







Dify本地部署(三)
书接上文:前两个章节介绍了服务器、基础环境、和容器镜像说明,本章针对dify功能做相关扫盲。
前言
提示:这里可以添加本文要记录的大概内容:
首先说明:dify本身不涵盖模型、智能体,它的能力是集成模型功能,能在可视化的方式下进行模型功能调用测试。你可以理解模型为人的大脑,而dify为人的四肢(我觉得比喻还是比较形象的 嘿嘿)----闲话少唠 直接上车!
补充其他“四肢” (相关的能力验证 后续有时间单独出篇幅)各有特色 按需使用

一、模型供应商是什么?
通俗点讲:你创造的智能体要使用的的“脑子”
专业点讲:deepseek-r1 qwen2.5 google/gemma-2-27b-it
1.在哪里添加
(注册省略 也就是邮箱+用户名+密码 )
访问localhost 注册登陆后点击右上角图标进入设置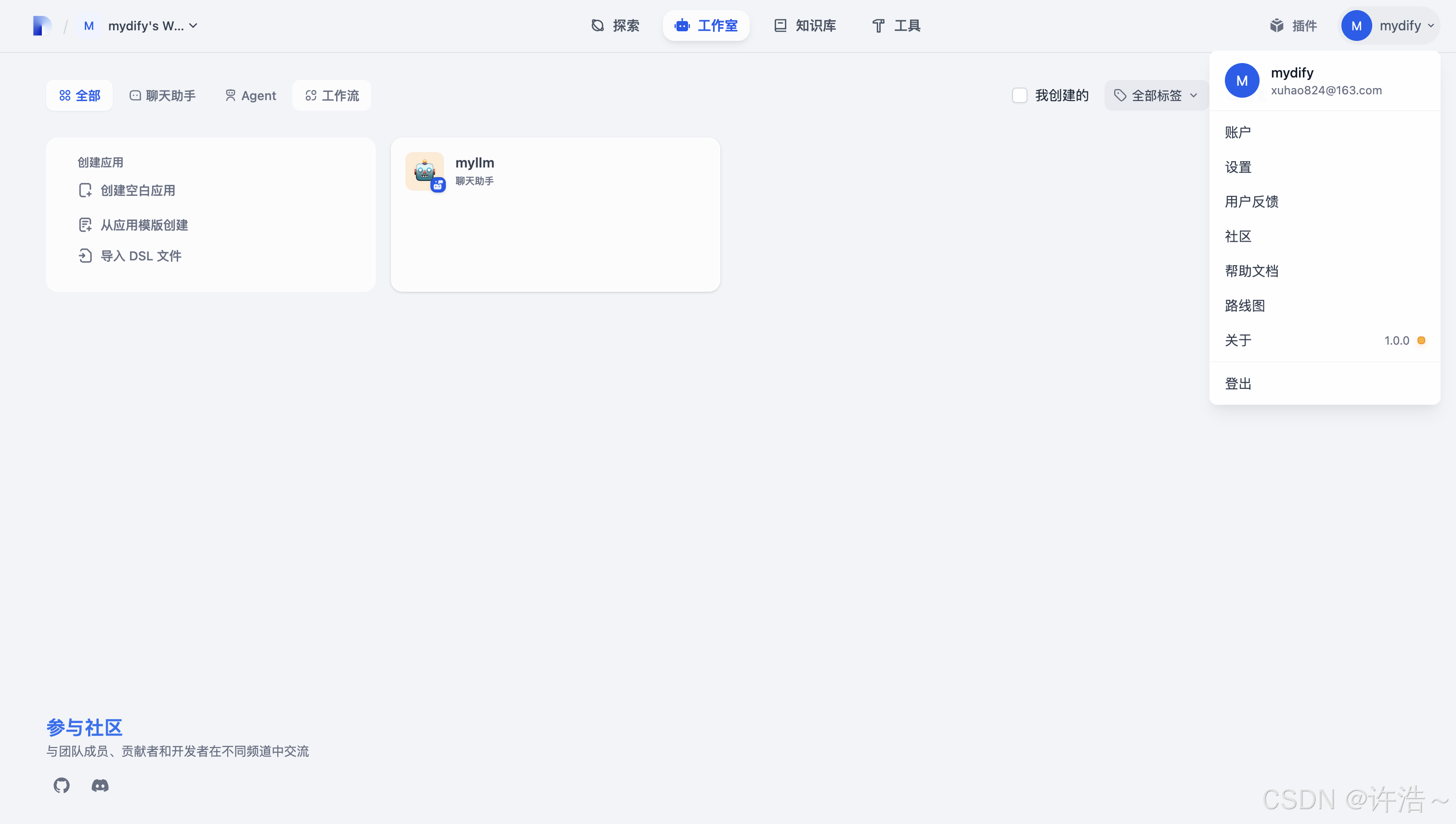
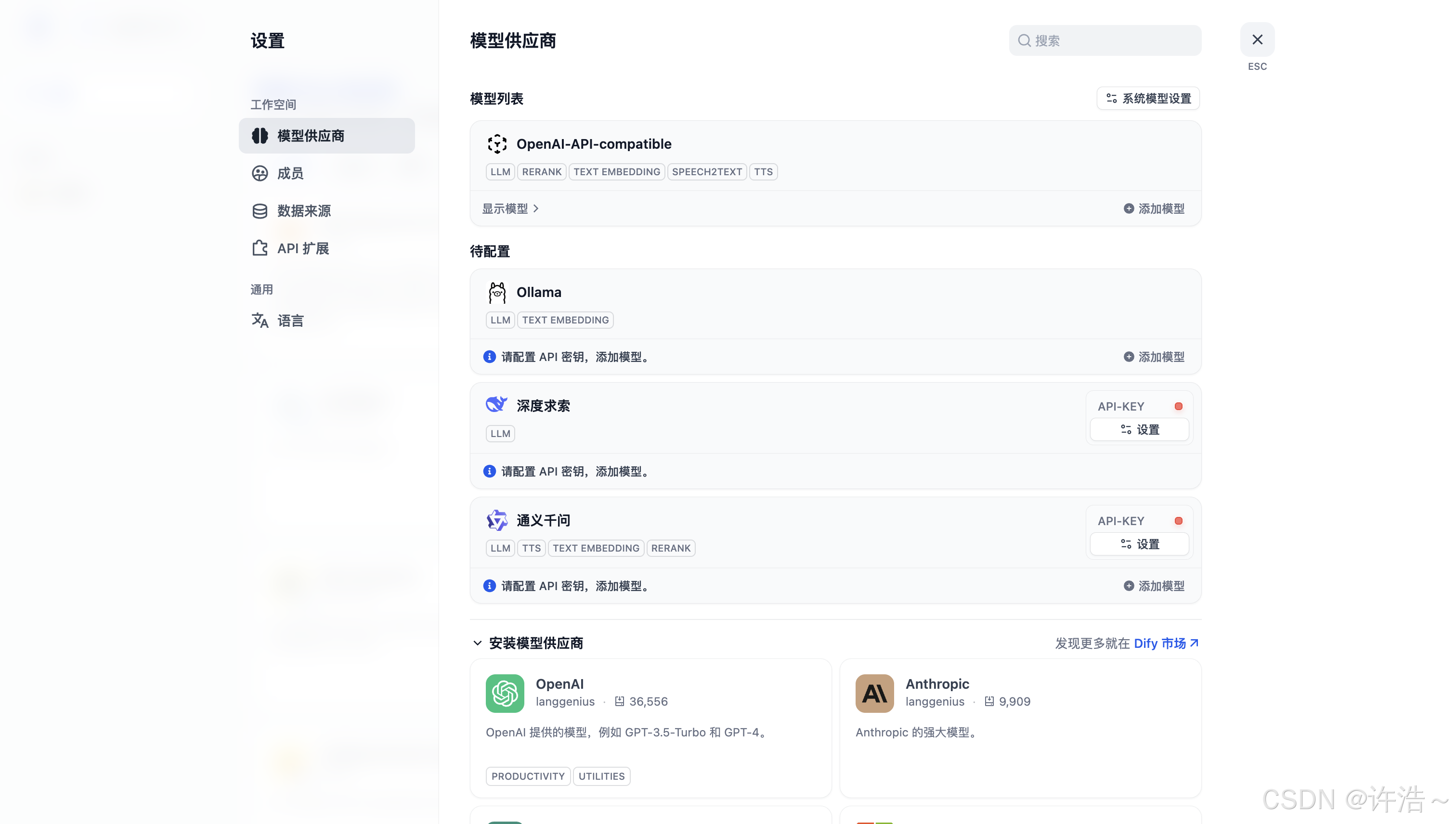
2.如何添加
本段以通义千问(阿里百炼大模型)为例
阿里云账号有吧(支付宝直接扫码登录访问控制台)
https://account.aliyun.com
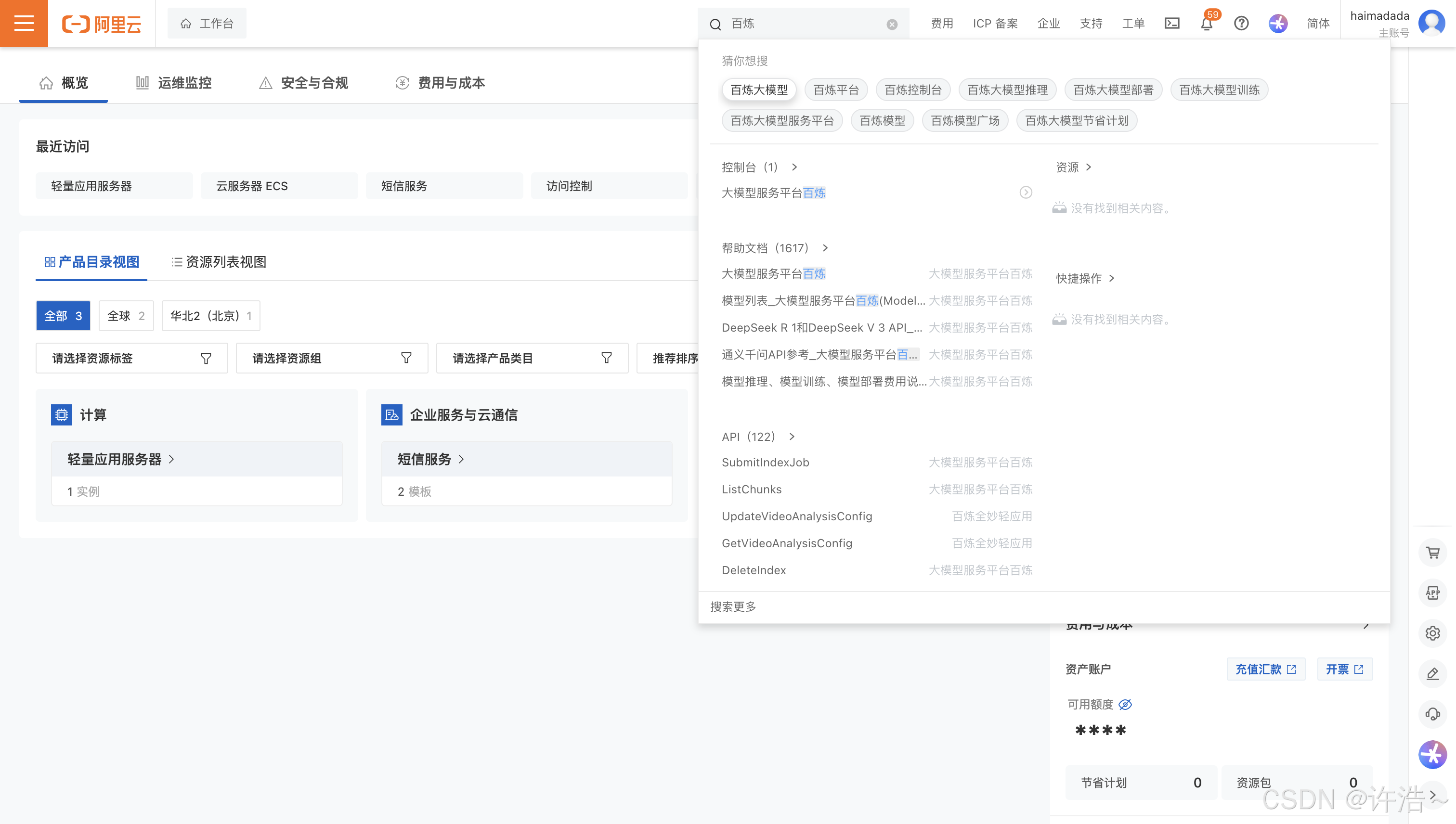
直接搜索–百炼大模型服务平台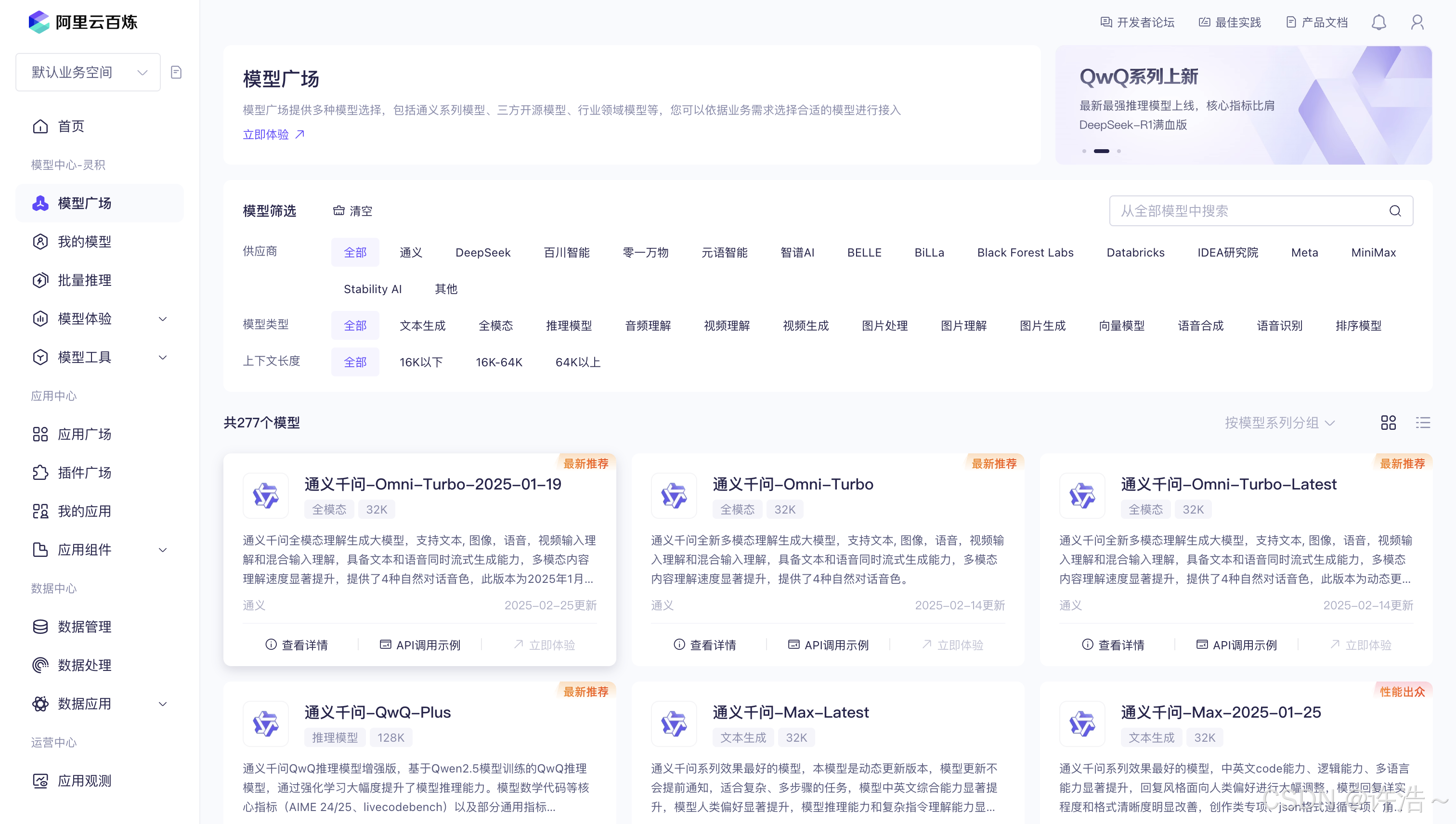
模型广场中 根据需求选择对应模型
创建自己的api-key并复制
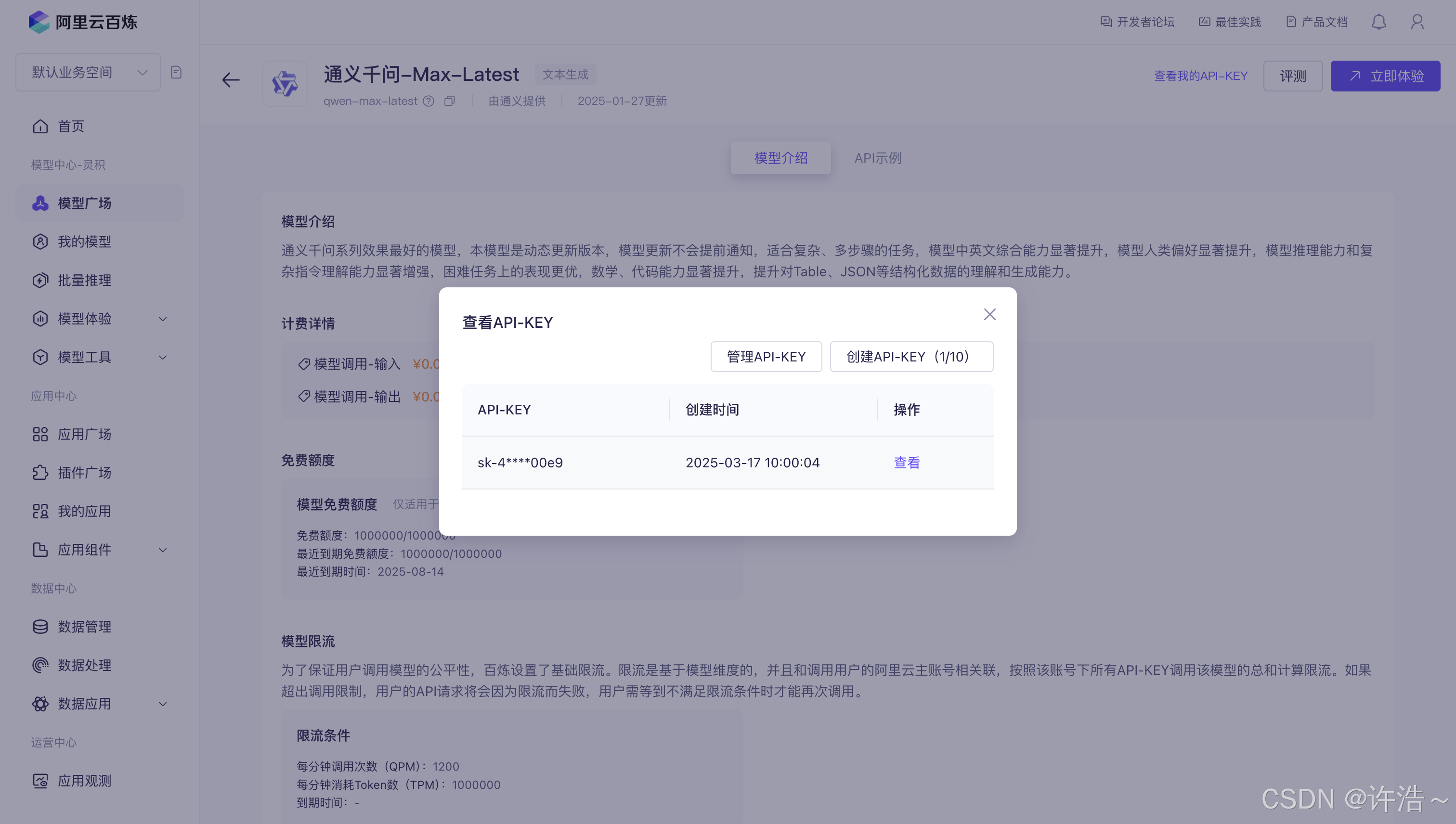
3.添加api-key
然后讲复制的api-key添加到列项1中的 通义千问(初始化没有的话 下边有安装的插件无脑点击就完了)中
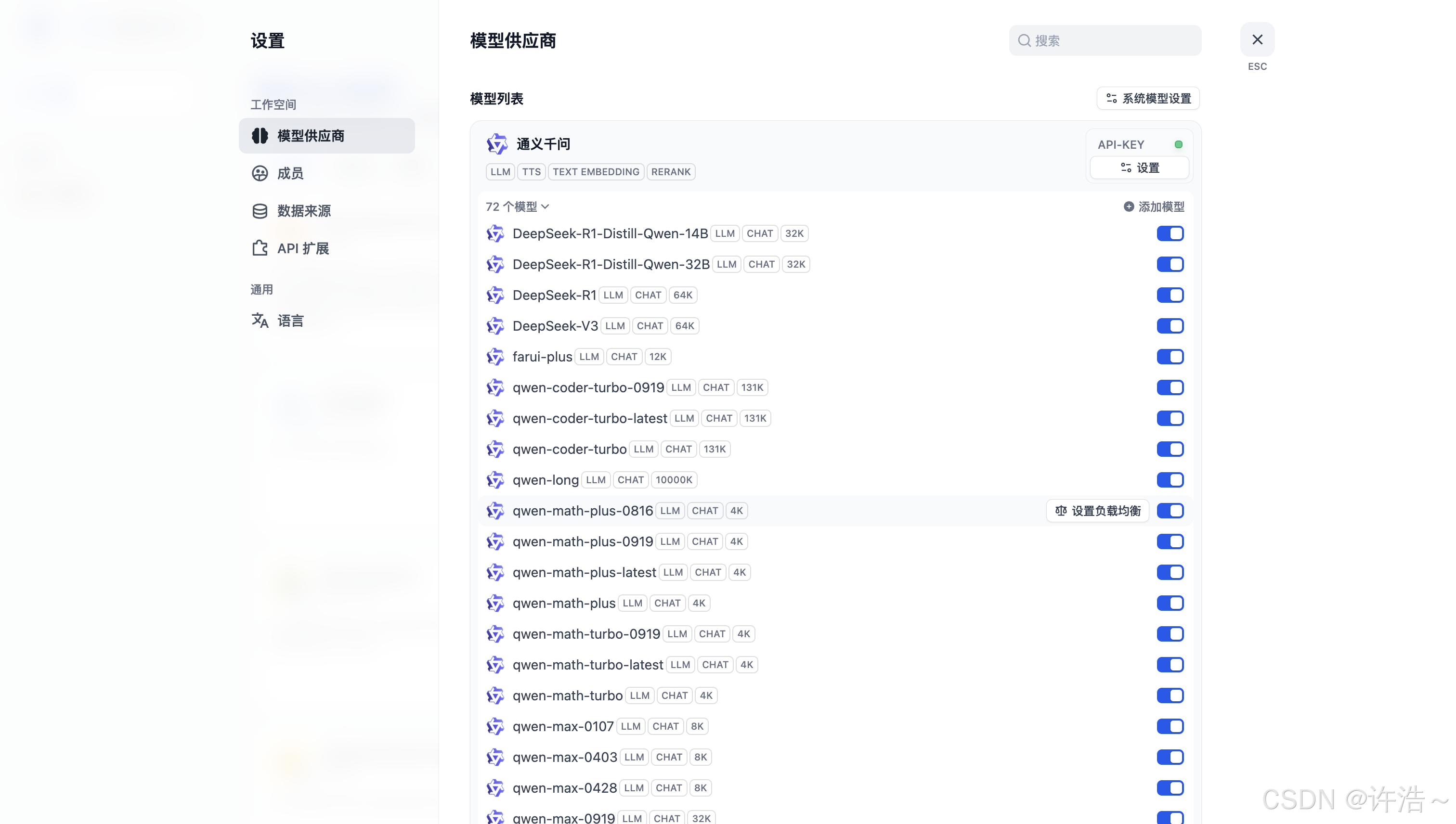
(又得啰嗦两句:是不是低估了各位看客姥爷 是不是太过于啰嗦 没办法兄弟们私信说是讲的多泛泛了 不知道怎么实现 觉得啰嗦直接略过 咯咯咯)
针对各大平台的免费tokens量
通义千问100w一个模型
硅基流动200w一个模型
。。。。
你是用deepseek 官方提供的界面还不如自己配置调用(官方目测限流过 小孩子问的太多容易崩溃哦 )
针对各大供应商的免费量。如果是你自己玩玩 能玩一年半载都用不完 当然如果你是模型微调 注意用量 实打实的的软妹币会花出去 哈哈哈
二、如何配置智能体
1.创建一个聊天
工作室下边创建对应应用

选择对应的模型
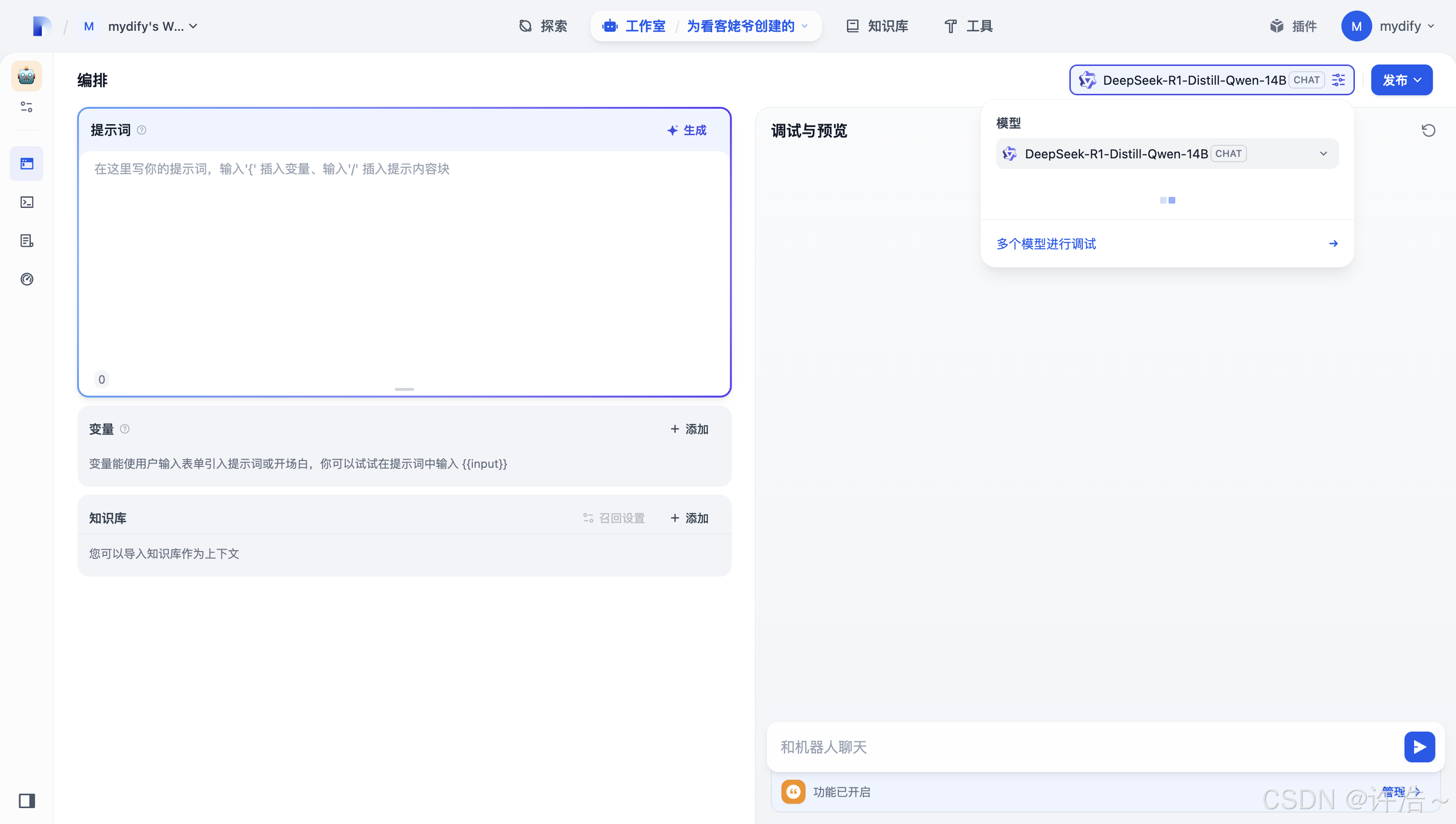
发布后就可以使用咯
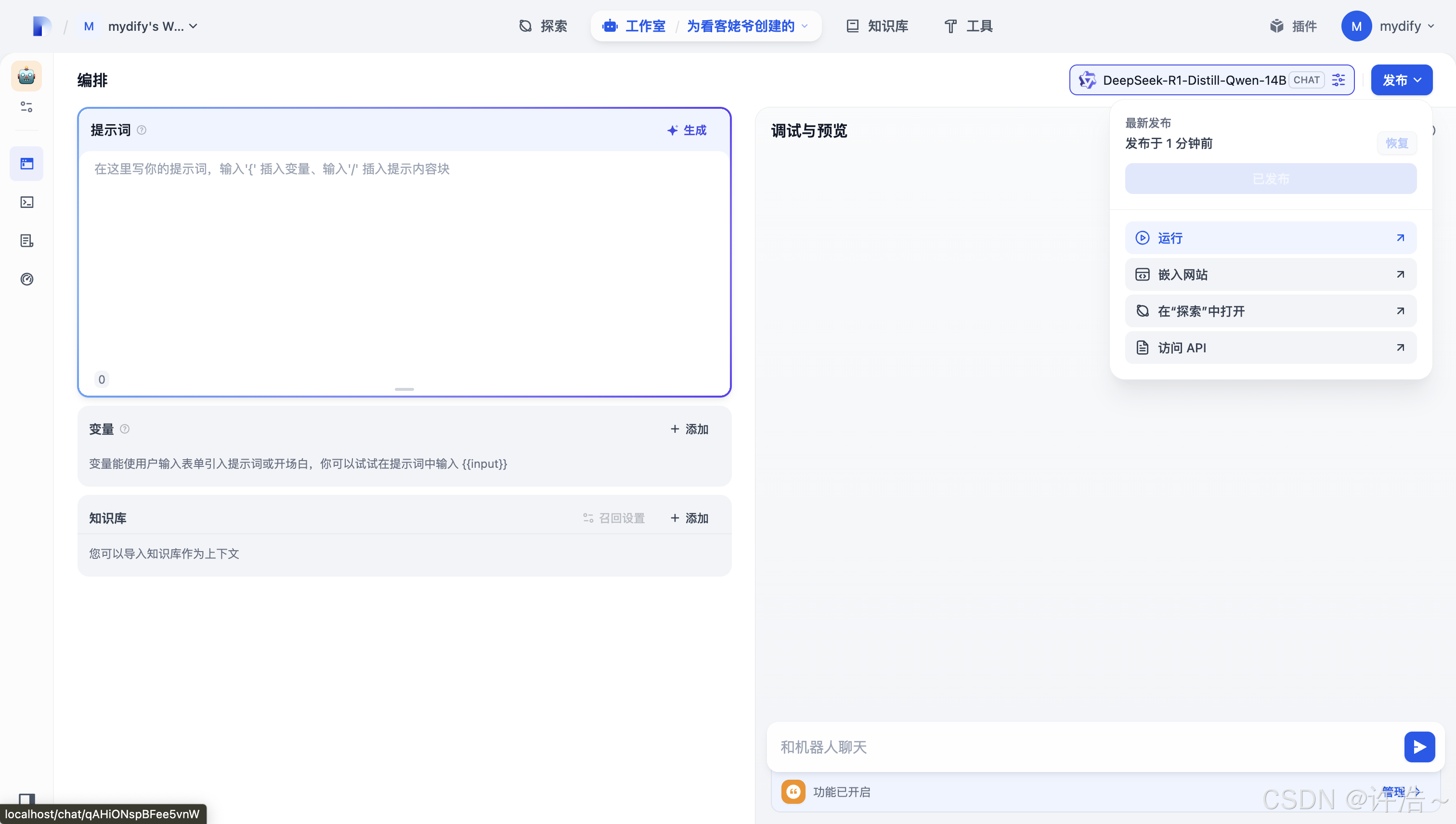
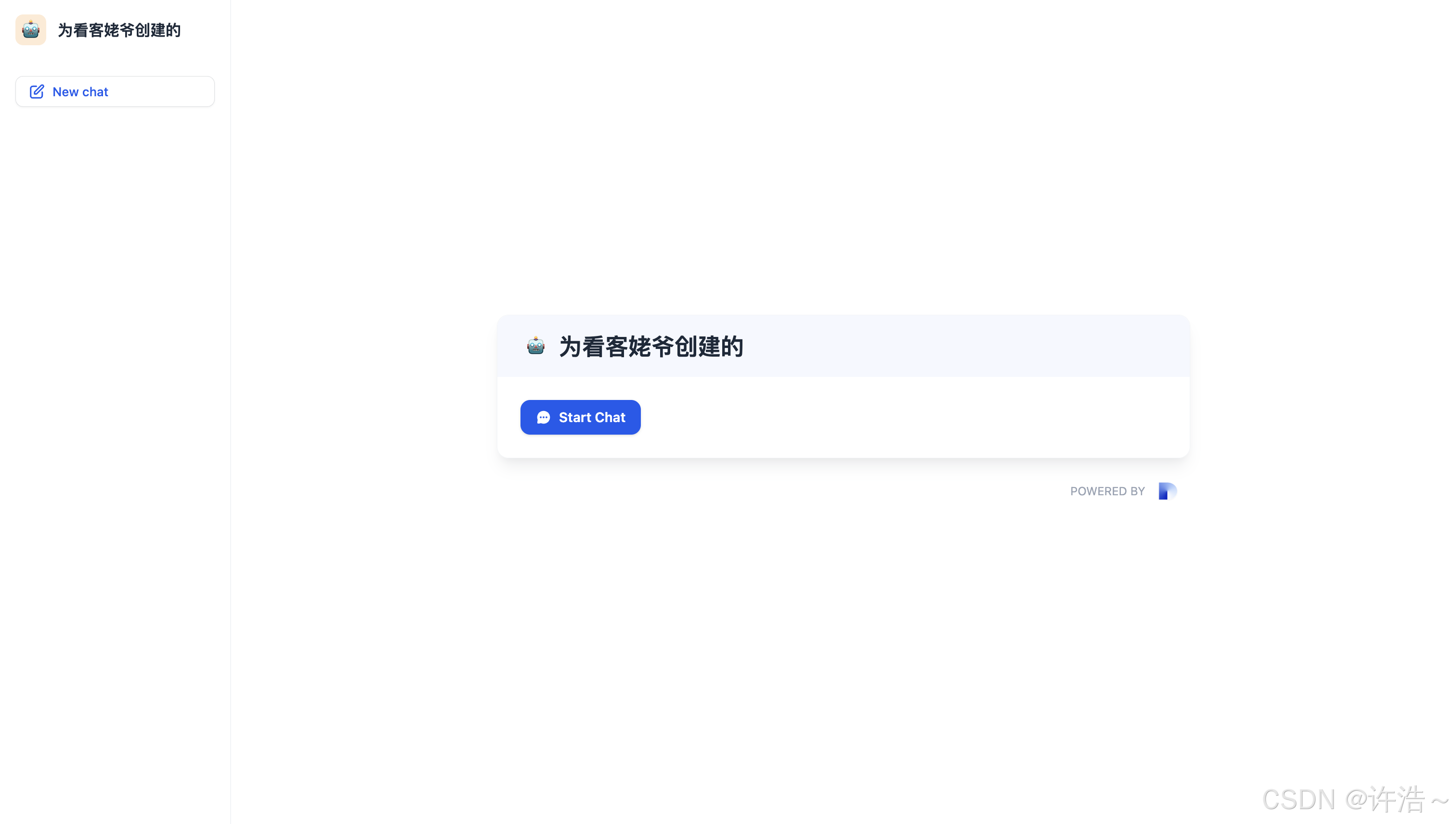
好咯
接下来你就可以问你那些觉得高端的问题了。
目前我验证了不少的语言模型及向量模型
目前我觉得大语言模型qwen max latest 较为合理(个人使用感受)deepseek倒不是不优秀 而是话太多(我问问题我只想知道结果)
2.创建知识库(内部)
创建本地知识库
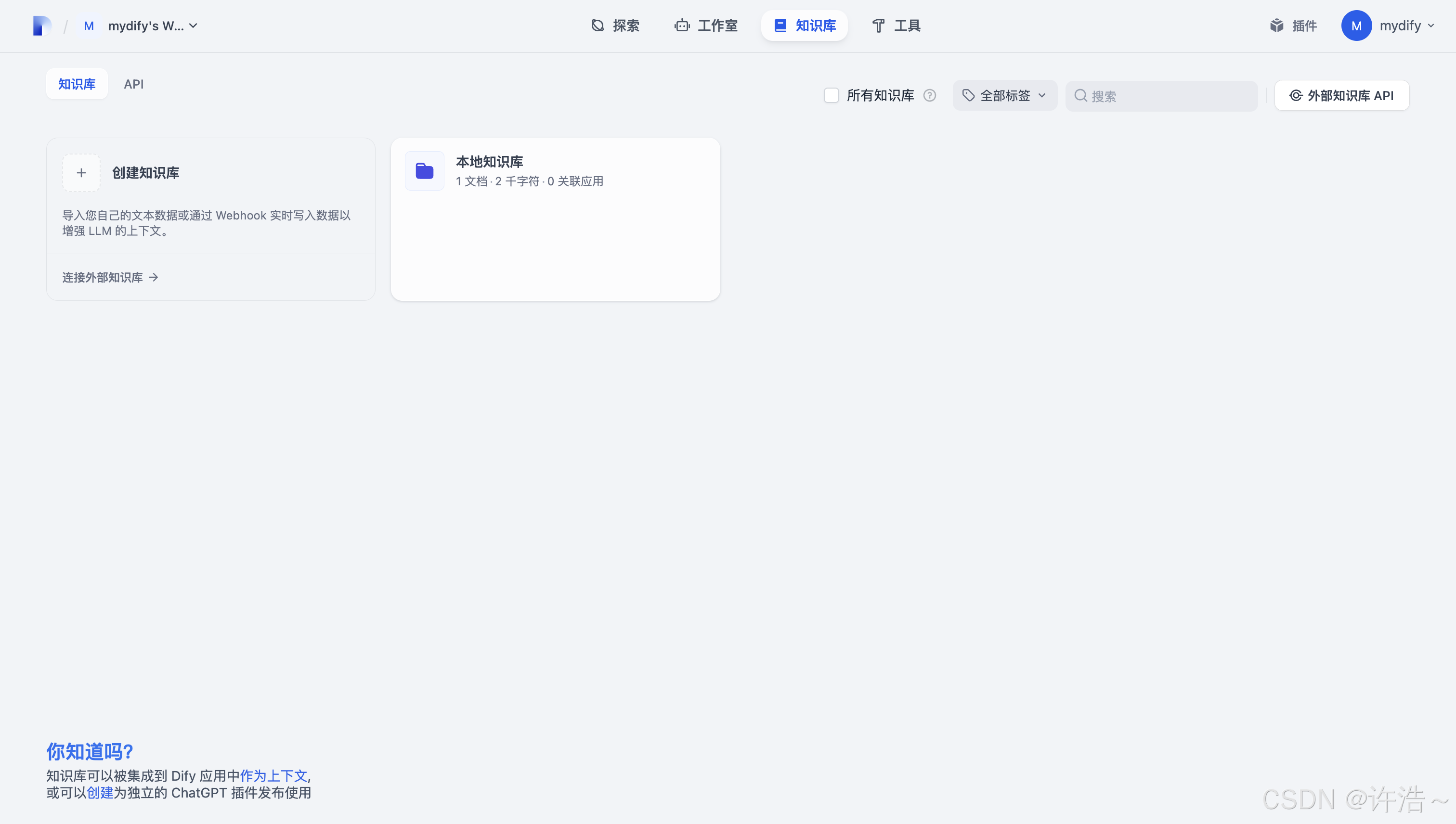
添加对应文件
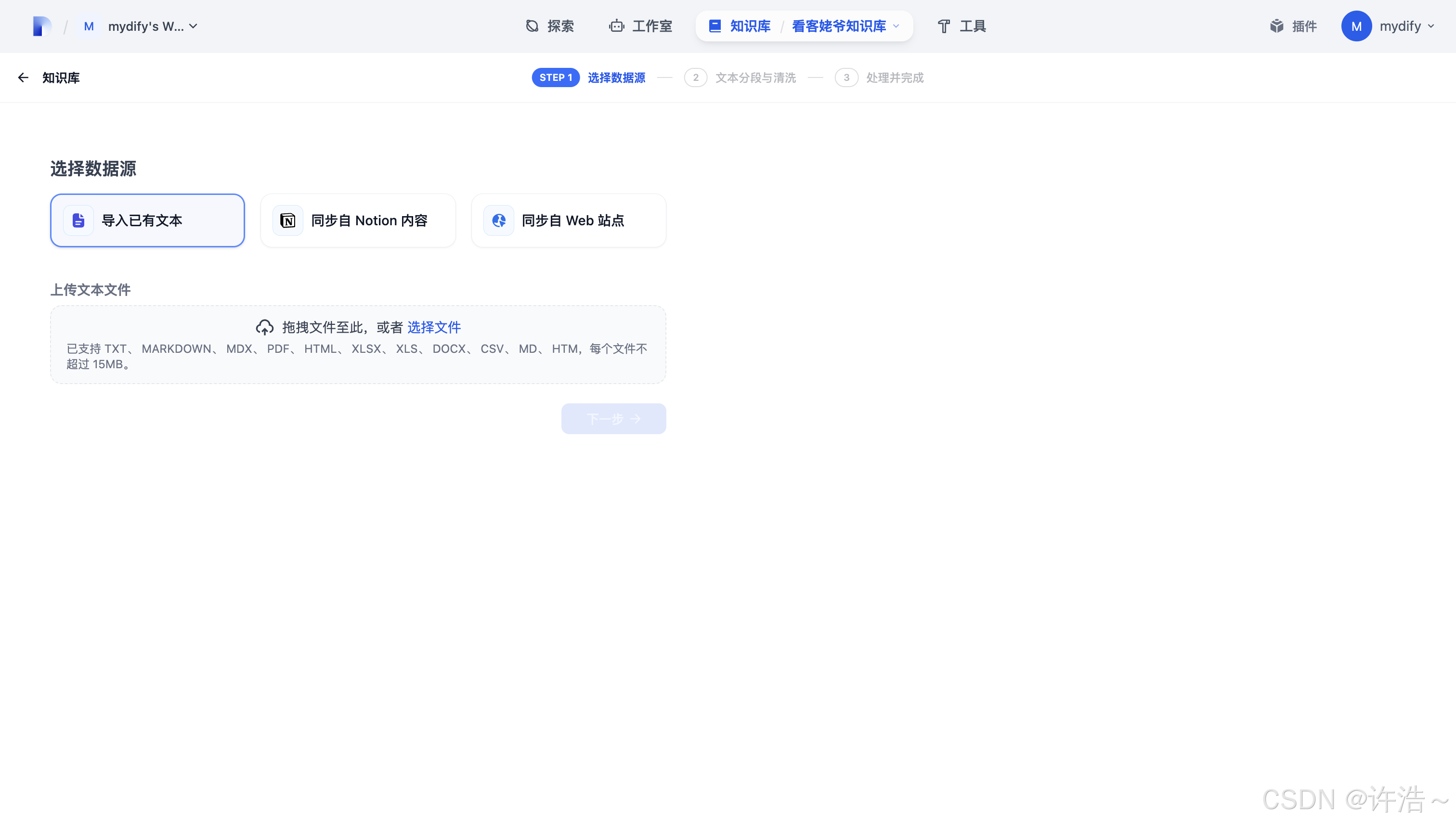
选择对应知识库切分
(这块得啰嗦两句:首先向量模型相当于 一个专用模型 针对用文档拆分及分片 简单理解就是切分后让自然语言模型学习的过程更加合理)
目前我验证的较多的向量模型 较为合理且切分度较高的是它(如果还有比较好的 评论 私信我试试 感谢看官老爷 哈哈哈)

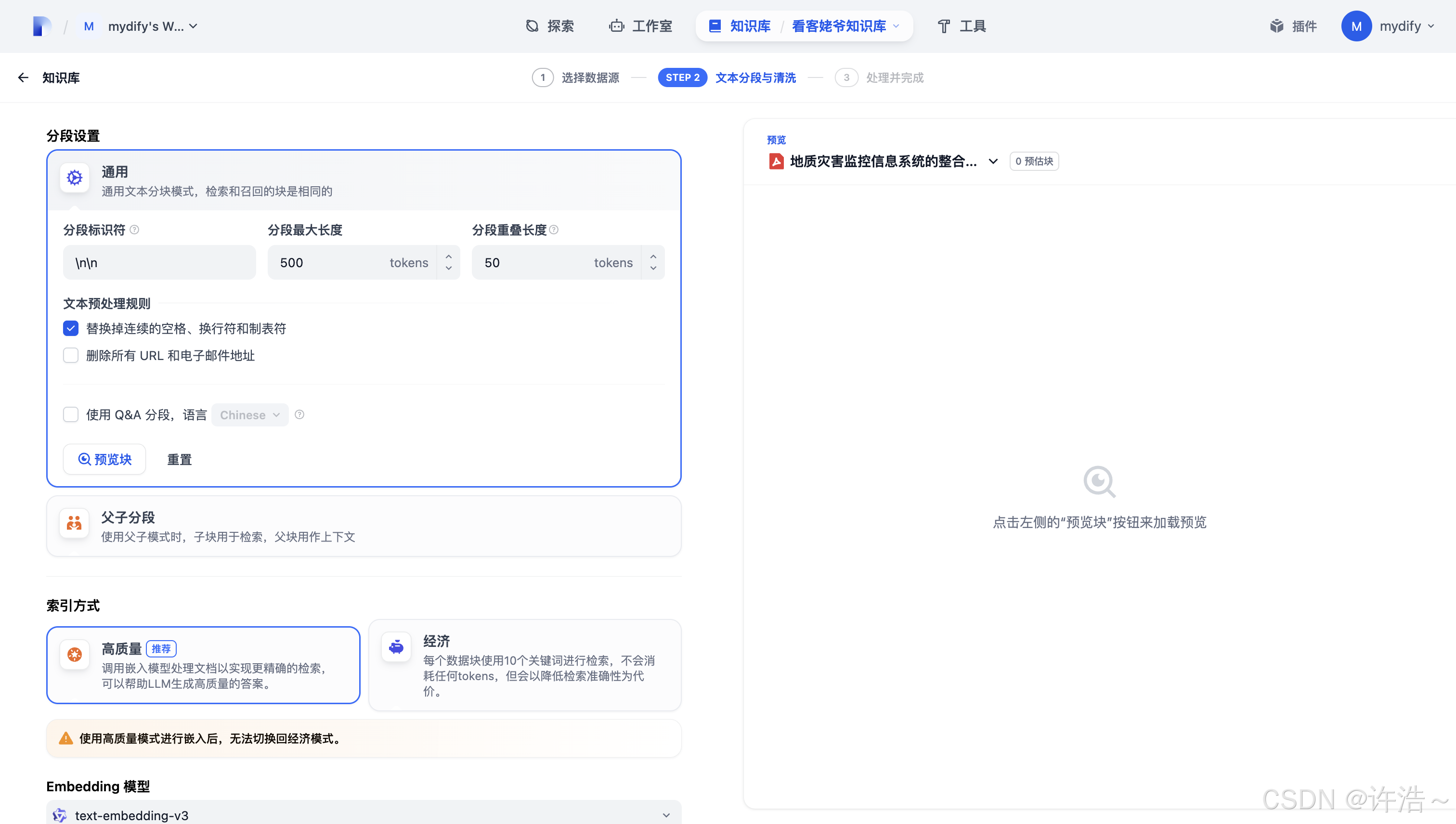
同样在选择后 记住一定要看看拆分的分片是否合理 文档中所有的段落是否完整
没有那个模型是能完完整整 条理清楚的适配所有文件的 所以人为干预尤为重要。
另外在补充一个 实践才能越靠近真相 微调也是只能越接近
总结
提示:这里对文章进行总结:
1.智能体
阿里
**针对于标准答案的问答模型如果想让模型完全理解并回答的答案无限接近于正确答案:阿里解决方案负责人给出的是2000+的问题对 进行投喂(针对于qwen的相关模型) **
华为
**针对于知识库相关的能力及模型微调目前也是需要人工干预,另外华为云上也有一键部署的dify应用。 **

2.知识库
如果你想让你的知识库被大模型识别的更加准确,我给出的简单方案,
1、使用问题对方式
2、m3向量模型(上文中有全称呼)
3、文档中的流程图需要添加箭头并附加解释
4、文档中的表哥拆分单元格不合并,让冗余
5、pdf文档中需要鉴别文档中文字尽量不为图片
6、markdown文档效果更好


















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











