






获得数据
关于如何从微信中获取聊天数据,这个功能我是依靠别人做好的功能留痕 | MemoTrace这个是下载官网,下载包我也放在下面的网盘里面,然后利用工具生成csv文件,![]()
利用留痕生成的是这样的,用别的方法导出也可以但是格式一定要和这个一样,要不然会报错。
分析数据和可视化
项目概述
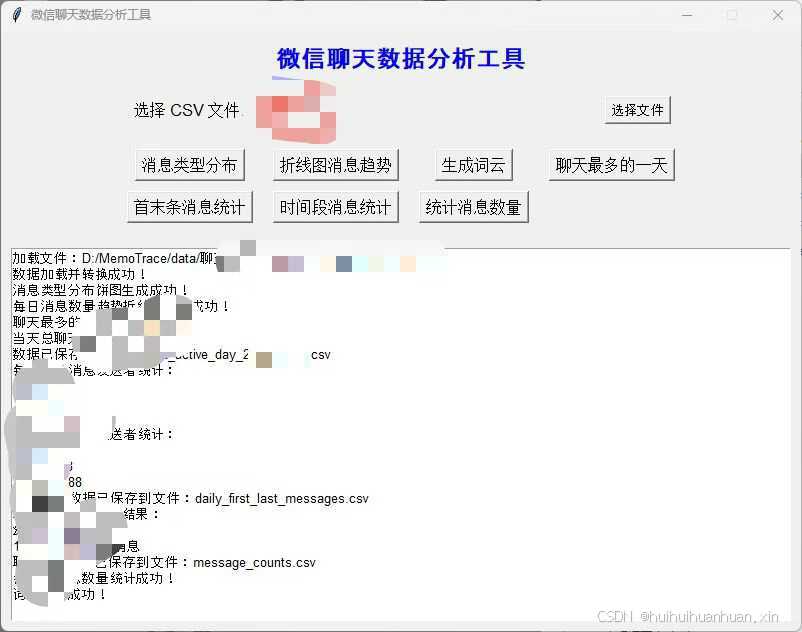
这款聊天数据分析工具的核心功能包括:
- 加载 CSV 文件:支持用户上传聊天记录文件。
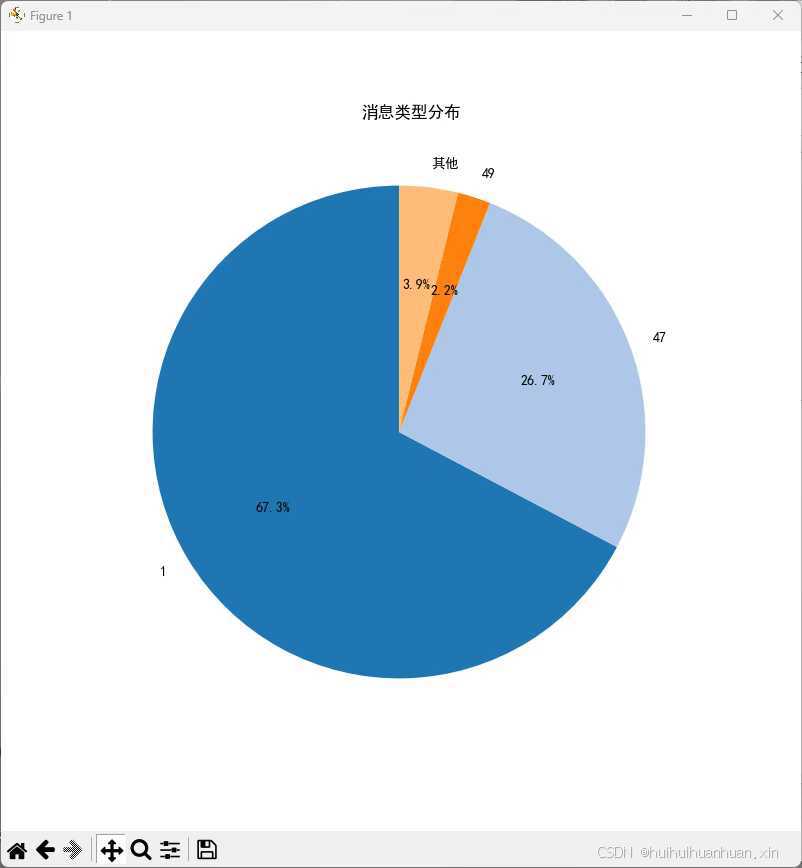
- 消息类型分析:生成饼图,显示每种消息类型的分布情况。
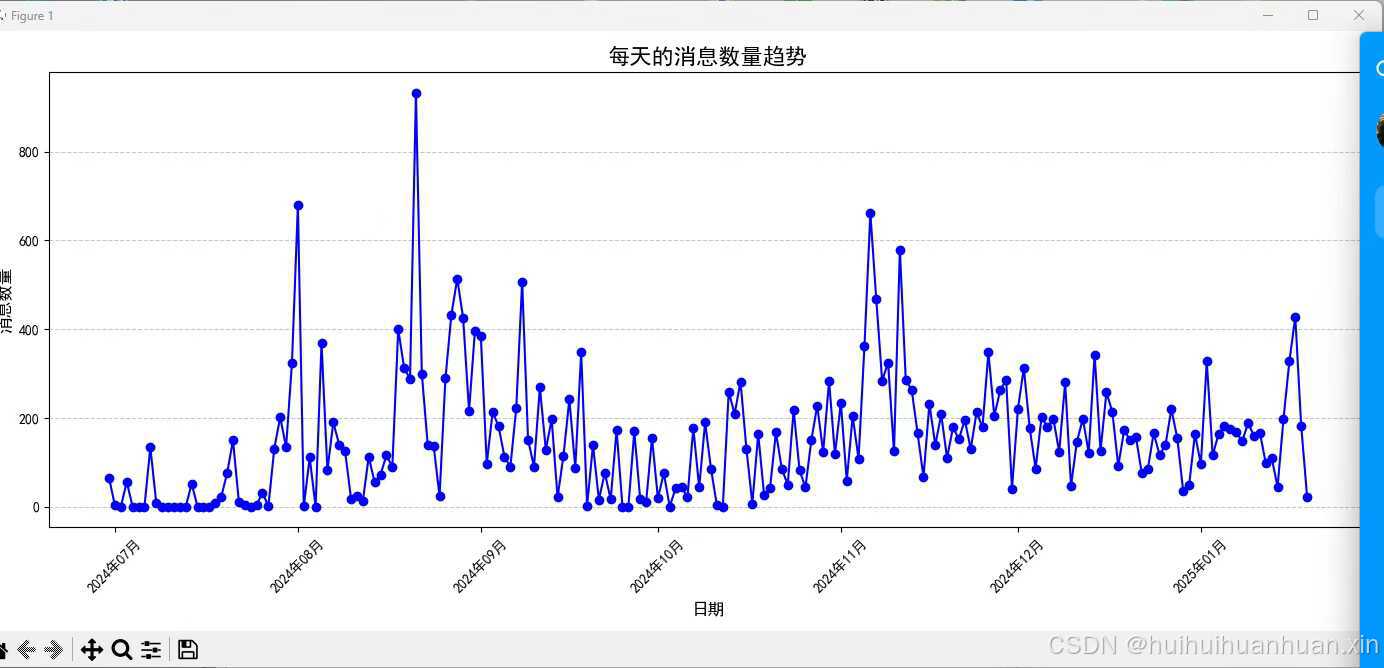
- 每日消息数量趋势:折线图显示每天的消息数量变化。
- 词云生成:展示聊天记录中的高频关键词。
- 提取聊天最多的一天:找出消息最多的一天,并保存当天的聊天内容。
- 提取首条和末条消息:显示每天的首条和末条消息发送者统计。
- 每小时消息统计:统计并显示每小时的消息数量,帮助用户发现活跃的聊天时段。
所有功能都可以通过简单的点击操作进行触发,结果通过图表和日志清晰展示。
如下图:

实现步骤
1. 导入必要的库
首先,我们需要安装并导入一些常用的库:
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter import ttk
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from collections import Counter
import jieba
from matplotlib import rcParams
import matplotlib.dates as mdates
from matplotlib.dates import DateFormatter
import os
其中,tkinter 用于创建图形界面,pandas 用于数据处理,matplotlib 用于数据可视化,jieba 用于中文分词,wordcloud 用于生成词云。
2. 设置图形界面
我们使用 Tkinter 创建了一个简洁的用户界面。用户可以通过点击按钮来触发不同的功能。界面包括:
- 一个文件选择框,允许用户选择 CSV 文件。
- 多个按钮,触发各种分析操作(如绘制消息类型分布饼图、生成每日消息趋势图等)。
- 一个文本框,用于显示分析过程中的日志信息和错误提示。
3. 加载和处理数据
加载数据是该工具的基础。我们用 pandas 的 read_csv 方法加载 CSV 文件,并将 StrTime 字段转化为日期时间格式。为了保证数据的正确性,所有异常情况都进行了处理,确保即使用户上传错误格式的文件,也能给出明确的错误提示。
self.data = pd.read_csv(self.file_path, encoding='utf-8')
self.data['StrTime'] = pd.to_datetime(self.data['StrTime'], format='%Y/%m/%d %H:%M')
4. 功能实现
消息类型分析:我们使用 value_counts 来统计每种消息类型的数量,并生成饼图来展示结果。
type_counts = self.data['Type'].value_counts()
filtered_counts = type_counts[type_counts / total_count >= 0.02]
filtered_counts["其他"] = total_count - filtered_counts.sum()
filtered_counts.plot(kind='pie', autopct='%1.1f%%', startangle=90, colors=plt.cm.tab20.colors)
每日消息数量趋势:使用 resample('D') 按天对数据进行重采样,计算每一天的消息数量,并使用折线图显示变化趋势。
daily_counts = self.data.resample('D', on='StrTime').size()
plt.plot(daily_counts.index, daily_counts.values, color='blue', marker='o', linestyle='-')
词云生成:我们对聊天内容进行分词,统计每个词语的出现频率,然后使用 WordCloud 库生成词云图。
wordcloud = WordCloud(font_path='SimHei.ttf', background_color='white', width=800, height=400).generate_from_frequencies(word_freq)
聊天最多的一天:通过按天重采样并找出消息最多的一天,获取当天的聊天记录,并保存为 CSV 文件。
most_active_day = daily_counts.idxmax().date()
most_active_day_data.to_csv(output_file, index=False, encoding='utf-8')
每小时消息统计:通过提取小时信息,统计每小时的消息数量,并通过柱状图显示最活跃的时段。
self.data['Hour'] = self.data['StrTime'].dt.hour
hourly_counts = self.data.groupby('Hour').size()
hourly_counts.plot(kind='bar', color='skyblue')
下载地址
通过网盘分享的文件:微信聊天记录分析.zip
链接: https://pan.baidu.com/s/1kuSILqRIFb8PsJlPNA7fYw 提取码: 0315
总结
在这篇文章中,我们探讨了如何使用 Python 创建一个简单而强大的聊天数据分析工具,通过对聊天记录的深入分析,我们可以提取关键信息,并以可视化图表的形式展示。通过利用 pandas、matplotlib、jieba 和 wordcloud 等库,我们实现了多种分析功能,包括消息类型分布、每日消息趋势、词云生成、最活跃聊天日的提取、以及每小时消息量的统计。
这种工具能够帮助我们更好地理解聊天数据,识别活跃时段、热门话题和用户行为模式,为数据分析、用户研究和产品改进提供重要依据。
尽管本项目已具备一定的功能,但仍有很大的扩展空间,未来可以进一步增强数据的处理效率、支持更多数据格式的导入,并加入更多交互式的可视化展示。这不仅为聊天记录分析提供了便捷的解决方案,也为如何在数据分析中结合实用功能和用户体验提供了宝贵的经验。
如果你对这个项目感兴趣,或者有任何建议与想法,欢迎提出,我们一起交流与探索

















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









