




两个变量之间什么时候会表现出相关性?
一是两变量具有因果关系,则两者会有相关性,二是两变量有一个共同的原因,这时即使两者没有因果关系,也会表现出相关性。
两种情况下,因果效应可以识别:
- 没有共同原因,没有干预变量和结果变量的共同原因,则没有任何后门路径需要阻断,因果效应可以识别。
- 有共同原因,但有足够的观测变量可以阻断所有后门路径。
按照估计范围划分,因果效应估计包括对平均干预效应(Average Treatment Effect,ATE)、条件平均干预效应(Conditional Average Treatment Effect,CATE)以及个体干预效应(Individual Treatment Effect,ITE)的估计。其中,ATE是指整个干预组与对照组潜在结果变量的差异,是一个平均意义上的指标。CATE针对每个具有相同属性的群体进行评估,是一种异质性的因果效应,能够帮助实现更加精准的决策。例如基于CATE将用户划分为四类群体,构建群体画像,确定出补贴敏感用户作为干预执行群体,为不同群体提供定制化的干预方案等。而ITE则细粒度到每个独立样本。根据干预的类型,因果效应估计又可以分为连续干预、离散干预、二值干预、组合干预以及动态干预下的因果效应估计等。
背景
我们先考虑平均因果效应估计的问题。假设我们有NT个干预组(treated group)的样本和NC个控制组(control group)的样本,样本i的观测结果为![]() , 一个简单的思路是直接计算两组的观测结果的平均值的差作为干预变量的平均因果效应:
, 一个简单的思路是直接计算两组的观测结果的平均值的差作为干预变量的平均因果效应:
![]()
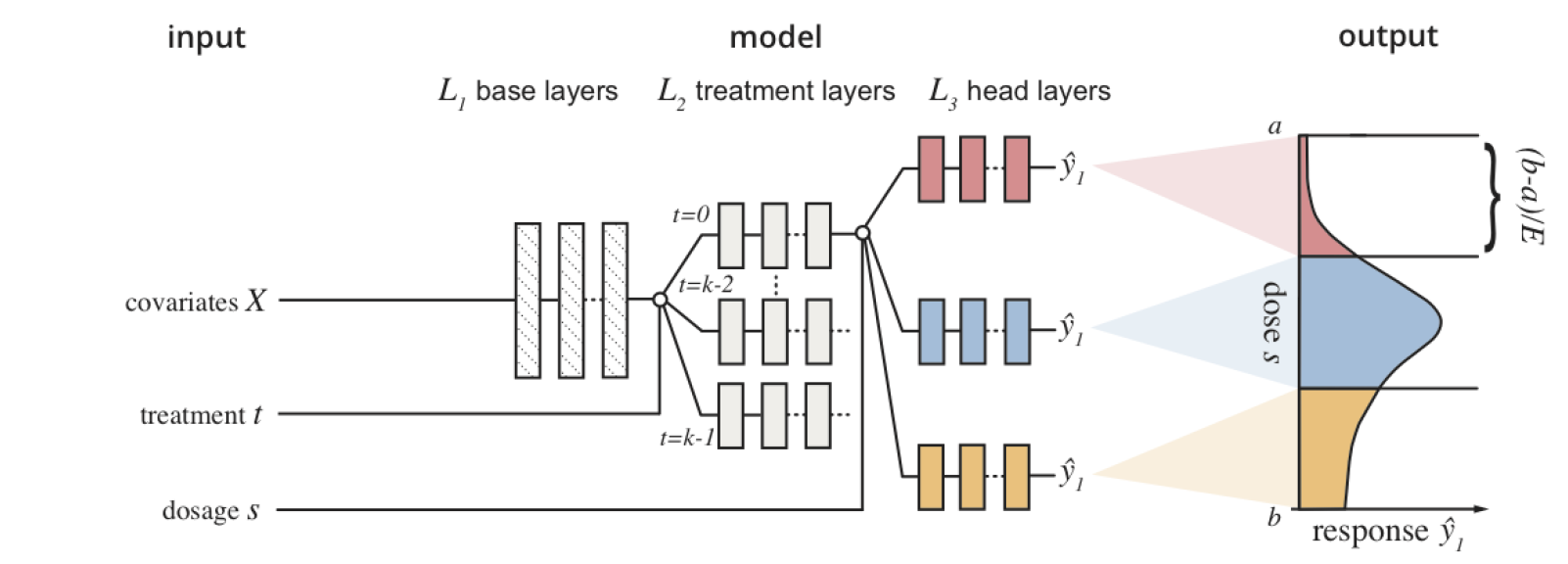
这种方法粗看之下方便易行,但其实已经落入了数据偏差设下的“陷阱”,例如“辛普森悖论”:假设有两种治疗方案A 和B, 在观测数据中对某种疾病的治愈率如下表所示,按上面的公式计算,即方案A的治愈率高于方案B。而如果分别从年轻和年长两个年龄层比较,方案B的治愈率却都高于方案A。为什么会有这样的结果呢?纵向比较'Young'和'Older'两行的数据,无论是哪种治疗方案,年轻人的治愈率都明显高于年长者;大部分(81%)接受方案A治疗的都是年轻人,而大部分接受方案B治疗的都是年长者,因此结论出现了悖论。用因果推断的语言来说,年龄这一因素既影响了治疗方案的分配,又影响了治疗的结果,称为一个混淆因子。如果我们忽略了数据集中混淆因子的存在,就可能得出错误的结论。该例估计出现偏差的重要原因在于年龄这一变量在干预组和控制组中的分布差异很大。如果在两组中的分布相同就可以得到无偏的估计,但这样的数据集极难自然产生,一般需要通过随机实验来获得,而随机实验的成本极大,在时间、金钱甚至伦理上都可能面临挑战。因果效应估计的目标就是要在有偏的观测数据集上准确估计出因果效应。

因果效应估计的主要思想是做样本平衡,既然出现偏差的原因是某个(些)变量在干预组和控制组的分布有差异,那么就通过一些手段来使得两个分布尽量接近。常用的方法包括:倾向性得分匹配(将实验组和对照组的样本做一下 “匹配”),IPTW(逆概率加权),SCM(合成控制法)。
通过机器学习算法预估CATE:
- meta-learning:首先学习各个干预下的结果与协变量的关系,然后利用第一步的结果进一步估计CATE
-
- S-learner
- T-learner
- X-learner
- R-learner
- 基于树的算法:树节点分裂目标是最大化分裂前后所对应的Y的差异,目的是为了突出因果效应在单个样本上的变化
-
- BART
- Causal Forest
- Uplift Tree
- 深度学习算法
如果协变量包含所有混杂变量(即treatment和outcome的共因),那么因果效应称为可确定的(identified)。因此大多数paper都会假设没有不可观测的混杂因子。
内生性问题
上述的辛普森悖论例子也可以理解为变量的内生性导致,“年龄”作为内生性变量,既影响了“因”又影响了“果”。对于内生性的解释:

场景的内生性来源:
- 遗漏变量
- 不一定带来内生性问题
- 选择性偏差
- 样本选择偏差:选择的样本非完全随机,即选择的样本是有偏的,例如想评估学生平均身高,选择的样本全部来自校篮球队,这就是样本选择偏误。
- 样本自选择偏差:解释变量不是随机的,存在内生的因素,会导致样本产生倾向性行为,从而导致评估产生误差,例如想评估参加职业技能培训对个人未来工资的影响,但是参加培训的人可能本身就更加上进、更加努力、有更多的信息渠道。
- 互为因果(双向因果)
- 成绩 与 努力
对因果效应的估计一般需要的几个假设:
- 稳定单元干预值假设(Stable Unit Treatment Value Assumption,SUTVA)SUTVA要求任意个体的潜在结果都不会因为其他个体的干预发生改变而变化,且每种干预是可以清晰定义的。
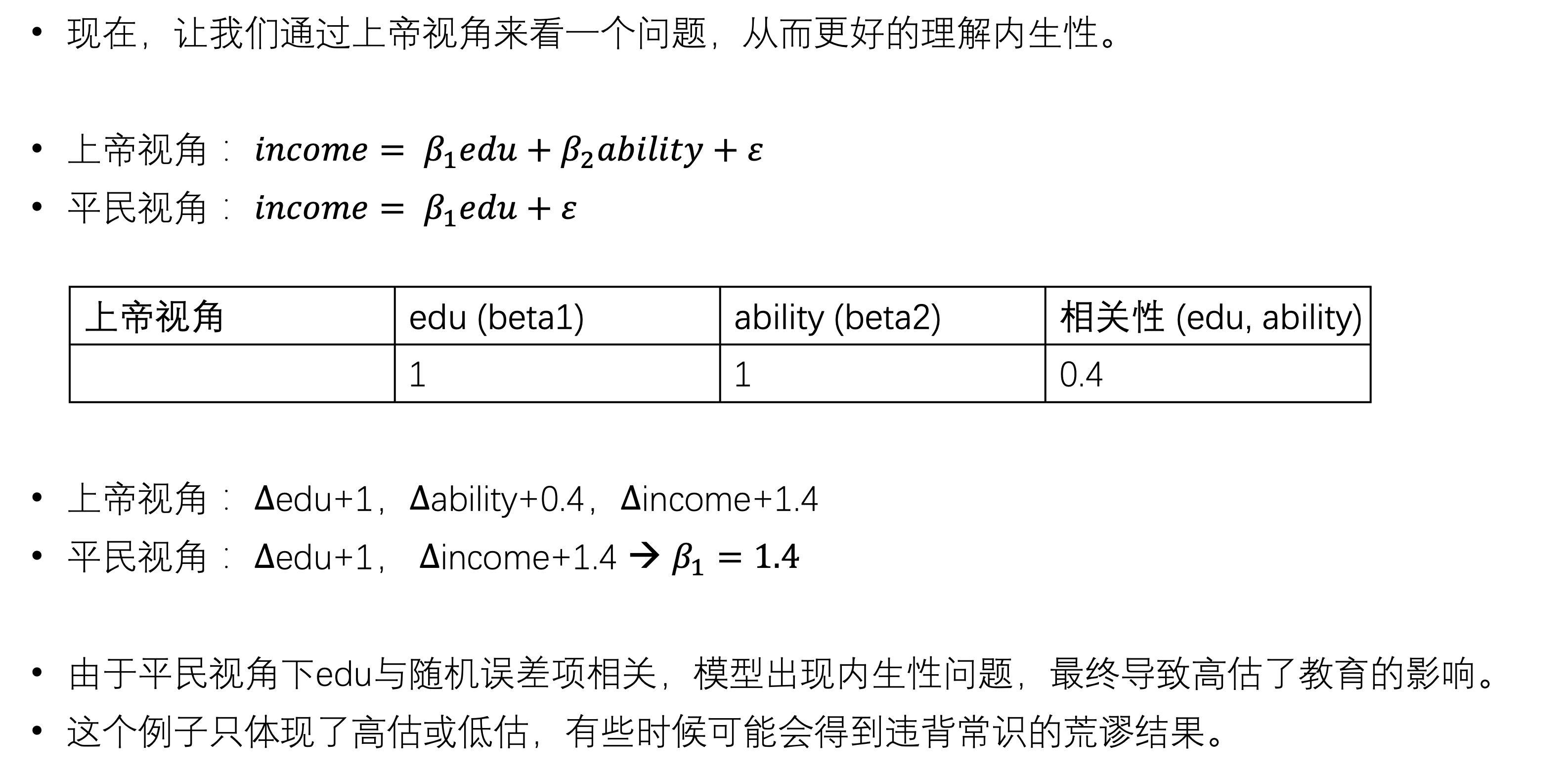
- 可忽略性假设(Ignorability)可忽略性假设也可称为无混淆假设。对于具有相同协变量取值的群体,干预的分配与潜在结果变量独立:
,即干预的分配应是完全随机的。怎么理解可忽略性?下图解释的比较清楚: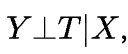

-

-

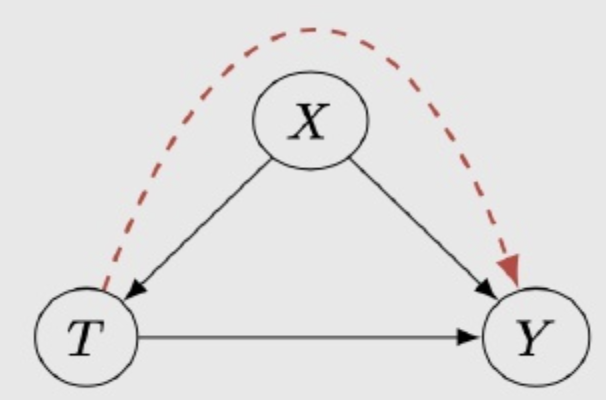
- 一致性假设(Consistency)当确定时,其观察结果应与对应的潜在结果一致。怎么理解一致性假设?看下图:

-

- 正值假设(Positivity)正值假设是指对于任意值的,其干预分配都具有随机性,即各种干预都有一定的执行概率。
随机对照实验满足以上全部假设,但在观察性研究中,SUTVA、Ignorability 和Consistency 这三个假设都是无法验证的,只能依靠经验或者数据进行判断。基于观察数据的估计方法需要依托于反事实推理,即得到在不同干预下对应的潜在结果,继而计算出不同干预对结果变量的影响程度。这种方法有两个待解决的核心问题,一是每个样本的反事实结果是不可能观察到的;二是基于观察数据,不同干预下协变量分布的不平衡会引入选择偏差。
以下列举了因果效应估计的相关文章。
《Estimating individual treatment effect: generalization bounds and algorithms》 (TARNet)
本文第一次提出了ITE的概念,假设混杂因子都能观测到。

(4)->(5)的证明:

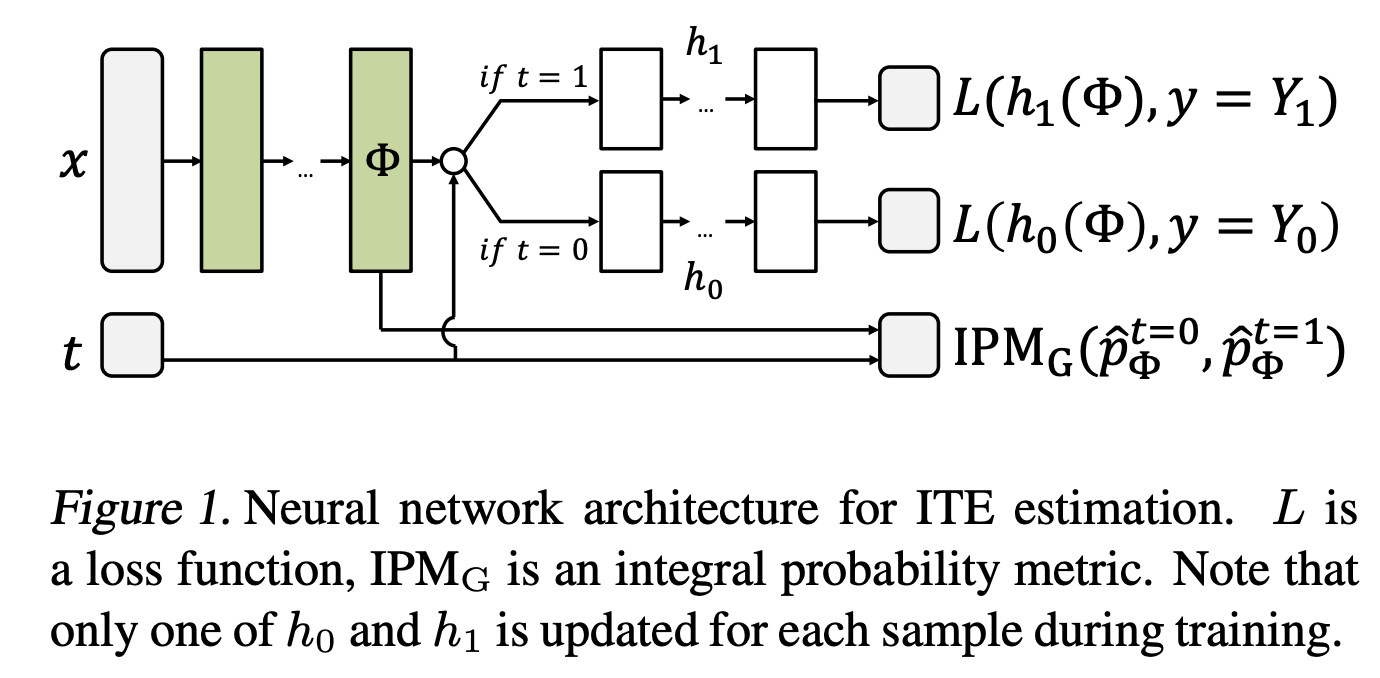
输入x,先抽取特征,然后根据T的不同训练不同的分类器,最小化两个分类器empirical loss的同时,减少representation分布之间的差异(使得干预组与对照组在变换后的表征空间上分布尽可能一致)。
考虑到我们的observational的训练样本可能存在针对t的imbalance(t和x不独立)的情况,举个例子:我们想要知道一个药对某个病的作用,由于这个药比较贵,我们采集到的样本用这个药的大部分人是富人,不用这个药的大部分人是穷人,如果说富和穷是X的一个特征,用不用药是t,这个时候如果拟合出来的h1和h0就不准了,特别是h1对穷人,h0对富人都不准。什么时候准呢?当样本来自于随机试验的时候才准,但是我们现在又只有observational data,没办法做试验,所以我们只能对样本的分布进行一个调整。

:counterfactual loss

wi的作用:对于treatment group和control group的样本数量不平均的情况做一个修正,使得他们在损失函数中的权重平衡。
第二项是模型复杂度的一个正则惩罚
第三项就是刚刚提到的对representation imbalance的一个修正。其中α用来控制这个修正的力度。当α>0时,这个模型就叫做CFR (Conterfactual Regression),当α=0时,则叫做TARNet (Treatment-Agnostic Representation Network)。实际上效果论文里是CFR好一些。
《Causal effect inference with deep latent-variable models》(CEVAE)
NIPS-2017 Causal Effect VAE VAE参考
假设我们肯定找不到也不知道谁是hidden confounder,我们都是通过表征的方法来解决,用各种reweight/rebalance的方法来调整表征解决问题。如果我们有这些hidden confounder的proxy,假设我们有如下的关系:
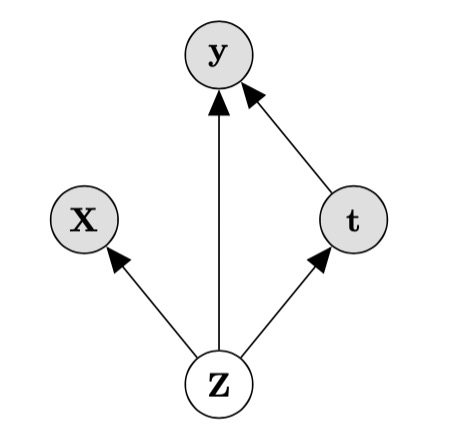
假设z是hidden confounder比如某个人的社会经济地位,这个变量会同时影响t和y,所以我们叫它confounder,但问题是他无法直接observe到,只能有一些proxy变量比如收入,职称来做部分的代理,那我们的X就是Z的proxy。如果我们直接把X拿来作为confounder进去fit模型,那结果是有偏的,于是这篇文章就志在解决上述这个情况下,该如何建模的问题。
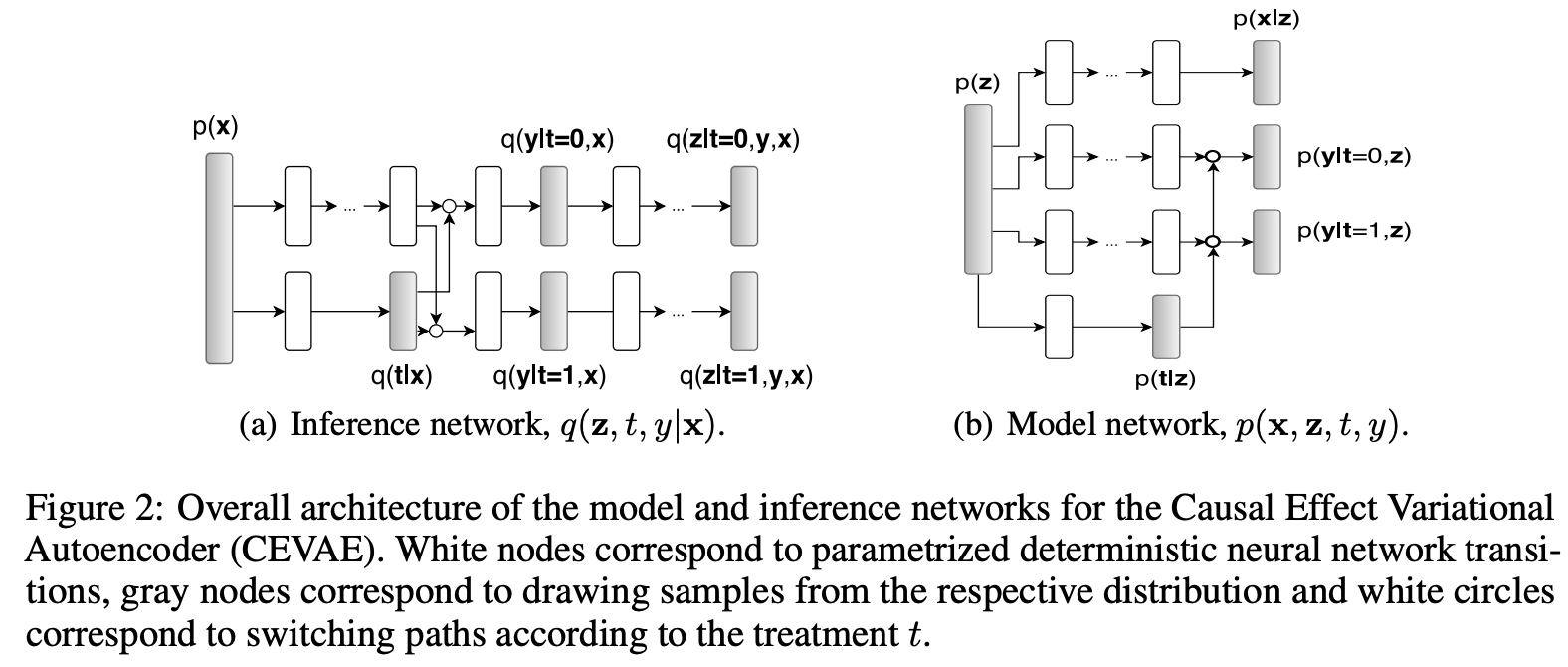
整体由两个子网络生成,一个叫inference network,一个叫model network。这两个网络可以看到其实都很像TARNet,也都是由TARNet启发而来。
- inference network:通过样本x,t,y可以得到q(z|x,t,y)的一个posterior分布的表征,我们希望这个分布是一个正态分布(NN拟合均值和方差);
- model network:把z的prior当作是一个标准正态分布,然后通过真实的x,t,y,去训练一个通过z可以生成最后p(x,y,t|z)的一个分布。和VAE一样,希望目标函数由两部分组成,一部分是衡量原本的p(x,y,t)和最后生成的p(x,y,t|z)足够相似,同时我们希望z的prior和posterior也足够相似。
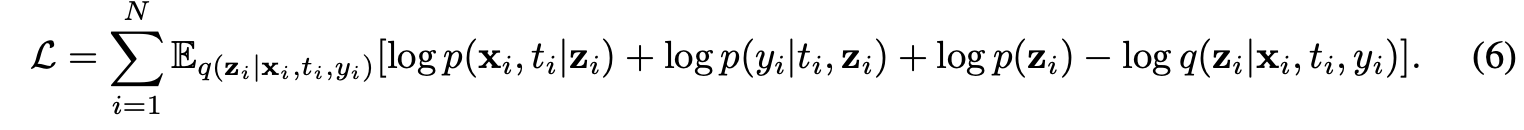
前两项为log likelihood,后两项为KL散度
本文借用VAE的思想,把hidden confounder更好的表征出来,通过hidden confounder直接去估计ITE。
《Perfect match: A simple method for learning representations for counterfactual inference with neural networks》
2018

核心:找一个很简单的方法来解决multiple treatment的方法。对于shared layer用全部的样本进行参数更新,而对后面的每个head network,只使用treatment为这个head的样本更新。
模型训练时,每一个进去训练batch的样本不只由真实的样本组成,还会通过propensity score去生成一些假样本,这个过程也叫perfect match。对于每一个样本X,有一个他实际的treatment t,我们需要找到这个样本另外k-1个treatment的match。怎么找呢?就用propensity score来找,比如我们要找X在treatment i下的match,我们就去计算这个样本在treatment i下的propensity score P(t|X)i,然后我们找到实际treatment是i的样本里propensity score和这个P(t|X)i最近的样本,来作为他在treatment i下的match。
《Adapting Neural Networks for the Estimation of Treatment Effects》 (Dragonnet)
NeurIPS 2019 paper
核心思想:没必要使用所有的协方差变量X进行adjustment,DragonNet 通过同时预测响应变量与干预变量,得到可近似认为是 ConfounderRepresentation 的表征空间。
同样假设无隐藏的混杂因子
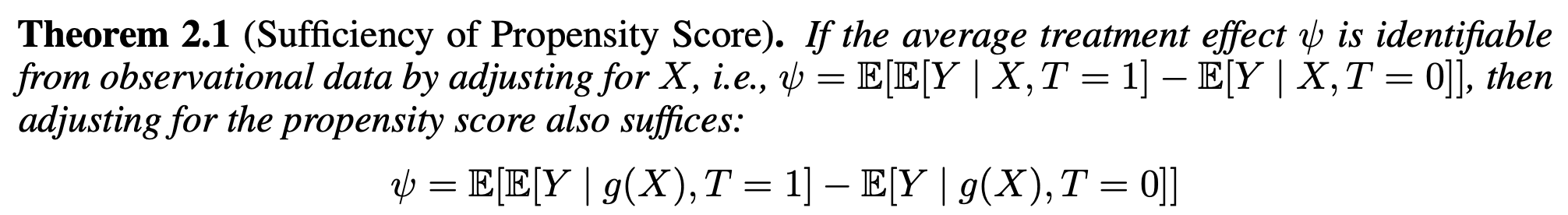
中有一部分变量只与outcome相关,和treatment无关,这些部分与因果关系的估计无关,是进行adjustment的噪声,因此我们应该抛弃这部分变量。我们需要找到域不变的特征这样才能有好的泛化性能。但是背景之类的特征往往有助于模型在当前分布下提升辨别能力。同样的,这里丢弃一部分协方差变量也会带来预测精度和鲁棒性的tradeoff。
模型拟合两部分:
![]()
![]()
用于筛选出与T相关的协变量
Loss:
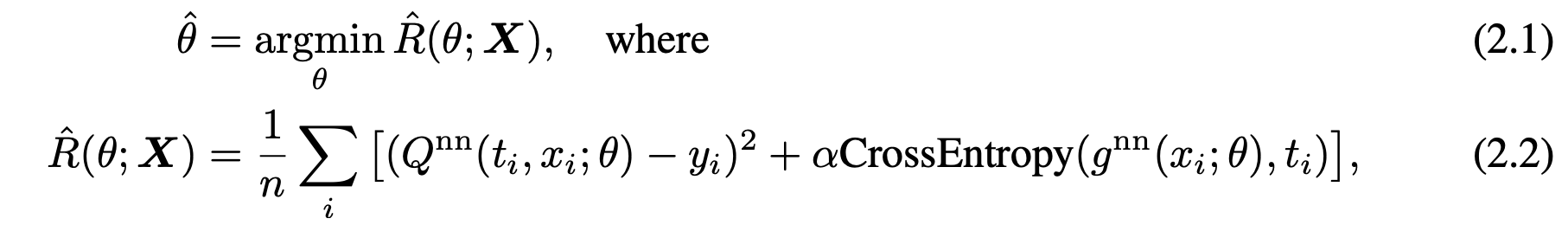
- 首先,一个三头的网络,和上一篇文章一样,一个encoder提取特征,然后给两个branch基于treatment和协变量预测outcome。
- 不同的是,这里训练一个分类器g_{hat},这样做的目的是。利用神经网络的特点,被分类器利用。即g激活的特征更有可能是与T相关的协变量。
- 为了更好的鲁棒性,在下游任务中估计因果关系时只使用g(x)挑选出来的协变量。
《Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning》
PNAS 2019 paper;
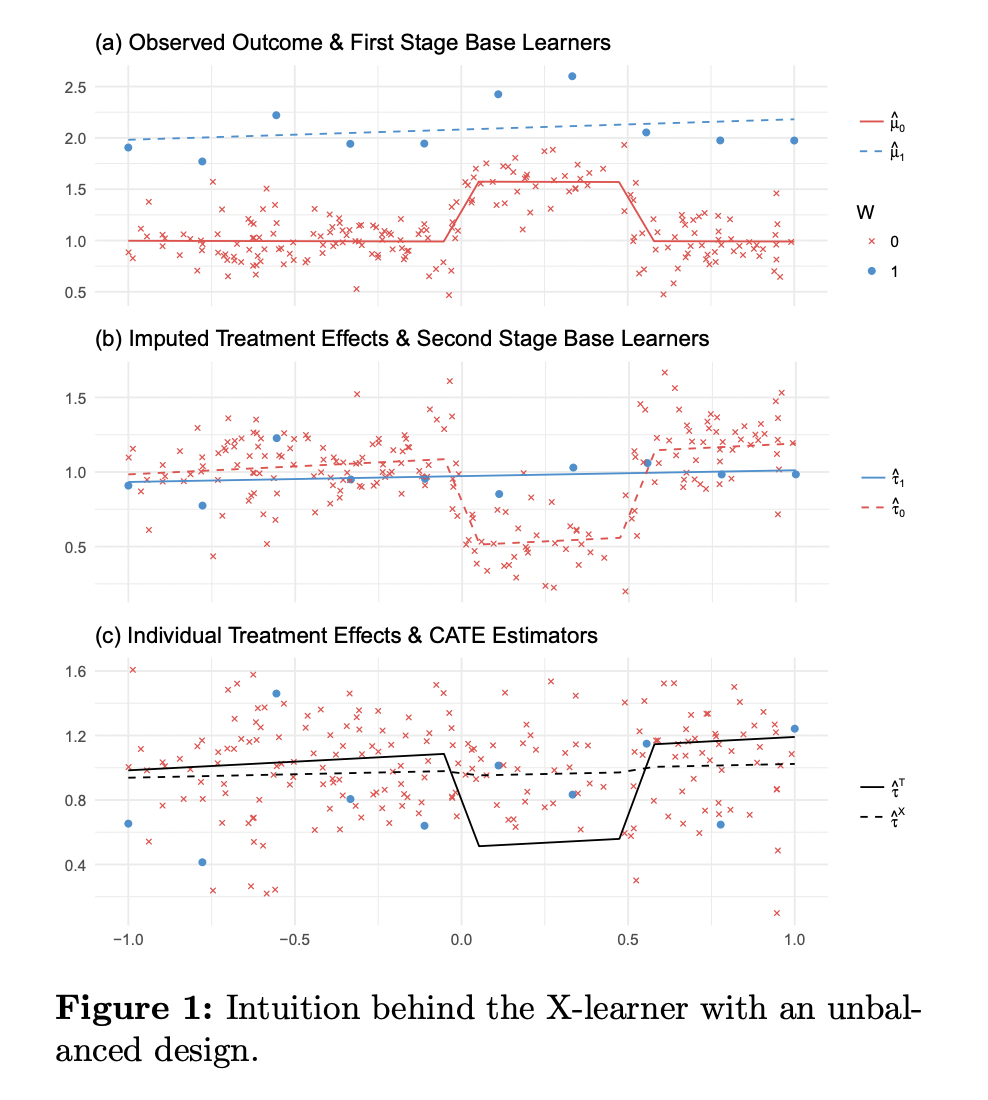
本文提出了一种新的框架X-learner,当各个treatment组的数据非常不均衡的时候,这种框架非常有效,对于样本量少的treatment组可采用简单模型避免过拟合。
S-learner
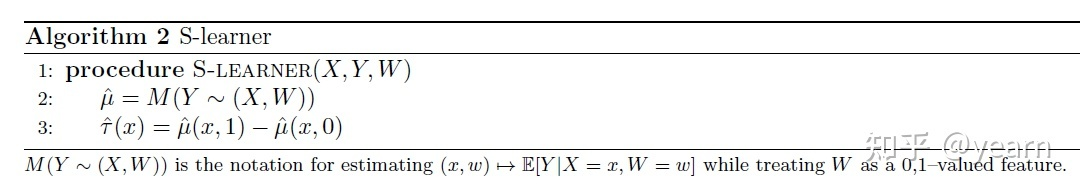
将T或者说W作为特征输入,使用同一个branch对二者进行估计。但是这种方法往往需要对T进行一定的变化,因为T只是一个标量,我们将他放入高维的特征中,影响微乎其微。
T-learner
使用两个不同的branch估计两种后验概率

X-learner
![]()
![]()

the observed data:
![]()
我们希望得到 ITE:
![]()

CATE:
![]()

MSE=
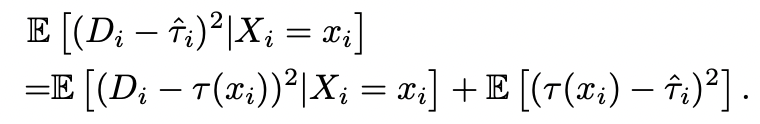
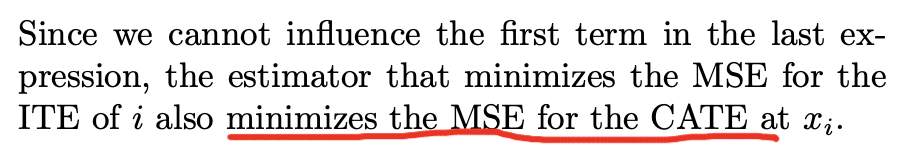
Expected Mean Squared Error (EMSE)
![]()
stage1

stage2
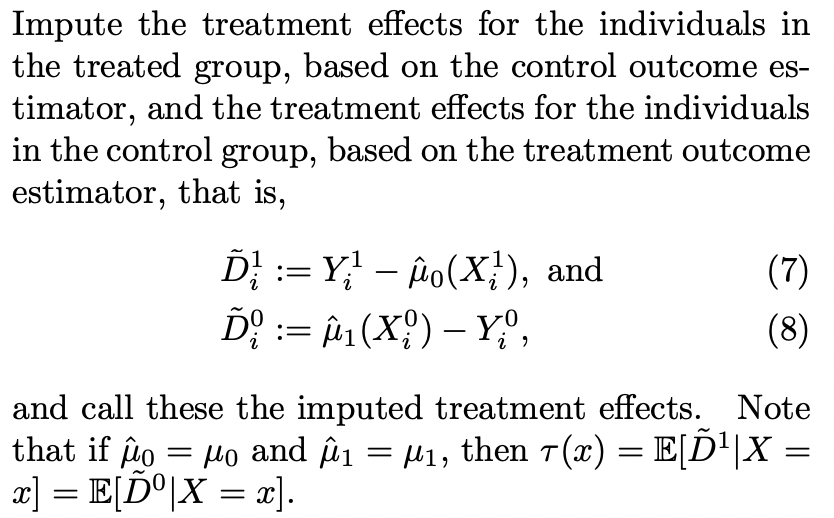
stage3
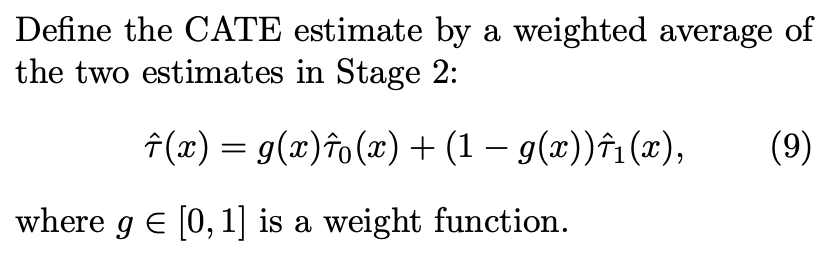
《Learning Counterfactual Representations for Estimating Individual Dose-Response Curves》
AAAI-2020 📎neurips_2019_dose_response_arxiv1_27May2019 (1).pdf
本文提出了新的metric,新的数据集,和训练策略,允许对任意数量的treatment的outcome进行估计。
Setting:本文考虑treatment有多个的场景,即T={0,1,2...k-1},如果是医生-病人的场景,每个treatment可能对应一个用药的剂量St。训练目标是对每个treatment范围内的任意一个s都可以给出一个估计值,因此此时对于一个个体x,因果效应显示为一个曲线。
Metric:本文给出了衡量该场景模型效果的metric,给定treatment和相应的剂量st,模型给出一个估计值y_{hat},那么总共的评估指标如下所示,对所有样本,所有treatment,在其剂量范围内均方误差的积分。
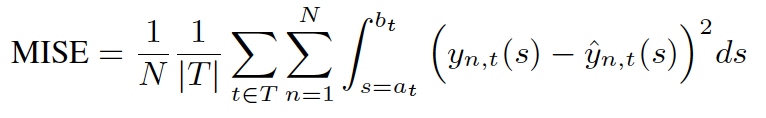
除了对均值进行评估,本文还提出了对最优剂量进行评估,对每个个体每个treatment的每个剂量我们找效果最好的那个,和预测的最好的那个进行比较,即给每个treatment评估其最优剂量是否正确。
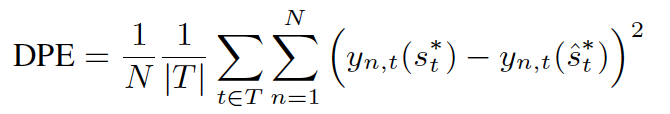
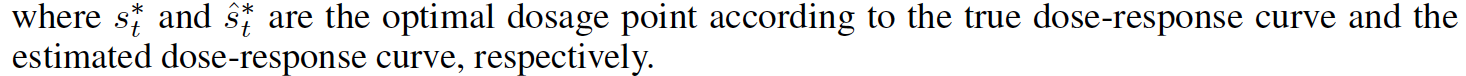
更进一步,我们在所有treatment中取最优,即个体层面看预测的最优treatment是否正确。这种做法往往是有意义的,因为在药物方面,医生也总是想选最优的treatment,而不关注其他次优的treatment的预测精度
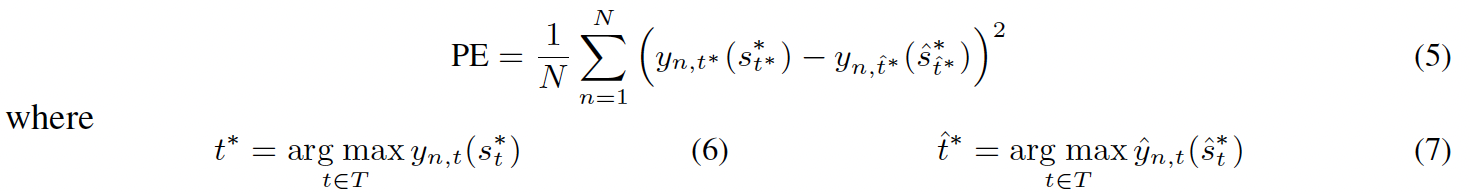
Model Architecture 从问题中我们可以看出现在有三层关系,一个个体,对应多个treatment,每个treatment有很多的剂量。因此本文将以往的工作进行扩展,提出了分层的结构。一个特征层提取协变量的特征,每个treatment对应一个branch将特征进一步处理,最后对于连续变量的问题,我们将区间分成E份,E越大,branch越密集,我们对连续变量的近似就越好,但是参数量也越大,二者是一个tradeoff。为了进一步提升对网络参数的影响,作者在head层每一层都会将concatenate进去。
treatment采用离散区间,非连续值
《Learning Disentangled Representations for CounterFactual Regression》 (DR-CFR)
ICLR 2020
为了处理选择性偏差,DR-CRF 提出了分离式表征的思想,通过将原始特征空间中的信息提取为不同类型的表征来实现反事实推断,并提出了一系列方法对模型进行约束以实现从有偏数据集中学习因果关系,但是其不足在于没有对模型添加分离式约束,无法保证所提取表征的分离性。
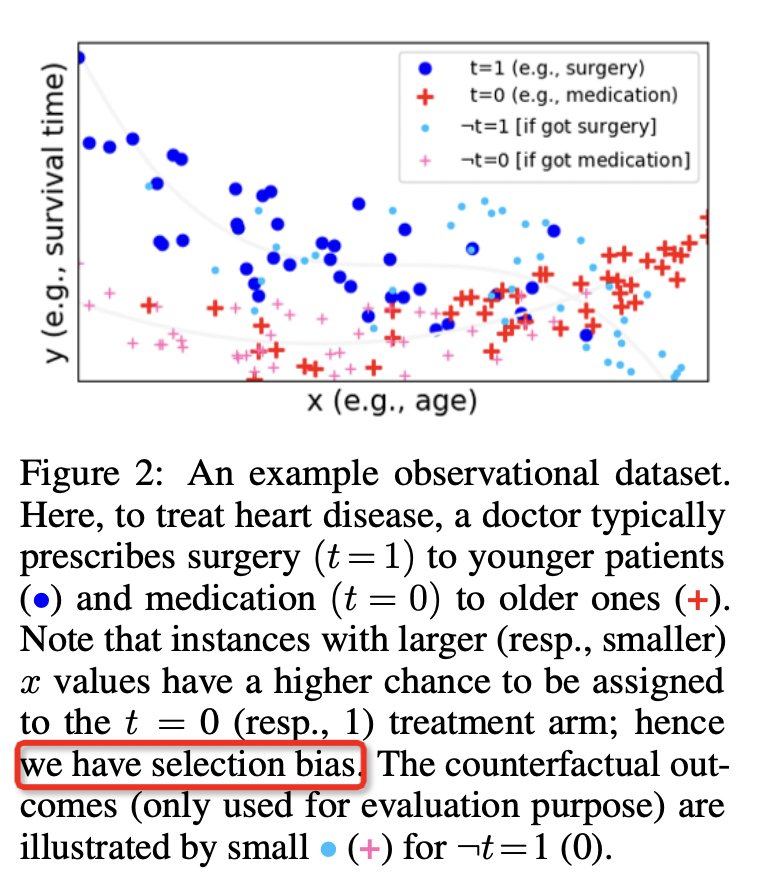

目标函数:
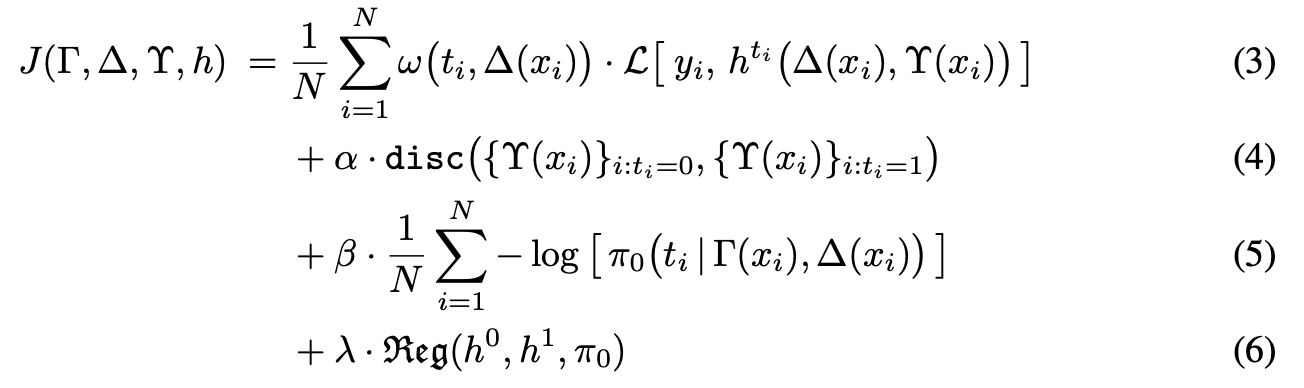

《Oral: VCNet and Functional Targeted Regularization For Learning Causal Effects of Continuous Treatments》
ICLR 2021 code
处理连续的treatment
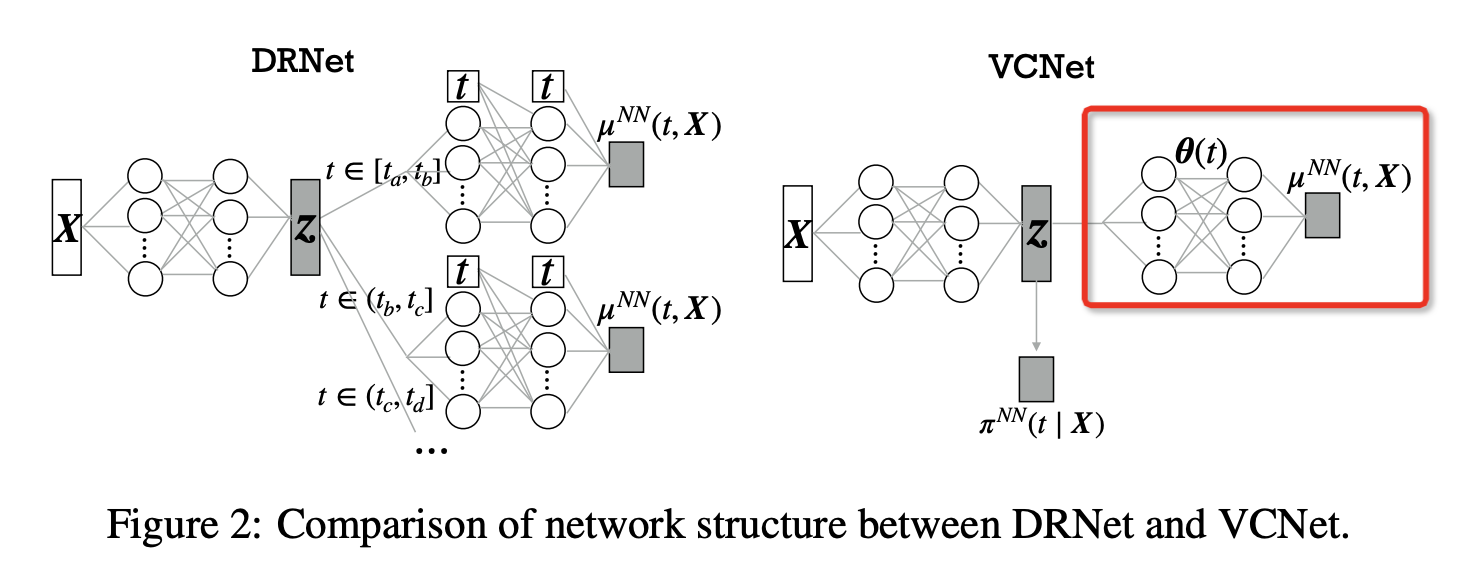
本文基于varying coefficient model,让treatment对应的branch成为treatment的函数,而不需要单独设计branch,达到真正的连续性。除此之外,本文也沿用了《Adapting Neural Networks for the Estimation of Treatment Effects》一文中的思路,训练一个分类器来抽取协变量中与T最相关的部分变量。
![]()

NN参数是t的函数,这意味着神经网络定义的非线性函数依赖于变化的treatment t。
《Neural Counterfactual Representation Learning for Combinations of Treatments》
Arxiv 2021
本文考虑更复杂的情况:多种treatment共同作用。作为一个具体的例子,考虑治疗HIV患者,医生会同时开出抗逆转录病毒药物的组合,而不是只给一种药,以防止病毒逃逸。这种场景非常具有挑战性,考虑15种可能的treatment,就有2^{15}种可能的组合,而大多数组合很少甚至不会出现在真实数据中。这时候如果我们沿用上述的做法,每种组合搞一个branch,参数量太大,而且每个branch相应的数据可能很少,很难训练。
本文提出了一种新的网络架构,如下所示,依然维护T个branch,如果协变量对应的多个treatment分别为,那么这三个branch都会进行训练。
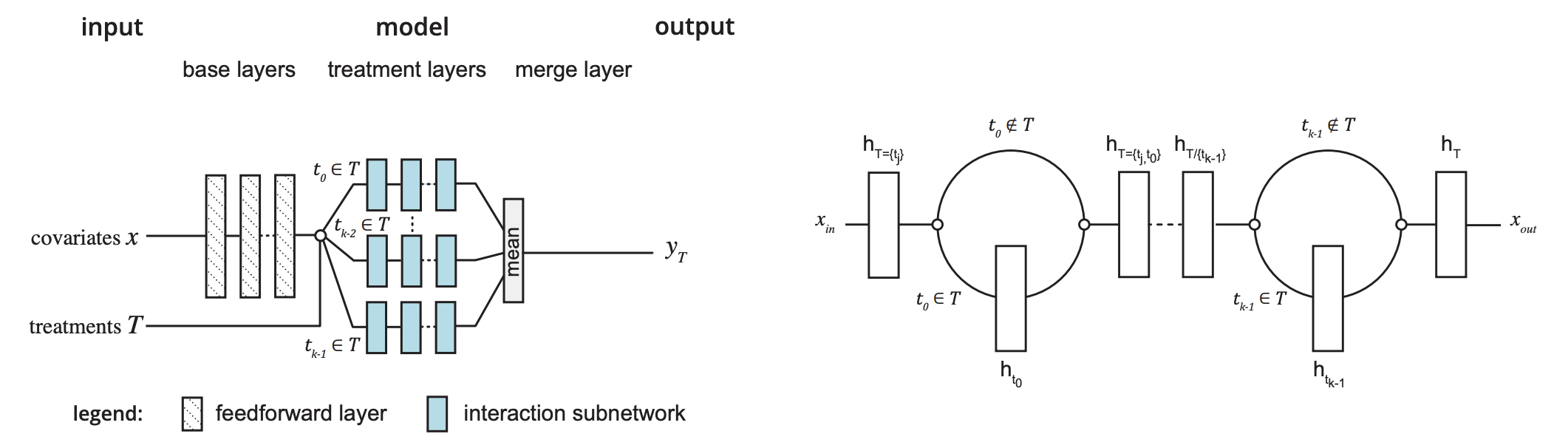
如何建模多个treatment之间的相互影响呢?答案就在于上图中的蓝色虚线,他们纵向是有相互连接的。最终所有treatment得到的embedding做均值得到最终的表达。
《DESCN: Deep Entire Space Cross Networks for Individual Treatment Effect Estimation》
KDD-2022
传统上,ITE 是通过在各自的样本空间中分别对实验组和对照组的响应函数进行建模来预测的。然而,这种方法在实践中通常会遇到两个问题:
- 由于干预偏差导致实验组和对照组之间的分布不同;
- 样本量的不平衡;
本文提出了深度全空间交叉网络(DESCN)从端到端的角度进行建模。 DESCN通过交叉网络以多任务学习的方式捕获干预的倾向、响应和隐藏干预效果的综合信息。
主要贡献:
- 提出一个端到端的多任务全空间交叉网络DESCN,用于估计ITE,可以缓解treatment偏差和样本不平衡的问题;
- 提出了全空间网络ESN用于建模全样本空间中treatment与response functions的联合分布,以往是分别基于control和treatment的样本进行训练;
- 公开大规模产业数据(Lazada),训练集中存在bias的treatment,测试集中为随机的treatmen(unbiased)。
Method
![]()

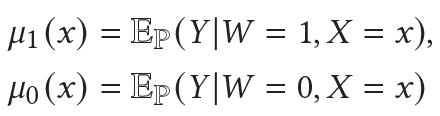
ITE:
![]()
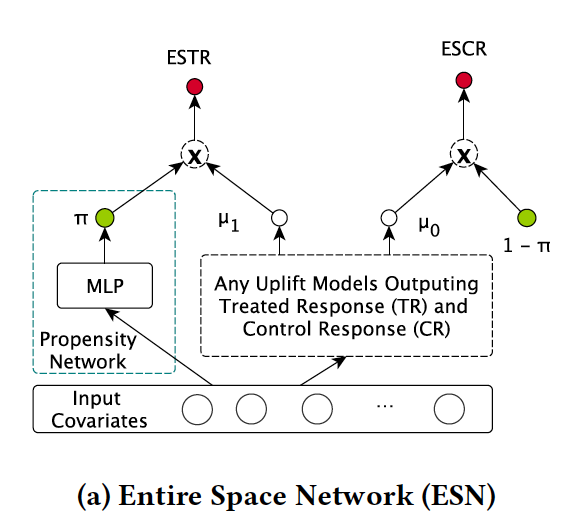
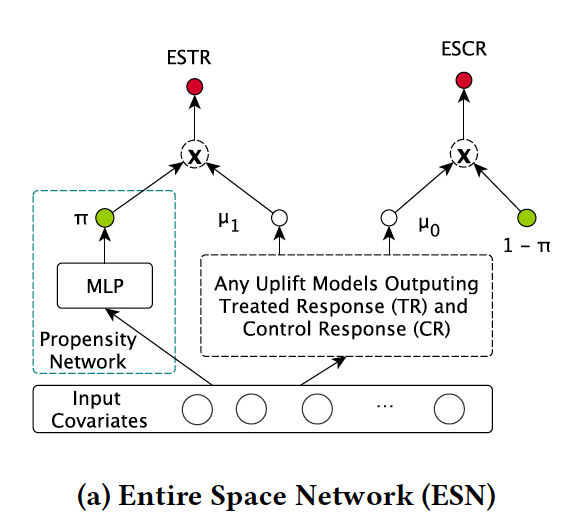
Entire Space Network (ESN)
全样本空间建模
Entire Space Treated Response (ESTR)
Entire Space Control Response (ESCR)
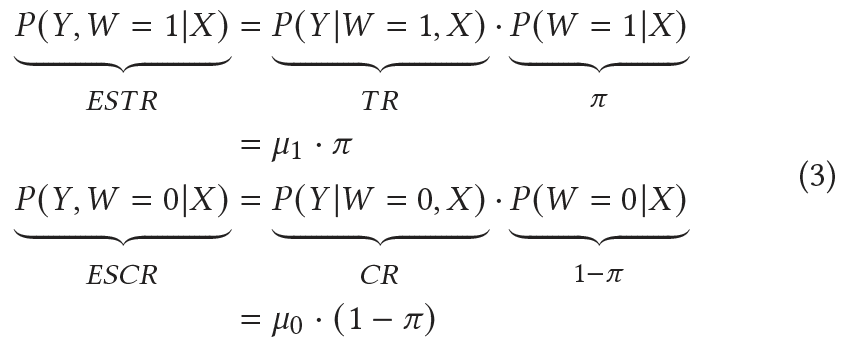
ESN Loss:
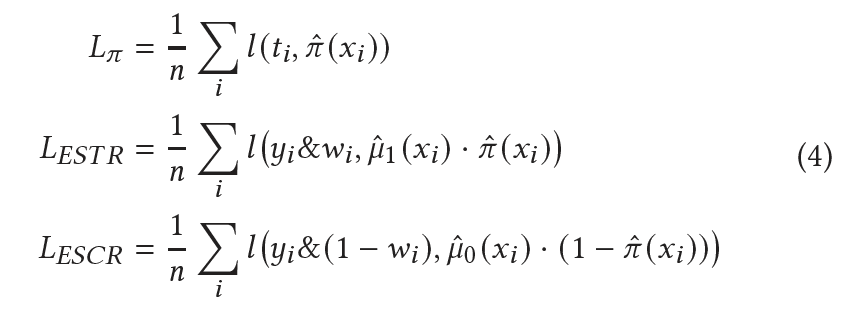
![]()
X-network
处理sample imbalance,引入Pseudo Treatment Effect network (PTE network)
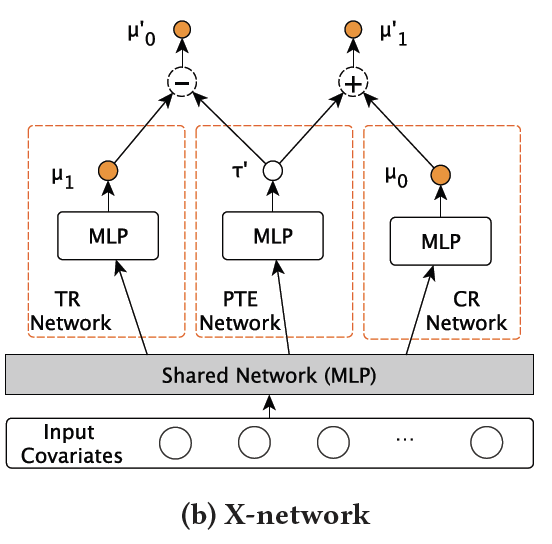
左右两个分支分别对干预组数据和对照组数据进行建模,中间的PTE(Pseudo Treatment Effe)得到τ′为干预带来的隐藏的效果。然后结合反事实,即干预的数据如果没有干预的话可以得到什么样的效果,反之亦然。
![]()
代表control组在treatment下的反事实结果。
![]()
代表treatment组在no treatment下的反事实结果。loss如下:
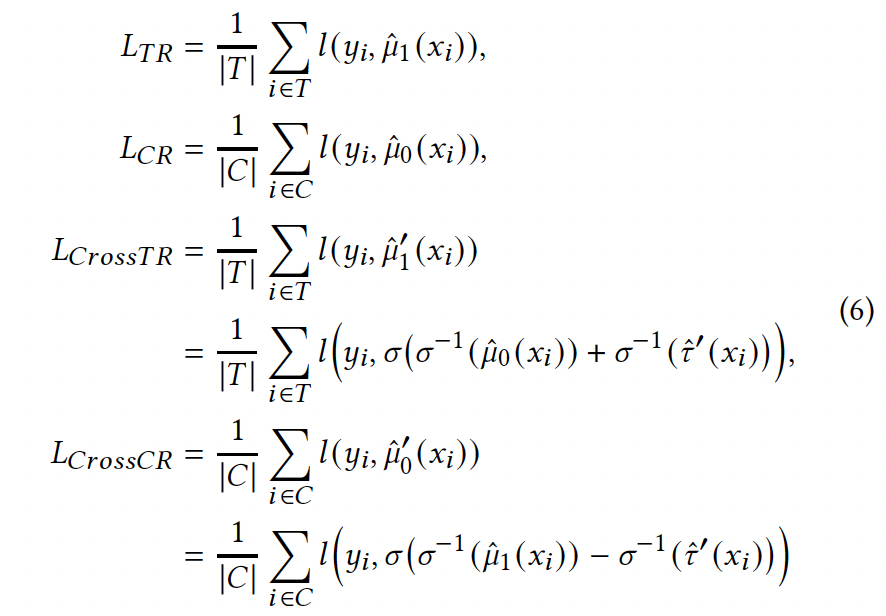
DESCN
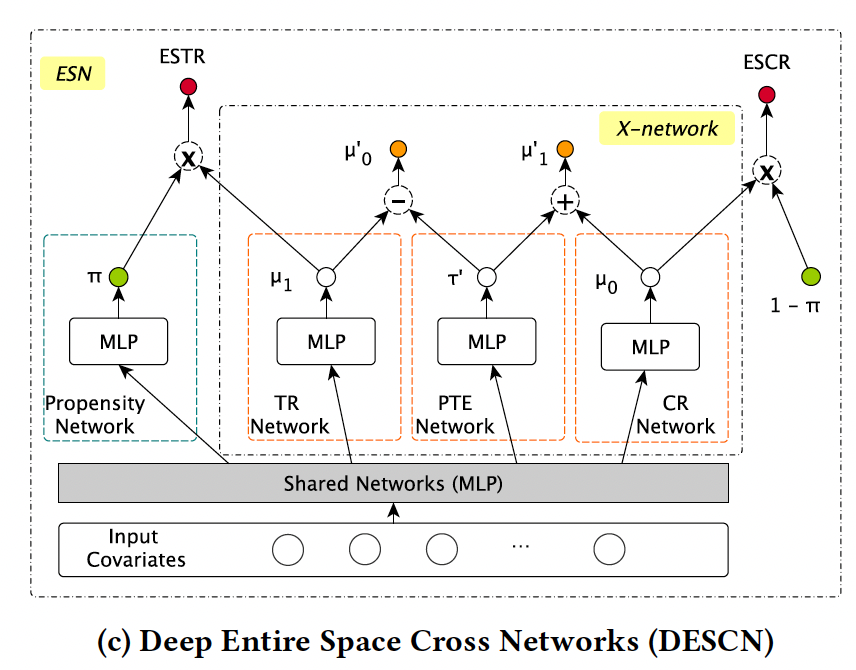
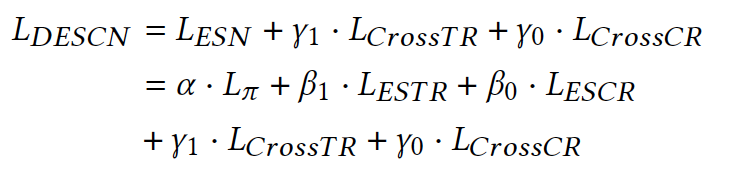
Entire Space Treated Response (ESTR)
Entire Space Control Response (ESCR)
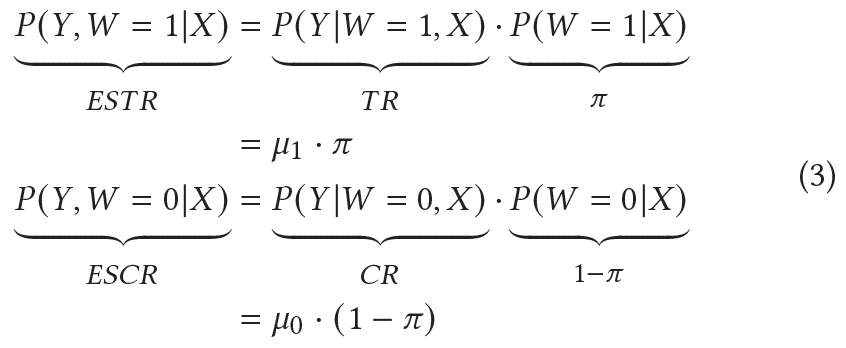
ESN Loss:
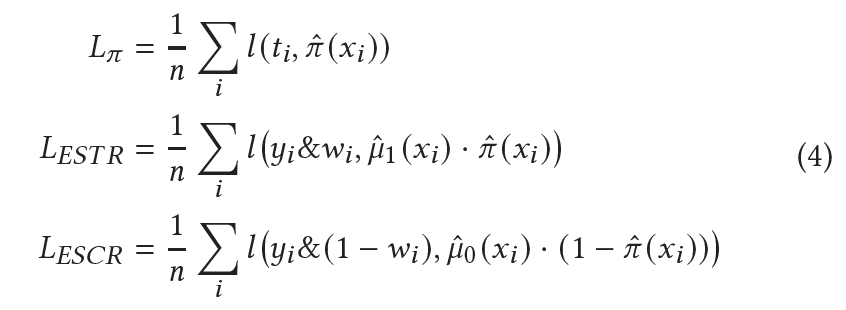
![]()
《EFIN: Explicit Feature Interaction-aware Uplift Network for Online Marketing》
KDD-2023
学习treatment的显示交互特征,详情见知乎
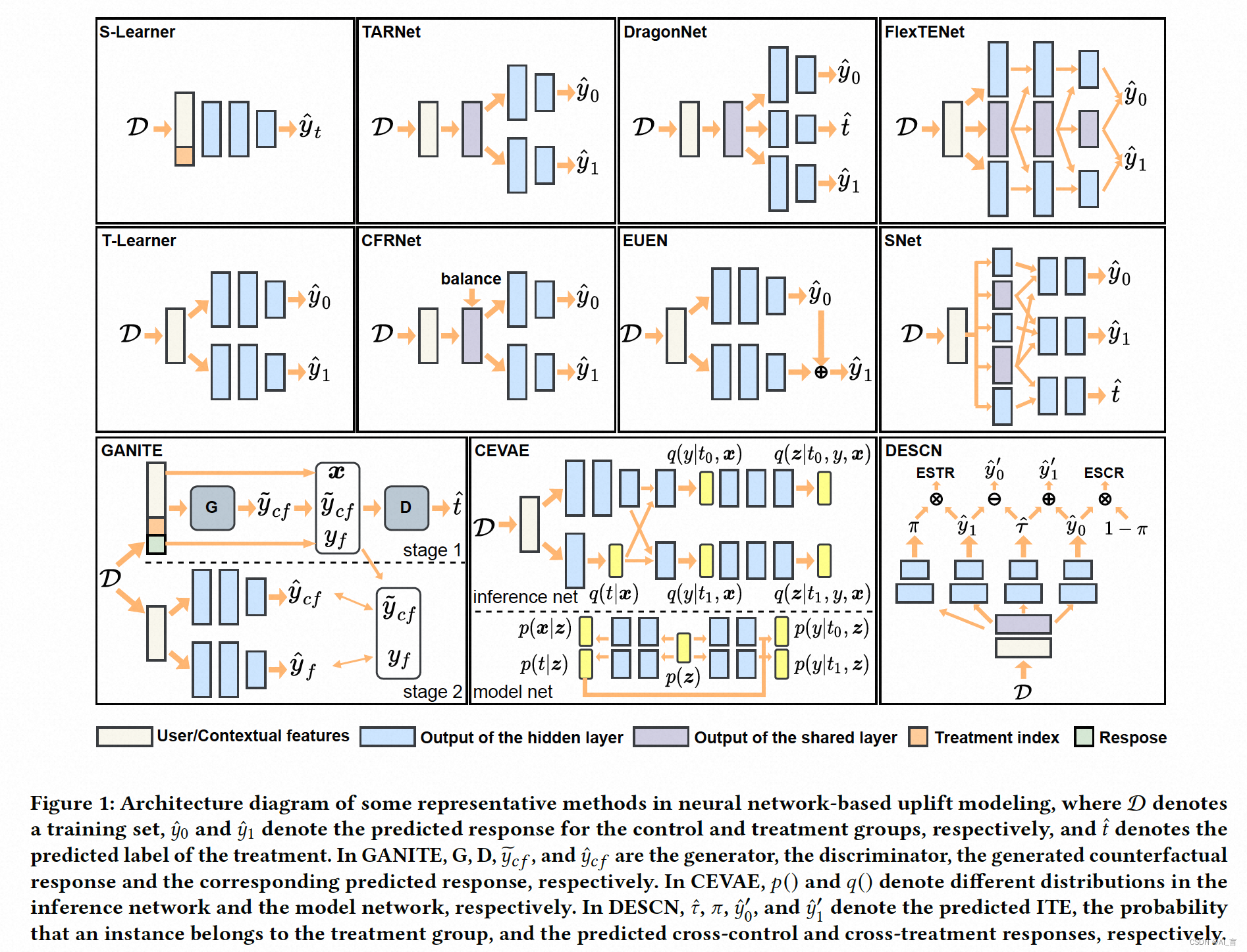
下面这张图汇总了大部分基于神经网络的ITE预估模型
文中提出的框架如下图:
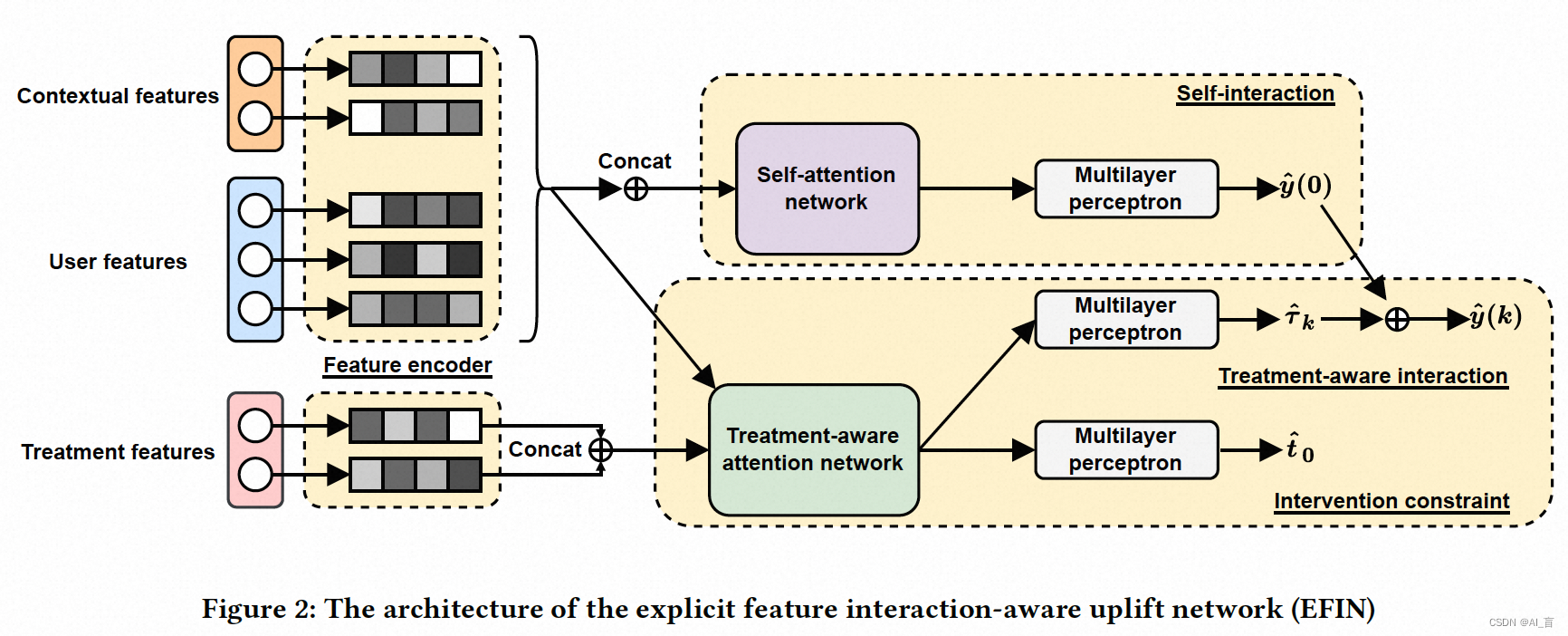
整体思路并不复杂,主要贡献在于treatment特征的处理上,这也是过去所有ITE模型没有仔细设计的地方。但有个问题是该模型无法保证treatment与outcome的单调性,这在营销场景中应该是个值得关注的点。
《CANDY: A Causality-Driven Model for Hotel Dynamic Pricing》
CIKM-2023
本文业务背景是酒店动态定价,其底层技术依赖也是对酒店价格的ITE估计,treatment为价格(连续型变量),outcome为预定概率,文中提出的模型CANDY本质上也是一个ITE预估模型。其主要解决了:
- 多值treatment在做ITE预估中面临的数据稀疏性问题;
- 很多工业场景中无法做随机实验,这就导致treatment bias问题;
- 实际业务中需要保证treatment与outcome的单调性。
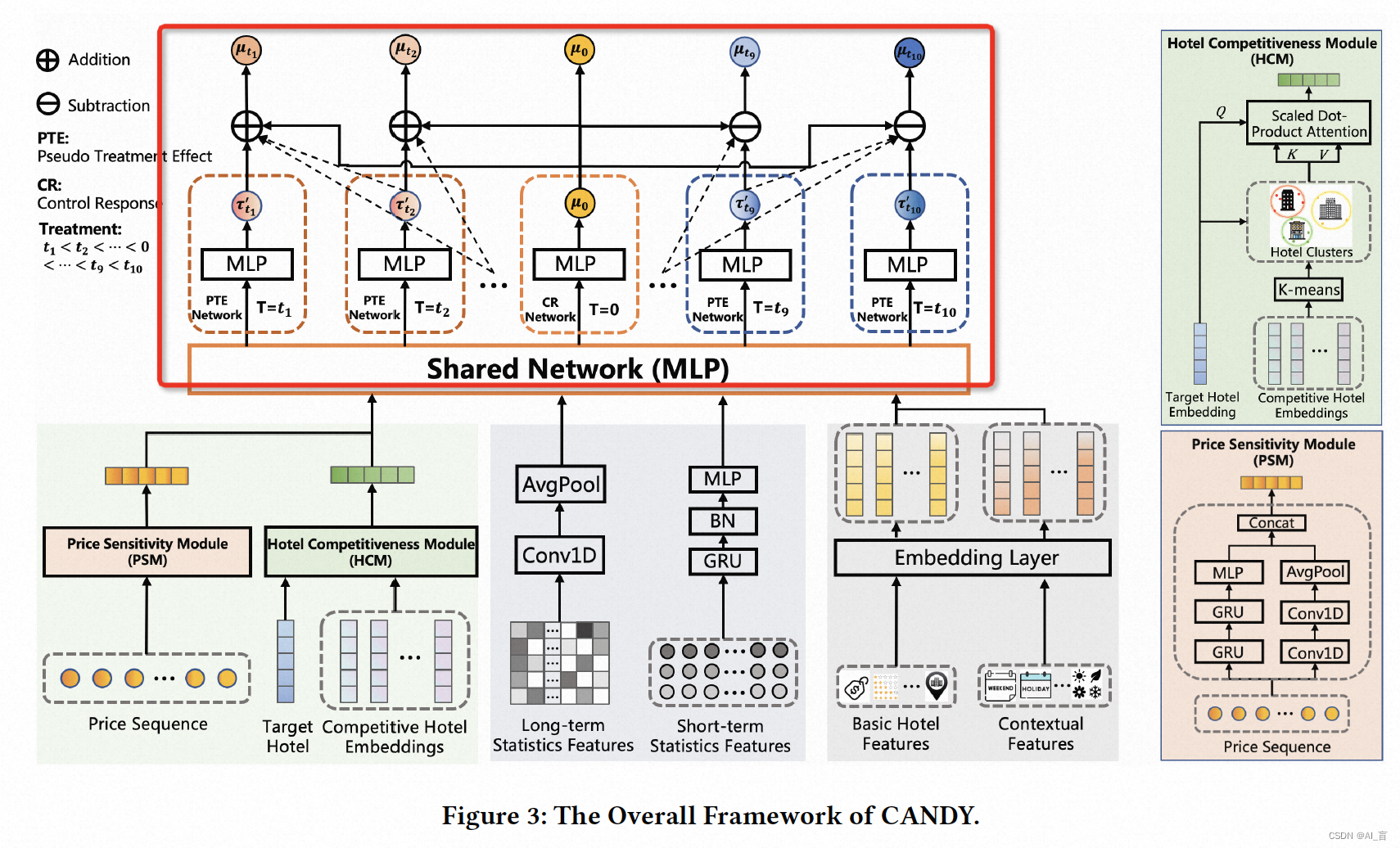
文中提出的模型如下图,MLP的输入在于酒店行业特色的特征处理,不是文中重点,主要关注MLP上面部分的结构,通过构造多个head,学习Pseudo effect,即Tao(t1)表示treatment从t2到变为t1的增量,通过该网络的设计能够保证treatment月outcome的单调性,另外能够缓解数据的稀疏性问题。为了处理treatment bias及数据稀疏性问题,文中提出了具有行业特色的数据增强方法,从训练数据层面缓解。
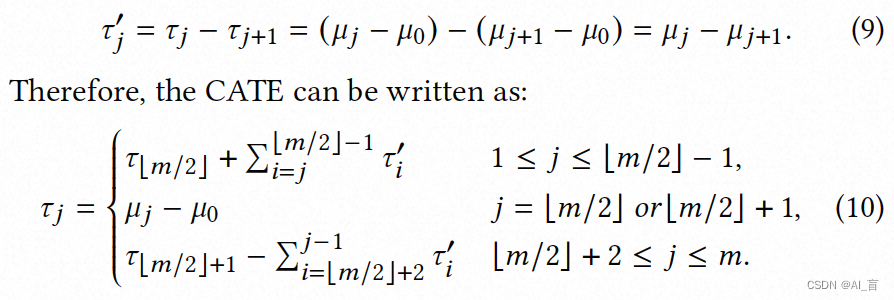
模型loss即将多头预估损失相加:
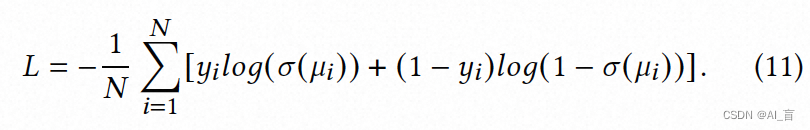
Double Machine Learning(DML)
2018
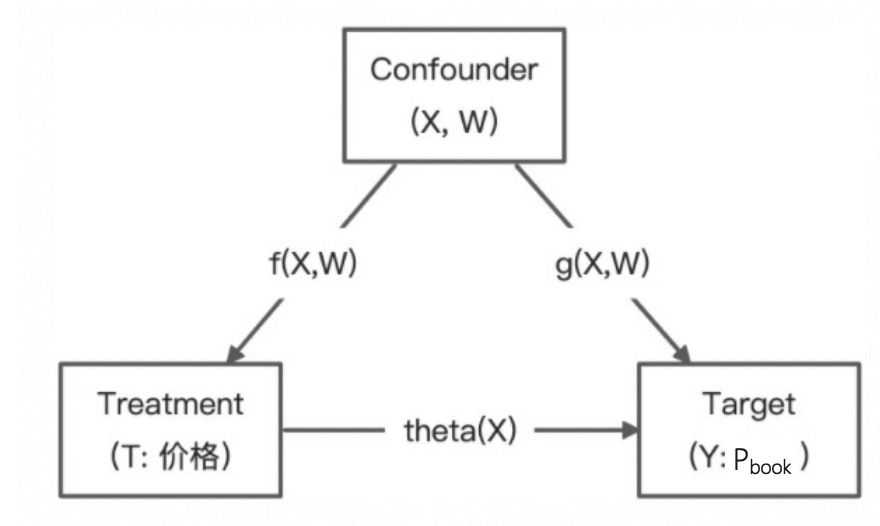
![]()
- 步骤1: 用任意ML模型拟合Y和T得到残差Y~,T~:
Y~=Y−Y^(X,W)=Y−E(Y|X,W); T~=T−T^(X,W)=T−E(T|X,W) - 步骤2: Y~=θ(X)T~,用任意ML模型拟合θ(X), θ^=argminθE[(Y~−θT~)2]。直观上,对θ的拟合有以下两种方式:
1.【OLS】参数模型:最小二乘法直接求解,θ^=Cov(Y~,T~)Var(T~)。
2.【DML naive】非参数模型:以loss为(Y~−θT~)2=T~2(Y~T~−θ)2,label为Y~T~,样本权重为T~2,训练模型得到θ^。
但是,以上两个方法无法保证对θ的估计是无偏的,DML保证估计无偏很重要的一步就是cross-fitting,用来降低overfitting带来的估计偏差,见步骤3. - 步骤3: 【DML cross-fitting】:先把总样本分成两份(样本1,样本2)。先用样本1估计残差,样本2估计;再用样本2估计残差,样本1估计,取平均得到最终的预估模型。当然也可以进一步使用K-Fold来增加估计的稳健性。3种方法的比较发现:DML cross-fitting最接近真实的参数分布。

















 99
99

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









