







复现论文
PureGaze
PureGaze Overview

这篇文章在purify的角度重新定义了gaze estimation的这个问题。
对提纯问题的定义
基于提纯的思想,可以把 gaze estimation 的问题定义为 g = F( E( I ) )。
其中,E 是一个特征提取的函数,F 是一个回归的函数,I 是输入模型的 Face/Eye image,g 是estimated gaze。
同时,定义 Z = E( I ),Z 为提取到的特征。
在此基础上,可以认为输入的 I 就是一系列特征的集合。可以把输入特征分为两大类:一类是与gaze有关的特征,表示为 G,一类是与gaze无关的剩余特征,如光照(illumination),个体信息(identity)~~,外貌(appearance)、表情(expression)~~等等,表示为 N。
G 和 N 满足以下公式:
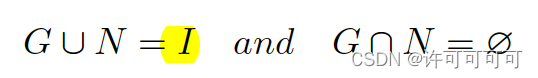
于是我们的任务就是——训练出足够好的特征提取器 E,使其*提纯出不包括视线无关特征 N 的特征 Z*。需要注意的是,我们认为与视线弱相关的信息也应该被忽略掉,已提高泛化性能。
自对抗的网络框架
我们设计了两个任务同时来做对抗:
-
最小化图像 I 和提取出的特征 Z 的互信息,这也表示着提取特征 Z 应该包含较少的图像信息。
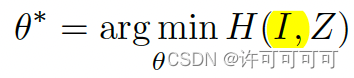
-
最大化 gaze相关特征 G 和提取出的特征 Z 的互信息,提出特征 Z 应该保留更多的gaze相关信息。
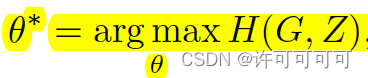
自对抗的方法
两个任务组成了一个自对抗的提纯框架。因为在满足 task 1 时,需要舍弃一些图像信息,但是为了同时满足 task 2,与 gaze 特征无关的图像信息会先被舍弃,留下 gaze 相关的信息被保留。
实现 PureGaze
我们需要将之前提出的两个 task 落地实现,这涉及到如何实现 gaze estimation 的问题,和对抗性重建(adversarial reconstruction)。同时文章还提出了两种不同的计算损失的函数。
gaze estimation的实现
为了能够得到 gaze 相关信息的特征,我们需要先对图像进行一次 gaze estimation,同时这个操作也是从图像特征中保留了与 gaze 相关的特征的过程,也可以看作是对 task 2 的实现。
这个 gaze estimation 可以用任何的网络来实现,文章提出的是使用 backbone + MLP,backbone 用来进行特征提取,MLP 进行回归。这里Lgaze 损失用的是 L1 损失。
adversarial reconstruction的实现
为了要 remove general image information from extracted feature,我们提出对抗性重构的模块来实现这个问题。这个模块主要是为了去除与 gaze 无关的信息,是对 task 1 的实现。
这里我们假设:如果从提取特征中没办法重构出的原始输入图像,就认为提取的特征已经包含较少的图像原始信息。
首先使用一个 backbone 进行特征提取,我们使用一个 SA-module 进行重构,backbone 与 SA-module 相互对抗(因为 backbone 的作用是提取 gaze 相关特征,而进行重构的 SA-module 要不断增强其从特征中重构出原始图像的能力)。这里 SA-module 使用的 Lrec 损失是 pixel-wise MSE 损失。
文章很巧妙的设计,将相互对抗表现令 backbone 的损失 Ladv = 1 - Lrec。
还有,对抗网络的 task1 和 task 2 的 backbone 都是提纯 gaze 相关特征的网络,所以这两个 backbone 是共享权值的。
PureGaze 的整体架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RQX81cH9-1681528452270)(/Users/xuke/Library/Application Support/typora-user-images/image-20230310171355333.png)]](https://img-blog.csdnimg.cn/a2ab43ed08d044fc935cae7851ddc803.png)
两个权值共享的 backbone 可以当做一个网络,
还有 MLP 网络和 SA-module :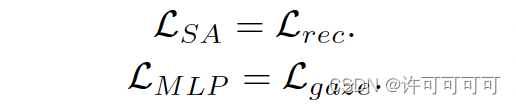
网络一共用到了两种 Loss 函数:
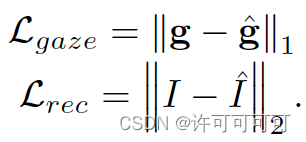
Problems
backbone 有两个目标,最小化 Lgaze 和最小化 Ladv。 最小化 Lgaze 意味着应该提取与注视有关的特征,最小化 Ladv 意味着应该去除图像特征。 这两个目标不是合作的而是对抗的,训练 backbone 包含了一个对抗学习的过程。
此外,Ladv 很容易满足于学习一个局部最优解来欺骗 SA-module。 要避免局部最优解。
Solution 1 - Local Purification Loss
因为眼部信息的 gaze 相关特征更多,所以希望更多关注眼部特征。希望能够对于局部进行提纯,设计了 LP-Loss。
使用 attention map(使用高斯混合分布,We use the coordinates of two eye centers as mean values, and the variance 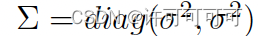
of the distribution can be customized.
),希望能够在去除图像特征时,保留一些眼部特征。
同时要注意,LP-Loss 只改变了 Ladv,没有改变 Lgaze,因为 gaze 特征不能只从眼部得到,需要整个人脸的特征。
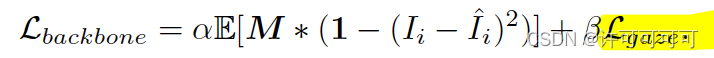
Solution 2 - Truncated Adversarial Loss
因为我们重构的目的是去除 gaze 无关的特征,而不是要真正的生成差异更大的原始图像的“反向”图像,所以为了防止出现很大的像素“冗余”,进一步设计了 TA-Loss。
使用了门限值 k(k 的值为 0.75,
),用来截断 Ladv。换言之,如果两张图像的差异过大,即 Ladv小于门限值(图像差异大于0.25)时,指示函数会令 Ladv 为0,防止这种情况被学习到。
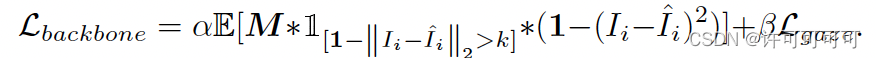
放一张伪代码:
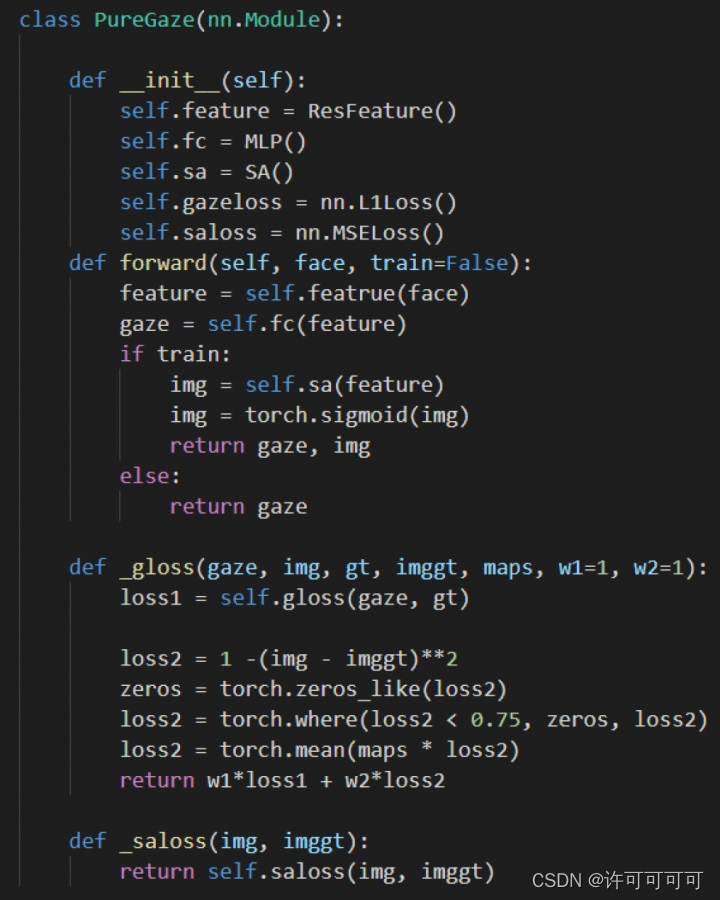
这里面的w1 = w2 = 1.
Puregaze 实验
train dataset:Gaze360,ETH-XGaze;test dataset:MPIIGaze,EyeDiap
Baseline:Full-Face,RT-Gene,Dilated-Net,CA-Net
效果(跟 baseline gaze estimation 方法以及域迁移的方法对比):in four cross-dataset tasks

因为过拟合,在源域上训练的 gaze estimation 模型在目标域上的表现效果较差。
跟域迁移的方法相比:
第三行:在加入了一些迁移时, ADL 和 PureGaze 的 backbone 一样,E->D 任务的表现并不是最好的。
第二行:在不加入迁移时,PureGaze 表现出了非常好的性能。

在 Full- Face 和 CA-Net 加入自对抗的框架(也就是 SA-Module 这个模块)后,在 CA-Net 上的表现性能有很大的提升,在 Full-Face 的各个任务上也都有所提升。

PureGaze 的方法是一种即插即用(plug-and-play attribute)的方法。















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









