







备注、必看
文章背景:
之前没接触过搜索引擎,然后接手了一个es的项目,临时抱佛脚东拼西凑查资料把项目支持下去了,把过程中查的资料与自己的一些操作整理了一下发了出来
不适合科班入门学习,也不适合专家参考 ,
适合需要快速学习使用的人
Lucene
- ElasticSearch和Solr 都是封装了
Lucene; 实现全文搜索功能
ElasticSearch
- 提供RESTful API接口,只支持json
- 注重核心的搜索功能,在处理大数据时性能更好
Solr
- 提供类似 webservice的API接口,支持json,xml,csv
- 有很多额外的功能,适合传统搜索
ElasticSearch
官网
https://www.elastic.co/cn/elasticsearch/
-
8.9
https://www.elastic.co/guide/cn/elasticsearch/reference/8.9/getting-started.html -
7.17
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/getting-started.html -
2.x (中文)
https://www.elastic.co/guide/cn/elasticsearch/guide/current/getting-started.html -
其他中文学习网站
https://www.knowledgedict.com/tutorial/elasticsearch-intro.html
版本变化
-
es5
支持多种type -
es6
规定每一个index只能有一个type
index 都将只有一个虚拟的固定的 type: _doc来代替 -
es7(建议使用)
去除了Type,包括API层面
废除 _all 字段的支持,为提升性能默认不在支持全文检索
默认分片数为1,不再是5 -
es8
Java 17 才能运行 Elasticsearch
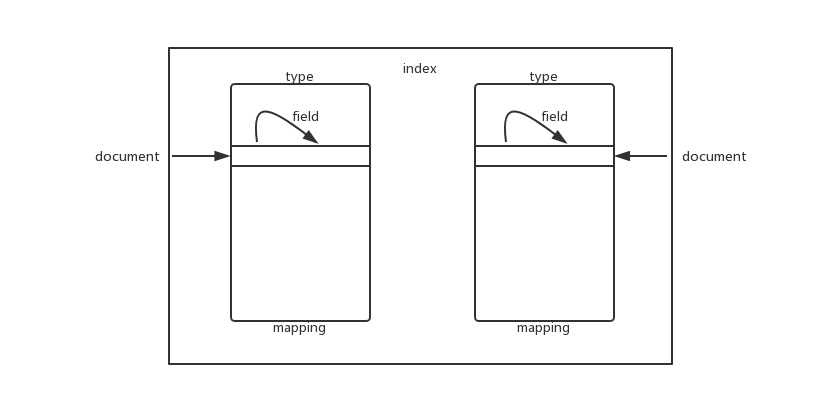
基本概念
早期ElasticSearch版本与 关系型数据库对比
- 网上常见的一张图,单实际很难完全对应上。理解即可

向Elasticsearch中存储数据,其实就是向es中的index下面的type中存储json类型的数据。
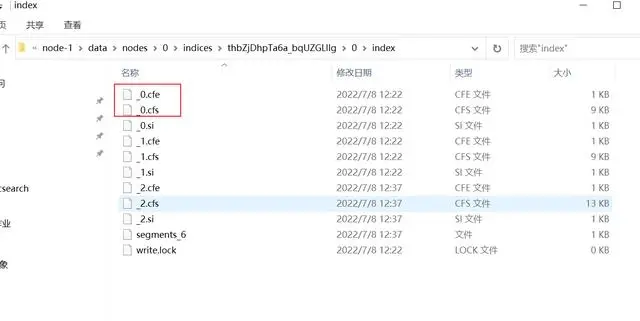
cfe为索引文,cfs 为数据文件,cfe文件保存Lucene各文件在.cfs文件的位置信息
cfs、cfe 在segment还很小的时候,将segment的所有文件都存在在cfs中,在cfs逐渐变大时,大小超过shard的10%,则会拆分为其他文件,如tim、dvd、fdt等文件
Index -索引
- Elastic 数据管理的顶层单位就叫做 Index(索引), 含义类似单个数据库 or 表
- Index 的名字必须是小写。
Index内容
- aliases
- mappings 映射,定义type
- settings
{
"users" : {
"aliases" : { 别名 },
"mappings" : {
type-name : {
"properties" : {
"age" : {
"type" : "integer"
},
"name" : {
"type" : "keyword"
}
}
}
},
"settings" : { 索引设置 }
}
}
Mapping 映射 (index结构信息)【重要】
定义index的结构信息
包括:每个字段的 类型、是否分词、是否可查询
- 具体属性有:
type
store
norms
index_options
term_vector
similarity
copy_to
analyzer
search_analyzer
fielddata
type 数据类型
- 字符串类型
- string
text:
全文搜索字段,会被分词器分成一个一个词项(term)keyword:
结构化的字段,只能通过精确值搜索。通常用于过滤、排序、聚合
比如 email 地址、主机名、状态码和标签
- 数字类型 long、integer、short、byte、double、float、half_float、scaled_float
- 日期类型 date
- 布尔类型 boolean
- 二进制类型 binary
- 范围类型
range:时间选择表单、年龄范围选择表单等 - 数组类型
array:数组中的值必须是同一种类型 - 对象类型 object
- 嵌套类型 nested
- 地理坐标类型 geo_point
- 地理图形类型 geo_shape
- 特殊类型: IP 类型、范围类型、令牌计数类型、附件类型和抽取类型。
静态映射
dynamic field mapping 动态字段映射
当 Elasticsearch 自动检测到文档中的新字段时,默认情况下它会动态地将该字段添加到类型映射中。参数 dynamic 控制此行为。
settings 设置
- 固定属性
版本号
uuid 信息 - 静态配置
创建时间戳
主分片数
数据存储的压缩算法
路由分区数
分析器
分词器 - 动态配置
主分片的副本数(1)
索引数据的刷新操作频率(1s)
【重要】索引原理:Inverted Index(倒排索引)
- Elastic 会索引所有字段,经过处理后写入一个Inverted Index
- 通过文档内容去管理主键ID
- 可以过滤无关数据,提高效率,适用于快速全文搜索
索引:通过有序的key去找value
正排索引:key=文档id,value=内容
倒排索引:key=内容(关键词),value=文档id

Type(逐渐弃用)
用来定义数据结构
- 例:该type 有age和name两个字段,age字段是integer类型,name是keyword类型
type-name : {
"properties" : {
"age" : {
"type" : "integer"
},
"name" : {
"type" : "keyword"
}
}
}
- 用法:
- 一个索引 里 有多种type,就可以存储多种类型的数据【废弃】
- 多个索引里有同一种 type,可以只根据type全部查询出来【type类似成了 数据库的概念】
Document -文档
- Index 里面单条的记录称为 Document(文档)
- 使用 JSON 格式表示
- 搜索数据的最小单元
文档结构
{
"_index": 所属索引,
"_type": 所属type,
"_id": 唯一id,
"_version": 版本,
"_score": 相关度评分,
"_source": {
"name": "张三",
"age": "18"
}
}
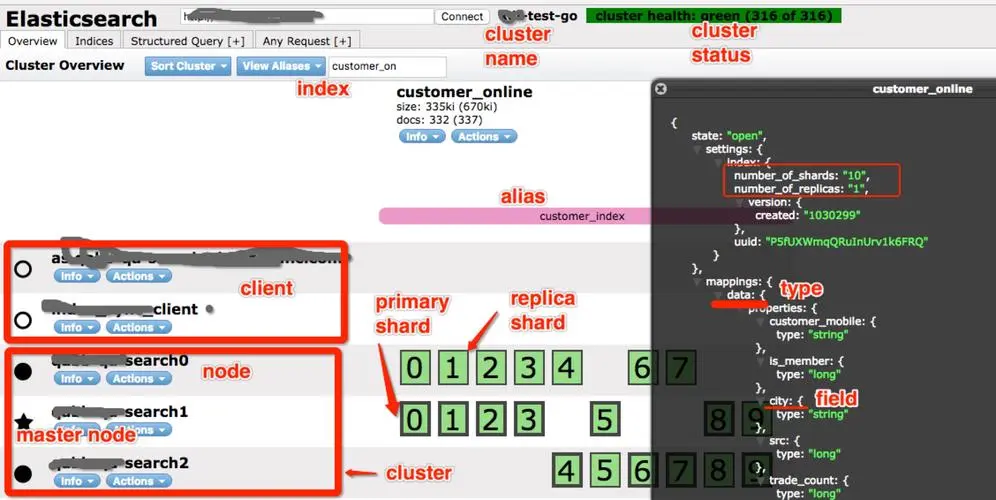
集群
Cluster(集群) 与 Node(节点)
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
单个 Elastic 实例称为一个节点(node)。
一组节点构成一个集群(cluster)。
- 主节点
集群中一个节点会被选举为主节点(master),
它将临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等 - 数据节点
- 客户端节点
用户,我们能够与集群中的任何节点通信,包括主节点。每一个节点都知道文档存在于哪个节点上,它们可以转发请求到相应的节点上
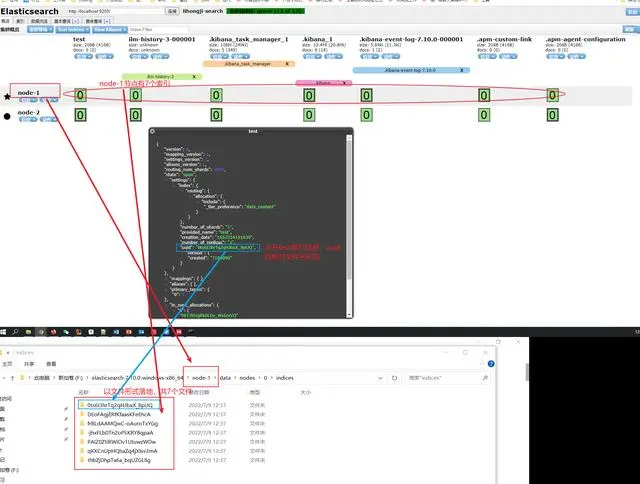
index分片、副本
单个节点由于物理机硬件限制 大小是有限的。一个索引如果特别大 导致在单个节点放不下。
索引分成多个分片,分片可以存储在集群中不同节点
- 主分片
分片并非将所有的数据都放在一起,多个主分片合起来才是所有的数据
以默认的5个主分片为例,ES会将数据均衡的存储到5个分片上,
也就是这5个分片的数据并集才是整个数据集,
这5个分片会按照一定规则分配到不同的ES Node上。这样的5个分片叫主分片。
- 复制分片 (replica shard)
从分片只是主分片的一个副本,它用于提供数据的冗余副本
默认设置是一个主分片会有一个从分片,那么就有5个从分片,那么默认配置会产生10个分片(5主5从)就散布在所有的Node上
当主分片丢失时,集群将副本提升为新的主分片。
节点用法:冷热数据分离
https://blog.csdn.net/laoyang360/article/details/102539888
插件:IK中文分词器
https://github.com/medcl/elasticsearch-analysis-ik
-
作用:把一段中文,按照分词器字典,拆分成一个个关键词
-
使用方法:
下载解压ik,放在es的plugins目录下,启动es会自动加载ik插件
分词器字典
默认字典:ik/config/*.dic
可以在 ik/config/IKAnalyzer.cfg.xml 文件 配置扩展字典
分词算法
- ik_smart 最少切分
- ik_max_word 最细粒度划分
curl -X PUT 'localhost:9200/accounts' -d '
{
"mappings": {
"person": {
"properties": {
"desc": {
"type": "张三是谁啊",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
}'
- analyzer:字段文本的分词器
- search_analyzer:搜索词的分词器
ES 增删改查
【重要】查询
搜索详见 :
https://blog.csdn.net/xyc1211/article/details/120349794
查询是一个比较复杂的执行模式,因为我们不知道那些 document 会被匹配到,任何一个 shard 上都有可能,所以一个 search 请求必须查询一个索引或多个索引里面的所有 shard 才能完整的查询到我们想要的结果。
- query :找到所有匹配的结果
- fetch:来自多个 shard 上的数据集在分页返回到客户端之前会被合并到一个排序后的 list 列表,由于需要经过一步取 top N 的操作
客户端工具
1. 可视化工具 ElasticSearch-head
https://github.com/mikewuhao/es-head
-
安装
- 可以独立安装使用(需要前端npm环境)
- 也可以通过浏览器插件使用
-
使用
- 连接es集群,可以 查看集群中的索引,索引中的类型,类型中的字段


- 查看文档

- 查询搜索

- 连接es集群,可以 查看集群中的索引,索引中的类型,类型中的字段
2. 数据分析展示 Kibana
java 客户端
https://www.elastic.co/guide/en/elasticsearch/client/index.html
Elasticsearch(ES)有多种client:【吐槽,学一个弃用一个,真的是够了】
- Java Transport Client (警告:在 7.0.0 中弃用)
- Java REST Client (警告:在 7.15.0 中已弃用)
- Java API Client
es官网也提供了ES Java RestClient的方式来访问es
<!-- es -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.5.3</version>
</dependency>
<!-- es 客户端 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>rest</artifactId>
<version>5.5.3</version>
</dependency>
都是线程安全的,都应该使用单例。
Java Transport Client(7.0以下)
- 通过TCP方式访问ES
- 该transport node并不会加入集群,而是简单的向ElasticSearch集群上的节点发送请求。
- 只支持java
- Elasticsearch计划在Elasticsearch 7.0中弃用TransportClient,在8.0中完全删除
import java.net.InetAddress;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
public class TestEsClient {
public static void main(String[] args) {
try {
//设置集群名称
Settings settings = Settings.builder()
.put("cluster.name", "elasticsearch")
.build();
//创建client
TransportClient client = new PreBuiltTransportClient(settings);
TransportAddress transportAddress = new TransportAddress(InetAddress.getByName("127.0.0.1"), Integer.valueOf(9300));
client.addTransportAddress(transportAddress);
//Get查询: 根据 (索引名称、类型、id)获取文档
GetResponse response = client.prepareGet("INDEX", "TYPE", "id").execute().actionGet();
//输出结果
System.out.println(response.getSourceAsString());
//关闭client
client.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 组合查询
转载至 https://blog.csdn.net/fanrenxiang/article/details/86509688
//复合查询-Bool查询
public void boolDsl() {
//Bool Query
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//电影名称必须包含我不是药神经过分词后的文本,比如我、不、是、药、神
boolQueryBuilder.must(QueryBuilders.matchQuery(MovieSearch.NAME, "我不是药神"));
//排除导演是张三的电影信息
boolQueryBuilder.mustNot(QueryBuilders.termQuery(MovieSearch.DIRECTORS, "张三"));
//别名中应该包含药神经过分词后的文本,比如药、神
boolQueryBuilder.should(QueryBuilders.matchQuery(MovieSearch.ALIAS, "药神"));
//评分必须大于9(因为es对filter会有智能缓存,推荐使用)
boolQueryBuilder.filter(QueryBuilders.rangeQuery(MovieSearch.SCORE).gt(9));
//name、actors、introduction、alias、label 多字段匹配"药神",或的关系
boolQueryBuilder.filter(QueryBuilders.multiMatchQuery("药神", MovieSearch.NAME, MovieSearch.ACTORS, MovieSearch.INTRODUCTION, MovieSearch.ALIAS, MovieSearch.LABEL));
String[] includes = {MovieSearch.NAME, MovieSearch.ALIAS, MovieSearch.SCORE, MovieSearch.ACTORS, MovieSearch.DIRECTORS, MovieSearch.INTRODUCTION};
SearchRequestBuilder searchRequestBuilder = transportClient
.prepareSearch(INDEX)
.setTypes(TYPE)
.setQuery(boolQueryBuilder)
.addSort(MovieSearch.SCORE, SortOrder.DESC)
.setFrom(0)
.setSize(10)
.setFetchSource(includes, null);
SearchResponse searchResponse = searchRequestBuilder.get();
if (!RestStatus.OK.equals(searchResponse.status())) {
return;
}
for (SearchHit searchHit : searchResponse.getHits()) {
String name = (String) searchHit.getSource().get(MovieSearch.NAME);
//TODO
}
}
Java REST Client
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.14/java-rest-high-search.html
- 通过http API 访问ES
- 没有语言限制。
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.17.8</version>
</dependency>
ES提供了两个JAVA REST client 版本
Java Low Level REST Client:
低级别的REST客户端,通过http与集群交互,用户需自己编组请求JSON串,及解析响应JSON串。兼容所有ES版本。
灵活、但手动编写
Java High Level REST Client: RestHighLevelClient
高级别的REST客户端,基于低级别的REST客户端,增加了编组请求JSON串、解析响应JSON串等相关api。使用的版本需要保持和ES服务端的版本一致,否则会有版本问题。
例
官方推荐使用高级版,低级版需要自己准确记住api。
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
//初始化RestClient实例
static RestClient restClient = RestClient.builder(
new HttpHost("192.168.10.5", 9200, "http"),
new HttpHost("192.168.10.6", 9200, "http"),
new HttpHost("192.168.10.7", 9200, "http")).build()
//同步调用 Rest Api方法
public Response performRequest(String method, String endpoint, Header... headers) throws IOException
public Response performRequest(String method, String endpoint, Map<String, String> params, Header... headers) throws IOException
public Response performRequest(String method, String endpoint, Map<String, String> params,
HttpEntity entity, Header... headers) throws IOException
// (1) 执行一个基本的方法,验证es集群是否搭建成功
Response response = restClient.performRequest(
"GET",
"/",
Collections.singletonMap("pretty", "true")
);
System.out.println(EntityUtils.toString(response.getEntity()));
//输出结果:
{
"name" : "nd2",
"cluster_name" : "search",
"version" : {
"number" : "2.3.4",
"build_hash" : "e455fd0c13dceca8dbbdbb1665d068ae55dabe3f",
"build_timestamp" : "2016-06-30T11:24:31Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
// (2)验证es的某个索引是否存在
Response response = restClient.performRequest(
"HEAD",
"/product/pdt",
Collections.<String, String>emptyMap()
);
System.out.println(response.getStatusLine().getReasonPhrase().equals("OK"));
//输出结果:
true
// (3) 删除某个索引的指定条件的数据
Map<String, String> paramMap = new HashMap<String, String>();
paramMap.put("q", "id:"+id);
paramMap.put("pretty", "true");
Response response = restClient.performRequest(
"DELETE",
"product/pdt/_query",
paramMap
);
System.out.println(EntityUtils.toString(response.getEntity()));
//输出结果:
{
"took" : 0,
"timed_out" : false,
"_indices" : {
"_all" : {
"found" : 1,
"deleted" : 0,
"missing" : 0,
"failed" : 0
}
},
"failures" : [ ]
}
// 用SearchSourceBuilder来构造 查询条件
String endPoint = "/index/_search?ignore_unavailable=true"
SearchSourceBuilder requestSourceBuilder = new SearchSourceBuilder();
requestSourceBuilder.from(from);
requestSourceBuilder.size(size);
HttpEntity entity = new NStringEntity(requestSourceBuilder.toString(), ContentType.APPLICATION_JSON);
HttpAsyncResponseConsumerFactory.HeapBufferedResponseConsumerFactory consumerFactory = new HttpAsyncResponseConsumerFactory.HeapBufferedResponseConsumerFactory(BUFFER_SIZE);
Response response = restClient.performRequest(
"GET",
endPoint,
Collections.<String, String>emptyMap(),
entity,
consumerFactory
);
Java API Client
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.6.1</version>
</dependency>
















 9138
9138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











