







本总结是是个人为防止遗忘而作,不得转载和商用。
本章总结优化学习率的知识,而前置知识就是“线性回归、梯度下降算法”,因此如果这一章你看的云里雾里甚至连学习率是什么都不知道的话就需要先吧前置知识搞定了。
其他说明
因为本总结的前置知识是“线性回归、梯度下降算法”,所以之后的内容都是以“求目标函数f(x)的极小值”为目的。
不过不用担心求极大值的话该怎么办,因为直接给f(x)加个负号就将问题转换为了求极小值问题了。
在顺便一提,个人感觉正因为研究了这么多求极小值的东西,于是大伙为了省事,就凡是遇到求极大值的问题则先将其转成求极小值,于是乎会经常看到这句话“习惯上我们将其转换成求极小值”....
什么是优化学习率
以梯度下降说明。
假设我将学习率固定为1时需要迭代10次才会收敛的话,那如果我将学习率改为第一次步长为8,第二次步长为2,则可能两次就收敛了。(这里的数字不太准确,但大概是这样的意思)
很明显,后者的收敛速度更快,而上面对学习率的调整就是优化学习率。
PS:就好像一个人下山,如果他以每步1M步伐下山可能要走10小时,那若他一开始以每步8M,然后等走了一半多了在每步2M的话,则到达山脚的时间会明显缩短。
话说,虽然在写这片文章时我还没入这一行,但我听到的都是些“工作时很多时候就拍脑门选一个学习率就好,若感觉收敛太慢就调大些”这样的内容,感觉没必要在这上面花费太多功夫。
不过个人感觉,如果能把这个知识掌握了,那工作起来会事半功倍。
怎么优化学习率
这个得一点点讲了。
既然我们的目标是优化学习率,那我们需要先转换下视角:你看啊,对于某个函数,如果我们的目标就是求函数中的参数x,那我们就将函数看成是关于x的函数。同理,既然这里的目标是函数中的学习率α,那我们就将函数看作是关于α的函数。又因为一般函数模型是:f(xk+αdk),其中dk是搜索方向(如对梯度下降来说,dk是负梯度方向),所以在转换视角后,我们将其看作是关于α的函数h(α),即:
h(α)= f(xk+αdk)
PS:一般学习率是大于0的,即α>0
既然已经是关于α的函数了,那对于梯度下降来说我们的目标就从“x为多少时函数的值最小 -- 注:样本xk是已知的,当前的搜索方向dk即梯度也可以求出来,只不过哪个xk会使函数最小不知道”,即:
arg_xmin f(xk+αdk)
变成了“在给定xk和dk的前提下,寻找α为多少时,能让函数下降的最快”,即:求对关于α的函数h(α)求“α = ? 时,函数h(α)最小”。
这就简单了,对h(α)求导并另导数为0呗,即:
h’(α)= ▽f(xk+αdk)Tdk= 0
这样求得的α就是一个对当前xk的一个十分优秀的学习率α。
画个图的话就像这样:
以前学习率固定时,可能每次只下降这么多:
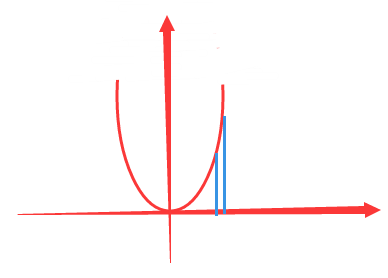
通过上面的方法就能一次性下降这么多(粉线是切线)
不过,如果你细心的话现在应该有点绕,即:h(α) 不就是 f(xk+αdk) 吗?那我对h(α) 求导后找到个最小值不就是f(xk+αdk)的最小值吗?按照这里理论,我不就一次性让函数收敛了?怎么上面的图还没有一次性收敛?你画错了吧!
嘛,上面的图的确有些不准确,是帮助理解而已,因此我要补充下面这句话:对h(α)求导并让导数为0后可以得到一个对当前xk的十分优秀的学习率α,但这个α可能并不能让原函数一次性收敛。
原因是:我们之前通过“视角转换”将函数变成了关于α的函数h(α),所以如果画坐标轴的话,那坐标轴的x轴就变成了α轴,即:函数图像会变成关于α的图像(这和原函数的图像是不同的)。于是对h(α)求导并让导数为0后可以得出一个关于α的图像的极小值点,这时就得到了一个“对当前xk的一个十分优秀的学习率α”,但因为“关于α的图像和原函数的关于x的图像是两个图像”,所以这个α可能并不能让原函数一次性收敛。
不过,虽然不能让原函数一次性收敛,但无论如何,也比固定α好,对吧。
现在总结下上面的步骤:
1、使用原函数对α求导,求出学习率α;
2、按照搜索方向更新函数(如梯度下降)
3、重复上面两步直到收敛。
一个更简单的方法(二分线性搜索)
说实话啊,虽然上面的步骤没问题,但如果计算h’(α)=0十分恶心咋办?
难道(╯‵□′)╯︵┻━┻不求了?
当然可以!
且听我一一道来。
首先,对于f(xk+αdk),如果令α = 0的话就有:
h’(0)= ▽f(xk +0*dk)Tdk = ▽f(xk)Tdk
上面的▽f(xk)是梯度(这是对原函数求导啊),dk是搜索方向,如果令dk为负梯度方向即:dk = -▽f(xk) 的话,就有:h’(0) < 0,即α = 0时,h’(0) < 0。
这时如果我们找到一个足够大的α,使得h’(α)>0的话,则必存在某α,可以使h’(α)=0,而这个α就是我们要寻找的学习率。
于!是!使用折半查找就OK了!如:
对于h’(α1)< 0、h’(α2) > 0
若h’( (α1+α2)/2 ) < 0,那就另a1 = (α1+α2)/2
若h’( (α1+α2)/2 ) > 0,那就另a2 = (α1+α2)/2
重复上面的步骤,直到找到h’(α)=0,这样就找到了α。
再优化一下(回溯线性搜索)
上面的折半查找已经很方便了,但以h’(α)=0作为是否找到α的条件还有些麻烦,而使用回溯线性搜索的Arimijo准则作为判断条件就很方便了。
首先是Armijo准则:首先给一个较大的学习率,然后不断缩减学习率,如果对于函数f(xk+αdk)当前的学习率使函数从当前的位置f(xk)的减小一定程度后还大于预设的期望值,那这个学习率就符合要求了。
什么意思?你看,对于函数f(xk+αdk),既然是求最小值,那对于当前的值f(xk)减小一定程度后就有个新值f(xk+1),于是,如果我们将f(xk+1)作为预设的期望值,即我们希望f(xk)在某个学习率α的情况下减小一定程度后可以到达f(xk+1),那这个α就是我们希望得到的α了对吧。而因为 这个减小程度在Armijo准则中是公式:
c1α▽f(xk)Tdk,c1∈(0, 1)
因为dk一般取梯度负方向,所以用式子表达上面的话的话就是:
f(xk+1)= f(xk) + c1α▽f(xk)Tdk,c1∈(0, 1)
但是在计算中实现上面的等号挺麻烦的,因为我们是不断缩减学习率,只要我们缩减的程度没把握好,就会有“上一个还f(xk+1) < f(xk) + c1α▽f(xk)Tdk,下一个就f(xk+1) > f(xk) +c1α▽f(xk)Tdk”的情况。
于是为了方便,只要f(xk+1) ≤ f(xk) + c1α▽f(xk)Tdk就OK了,而这就是Armijo准则的方程。
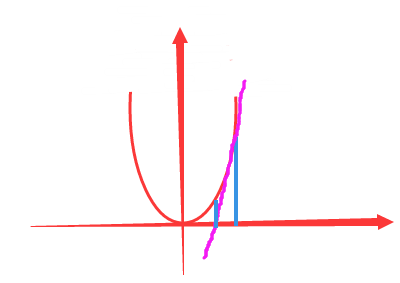
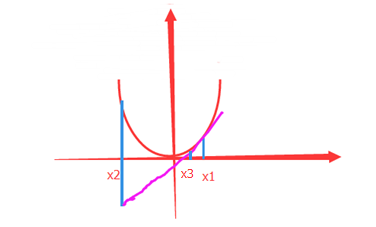
| PS:为什么要给一个较大的学习率后还不停的缩减?直接选这个较大的学习率不就好了? 看下图: 如果学习率太大一下子从x1走到了x2的话,那还求个屁的最小值啊。 于是我们就先规定个期望值,比如:你这次下降到f(x3)就行了。这样就能控制学习率为一个我们期望的值了。 |
回溯与二分线性搜索的异同
二分线性搜索的目标是求得满足h’(α)≈0的最优步长近似值,而回溯线性搜索放松了对步长的约束,只要步长能使函数值有足够大的变化即可。
二分线性搜索可以减少下降次数,但在计算最优步长上花费了不少代价;回溯线性搜索找到一个差不多的步长即可。
回溯线性搜索代码(出自邹博老师)

红框:若传来的学习率a不满足h’(a) > 0就将a扩大2倍,因此到达绿色框的代码时a已经满足h’(a) > 0。或者说红框中是为了找到“第一个”不满足函数下降的学习率。正常情况下,只要沿着负梯度方向下降微小的值,next<now是恒成立的,因此,不断执行红框的代码,可以不断抬高学习率,直到发现不满足条件的(即:“步子太大”),从而保证接下来绿框中的有效执行。
绿框: 如果学习率不满足Armijo准则,就把学习率a降一半,看看新的学习率是否满足。
最后返回学习率。
回溯线性搜索的改进-二次插值法
怎么还没完啊?
我也这样想过,但改进是永无止境的,认命吧- -....
不过在介绍插值法之前还得再说个很简单的预备知识,如下:
如果知道3个点,那就可以确定一个二次曲线经过这三个已知点,换句话说为了确定一个二次曲线就需要3个类型的信息,因此我们就可以这样想:如果题目给定了在一个点x1处的函数值y1=f(x1)、在该点处的切线值即x1处的导数值f’(x1)、x2点处的函数值y2=f(x2),那么也是能唯一的确定一个二次函数,看下图:
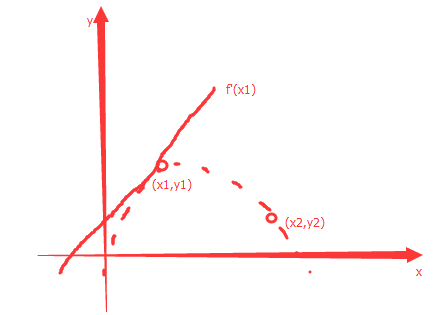
而如果x1=0,x2=a的话,那这个二次函数的方程就是下面的样子:
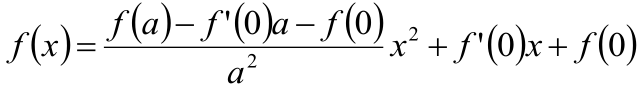
PS:这个是这样算出来的: 假设这个二次函数的方程是 f(x) = px2 + qx + z,因为f(0)、f’(0)、f(a)是已知的,f’(x)的可以求出来,即f’(x) = 2px + q,那把这三个值代入f(x)和f’(x)就可以把p、q、z求出来了,就得出上面的式子了。
对这个式子求极值的方法是:
假设式子为:h(a) = qx2 + px + z
则x在 - p/(2q) 处可以取得极值
这是初中的知识,所以别问为什么,像初中生一样直接拿去用就好。
好了预备知识说完了,下面介绍插值法。
经过前面的内容已经知道:我们找学习率a的方法是,找一个h’(a) < 0,一个h’(a) > 0,然后不停的二分查找,直到h’(a) = 0。
那有没有一个更好的方法?有的。
首先,对于学习率a,其函数h(a)是一个二次函数。
PS:一个a代入h(a)有一个值,最后就是在以a为横轴h(a)为纵轴的坐标轴上画了一条弯曲的曲线,这是个二次曲线没问题吧
然后对于这个二次函数我们总结下已知的信息:
1,h(a)一定经过两个点:a=0处的值h(0)、当前的准备尝试的学习率a0的值h(a0)。其中h(0)就是当前的函数值f(xk),因为对于h(α) = f(xk+αdk),如果a=0,就有h(0) = f(xk);而当前准备尝试的学习率如果满足Armijo准则就直接返回该学习率,否则才需要找个更好的学习率。
2,当前xk处的的导数可以求出来,即f’(xk)已知,也就是h’(0)已知。
即 :已知h(0)、h’(0)、h(a0)
接下来利用刚才的预备知识,我们就可以构造出一个二次函数来近似学习率a的曲线了,即:
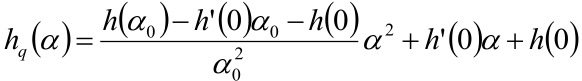
PS:这个只是近似,因为只是通过3个数据来确定的曲线,和真正的h(a)是有些不同的,不过,虽然这条曲线和真正的曲线有些误差,但可以使用,这就足够了。
而我们的目标是什么来着?对,求h’(a)=0时的a,也就是求h(a)的极值,那就直接利用初中的知识
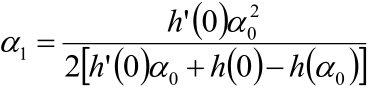
求hq(a)的极值就OK了,这多简单,初中生都会。
过程总结
1,利用式1求a1
2,若a1满足Armijo准则,则输出该学习率,否则继续迭代。
代码(出自邹博老师)

最后总结
一般的说,回溯线性搜索和二次插值线性搜索能够基本满足实践中的需要。














 1378
1378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









