







1.Hbase简介
Hbase是一个分布式可扩展的NoSQL数据库,提供对结构化,半结构化,非结构化大数据的实时读写和随机访问能力,而且操作速度与数据量基本无关,所以可以用于海量数据处理。Hbase之于HDFS就类似于数据库之于文件系统。自然Hbase是建立在HDFS之上的,可以存储海量的数据。
常见的NoSQL数据库还有:Apache Cassandra,MongoDB等。
下图1展示了Hbase在Hadoop的逻辑位置。
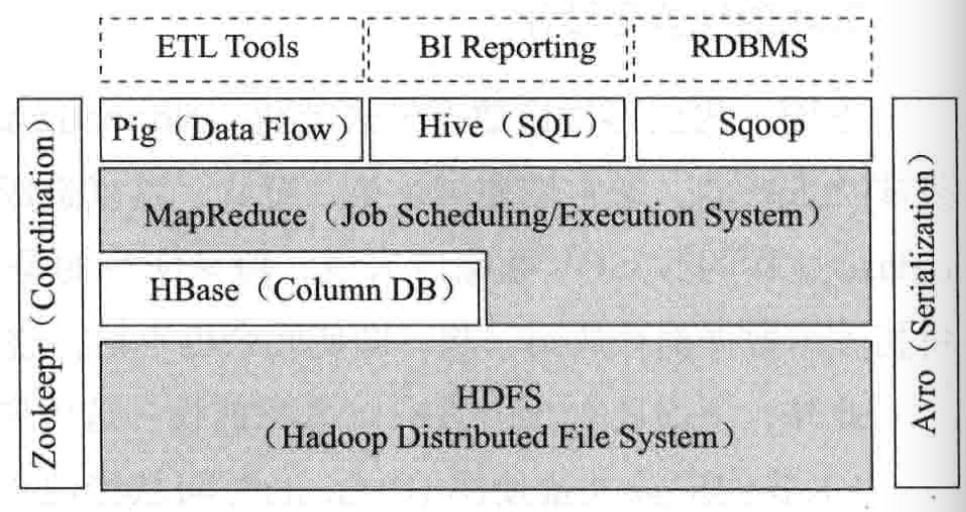
图1:Hbase在Hadoop中的位置
2.HBase表的逻辑模型
Hbase是Google BigTable的一个开源实现,数据存储逻辑模型与BigTable类似,但实现上有一些不同之处。是一个分布式多维表,表中的数据通过:一个行关键字(row key),一个列关键字(column key),一个时间戳(time stamp)进行索引和查询定位的。如下图2:Hbase表的示例。

图2:Hbase表的示例
在实际的HDFS存储中,以及存储每个字段数据所对应的完成的键值对:
{row key,column family,column name,timestamp}->value
如图2中key3行Address字段下t2时间戳下的数值Shanghai,存储的完整键值对是:
{key3,PersonalInfo,Address,t2}->Shanghai
也就是说Hbase真实是不存在行列的概念,只有键值对的概念。其行的概念是通过相邻的键值对的数据比较构建出来的。所以其物理上不是二维表的概念。
3.HBase表的存储模型
前面了解了表的结构,那这个表又是怎么存储的呢?来看下图3。
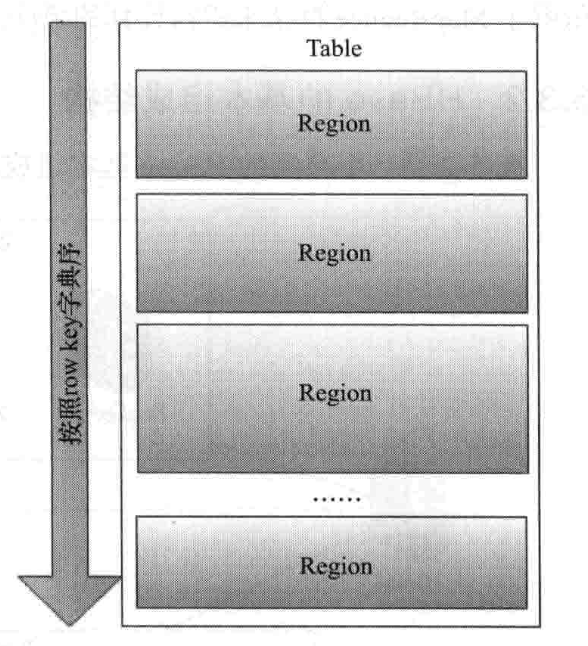
图3:HBase表的存储模型
每张Table按row key进行全局排序,Hbase将表划分为若干个Region。Region也是Hbase调度的基本单位。
表在刚开始就只有一个Region,之后由于数据不断增加,Region越来愈大,在Region中又分为多个Store(5中会提到),而当Store大小超过阈值,则会将Region分裂。依次就有了多个Region。
4.Hbase集群的组成结构
这里分布讲集群的物理组成结构和集群的逻辑组成结构。
4.1 Hbase集群的物理组成结构
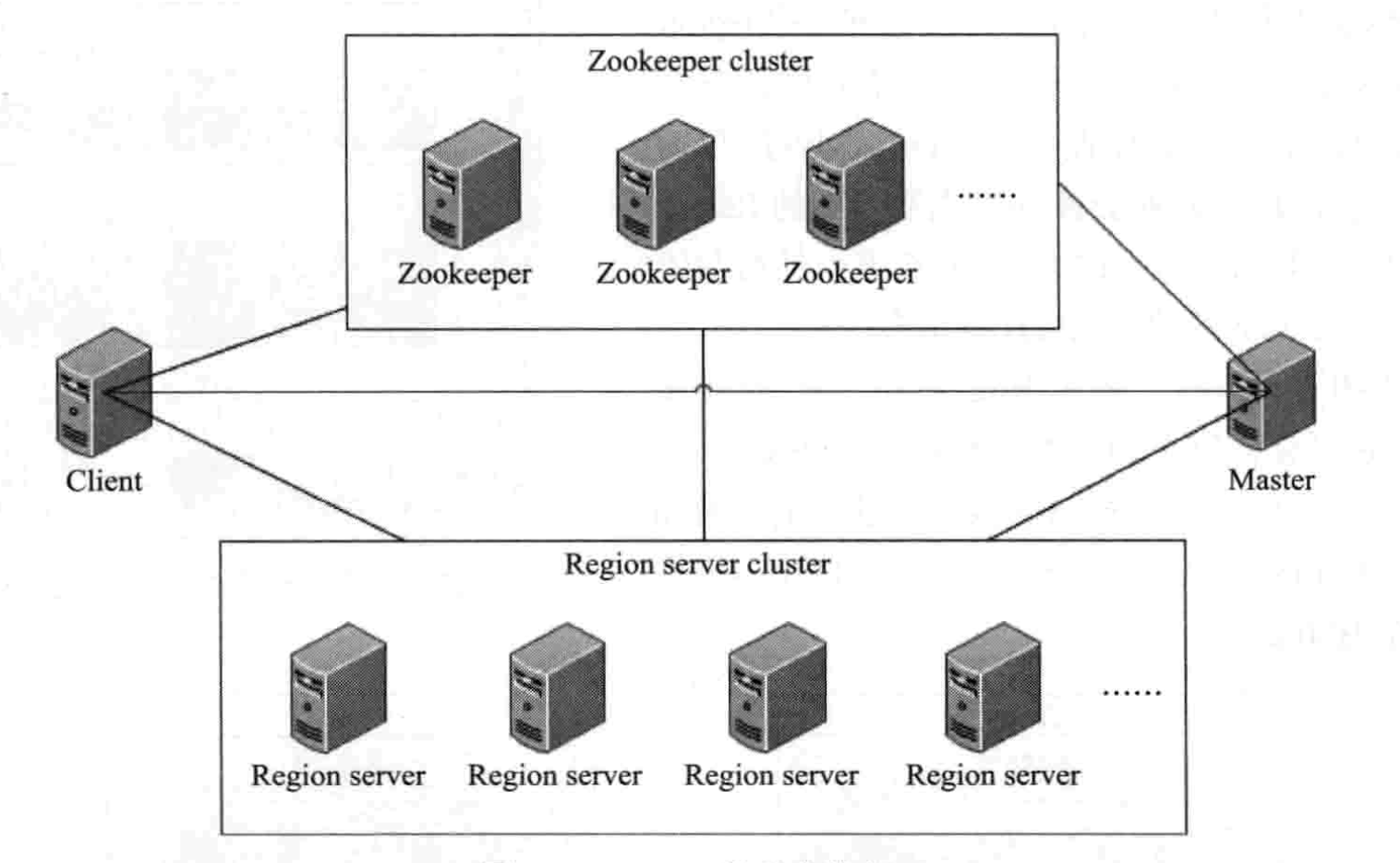
图4:Hbase集群的物理组成结构
Hbase集群分两部分:Hbase Master和Hbase Region Server。如上图3所示
另外Hbase集群由zookeeper来监控。在伪分布模式下Hbase会开启自带的zookeeper。
4.2 Hbase集群的逻辑组成结构
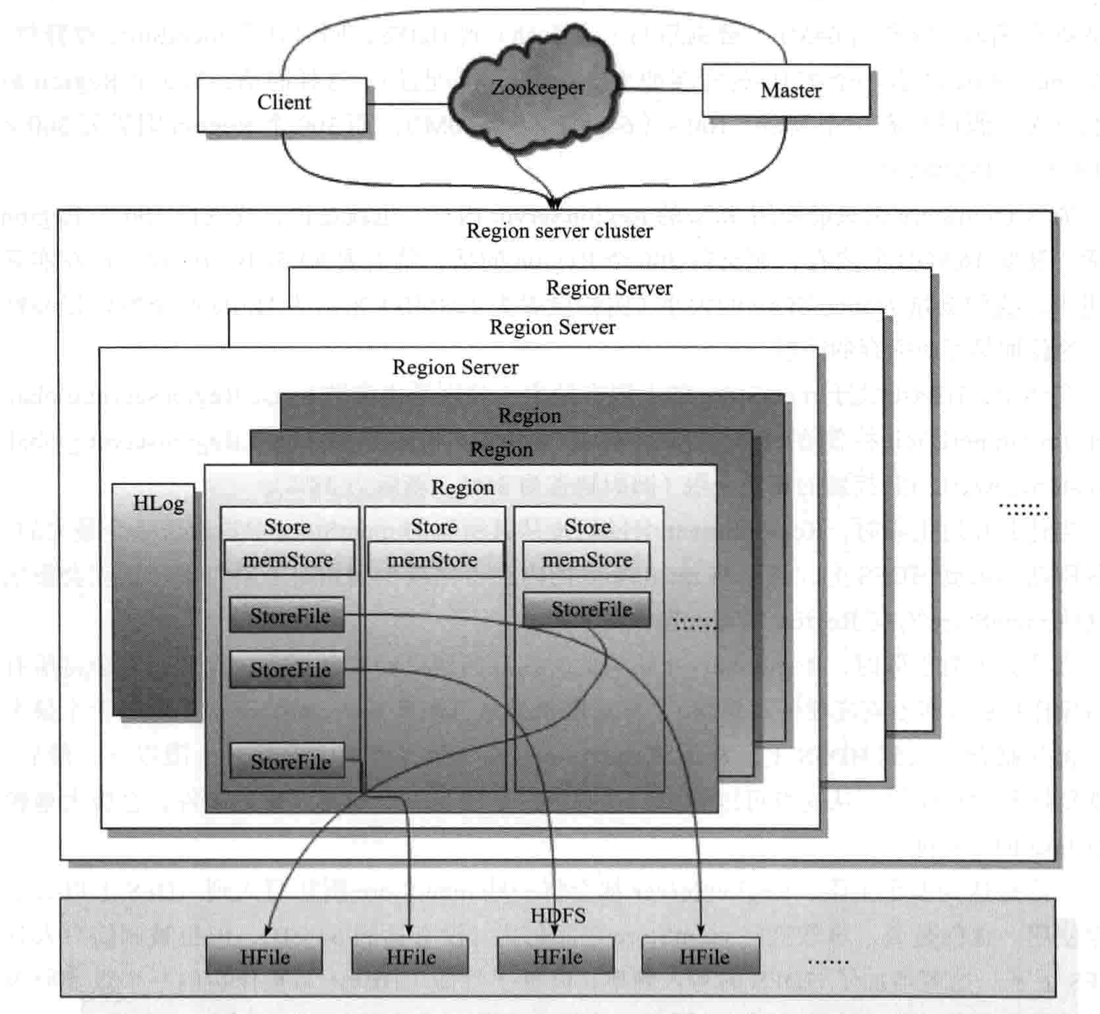
图5:Hbase集群的逻辑组成结构
可以从图5中看出来:
1)在一个Region server cluster里会有多个Region Server机器。
2)在每个Region Server机器内部有多个Region,结合前面Region的介绍,知道多个Region才组成一个真正的Table。Region是基本调度单位。
3)每个Region内部又有多个Store。
4)每个Store里面又由menStore和StoreFile两部分组成。其中StoreFile是最终的数据,它存储到HDFS中去。menStore不论在Store是否有真实数据都会有。
Xianming















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









