







文章提出了一个新的Idea, 不再是用传统的二值去标记一幅图像含不含attribute,而是用对比的关系去描述图像,对于某个attribute,一幅图像呈现的比另一幅图像多。例如“A is smiling more than B” or “A is crowded more than B”。从而获得更多的supervision,使得算法在预测类别时更加稳健,准确率也更高。
作者将其做了两个方面的应用。一个是zero-shot transfer learning。一个是用对比特征描述一幅新的图像。
attribute有很多功能:
1.它能够帮助描述和识别外观相近的物体,可以参见:A. Farhadi and I. Endres and D. Hoiem, and D. Forsyth, Describing objects by their attributes和C.H. Lampert and H. Nickisch, and S. Harmeling, Learning to detect unseen object classes by between-class attribute transfer
2.能够解决zero-shot learning的问题,也就是零样本分类的问题。我感觉这种功能的实现主要依赖于把预先定 义的属性作为先验,然后进行transfer learning。可以参见:D. Parikh and K. Grauman, Relative attributes和J. Liu and B. Kuipers, and S. Savarese, Recognizing human actions by attributes
首先有一堆来自不同类别的图像I={i},以及集合O and S,对每一个attribute m,有
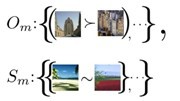
表示若(I,j)属于Om,则atrribute m在i中比j有更强的体现。若(I,j)属于Sm,则attribute m在i 和J中的体现差不多。然后对每个attribute m,学习一个ranking function。
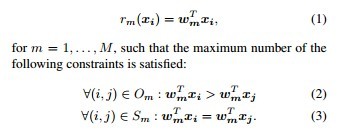
从而得到m个函数,对每一个新的图像,可以得到这幅图像对m个attributes的体现强度。
这个问题是NP难的,因此引入松弛变量转化成不等式最优化问题。(其中包含了对这个过程与SVM对应的相应)我们改编了最初用来网页排序的公式,我们采用二次损失函数和相似性约束解决最优化问题:
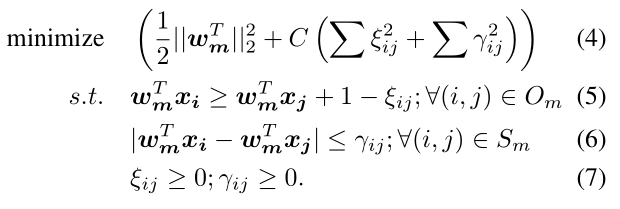
For zero-shot transfer learning,这里所谓zero-shot,即指在需要在分类的某些类别上是没有训练图像的。总共N个类别,S 个seen, U个 unseen,S+U=N。假设每个类别在attributes空间中是一个高斯模型。对于每个属于S的类别,通过其中的训练图像的attributes值计算高斯模型的均值和方差。而对于属于U的没有训练数据的类别,则需要通过这个类别与S中类别的Atrributes大小关系来估计U中的均值和方差,具体见paper。这样对于每个类别,就得到了一个generative 模型,可以对新图像进行分类了。对于一幅新的图像,首先将其转换为m维的attributes score向量,然后用极大似然法去估计这副图像的类别。即
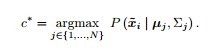
For describing new images,就是用新图像的m维attributes score去与已有的图像库里面的score进行比较。这样对于某个attribute m, 可以说明新图像的体现强度比哪些图像强,或比哪些图像弱。具体如何选取作比较的图像需要与新图像有一定的距离,太近可能Overfitting,太远可能underfitting。
最后作者在Outdoor Scene Recognition(OSR) dataset,以及在Public Figure Face Database (PubFig)这两个数据集上进行了实验,得到了比用二值Attributes训练出的分类器效果要好很多。具体见paper。















 1212
1212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









