







简单来说,sampler用于生成图片序号idx返回给dataloader,dataloader再把idx传给dataset的getitem函数,dataset的getitem函数再根据idx来用Image.open()等函数读取图片。
总述:for循环先进入dataloader的__iter__函数,然后__iter__调用dataloader的__next__函数,__next__函数调用dataset的__getitem__,__getitem__读取完一个batch的数据后返回值送入dataloader的collate_fn函数进行处理。
这里补充一个只是,dataloader的num_worker参数,它就是在dataloader读数据的时候起作用的,比如正常来说,如果num_worker=0,则每次读完一个batch的数据以后,代码会从dataloader的collate_fn直接返回到雪莲时候的for循环,然后就是正常的训练了,但如果设置了num_worker,比如设置为num_worker=2,那么在读数据的时候,其实是一次性读取了5个batch的数据,原因在于,num_worker=2,代表用2个进程来读数据,每个进程读batch个数据,比如我们设置batch=2,那么这时候两个进程共读取了batch=4的数据,但是由于我们送出去以后,有一个进程就少了一个batch的数据,因此,这个少了batch的进程又会读一个batch进来,也就是或每个进程是保证有指定batch个数据的。
sampler
如图为我们自定义的一个sampler:其中最主要的是:
1:自定义sampler必须继承自Sampler
2:重写__iter__函数,这个函数是用来生成一个序列的迭代器,这个迭代器就是传给dataloader的
3:必须定义 __len__函数,并且该函数只返回每一个GPU要处理的数据长度,但只有一张卡的时候,就是整个数据的长度
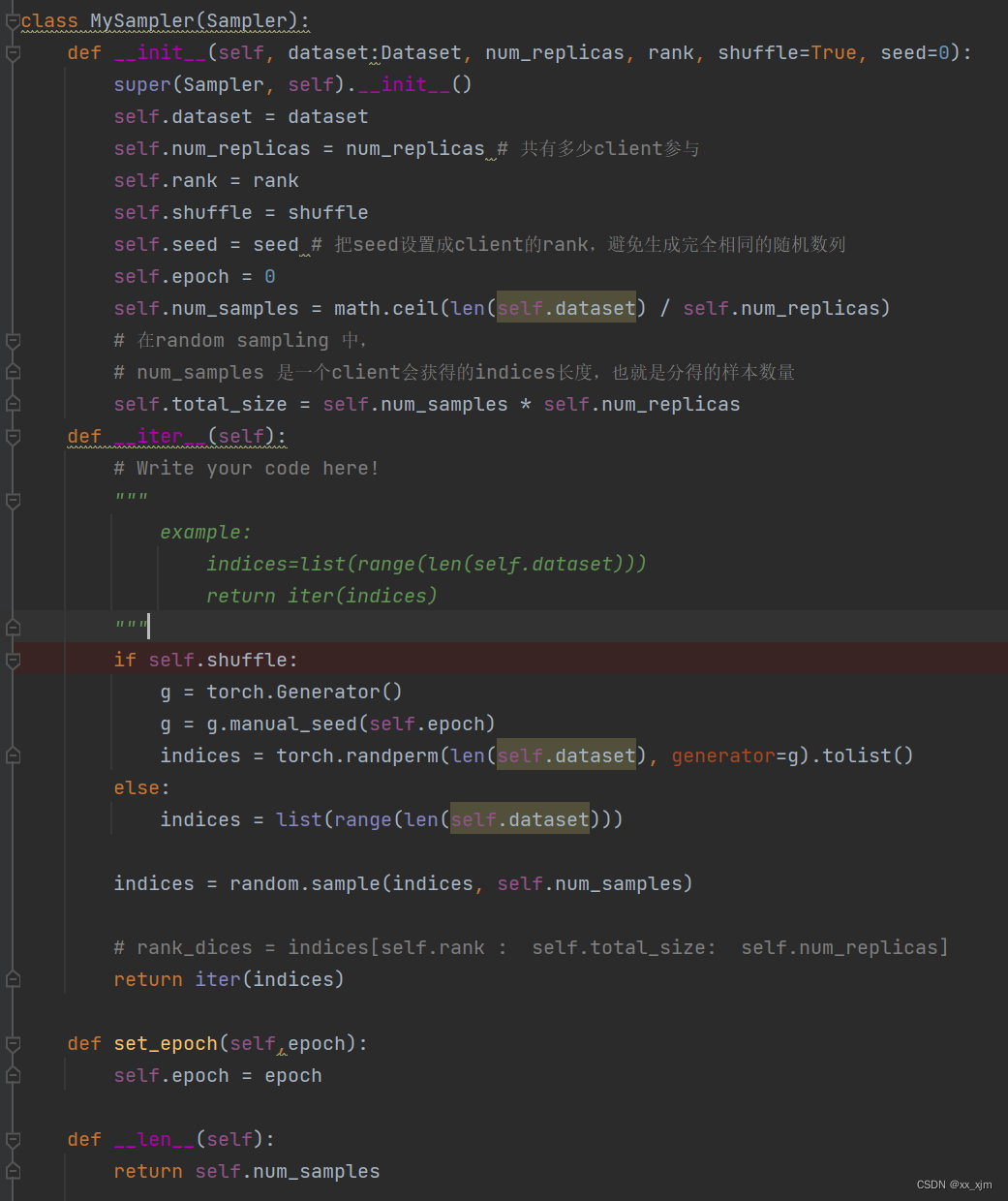
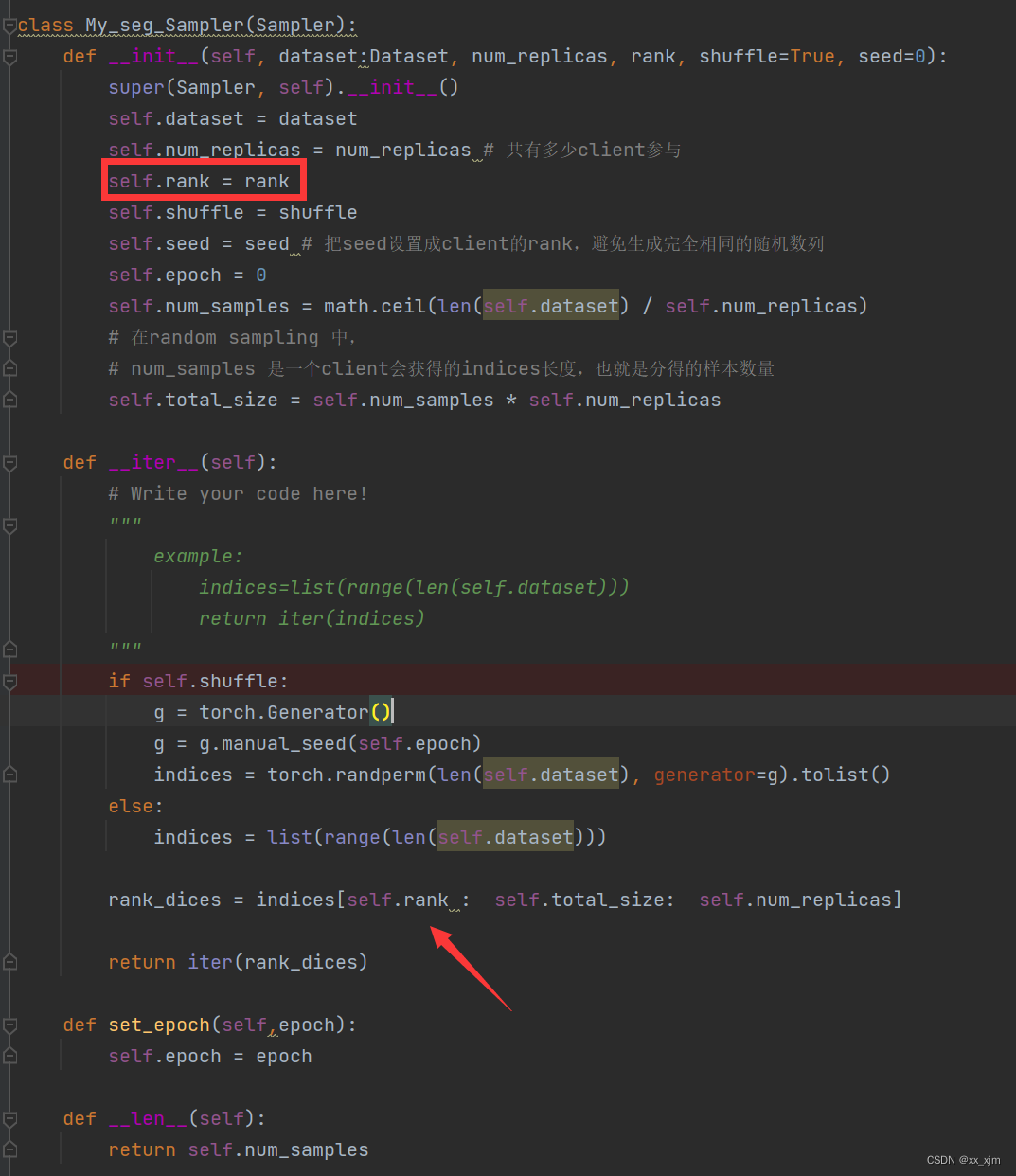
我们看一下分布式里面sampler到底是怎么定义的:如下图,是一个用于分布式的sampler,其中最关键的就是self.rank这个属性,它指明了不同的rank,同时在__iter__中用于为不同rank生成不同的序列迭代器。















 3983
3983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









