







分割一切模型 (SAM) 根据输入提示(如点或框)生成高质量的对象mask,并可用于为图像中的所有对象生成mask。它已经在 1100 万张图像和 11 亿个掩码的数据集上进行了训练,在各种分割任务上具有强大的零样本性能。官方文档:facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model. (github.com)
Installation
代码能够运行需要:python>=3.8, as well as pytorch>=1.7 and torchvision>=0.8
1.(可以先创建一个虚拟环境如sam)下载sam:
(建议直接下载,解压到当前文件夹,并把解压出的文件夹名字改成segment-anything)
pip install git+https://github.com/facebookresearch/segment-anything.git 
2.安装:
git clone git@github.com:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .下载zip文件的解压后
cd segment-anything#激活虚拟环境进入文件夹
pip install -e .
如何安装其他依赖:torch等
pip install opencv-python pycocotools matplotlib onnxruntime onnx
3.下载权重模型
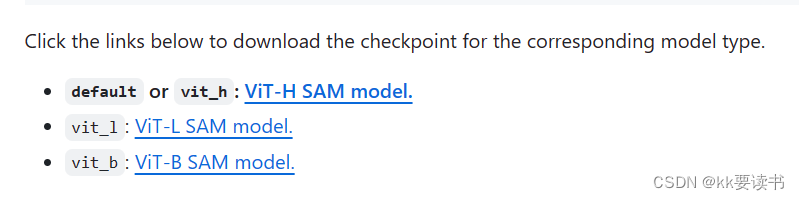
比如vit-h
https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
建议直接下载进入segment-anything文件里面
各个模块介绍
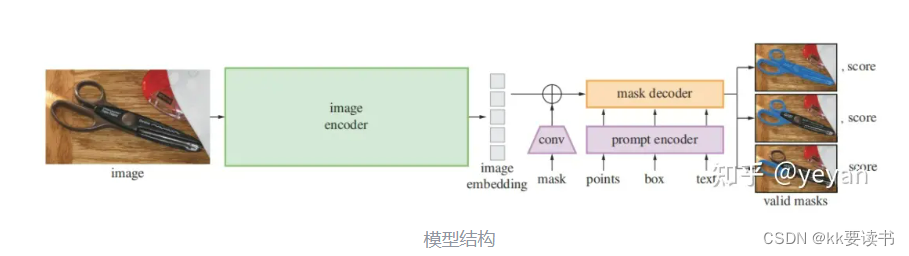
Sam
1.图像编码器(image_encoder):使用ViT模型对图像进行编码,提取图像的特征。
2.提示编码器(prompt_encoder):将图像中的区域位置编码成向量,并与提示文本进行拼接,形成提示编码器的输入。
3.掩膜解码器(mask_decoder):将提示编码器的输出作为输入,生成掩膜,用于对图像进行分割。
在函数的参数中,encoder_embed_dim、encoder_depth、encoder_num_heads、encoder_global_attn_indexes等是图像编码器使用的参数,用于控制ViT模型的参数;
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
from torch import nn
from torch.nn import functional as F
from typing import Any, Dict, List, Tuple
from .image_encoder import ImageEncoderViT
from .mask_decoder import MaskDecoder
from .prompt_encoder import PromptEncoder
class Sam(nn.Module):
mask_threshold: float = 0.0
image_format: str = "RGB"
def __init__(
self,
image_encoder: ImageEncoderViT,
prompt_encoder: PromptEncoder,
mask_decoder: MaskDecoder,
pixel_mean: List[float] = [123.675, 116.28, 103.53],
pixel_std: List[float] = [58.395, 57.12, 57.375],
) -> None:
"""
SAM predicts object masks from an image and input prompts.
Arguments:
image_encoder (ImageEncoderViT): The backbone used to encode the
image into image embeddings that allow for efficient mask prediction.
prompt_encoder (PromptEncoder): Encodes various types of input prompts.
mask_decoder (MaskDecoder): Predicts masks from the image embeddings
and encoded prompts.
pixel_mean (list(float)): Mean values for normalizing pixels in the input image.
pixel_std (list(float)): Std values for normalizing pixels in the input image.
"""
super().__init__()
self.image_encoder = image_encoder
self.prompt_encoder = prompt_encoder
self.mask_decoder = mask_decoder
self.register_buffer("pixel_mean", torch.Tensor(pixel_mean).view(-1, 1, 1), False)
self.register_buffer("pixel_std", torch.Tensor(pixel_std).view(-1, 1, 1), False)
@property
def device(self) -> Any:
return self.pixel_mean.device
# Sam的forword要求输入的是list对象,其对图像编码时是进行batch操作(一次性推理出所有图像的特征)
# 而对提示输入和mask生成则是单独操作(通过for循环预测每一个位置提示所对应的mask);其输出也是list对象
# 每个元素包含masks、iou_predictions和low_res_logits值
# 其中,masks是low_res_logits的高分辨率结果,并按照mask_threshold进行二值化(也就是说模型只时预测出低分辨率的low_res_logits)
@torch.no_grad()
def forward(
self,
batched_input: List[Dict[str, Any]],
multimask_output: bool,
) -> List[Dict[str, torch.Tensor]]:
"""
Predicts masks end-to-end from provided images and prompts.
If prompts are not known in advance, using SamPredictor is
recommended over calling the model directly.
Arguments:
batched_input (list(dict)): A list over input images, each a
dictionary with the following keys. A prompt key can be
excluded if it is not present.
'image': The image as a torch tensor in 3xHxW format,
already transformed for input to the model.
'original_size': (tuple(int, int)) The original size of
the image before transformation, as (H, W).
'point_coords': (torch.Tensor) Batched point prompts for
this image, with shape BxNx2. Already transformed to the
input frame of the model.
'point_labels': (torch.Tensor) Batched labels for point prompts,
with shape BxN.
'boxes': (torch.Tensor) Batched box inputs, with shape Bx4.
Already transformed to the input frame of the model.
'mask_inputs': (torch.Tensor) Batched mask inputs to the model,
in the form Bx1xHxW.
multimask_output (bool): Whether the model should predict multiple
disambiguating masks, or return a single mask.
Returns:
(list(dict)): A list over input images, where each element is
as dictionary with the following keys.
'masks': (torch.Tensor) Batched binary mask predictions,
with shape BxCxHxW, where B is the number of input prompts,
C is determined by multimask_output, and (H, W) is the
original size of the image.
'iou_predictions': (torch.Tensor) The model's predictions
of mask quality, in shape BxC.
'low_res_logits': (torch.Tensor) Low resolution logits with
shape BxCxHxW, where H=W=256. Can be passed as mask input
to subsequent iterations of prediction.
"""
input_images = torch.stack([self.preprocess(x["image"]) for x in batched_input], dim=0)
image_embeddings = self.image_encoder(input_images)
outputs = []
for image_record, curr_embedding in zip(batched_input, image_embeddings):
if "point_coords" in image_record:
points = (image_record["point_coords"], image_record["point_labels"])
else:
points = None
sparse_embeddings, dense_embeddings = self.prompt_encoder(
points=points,
boxes=image_record.get("boxes", None),
masks=image_record.get("mask_inputs", None),
)
low_res_masks, iou_predictions = self.mask_decoder(
image_embeddings=curr_embedding.unsqueeze(0),
image_pe=self.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
masks = self.postprocess_masks(
low_res_masks,
input_size=image_record["image"].shape[-2:],
original_size=image_record["original_size"],
)
masks = masks > self.mask_threshold
outputs.append(
{
"masks": masks,
"iou_predictions": iou_predictions,
"low_res_logits": low_res_masks,
}
)
return outputs
def postprocess_masks(
self,
masks: torch.Tensor,
input_size: Tuple[int, ...],
original_size: Tuple[int, ...],
) -> torch.Tensor:
"""
Remove padding and upscale masks to the original image size.
Arguments:
masks (torch.Tensor): Batched masks from the mask_decoder,
in BxCxHxW format.
input_size (tuple(int, int)): The size of the image input to the
model, in (H, W) format. Used to remove padding.
original_size (tuple(int, int)): The original size of the image
before resizing for input to the model, in (H, W) format.
Returns:
(torch.Tensor): Batched masks in BxCxHxW format, where (H, W)
is given by original_size.
"""
masks = F.interpolate(
masks,
(self.image_encoder.img_size, self.image_encoder.img_size),
mode="bilinear",
align_corners=False,
)
masks = masks[..., : input_size[0], : input_size[1]]
masks = F.interpolate(masks, original_size, mode="bilinear", align_corners=False)
return masks
def preprocess(self, x: torch.Tensor) -> torch.Tensor:
"""Normalize pixel values and pad to a square input."""
# Normalize colors
x = (x - self.pixel_mean) / self.pixel_std
# Pad
h, w = x.shape[-2:]
padh = self.image_encoder.img_size - h
padw = self.image_encoder.img_size - w
x = F.pad(x, (0, padw, 0, padh))
return x
image_encoder模块
利用mae预训练的vit,最低限度适应高分辨率的输入,该encoder在prompt encoder之前,对每张图像只运行一次。 输入(c,h,w)的图像,对图像进行缩放,按照长边缩放成1024,短边不够就pad,得(c,1024,1024)的图像,经过image encoder,得到对图像16倍下采样的feature,大小为(256,64,64)。
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Optional, Tuple, Type
from .common import LayerNorm2d, MLPBlock
# 其先由patch_embed对输入数据进行16倍的下采样(将patch_size设为16)
# 并将embed_dim[token长度]设为768(原始的vit中embed_dim是为196=img_wimg_h/(patch_wpatch_h),img_w:224 patch_w:16)
# 这与原始ViT相比,是存在一定信息缺失的(64x64=4096)
#ImageEncoderViT还多了一个neck层,用于将embed_dim从768转换到所需的out_chans(256)
# This c 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









