






public V put(K key, V value) {
if (table == EMPTY_TABLE) {
//初始化HashMap容器大小
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
//根据key获取hash值
int hash = hash(key);
//根据Hash值和table的长度获取数组index(定位到数组的下标)
int i = indexFor(hash, table.length);
//遍历链表,
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
//判断该条链上是否存在hash值相同且key值相等的映射,若存在,则直接覆盖 value,并返回旧value
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//原HashMap中无该映射,将该添加至该链的链头
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
// 1. 插入前先判断是否需要扩容
// 如果元素个数>=扩容阈值 并且 对应数组下标不为空 threshold = capacity(table的长度) * loadFactor
if ((size >= threshold) && (null != table[bucketIndex])) {
//扩容2倍
resize(2 * table.length);
// 重新计算Key对应的hash值
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
//代码扩容,
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}假设线程1,线程2同时进入 transfer方法,等线程1执行完之后,线程2再去执行造成HashMap链表循环的场景
(由于扩容的时候数据的顺序发生变化,然后会导致这样的情况,扩容的目的是让链表变短,get的效率会高)

(a-1)图解步骤
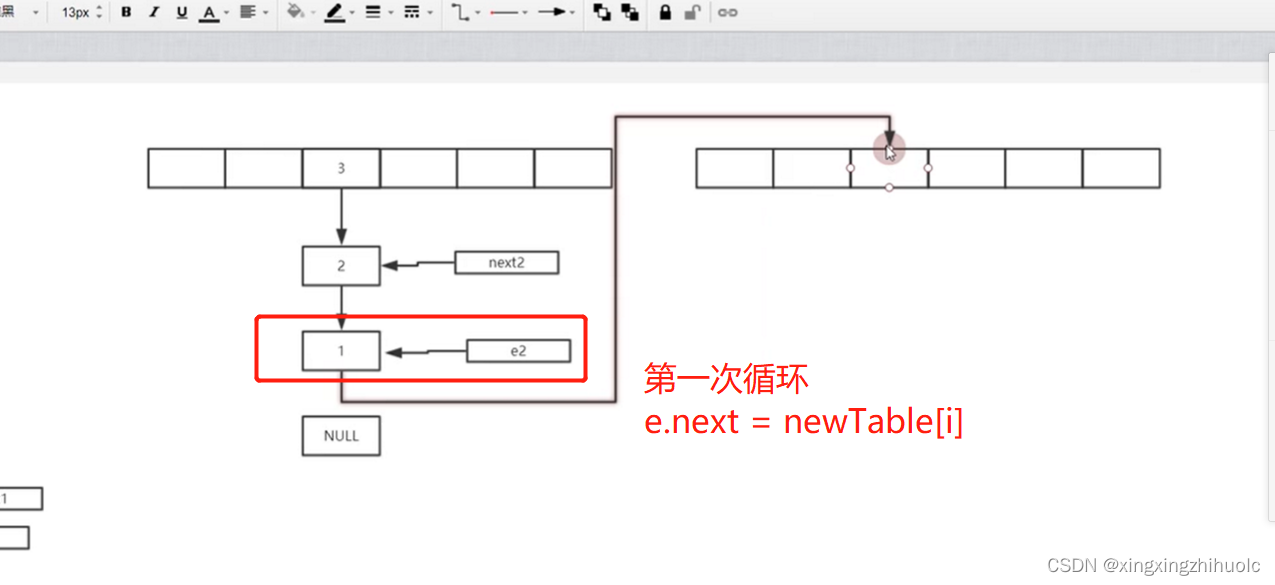
(a-2)图解步骤

(a-3)图解步骤

(b-1)图解步骤

(b-2)图解步骤

(b-3)图解步骤

(b-4)图解步骤

(c-1)图解步骤

(c-2)图解步骤

(c-3)图解步骤

(c-4)图解步骤















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









