






知识图谱
Large Language Models for Generative Information Extraction: A Survey
信息抽取(IE)致力于从自然语言文本中提炼出结构化知识,如实体、关系和事件。生成型大型语言模型(LLMs)近期在文本理解和生成领域大放异彩,展现出跨领域的泛化能力。鉴于此,众多研究纷纷利用 LLMs 的潜能,为 IE 任务提供了基于生成范式的创新解决方案。本研究旨在对 LLMs 在 IE 领域的应用进行深入的系统回顾,我们首先根据 IE 子任务和学习范式对相关工作进行分类概述,随后实证分析了前沿技术,揭示了 LLMs 与 IE 任务结合的新趋势。通过详尽的回顾,我们指出了技术上的洞见和未来研究值得深究的方向,并维护了一个公共资源库,持续更新相关资料,地址为:\url{https://github.com/quqxui/Awesome-LLM4IE-Papers}。
https://arxiv.org/abs/2312.17617
1. 背景
信息抽取(Information Extraction, IE)是自然语言处理领域的核心,也是构建知识图谱、知识推理和知识问答等众多下游任务的基础。信息抽取一般包括:命名实体识别(Named Entity Recognition, NER)、关系抽取(Relation Extraction,RE )和事件抽取(Event Extraction)。
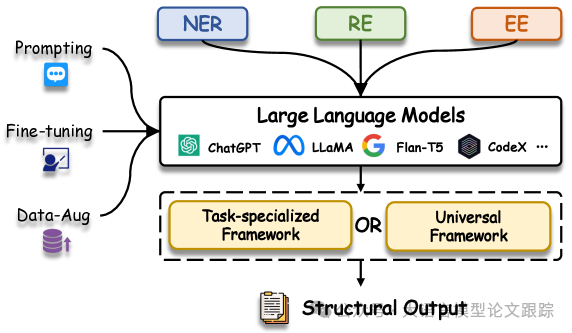
随着大语言模型的兴起,比如GPT4,信息抽取领域迎来了重大发展,因为这些模型在文本理解等方面能力非常强悍。所以现在大家都倾向于使用LLM来进行信息抽取任务。
-
• 命名实体识别(NER):囊括了两项任务:首先是实体识别,它负责辨认出文本中的实体部分(如“Steve”);其次是实体分类,为识别出的实体贴上类型标签,比如:人物。
-
• 关系抽取(RE):在不同研究中有着不同的应用场景。将其分为三大类:
-
-
• (1)Relation Classification:
即确定两个实体间的关系类别;
-
• (2)Relation Triplet:
即找出关系类型及其对应的主体和客体实体;
-
• (3)Relation Strict:
即精确指出关系类型、实体跨度以及主体和客体的类别。
-
-
• 事件抽取(EE):则分为两个子任务,
-
-
• (1)事件检测(Event Detection):
有时也称作事件触发器抽取,其目标是识别并界定最能体现事件发生的触发词及其类型;
-
• (2)事件论元抽取(Event Arguments Extraction):
其目的在于从文本中找出并分类事件中扮演特定角色的论元。
-
2. 按任务类型分类
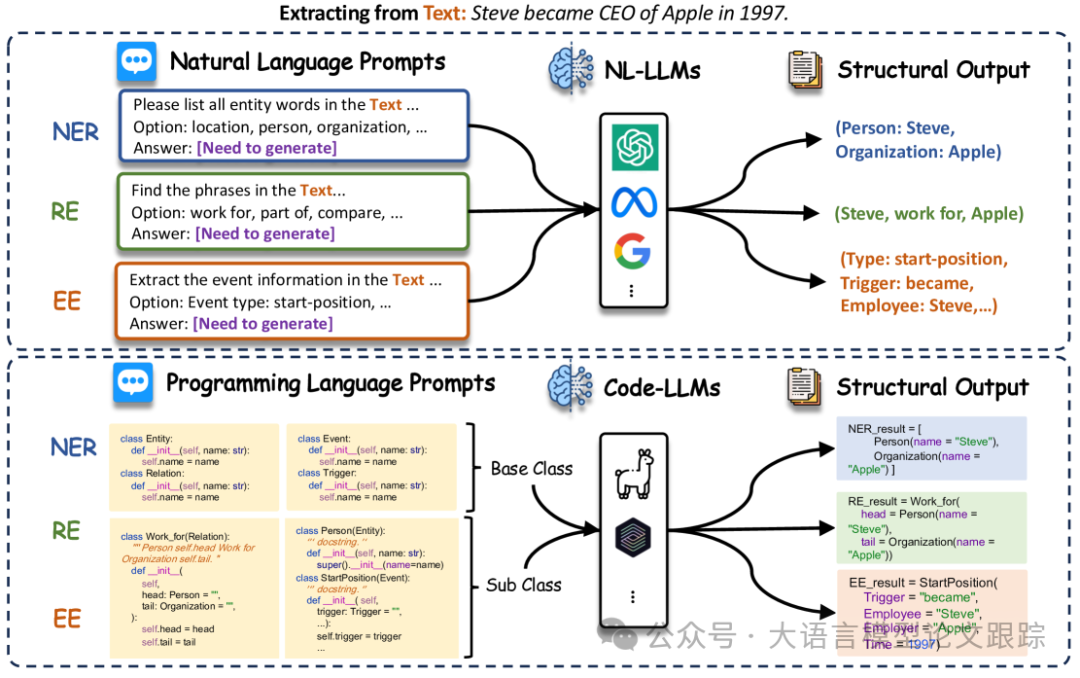
如上文提到的,按任务类型分类,信息抽取任务可以分为:命名实体识别(Named Entity Recognition, NER)、关系抽取(Relation Extraction,RE )和事件抽取(Event Extraction)。
2.1 命名实体识别(NER)
命名实体识别(NER)作为信息抽取(IE)的核心环节,同时在关系抽取(RE)和事件抽取(EE)中充当基础或前置任务。它在自然语言处理(NLP)的其他领域也是基石般的存在,因此成为研究者在大型语言模型(LLMs)时代探索新视野的热点。
夏等人(2023b)通过将所有概率质量集中在观测序列上引入了偏差;本文则提出了一种在序列到序列(Seq2Seq)框架下的基于重新排名的方法,该方法利用对比损失在候选序列间重新分配可能性,而非简单地扩充数据集。鉴于NER的序列标注特性与LLMs等文本生成模型之间的差异,GPT-NER王等人(2023b)提出了将NER问题转化为生成任务的创新思路,并设计了一种自我验证策略,以纠正将NULL输入误判为实体的问题。谢等人(2023b)提出了一种无需额外训练的自我提升框架,该框架通过大型语言模型(LLM)对未标注语料库进行预测,生成伪标签,以此提升LLM在零样本NER任务中的表现。
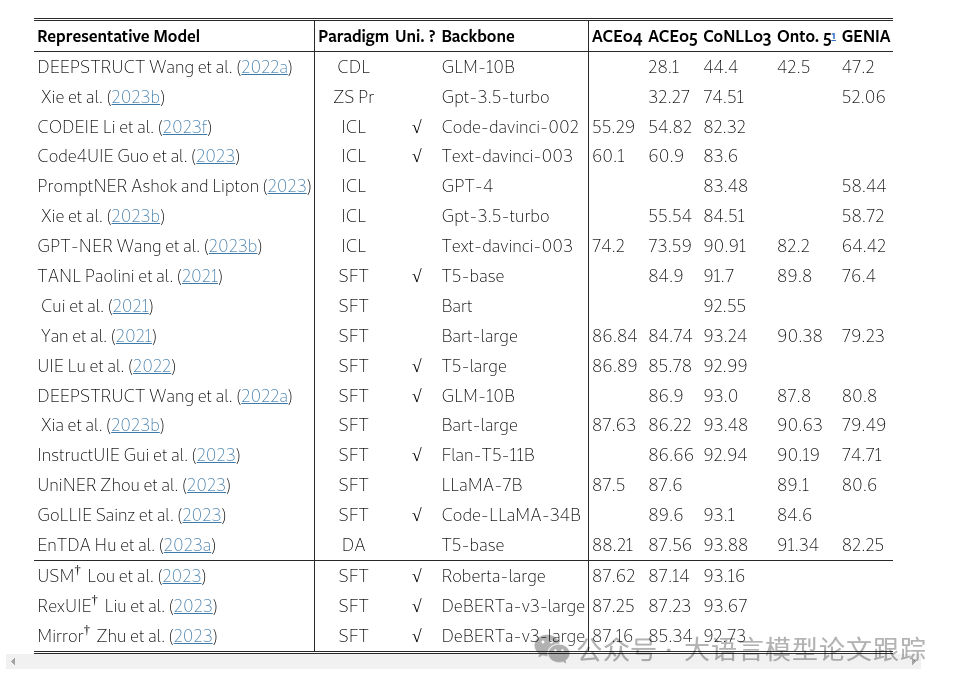
上图展示了五个主要数据集上NER性能的对比,可以发现:
- • 1)在少样本和零样本场景下的模型与在监督微调(SFT)和领域适应(DA)场景下的模型相比,性能差距依然显著。
- • 2)尽管不同模型的基础架构差异不大,但在上下文学习(ICL)框架下,不同方法之间的性能却大相径庭。例如,GPT-NER在各个数据集上的F1值至少比其他方法高出6%,最高可达19%。
- • 3)与ICL相比,在SFT框架下,即使模型的基础参数相差数百倍,它们的性能差异也相对较小。
小编:在ICL方法中,GPT-NER方法在各个数据集中得分是最高的
附上表中的缩写:
- • Cross-Domain Learning (CDL)
- • Zero-Shot Prompting (ZS Pr)
- • In-Context Learning (ICL)
- • Supervised Fine-Tuning (SFT)
- • Data Augmentation (DA)
2.2 关系抽取(Relation Extraction,RE)
总体而言,LLM在关系抽取任务上表现一般,主要原因可能是由于指令调优数据集里关系抽取的数据比较少。
- • Zhang等人(2023b)的QA4RE提出了一种框架,通过将关系抽取任务与问答任务相结合来提升LLMs的性能。
- • Wan等人(2023)的GPT-RE则通过引入任务感知表示和注入推理逻辑的演示,增强了实体与关系之间低相关性的问题,以及解释输入与标签映射的不足。
- • 面对预定义关系类型的繁多和LLMs的难以控制,Li等人(2023e)建议将LLM与自然语言推理模块相结合,以生成关系三元组,从而增强文档层面的关系数据集。
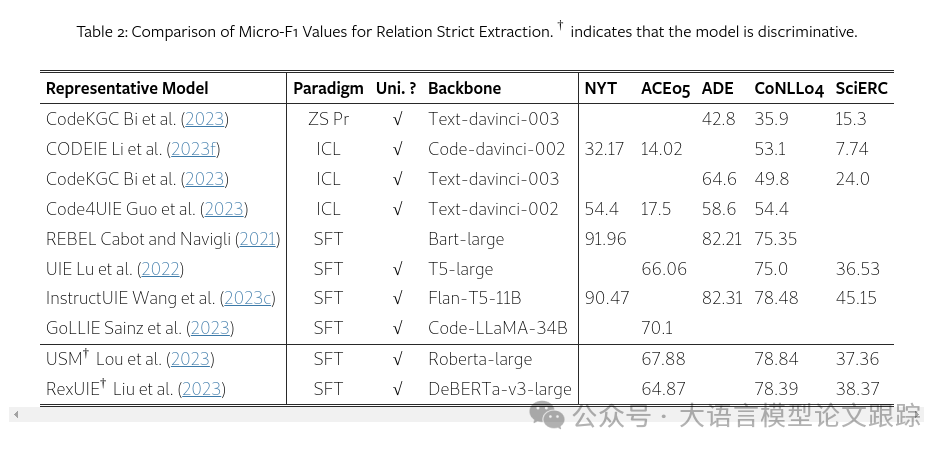
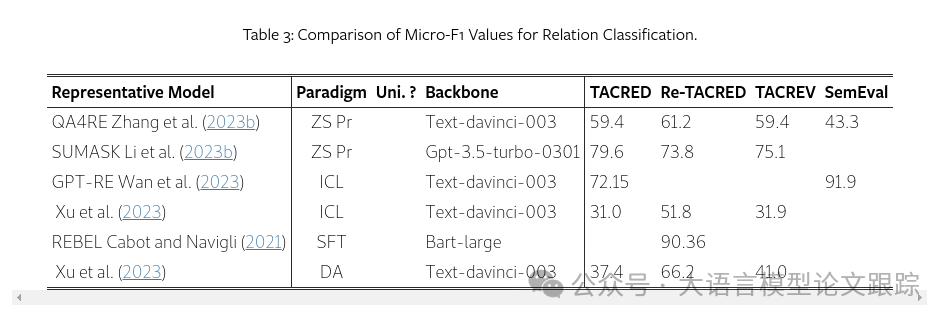
从上面两个表的统计数据中可以发现,uni-ie模型倾向于解决更具挑战性的Relation Strict问题,这是因为它们学习了多任务间的相互依赖,如Paolini等人(2021)和Lu等人(2022)所指出的;而特定于任务的方法则更多地解决了较为简单的关系抽取子任务,例如关系分类。此外,与命名实体识别(NER)相比,关系抽取(RE)中模型性能的差异更为显著,这表明LLM在关系抽取任务上的潜力尚有很大的挖掘空间。
2.3 事件抽取(Event Extraction)
事件可被界定为在特定情境中发生的特定事件或事故。
- • 如Lu等人(2023)致力于通过大型语言模型(LLMs)提取事件触发词和观点,以理解事件并捕获它们之间的联系,这对于多样的推理任务而言至关重要。
- • Zhou等人(2022b)提出的ClarET模型通过三项预训练任务,更高效地捕捉事件间的相互关系,并在众多下游任务中取得了最先进的成绩(SOTA)。
- • Wang等人(2023d)开发的Code4Struct模型则利用LLMs将文本转化为代码,以应对结构化预测任务,通过结构与代码之间的对应关系,引入外部知识和约束。
- • Luo和Xu(2023)提出的PGAD模型考虑到扩展上下文中不同论元间的相互联系,采用文本扩散模型生成多样的上下文感知提示表示,通过识别并协调多个与角色特定的论元范围查询,提升了句子级和文档级事件论元抽取的效果。
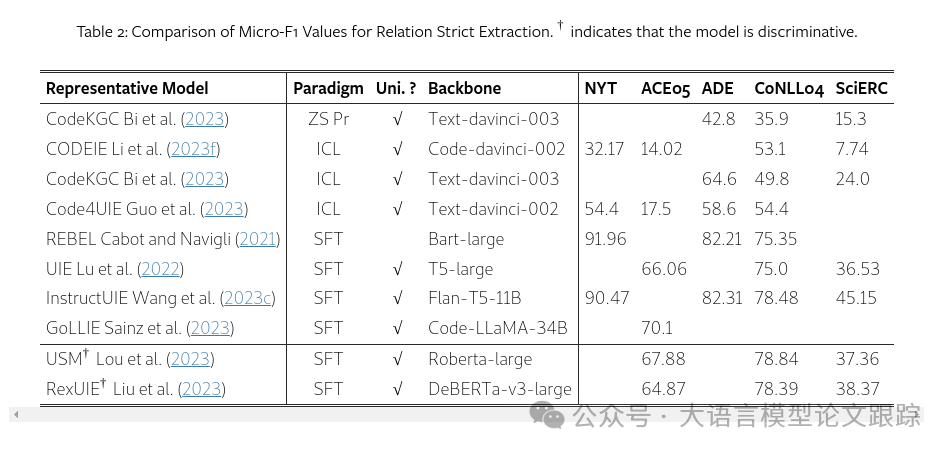
上表中汇总了基于常见事件抽取数据集ACE05的近期研究实验结果。结果显示,目前绝大多数方法均基于监督式微调(SFT)范式,而采用LLMs进行零样本或少样本学习的方法相对较少。此外,生成性方法在观点分类指标上显著优于区分性方法,这表明在事件抽取领域,生成性LLMs拥有巨大的发展潜力。
3. 信息抽取框架
过去,很多信息抽取框架只针对某一类抽取任务,但是随着大语言模型的发展,越来越多的框架支持所有的信息抽取任务。这其中又可以根据抽取方式的不同,分为基于自然语言的LLMs(NL-LLMs)和基于代码的LLMs(code-LLMs)。
3.1 基于自然语言的LLMs(NL-LLMs)
基于自然语言的方法将所有信息抽取任务统一到一个通用的自然语言架构中。例如,Lu等人(2022)提出的UIE采用统一的文本到结构生成框架,通过结构化提取语言编码抽取结构,捕捉信息抽取的共通能力。Wang等人(2023c)的InstructUIE通过专家编写的指令集来增强UIE,微调LLMs以一致性地模拟不同的信息抽取任务,捕捉任务间的相互依赖。Wei等人(2023)的ChatIE则探索了使用如GPT3和ChatGPT这样的LLMs进行零样本提示,将任务转化为多轮问答形式。
3.2 基于代码的LLMs(code-LLMs)
基于代码的方法通过生成符合通用编程架构的代码来统一信息抽取任务,如Wang等人(2023d)所述。Guo等人(2023)的Code4UIE提出了一个通用的检索增强型代码生成框架,使用Python类定义架构,并通过上下文学习从文本中生成代码以抽取结构化知识。Bi等人(2023)的CodeKGC则利用代码中固有的结构知识,采用架构感知提示和理由增强生成来提升性能。Sainz等人(2023)提出的GoLLIE旨在通过微调LLMs以符合注释指南,增强在未见信息抽取任务上的零样本性能。
4. 学习范式
根据学习范式对方法进行分类,涵盖监督式微调、少样本学习、零样本学习和数据增强。
4.1 监督式微调
将全部训练数据输入以微调LLMs,这种方法常见,它使模型能够捕捉数据中的结构性模式,并良好地泛化至未见过的IE任务。例如,Deepstruct通过结构预训练来增强语言模型的结构理解;UniNER探索了针对性的蒸馏和指令调整,以训练学生模型广泛用于命名实体识别(NER)等任务;GIELLM则利用混合数据集微调LLMs,以提升多任务性能。
4.2 少样本学习
少样本学习面对的挑战包括过拟合和难以捕捉复杂关系。然而,扩大LLMs的参数规模赋予了它们出色的泛化能力,使它们在少样本场景中表现卓越。TANL、UIE和cp-NER等创新方法通过翻译框架、文本到结构生成框架和领域前缀调整等策略,实现了少样本微调的先进性能。尽管LLMs取得了成功,但在无训练的IE任务中仍面临挑战。GPT-NER和GPT-RE通过自我验证策略和增强任务感知表示,展示了如何有效利用GPT进行上下文学习。CODEIE和CodeKGC则表明,将IE任务转换为代码生成任务,可以获得比自然语言LLMs更优越的性能。
4.3 零样本学习
零样本学习的主要挑战在于使模型有效泛化至未训练的任务和领域,并与LLMs的预训练范式对齐。LLMs因其丰富的知识储备,在未见任务的零样本场景中展现出令人印象深刻的能力。为了实现LLMs在IE任务中的零样本跨域泛化,提出了多项工作,提供了一个通用框架来建模各种IE任务和领域,并引入了创新的训练提示。BART-Gen提出了一个文档级神经模型,通过将实体抽取任务制定为条件生成,实现了更好的性能和可移植性。
4.4 数据增强
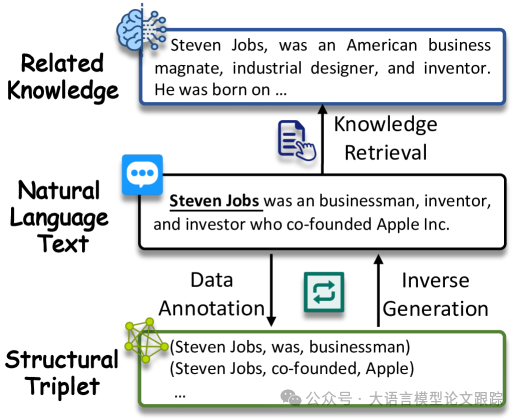
数据增强通过创造丰富多样的数据来提升训练样本或信息的质量,同时避免引入不真实、误导性或有偏差的模式。当前强大的大型语言模型(LLMs)在数据生成任务上展现出了卓越的能力,这激发了众多研究者利用LLMs为信息抽取(IE)领域生成合成数据的兴趣。这一过程大致可分为三大策略,如上图所示。
4.4.1 数据注释策略
直接利用LLMs生成带有标签的数据。例如,Zhang等人(2023c)提出的LLMaAA,通过在主动学习循环中将LLMs作为注释器使用,以提高数据的准确性和效率,优化了注释与训练流程。AugURE由Wang等人(2023a)开发,它通过句子内对的增强和跨句子对的提取,增强了无监督实体识别(RE)中正例的多样性,并引入了针对句子对的边界损失。
4.4.2 知识检索策略
旨在从LLMs中提取与IE相关的知识。Li等人(2023d)提出的PGIM采用了一个两阶段框架,利用ChatGPT作为一个隐式知识库,以启发式的方式检索辅助知识,提高实体预测的效率。Amalvy等人(2023)提出通过创建合成的上下文检索训练数据集,并训练一个神经网络上下文检索器,来提升长文档的命名实体识别(NER)性能。
4.4.3 逆向生成策略
鼓励LLMs根据输入的结构化数据生成自然文本或问题,与LLMs的训练模式保持一致。Josifoski等人(2023)的SynthIE展示了LLMs能够通过逆转任务方向,为复杂任务创造高质量的合成数据。他们利用这种方法为封闭信息提取创建了大型数据集,并训练出了超越以往标准的模型。这证明了利用LLMs生成复杂任务合成数据的潜力。Ma等人(2023b)的STAR项目则不依赖于真实目标,而是从有效的触发器和参数生成结构,然后由LLMs生成段落,这避免了限制泛化性和可扩展性的问题。
综合来看,这些策略各有利弊。数据注释能够直接满足任务需求,但LLMs在结构化生成方面的能力还有待提升。知识检索可以提供关于实体和关系的额外信息,但可能会产生幻觉问题并引入噪声。逆向生成与LLMs的问答(QA)范式相吻合,但需要结构化数据,且在生成对与领域之间存在一定的差距,需要进一步解决。
5. 领域知识
不可忽视,大型语言模型(LLMs)在挖掘特定领域信息方面拥有巨大潜力,如多模态信息处理Chen和Feng(2023);Li等人(2023d)、医疗信息Tang等人(2023);Ma等人(2023a)以及科学文献Dunn等人(2022);Cheung等人(2023)的分析。例如,在多模态领域,Chen和Feng(2023)提出了一种条件性提示蒸馏技术,它通过结合文本-图像配对与LLMs的思维链知识,显著提升了多模态命名实体识别(NER)和实体识别(RE)的性能。
在医疗领域,Tang等人(2023)深入探究了LLMs在临床文本挖掘中的应用,并提出了一种创新的训练策略,该策略通过使用合成数据来增强性能并解决隐私保护问题。
在科学文献分析方面,Dunn等人(2022)展示了一种使用GPT-3的序列到序列方法,有效地从复杂的科学文本中联合提取命名实体和实体,特别是在材料化学领域,证明了其在提取复杂科学知识方面的卓越能力。
6. 未来展望
融合大型语言模型(LLMs)以构建生成式信息抽取(IE)系统仍处于起步阶段,提升空间广阔。
6.1 通用IE
传统生成式IE技术和评测基准往往针对特定领域或任务定制,这限制了它们的普适性Yuan等人(2022)。虽然近期提出了一些利用LLMs的通用方法Lu等人(2022),但它们仍存在局限,如处理长上下文输入和结构化输出的不一致性。因此,开发能够灵活适应多样化领域和任务的通用IE框架,是未来研究的一大方向,比如整合特定任务模型的洞察来辅助构建通用模型。
6.2 低资源IE
在资源受限的环境中,结合LLMs的生成式IE系统依旧面临挑战Li等人(2023a)。综上,需要进一步挖掘LLMs的上下文学习能力,尤其是在提升样本选择上。未来研究应着重开发强大的跨领域学习技术Wang等人(2023c),例如通过领域适应或多任务学习,从资源丰富的领域中汲取知识。同时,也应探索与LLMs结合的高效数据注释策略。
6.3 IE的提示设计
精心设计的指令对LLMs的性能有着重要影响Qiao等人(2022);Yin等人(2023)。一方面,提示设计要构建与LLMs预训练阶段更契合的输入输出对(例如代码生成)Guo等人(2023)。另一方面,优化提示以促进模型的深入理解和推理(例如思维链)Li等人(2023b),鼓励LLMs进行逻辑推断或生成可解释的内容。此外,还可以探索交互式提示设计(如多轮问答)Zhang等人(2023b),使LLMs能够自动迭代优化或对生成的抽取结果提供反馈。
6.4 开放IE
开放IE环境对IE模型来说更具挑战性,因为它们不预设任何候选标签集,完全依靠模型对任务的理解能力。凭借其丰富的知识和理解力,LLMs在某些开放IE任务上拥有明显优势Zhou等人(2023)。然而,在一些更具挑战性的任务上,LLMs的表现仍有待提高Qi等人(2023);Li等人(2023a),这需要研究者们继续深入探索。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









