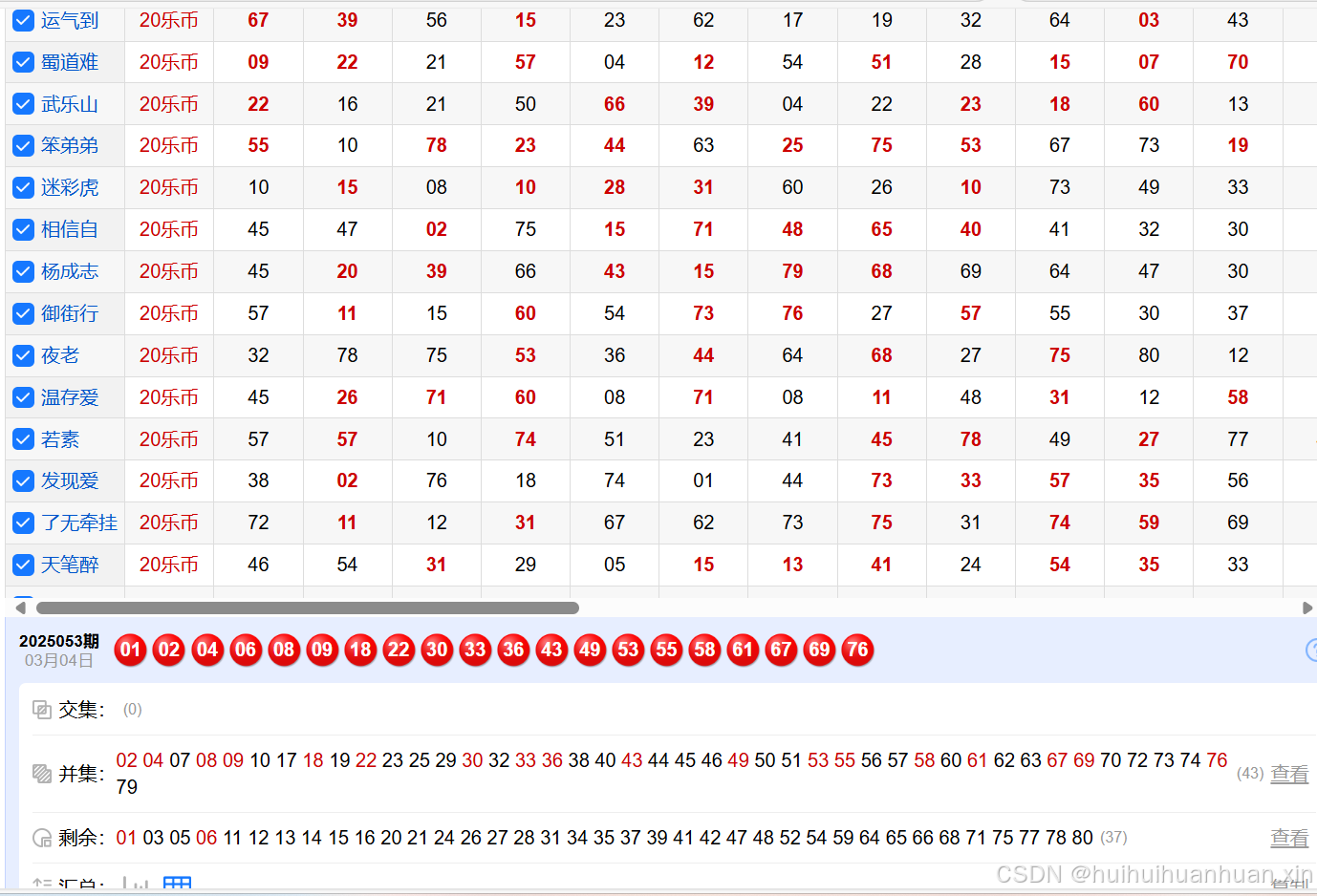 这一部分全部采集喽,简单的是像每个人每期中没中奖,在页面源代码里面就有,非常方便,带个user-agent就能正常返回数据,但是下面的数据分析那一部分没有,我们可以选择抓包接口,我分析应该就带了一个时间戳,我懒得试,就直接用python模拟了一下进行数据分析,然后每个人的具体页面在页面原码里面也有,这是一次比较简单但是麻烦的接单,因为顾客后面又提了一些需求能写但是我需要改我已经写好的代码,这就很烦,这个爬虫没有什么难的,直接请求网址就可以了。
这一部分全部采集喽,简单的是像每个人每期中没中奖,在页面源代码里面就有,非常方便,带个user-agent就能正常返回数据,但是下面的数据分析那一部分没有,我们可以选择抓包接口,我分析应该就带了一个时间戳,我懒得试,就直接用python模拟了一下进行数据分析,然后每个人的具体页面在页面原码里面也有,这是一次比较简单但是麻烦的接单,因为顾客后面又提了一些需求能写但是我需要改我已经写好的代码,这就很烦,这个爬虫没有什么难的,直接请求网址就可以了。
但是需要教会顾客,而且要满足他后面加的一些小需求。
下面是代码
import os
import json
import time
import requests
from lxml import etree
from openpyxl import Workbook
from openpyxl.styles import Font
import tkinter as tk
from tkinter import messagebox, filedialog, ttk
import datetime
# 请求头设置
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0',
}
# 获取当前样本数据的文件夹路径
def get_sample_folder_path():
folder_path = filedialog.askdirectory(title="选择存放样本数据的文件夹")
return folder_path
# 第一份代码:抓取样本数据
def fetch_sample_data(sample_folder, output_text,period,rank):
main_url = f'https://lebi.17500.cn/tops-kl8-fx-1-d1-{period}-0-20-{rank}-0-1.html'
base_url = 'https://lebi.17500.cn/'
main_url = str(main_url)
print(main_url)
response = requests.get(url=main_url, headers=headers)
# //*[@id="app_new_tops"]/div[7]/table/thead/tr/td[1]
print(period,rank)
wb = Workbook()
ws = wb.active
html = etree.HTML(response.text)
head = html.xpath('//*[@id="app_new_tops"]/div[7]/table/thead/tr/td')
cnt = 1
for td in head:
ws.cell(1, column=cnt, value=td.text)
if cnt != 2:
ws.cell(2, column=cnt, value='奖号')
else:
ws.cell(2, column=cnt, value='-')
cnt = cnt + 1
ws.cell(1, column=cnt, value="彩研师页面")
ws.cell(2,column=cnt,value="彩研师页面")
body = html.xpath('//*[@id="app_new_tops"]/div[7]/table/tbody/tr')
# //*[@id="app_new_tops"]/div[7]/table/tbody/tr[2]/td[1]/div/em/a
# //*[@id="app_new_tops"]/div[7]/table/tbody/tr[2]/td[2]/a
# //*[@id="app_new_tops"]/div[7]/table/tbody/tr[2]/td[3]/span/span
# //*[@id="app_new_tops"]/div[7]/table/tbody/tr[2]/td[7]/span
# //*[@id="truecs_16774"]
# //*[@id="curlz_16774"]
# //*[@id="curlc_16774"]
# //*[@id="truelv_16774"]
all_num = {}
row = 3
numbers = []
urls = []
period=int(period)
output_text.insert(tk.END, "数据解析完成。\n")
output_text.yview(tk.END)
for i in range(1, 81):
numbers.append(str(i))
for tr in body:
eid = tr.xpath('./@eid')
if eid:
url = tr.xpath('.//td[1]/div/em/a/@href')
url = base_url + str(url[0])
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









