







《Denoising User-aware Memory Network for Recommendation》
[RecSys2021 Oral] 高德
- 去噪用户感知记忆网络DUMN 文章地址
背景
现存很多ctr模型仅仅考虑了用户对什么商品感兴趣,并未对其不感兴趣的偏好进行建模,这将导致模型对用户学习到的表征是有偏的。
用户的反馈数据分成显性反馈和隐性反馈两类:
-
显性反馈:能直接反映出用户感兴趣/不感兴趣的表征;信息准确但数据量较少;包括用户评分、打标签(喜欢或不喜欢)等。
-
隐性反馈:能直接反映出用户感兴趣/不感兴趣的表征;含有噪声但数据量较大;包括用户对滑动展示页面中item的点击和未点击反馈。
本文探讨了以下两个点:
-
隐性反馈中的噪声
已有的方法在去躁工作中的研究存在不足:现有的表征噪声去除方法大多使用的是注意力机制[3]和autoencoder[4]来增加具有更大相关性item之间的权重,但是这类方法所学习到的权重有时并不一定是准确的,这就导致去噪工作还有很大的研究空间。在本文,我们从显性反馈能明确描述用户兴趣的角度出发,提出了一种利用显性反馈的表征来对隐性反馈的表征进行提纯的去躁方法,这也是已有方法都未尝试过的。
-
细粒度的用户长期兴趣
用户的长期兴趣能反应用户在一段较长时间内的行为偏好,通常是比较稳定的(在实验的用例分析章节也进行了验证)。现有的序列推荐模型,SDM[5]、DIEN[6]和DSIN[7]等都是通过增加行为序列长度才能捕捉用户更长的兴趣偏好,但是这种处理方式存在以下不足:1)这些方法都是基于item的方法,并且item序列的长度受限于硬件条件,这将导致所建模的偏好表征和用户真实的长期兴趣之间存在Gap。相反的,我们认为用户的长期兴趣更应该是从用户层面进行建模,这是一种和序列无关的并且和用户属性密切相关的兴趣,例如一个用户养了一只猫,那么该用户大概率会在一段较长时间后购买猫粮,这和短期内的行为数据关联性并不大;2)现有的用户长期兴趣建模方法中,最经典的是MIMN[8],它使用NTM[9]实现了对用户的长期兴趣的保存和更新。但是已有的长期兴趣建模方法都只使用了点击序列进行建模,忽视了对用户不感兴趣偏好的建模,这将导致所得到的表征是有偏的。
为了解决以上分析过的2个问题,文中提出了DUMN模型对用户的偏好进行细腻度的建模,将用户反馈细分为click、unclick、like和dislike 4种序列,用于得到用户无偏的偏好演变,具体的工作简要总结如下:
-
特征提纯模块(feature purification,FP):将隐性反馈和显性反馈分成<click,dislike>和<unclick,like>两组,并提出了一种新奇的特征正交映射提纯方法,利用显性反馈的表征对隐性反馈进行提纯。
-
用户记忆网络模块(user memory network,UMN):改进了NTM中的memory network,用于对用户长期兴趣的细腻度建模。
-
偏好感知的交叉表征模块(Preference-aware Interactive Representation Component,PAIR):设计了一种门控机制,用于将用户的长期兴趣表征和短期兴趣表征融合获得高维交叉表征。
-
在2个真实数据集上对所提出的模型进行验证,实验效果都优于所对比的SOTA模型。
模型
网络的输入包含用户表征、目标item表征、以及4种用户隐/显性反馈序列(click序列、unclick序列、like序列、dislike序列)。如下图,框架包含4个模块:embedding模块、特征提纯模块(FP)、用户记忆网络模块(UMN)和偏好感知的交叉表征模块(PAIR)。

特征提纯模块
输入为embedding layer的输出,该模块主要包含Multi-head Interaction-attention Component和Feature Orthogonal Mapping Component两个子模块来分别获得用户的短期兴趣表征和实现隐性反馈表征的去躁。
本文使用multi-head self-attention网络分别对4种反馈序列进行处理,由此可以得到用户细腻度的短期兴趣的表征。
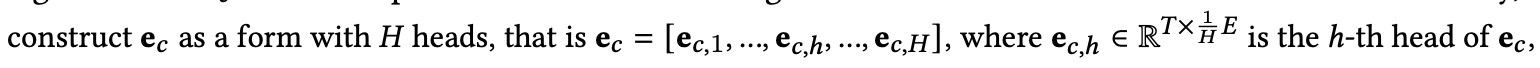
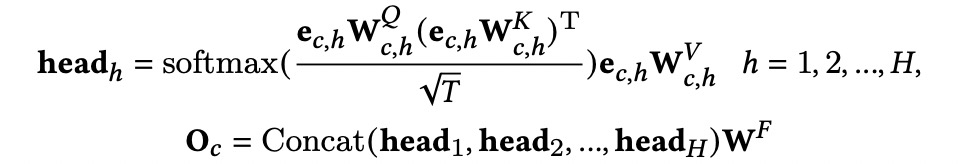
计算目标item和序列中每个item的表征之间的注意力权重,计算公式如下:
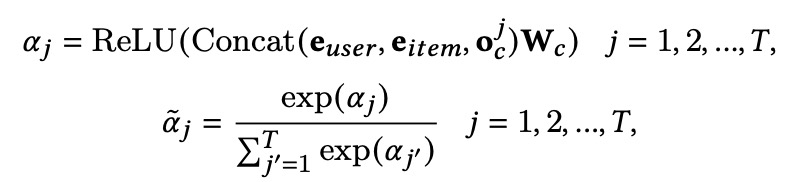
其中o_c^j是multi-head self-attention输出的第j个item的表征,融合有目标item的用户click序列表征为:
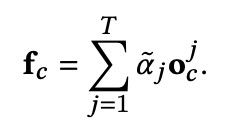
同样的,根据以上计算公式,我们可以获得unclick、like和dislike序列的表征。
Feature Orthogonal Mapping Component
Feature Orthogonal Mapping Component的目标是对其进行特征提纯。认为用户的显性反馈表征能用于隐性反馈的提纯,因为显性反馈能直接反应用户的偏好。基于此,本文构造了两组正交映射组<click,dislike>和<unclick,like>,其对应的序列表征组分别为![]() ,f_c在f_d方向上的映射表征f_c^p是用户click偏好和dislike偏好的混合,f_c^p定义为f_c的噪声表征,将垂直方向的表征f_c^o作为对f_c提纯后的表征。计算如下:
,f_c在f_d方向上的映射表征f_c^p是用户click偏好和dislike偏好的混合,f_c^p定义为f_c的噪声表征,将垂直方向的表征f_c^o作为对f_c提纯后的表征。计算如下:
![]() ,
,![]() ,
,![]()
提纯后的表征f_c^o在正交空间上能用于表示用户纯粹的click偏好,这和我们的假设一致--用户的click表征和dislike表征是截然不同的。
用户记忆网络模块--UMN
为了得到用户长期稳定的长期兴趣,本文改进了NTM中使用到的menory network。NTM中的memory network具有多个slot,用于建模用户的click序列;memory network使用controller生成用于reading和writing的key,进而实现对memory network的memory read和memory write操作。考虑到memory network中的每个slot能聚合具有相同特征的表征,我们拓展memory network用于存储用户级别的长期兴趣偏好,使得用户在同一个slot下的表征能反应用户之间兴趣的相似性。
为了获得用户无偏的长期兴趣偏好,本文对原始的memory network改进如下:
-
使用4个memory network M_c,M_u,M_l,M_d来分别存储用户的click、unclick、like和dislike偏好,每个memory network含有m个输出纬度为Z的slot。
-
将用户属性的embedding layer输出和特征提纯模块的输出(f_u^o,f_c^o,f_l,f_d)进行拼接,作为memory network的输入,使得memory network能够保存user-level的长期偏好。
以M_c为例,memory read和memory write流程如下。
【memory read】
controller生成用于读操作的key:![]()
K_c遍历M_c中所有的slot,生成权重向:
最后由下式得到memory read的用户长期兴趣表征: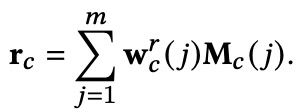
【memory write】
和生成用于memory read的权重向量w_c^r相似,由上述公式生成用于memory write的权重向量w_c^w,此外额外新增2个key(E_c,A_c)用于memory network的更新。
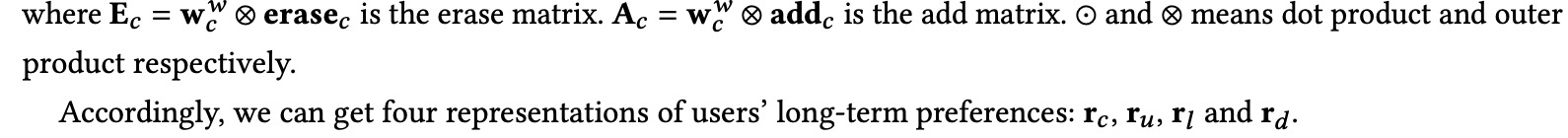 偏好感知的交叉表征模块--PAIR
偏好感知的交叉表征模块--PAIR
前2个模块分别获得了用户的短期兴趣表征和长期兴趣表征,在本模块,本文设计了特定的门控机制用于获得长短期特征的交叉特征。
对于用户的点击偏好,用户的长短期交叉表征计算为:
![]()

由该公式我们可以获得用户unclick, like 和 dislike的交叉偏好表征U_u,U_l,U_d。将4种交叉特征进行拼接可以获得用户的高维无偏兴趣表征:![]()
最终,DUMN模型使用全连接层进行预测![]()















 4110
4110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









