






开发定制和精简版的模型是一个有前途的方向,这些精简的模型有望在边缘设备上更具可行性,能够在计算需求和功耗效率之间取得平衡。
原标题:DOLPHINS: MULTIMODAL LANGUAGE MODEL FOR DRIVING
论文链接:https://arxiv.org/pdf/2312.00438
代码链接:https://github.com/SaFoLab-WISC/Dolphins
项目地址:https://vlm-driver.github.io/
作者单位:威斯康星大学麦迪逊分校 NVIDIA 密歇根大学 斯坦福大学
01
论文思路
探索完全自动驾驶汽车(AVs),使其能够在复杂的现实世界场景中以人类般的理解力和反应力进行导航一直是一个重要的目标。本文提出了**Dolphins,这是一种新颖的视觉-语言模型,旨在作为对话式驾驶助手,具备类似人类的能力。**Dolphins能够处理包括视频(或图像)数据、文本指令和历史控制信号在内的多模态输入,并生成与所提供指令相对应的知情输出(informed outputs)。
基于开源的预训练视觉-语言模型OpenFlamingo,本文首先通过创新的Grounded Chain of Thought(GCoT)过程增强了Dolphins的推理能力。然后,本文通过构建特定于驾驶的指令数据并进行指令调优,将Dolphins定制化为驾驶领域的应用。通过利用BDD-X数据集,本文设计并整合了四种不同的自动驾驶任务到Dolphins中,以促进对复杂驾驶场景的整体理解。最终,Dolphins的独特特征体现在两个方面:(1)能够全面理解复杂且长尾的开放世界驾驶场景,并解决一系列自动驾驶任务;(2)展现出类似人类的能力,包括通过上下文学习进行无梯度的即时适应,以及通过反思进行错误恢复。
02
主要贡献
-
本文提出了一种基于视觉-语言模型(VLM)的对话式驾驶助手Dolphins,该助手能够像人类一样规划高级行为,补充自动驾驶系统(ADS)。
-
本文设计了一种 Grounded Chain of Thought(GCoT)过程,最初赋予Dolphins链式思维推理的能力。随后,本文使模型与自动驾驶任务对齐,尽管可用数据集的范围有限,这一方法不仅弥补了数据集的限制,还使Dolphins能够有效地分解复杂任务并学习其基础子任务。
-
本文通过定量指标和定性展示,证明了Dolphins在场景理解和推理、即时学习和适应、反思和错误恢复方面的显著能力。
03
论文设计
实现车辆系统完全自动化的探索是一场创新的考验,融合了人工智能[1]、机器人技术[2]和汽车工程[3]的见解。其核心目标是设计出能够在人类般理解和响应的复杂现实驾驶情境中进行操作的自动驾驶车辆(AVs)。
当前的自动驾驶系统(ADS)[4]是数据驱动并且通常是模块化的,将任务分为感知、预测、规划和控制[5]。然而,这些系统在不同情境下的集成和性能方面仍面临挑战。端到端(E2E)设计提供了直接从感官输入到控制输出的映射,但它们缺乏可解释性,给安全性和法规遵从带来了挑战[6, 7, 8]。
此外,与人类驾驶员相比,现有的自动驾驶系统(ADS)存在许多局限性,包括:
-
整体理解和解释: 现有的数据驱动自动驾驶系统(ADS)在整体理解和解释动态复杂场景方面往往表现不足,尤其是在开放世界驾驶环境中长尾分布的场景中[9, 10]。例如,在一个球弹到路上,随后一个孩子追着球跑的场景中,人类驾驶员可以立即推断出潜在的危险,并采取相应的行动来防止意外发生,这依赖于常识、过去的经验以及对人类行为的基本理解。相比之下,现有的ADS如果没有大量类似数据的先前暴露,可能难以准确地解释这种场景。这种缺乏整体理解能力限制了系统在数据分布长尾中意外场景中的泛化能力[11, 12]。
-
即时学习和适应: 与能够通过少量示例即时学习和适应新场景的人类驾驶员不同,现有的ADS需要大量数据的广泛训练才能处理新情况。例如,人类驾驶员可以在遇到一种新的道路障碍后迅速学会绕行,而ADS可能需要暴露于许多类似场景才能学到同样的教训。
-
反思和错误恢复: 现有的ADS通常在操作过程中采用前馈处理,缺乏基于反馈和指导进行实时纠正的能力。相比之下,人类驾驶员可以根据反馈实时纠正其驾驶行为。例如,如果人类驾驶员走错了路,他们可以迅速根据错误反馈调整决策,而ADS可能难以迅速从错误反馈中恢复[13, 14]。
这些局限性突显了需要一种中间框架来弥合当前自动驾驶系统(AVs)与人类驾驶之间的差距。最近在(多模态)大型语言模型(LLMs)[15, 16, 17]方面的进展,带来了应对这些挑战的希望。这些模型具备丰富的人类知识库,为显著改进自动驾驶系统提供了宝贵的见解。然而,这些模型主要在一般的视觉和语言数据上进行训练,这限制了它们在专门驾驶领域的有效性。此外,当前的模型设计只能处理静态图像和文本数据以生成零样本决策,缺乏处理时间性视频输入和上下文学习的能力。
本文提出了Dolphins(如图1所示),这是一种专门为自动驾驶车辆(AVs)定制的视觉语言模型(VLM),作为对话式驾驶助手,旨在缩小现有自动驾驶系统(ADS)与人类驾驶之间的差距。
基于OpenFlamingo [18],Dolphins通过一系列专门的指令数据集和有针对性的指令微调,适应了驾驶领域。本文首先基于一些公共视觉问答(VQA)数据集[19, 20, 21, 22]、视觉指令数据集[15, 23]和ChatGPT,构建了一个带有 grounded CoT 响应的图像指令跟随数据集,以将细粒度推理能力融入OpenFlamingo模型中。然后,本文利用BDD-X [24]建立了本文的指令数据集,重点关注四个关键的自动驾驶任务:行为理解、控制信号预测、行为分析和深入对话。
Dolphins展示了对复杂驾驶场景的高级理解和类似人类的能力,如即时学习、适应、反思和推理,这显著缩小了现有自动驾驶系统(ADS)与人类驾驶之间的差距。值得注意的是,Dolphins在感知、预测和规划等广泛任务中展现了广泛的适用性,这要归功于其对场景的全面理解。它能够解释静态和动态场景,整合环境因素,并有效地处理下游的预测和规划任务。
此外,Dolphins的上下文学习能力使其能够快速适应新的驾驶条件,相较于现有模型是一个显著的进步。其错误恢复机制提高了模型的准确性和可靠性,使其成为实际驾驶场景中的宝贵工具。更重要的是,Dolphins提供了可解释性,这是在自动驾驶系统(ADS)操作中建立信任和确保透明度的关键因素。
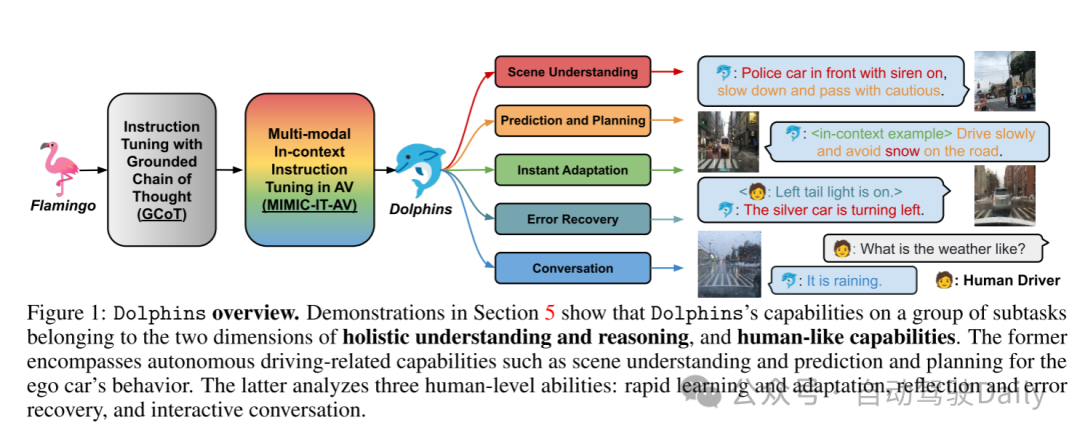
图1:Dolphins概述。第5部分的演示展示了Dolphins在属于整体理解与推理和类人能力这两个维度的一组子任务中的能力。前者包括与自动驾驶相关的能力,如场景理解以及对自车行为的预测和规划。后者则分析了三种人类级别的能力:快速学习与适应、反思与错误恢复以及互动对话。

图2:为增强视觉语言模型(VLMs)的细粒度推理能力而生成 GCoT 响应的过程。ChatGPT从文本输入开始,逐步生成GCoT。
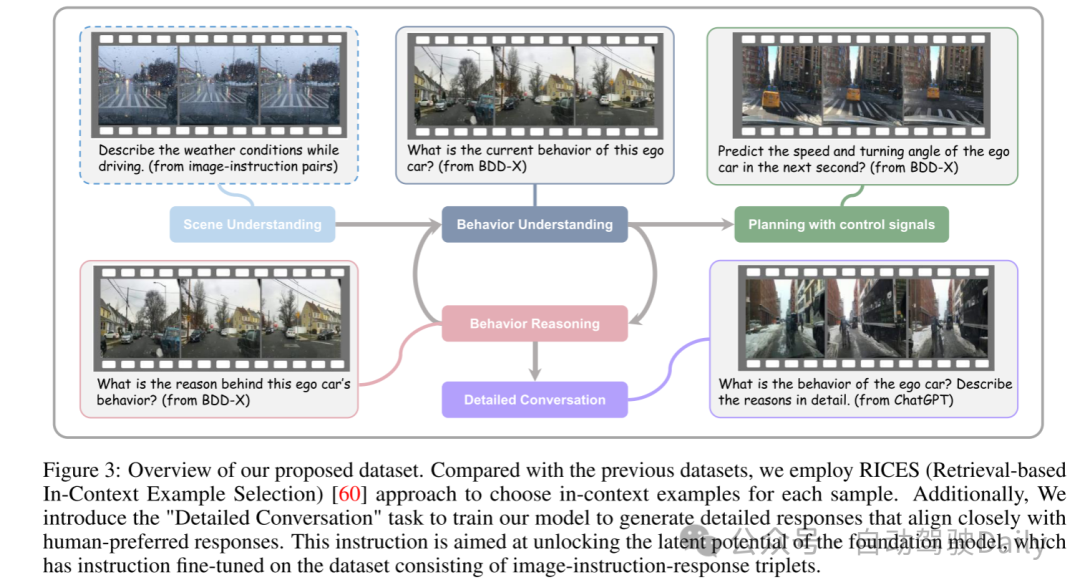
图3:本文提出的数据集概述。与之前的数据集相比,本文采用了RICES(基于检索的上下文示例选择)[60]方法为每个样本选择上下文示例。此外,本文引入了“详细对话”任务,以训练本文的模型生成与人类偏好高度一致的详细响应。此指令旨在释放基础模型的潜在能力,该模型已在由图像-指令-响应三元组组成的数据集上进行了指令微调。
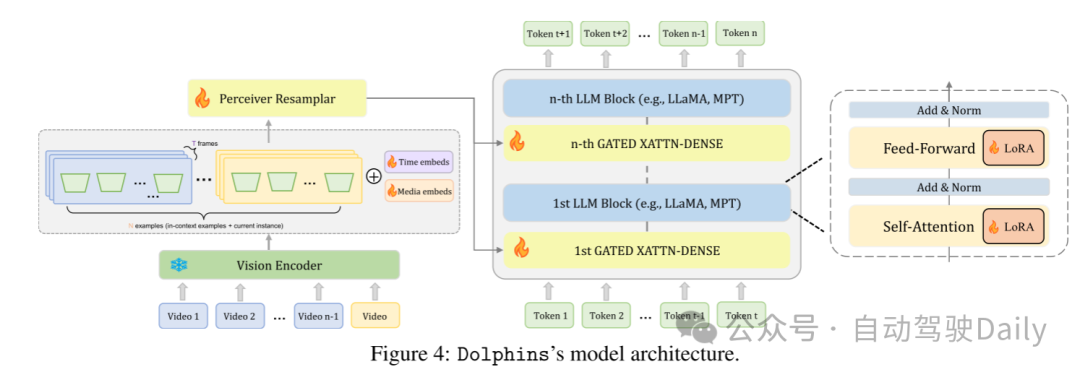
图4:Dolphins模型架构。

表1:和标记最初来自OpenFlamingo训练范式,本文遵循Otter的做法,加入了一个新标记,以更容易截取模型输出的目标答案。请注意,只有绿色序列/标记用于计算损失,本文使用交叉熵损失来训练本文的模型。
实验结果:
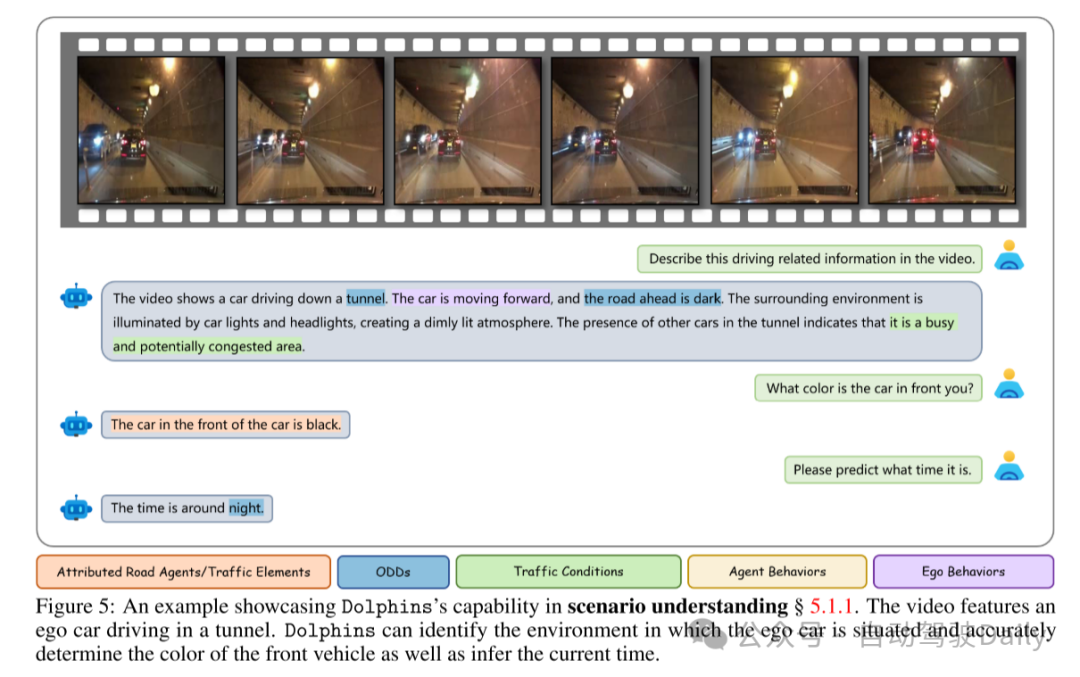
图5:展示Dolphins在场景理解方面能力的示例 § 5.1.1。视频中展示了一辆自车在隧道中行驶的场景。Dolphins能够识别自车所处的环境,并准确确定前方车辆的颜色以及推断当前时间。
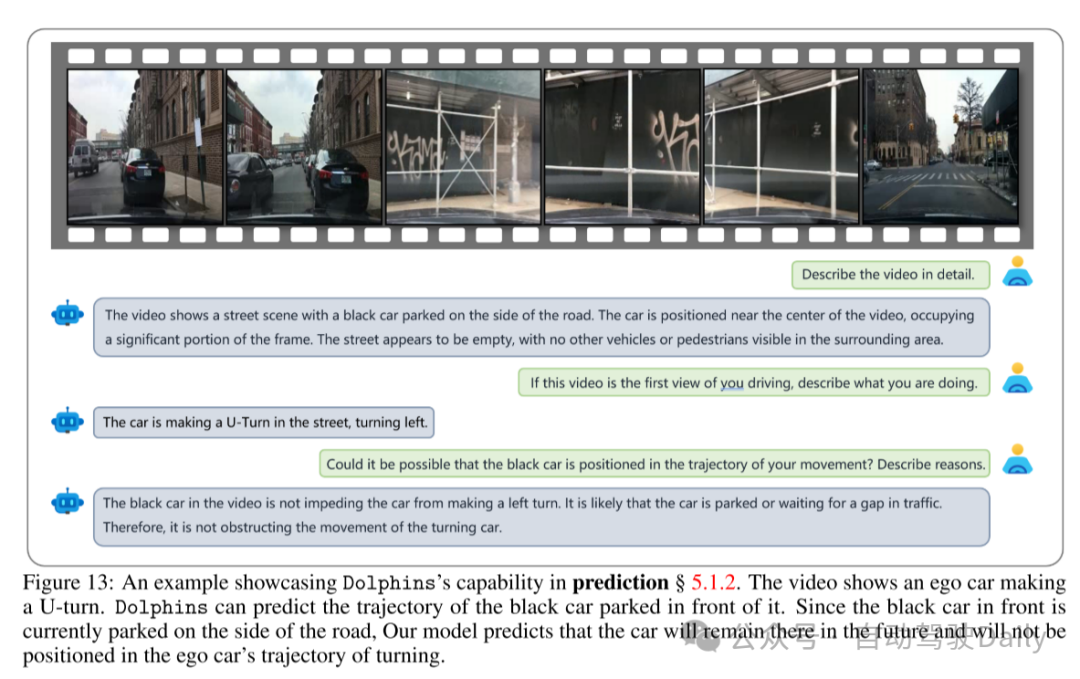 图13:展示Dolphins在预测能力方面的示例 § 5.1.2。视频中展示了一辆自车正在掉头。Dolphins能够预测前方停放的黑色车辆的轨迹。由于前方的黑色车辆目前停在路边,本文的模型预测该车辆将继续停在那里,不会出现在自车的掉头轨迹中。
图13:展示Dolphins在预测能力方面的示例 § 5.1.2。视频中展示了一辆自车正在掉头。Dolphins能够预测前方停放的黑色车辆的轨迹。由于前方的黑色车辆目前停在路边,本文的模型预测该车辆将继续停在那里,不会出现在自车的掉头轨迹中。

图14:展示Dolphins在规划能力方面的示例 § 5.1.2 及控制信号。Dolphins还能够理解控制信号,并利用这些信号预测自车下一秒的速度和转向角度。此外,本文可以启用Dolphins为自车制定规划,从而在驾驶过程中辅助驾驶员。然而,由于缺乏足够的信息,如地图、驾驶目的地等,该规划目前仍然仅限于短时间的未来。

图20:三个示例展示了本文的模型通过上下文学习实现对未见指令的快速适应 § 5.2.1。在前两个示例中,Dolphins通过上下文示例学习扮演驾驶员的角色,并能够准确描述其行为,尽管没有接受过此类指令的训练。第三个示例显示,Dolphins能够从上下文示例中学习常识,例如在隧道内无法根据光线判断当前时间。
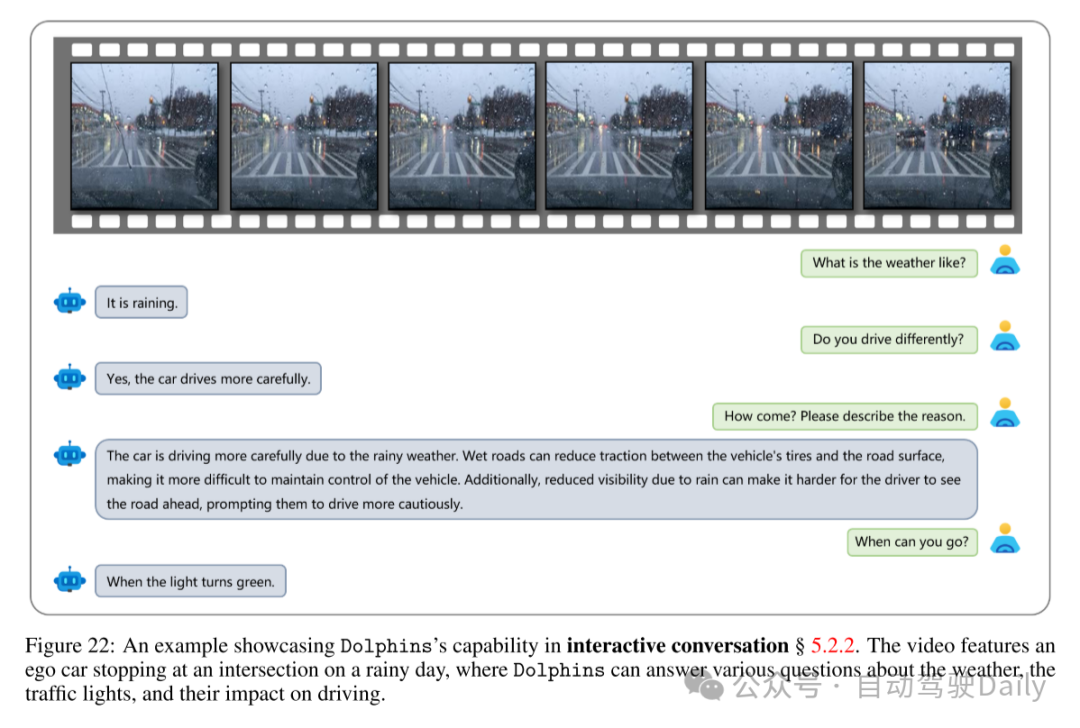
图22:展示Dolphins在交互对话能力方面的示例 § 5.2.2。视频中展示了一辆自车在雨天停在路口,Dolphins能够回答关于天气、交通信号灯及其对驾驶影响的各种问题。

图25:展示Dolphins在反思能力方面的示例 § 5.2.3。视频中展示了一辆自车在城市街道的路口行驶。前方的黑色车辆似乎想要右转,因为它的右尾灯在闪烁。最初,Dolphins预测黑色车辆会继续向前行驶。然而,在被告知“闪烁的尾灯表示转弯或变道”这一交通规则后,Dolphins进行了反思并修正了错误的预测。
04
总结
随着本文对Dolphins的探索接近尾声,这款旨在提升自动驾驶车辆(AVs)的新型视觉语言模型展示了其在复杂驾驶场景中进行整体理解和类人推理的显著能力,标志着自动驾驶技术领域的一大进步。通过利用多模态输入和创新的 Grounded Chain of Thought, GCoT 过程,Dolphins展现了其作为对话式驾驶助手的高超能力,能够以更高的解释能力和快速适应能力应对广泛的自动驾驶任务。尽管本文已经取得了显著进展,但未来仍面临诸多挑战。
然而,本文在将Dolphins完全优化用于实际自动驾驶车辆(AVs)应用的过程中遇到了显著挑战,特别是在计算开销和可行性方面。本文对Dolphins在DriveLM数据集上的表现进行了评估,这是一个针对现实驾驶场景的基准测试,结果显示其在NVIDIA A100上的平均推理时间为1.34秒,**这表明在边缘设备上实现高帧率可能存在限制。**此外,**在车辆中运行如此复杂的模型所需的功耗也构成了部署的重大障碍。**这些发现强调了在模型效率方面进一步改进的必要性。
展望未来,正如新兴研究[78]所建议的,开发定制和精简版的模型似乎是一个有前途的方向。**这些精简的模型有望在边缘设备上更具可行性,能够在计算需求和功耗效率之间取得平衡。**本文相信,在这一领域的持续探索和创新对于实现配备Dolphins等先进AI功能的自动驾驶车辆的全部潜力至关重要。
引用:
Ma Y, Cao Y, Sun J, et al. Dolphins: Multimodal language model for driving[J]. arXiv preprint arXiv:2312.00438, 2023.
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









