






带提示的修剪:一个有效的模型加速框架
ABSTRACT
在本文中,我们提出了一个有效的框架来加速卷积神经网络。我们使用两种类型的加速方法:修剪和提示。修剪可以通过移除层的通道来减小模型大小。提示可以通过从教师模式转移知识来提高学生模式的绩效。
我们证明了修剪和提示是相辅相成的。一方面,提示可以通过维护相似的特征表示来有益于修剪。另一方面,从教师网络中修剪出的模型是学生模型的良好初始化,增加了两个网络之间的可转移性。我们的方法迭代执行修剪阶段和提示阶段,以进一步提高性能。此外,我们还提出了一种算法来重建提示层的参数,使修剪后的模型更适合提示。在分类和姿态估计等任务上进行了实验。在CIFAR-10、ImageNet和COCO上的实验结果证明了该框架的通用性和优越性。
一、INTRODUCTION
近年来,卷积神经网络(CNN)在许多计算机视觉任务中得到了应用,例如分类Krizhevsky & Hinton (2009);Deng et al . (2016), Everingham et al . (2010);Ren et al .(2015)和姿态估计Lin et al .(2014)。CNN的成功推动了计算机视觉的发展。然而,受模型规模大和计算复杂度的限制,许多CNN模型难以直接投入实际应用。为了解决这个问题,越来越多的研究集中在不降低性能的加速模型上。
剪枝和知识精馏是模型加速的两种主流方法。修剪的目标是去除不太重要的参数,同时保持原始模型的相似性能。尽管剪枝方法具有优势,但我们注意到,对于许多剪枝方法,随着剪枝通道数的增加,剪枝模型的性能迅速下降。知识蒸馏描述师生框架:利用教师模型的高层表示来监督学生模型。Romero等人(2015)分享了类似的知识蒸馏思想,其中使用教师模型的特征图作为高级表示。Yosinski et al .(2014)认为,如果学生网络的初始化能产生与教师模型相似的特征,那么学生网络在知识转移方面的表现会更好。受此工作的启发,我们提出了修剪后的模型输出与原始模型相似的特征,并为学生模型提供了良好的初始化,这有助于蒸馏。另一方面,提示可以帮助重建参数,减轻剪枝操作带来的性能下降。图1说明了我们框架的动机。在此基础上,提出了一种算法:迭代地进行剪枝和提示操作。对于每次迭代,我们在剪枝和提示操作之间执行一个重建步骤。我们证明了这种重构操作可以为学生模型提供更好的初始化,并促进提示步骤(见图2)。我们将我们的方法命名为PWH Framework。据我们所知,我们是第一个将修剪和提示结合在一起作为一个框架的人。
我们的框架可以应用于不同的视觉任务。在CIFAR-10 Krizhevsky & Hinton(2009)、ImageNet Deng等(2016)和COCO Lin等(2014)数据集上的实验表明我们框架的有效性。此外,我们的方法是一个框架,其中可以包含不同的修剪和提示方法。

图1:PWH架构的动机。剪枝和提示是相辅相成的。
提示可以帮助剪枝模型重建参数。从教师模型中修剪出来的网络可以为提示学习中的学生模型提供良好的初始化。
综上所述,本文的贡献如下:(1)分析了剪枝方法和提示方法的性质,证明了这两种模型加速方法具有互补性。据我们所知,这是第一次把剪枝和提示结合起来。我们的框架很容易扩展到不同的修剪和提示方法。(3)充分的实验证明了我们的框架在不同数据集上针对不同任务的有效性。
二、RELATED WORK
近年来,模型加速受到了广泛的关注。量化方法Rastegari et al . (2016);Courbariaux et al (2016;2015);Juefei-Xu等(2017);Zhou等(2017)通过将浮动参数量化为定点参数来减小模型尺寸。定点网络通过特殊的实现可以加快速度。基于群卷积的方法Howard等人(2017);Chollet(2017)将卷积运算分成若干组,可以降低计算复杂度。一些作品利用参数的线性结构和使用低秩方法接近参数来减少计算参数Denton等(2014);Jaderberg et al (2014);Alvarez & Petersson (2016);Zhang et al(2016)。在我们的实验中,我们使用了目前主流的两种模型加速方法:剪枝和知识蒸馏。
2.1PRUNING
网络剪枝很早以前就提出了,如Hanson & Pratt (1989);哈西比等人(1993);LeCun et al .(1990)。
近期的修剪方法大致可分为两个层次:
channel-wise:Molchanov等人(2017);He et al (2017);萨吉德·安瓦尔(2015);Hu等人(2017)
和参数化的Han等人(2016);2015);Yang等(2017);Li et al . (2017a);Wen et al (2015);Luo等(2017)。
在本文中,我们使用channel-wise方法作为我们的修剪方法。
在channel-wise家庭中有许多方法。He et al(2017)使用LASSO回归方法从样本特征图中修剪通道。Liu等人(2017)提出,使用批处理归一化层中的尺度参数来评估不同通道的重要性。Molchanov et al(2017)利用泰勒公式分析各渠道对损失的贡献,并修剪贡献最低的渠道。我们在框架中使用了这种方法。
尽管剪枝方法有其优越性,但我们发现,它们的有效性会随着修剪通道数的增加而明显降低。
2.2DISTILLATION
Hinton等开创了知识蒸馏这一领域。Hinton(2015)定义了软目标并且使用它去监督学生网络。除了软目标之外,hints在2015年由Fitnets Romero e等人引入。hints这可以解释为全特征图模拟学习。有许多研究报告是关于hints的,Zagoruyko和Komodakis(2017)建议使用学生网络模拟大型网络集合的组合输出。此外,Li等人(2017b)展示了一种基于兴趣区域的模拟学习策略,以提高小型网络的目标检测性能。
然而,这些工作大多是从头开始训练学生模型,而忽略了学生网络初始化的意义。
三、OUR APPROACH
在本节中,我们将详细描述我们的方法。首先,我们展示了在我们的框架中使用的提示和修剪方法。然后介绍了重构操作,并对其有效性进行了分析。最后,结合提示、剪枝和重构操作,提出PWH框架。
3.1PRUNING STEP(剪枝步骤)
我们在本文中使用的修剪方法基于Molchanov等人(2017)。该算法可以描述为一个组合优化问题:



在反向传播过程中,我们可以得到梯度δC/δhi和激活hi。因此,这个标准可以很容易地实现信道修剪。

3.2HINTS STEP
提示可以为学生网络提供额外的监督,通常与任务丢失相结合。
提示学习的整个损失函数表示为:
![]()
其中,Lt为任务损失(如分类损失),Lh为提示损失。λ是提示损失权值,它决定了提示监督的强度。提示方法有很多种类型。不同的提示方法适用于不同的任务和网络架构。为了证明该框架的优越性和通用性,我们在实验中尝试了三种提示方法:L2提示、归一化提示和自适应提示。我们在附录中介绍L2提示,规范化提示。
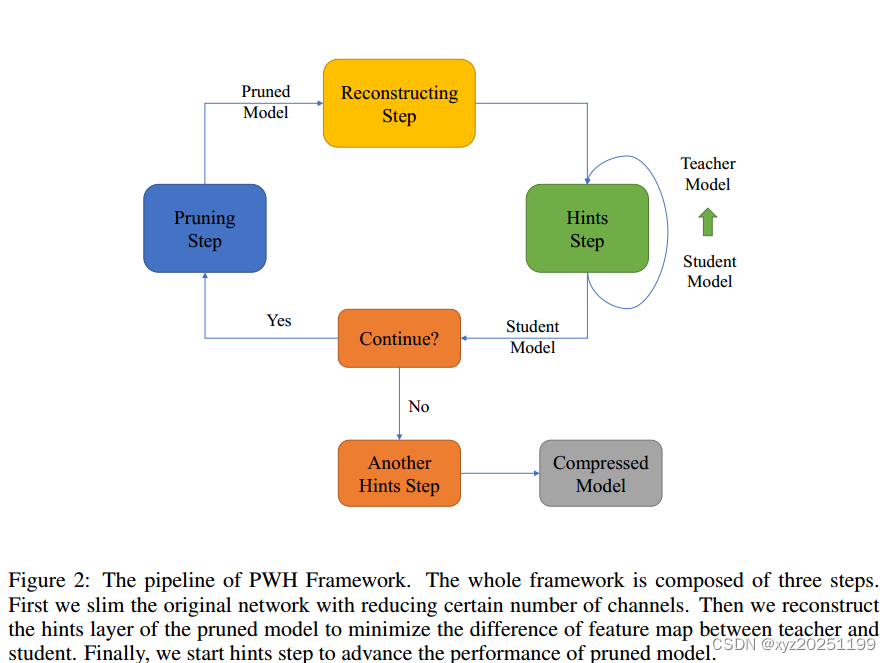
图2:PWH框架的流水线。整个框架由三个步骤组成。
首先,我们通过减少一定数量的频道来精简原有的网络。然后对剪枝模型的提示层进行重构,使师生特征映射的差异最小化。最后,我们开始提示步骤,以提高剪枝模型的性能。
适应提示: Chen等人(2017)证明有必要在学生和教师网络之间添加一个适应层。适应层可以将学生层特征空间迁移到教师层特征空间,促进提示学习。自适应提示的表达式如式4所示。

3.3RECONSTRUCTING STEP重构的步骤
重构步骤的目标函数为:
![]()
其中Y为原始(教师)模型的特征映射,X为提示层的输入,W为提示层的参数。该优化问题采用最小二乘法解为:W = (XTX)−1XTY。然而,由于一些数据集(如ImageNet Deng等)(2016))有众多的图像,X将是高维矩阵。而涉及如此庞大的矩阵的问题是不可能一次性解决的。所以我们在数据集中随机抽取图像,并根据这些图像计算X。由于权重的随机性,重构后的权重可能比原始权重差。因此,我们最终使用一个开关来选择更好的权重(参见公式6)。
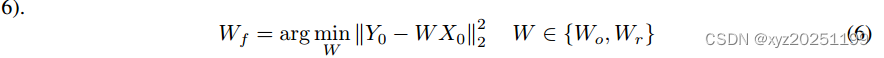
其中Wf、Wo、Wr分别为提示层的最终权值、原始权值和重构权值。Y0和X0是从整个数据集计算出来的。归一化L2损耗的目标函数(见式16)不同于L2损耗,但我们解释了重构步骤对于归一化L2损耗也是有效的。证据的细节可在补充材料中找到。
3.4PWH FRAMEWORK PWH框架
结合剪枝步骤、重构步骤和提示步骤,提出了PWH框架。该框架迭代地执行三个步骤。
对于剪枝,我们将通过确定通道的数量来模型大小减小( For pruning, we reduce the model size by certain numbers of channels.)然后对提示层参数进行重构,使剪枝模型与教师模型的特征映射差异最小化。最后以剪枝模型为学生,原始模型为教师,进行提示学习。在下一个迭代中,原始模型将被这个迭代中的学生模型所取代。经过训练后,学生模型将成为下一次迭代的教师模型。另一个提示步骤是在框架的末尾实现的,其中教师模型将在培训开始时被设置为原始模型(第一次迭代中的教师模型)。我们的方法的伪代码在附录中提供。
我们证明,与第一次迭代中的原始模型相比,当前迭代中的学生模型是下一步提示步骤中教师模型的更好候选。原因是剪枝前和剪枝后的模型有更多相似的特征映射和参数,可以促进和加快提示步进。在整个框架的最后,我们做了另一个提示步骤。
与之前的提示步骤不同,在第一次迭代中选择教师模型作为原始模型。我们证明了最后的提示步骤类似于剪枝方法中的微调步骤,可能需要长时间的训练并提高压缩模型的性能。第一次迭代的原始模型将是更好的老师。图2显示了框架的管道。
3.5ANALYSIS
PWH框架中的提示和剪枝是相辅相成的。一方面,剪枝模型是提示步骤中学生模型的良好初始化。我们提出,与随机初始化模型相比,剪枝模型的特征映射与原始模型相似。这样,Yosinski et al(2014)提出,学生和教师网络之间的可转移性会增加,这有利于提示学习。x4.4中的实验表明,与随机初始化模型相比,原始模型与剪枝模型特征映射的差异要小得多。另一方面,提示有助于修剪重建参数。结果表明,当剪枝通道数较大时,剪枝方法效率较低。在这种情况下,剪枝操作会带来很大的性能下降。我们发现,修剪大量的通道会破坏网络的主要结构(见3)。而提示可以缓解这种趋势,并有助于恢复结构和重建模型中的参数(见4)。
重构步骤的动机是对我们方法的推广。我们的方法是一个框架,它应该适用于不同的修剪方法。然而,一些剪枝方法的准则并不是基于最小化特征映射的重构误差。换句话说,原始(教师)网络和修剪后(学生)网络的特征图相似度仍有提高的空间,这有利于提示学习。我们只对提示层进行重构操作,因为这样既可以减少用于提示的特征映射的差异,又可以保持修剪后模型的主体结构(见4.3.3的实验)。此外,对于自适应提示方法,需要初始化自适应层(提示层)。与随机初始化相比,重构操作可以帮助构建该层,并提供更多与教师模型相似的特征。
四、EXPERIMENTS
我们在CIFAR-10 Krizhevsky & Hinton(2009)、ImageNet Deng等(2016)和COCO Lin等(2014)上进行了分类和姿态估计任务的实验,以证明PWH框架的优越性。在本节中,我们首先介绍不同数据集上不同实验的实现细节。然后将该方法与剪枝方法和提示方法进行了比较。
此外,在4.3中,我们做了消融研究来进一步分析框架。最后,我们分析了我们的方法在4.4中的有效性,并表明提示和修剪方法是相互补充的。
4.1实现细节
我们使用PyTorch深度学习框架训练网络。纯修剪是指经典的迭代修剪和微调操作。对于纯提示方法,我们将原始模型设置为教师模型,使用压缩随机初始化模型作为学生模型。为了公平比较,提示-only中的学生模型与PHW框架中的学生模型具有相同的网络结构.

我们使用标准的SGD,动量设置为0.9。标准权重衰减设置为1e-4。VGG-16 Simonyan & Zisserman(2015)网络与BatchNorm Ioffe & Szegedy(2015)、ResNet18 He等人(2016)和ResNet18与FPN Chen等人(2018)分别用于CIFAR-10、ImageNet和COCO。
4.2主要结果
表1说明了结果。我们可以发现PWH框架在不同任务的所有数据集上都以很大的幅度优于仅修剪方法和仅提示方法,这验证了我们框架的有效性,也表明提示和修剪可以结合起来提高性能。不同任务和模型的实验结果表明,PWH框架可以在不受任务和网络架构限制的情况下实现。此外,如表1所示,我们的框架可以适用于不同的剪枝比,这意味着我们可以针对不同的任务调整框架中的剪枝比,以实现不同的加速比。
4.3消融实验
为了进一步分析PWH框架,我们做了几个烧蚀研究。所有实验均在CIFAR-10数据集上使用VGG16BN进行。本节提出的feature map是指最后一个卷积层的输出,也是用于提示学习的feature map。在本节中,我们将从三个不同的方面进行消融研究。首先,我们通过实验证明迭代运算是PWH框架的重要组成部分。然后对提示步骤中教师模型的选择进行了研究。最后,对重构步骤的效果进行了验证。
4.3.1迭代的重要性
在PWH框架中,我们迭代地实现了三个步骤。在本节中,我们将展示迭代运算的重要性和必要性。我们做了一个实验来比较只做一次修剪和提示(即先做修剪,然后做提示)效果。这两个操作只执行一次),并迭代地执行修剪和提示。表2显示了结果。

我们可以看到,迭代运算可以显著提高模型的性能。为了进一步解释这一结果,我们做了另一个实验:我们分析了修剪模型的性能与修剪通道数量之间的关系。从图3的结果可以看出,当剪枝通道数量较大时,剪枝模型的性能会迅速下降。因此,如果我们只做一次剪枝和提示,剪枝会带来很大的性能下降,剪枝后的模型不能输出与原始模型相似的特征。这样看来,剪枝模型并不是一个更合理的初始化学生模型。在这种情况下,修剪步骤对提示步骤是无用的。
4.3.2教师模式的选择
教师模型是PWH框架中先前迭代的修剪模型。培训开始时的原始模型可以作为每次迭代中教师模型的另一种选择。我们通过实验对这两种模式的教师模型进行了比较。在这个实验中,我们在每次迭代中修剪256个频道。图4显示了结果。
我们观察到,当迭代较小时,在第一次迭代中使用原始模型作为教师模型与在前一次迭代中使用修剪后的模型具有相当的性能。然而,随着迭代次数的增加,我们可以发现在前一次迭代中使用剪枝模型的优越性增加。原因是原始模型在第一次迭代时具有较高的精度,因此在迭代次数较少时表现良好。但当迭代次数较大时,剪剪后的模型特征图与原始模型的特征图差异较大。在这种情况下,在提示步骤中,剪枝模型与教师模型之间存在着差距。另一方面,在之前的迭代中使用修剪后的模型可以提高学生模型和教师模型之间特征映射的相似性,从而有助于提示步骤的提炼。
4.3.3重构步骤的有效性
在3.3中提出了重构步骤,用于进一步细化剪枝模型的特征,使其更接近教师的特征。通过实验验证了重构步骤的有效性。为了公平地比较,我们实现了有和没有重建步骤的PWH框架。
在每次迭代中,我们修剪了256个通道。采用两种不同的方法对压缩模型的精度进行了研究。此外,我们还分析了每次迭代中剪枝模型与原始模型特征映射之间的L2损失。实验结果如图5所示。我们发现带重构步骤的方法性能更好。我们希望我们的框架能够适应不同的剪枝方法,但是一些剪枝方法的标准并没有最小化重构特征映射的误差。重构步骤可以解决这一问题,增加两个模型之间特征映射的相似度。
4.4PWH框架分析
为了进一步分析PWH框架的特性,我们对我们的方法进行了进一步的实验。实验结果验证了我们的假设:剪枝和提示是互补的。所有实验均在CIFAR-10数据集上进行,以VGG16为原始模型。
4.4.1修剪有助于提示
通过实验比较了剪枝模型和随机初始模型重构特征映射的误差。我们使用3.1中的修剪方法从原始网络中修剪一定数量的通道,并计算修剪后的模型的特征映射与原始模型的特征映射之间的L2损失。同样,我们随机初始化一个与剪枝模型大小相同的模型,并计算该模型与原模型之间特征映射的L2损失。然后增加剪枝通道数,记录这两种误差。在表2中,我们注意到在大范围内(0-1024个修剪通道),修剪后模型的特征映射与原始模型的特征映射更加相似。这表明,剪枝模型与原始模型之间的可移植性更大。学生模型采用剪枝模型的权值初始化,提示学习效果更好。
4.4.2提示有助于修剪
为了证明提示方法有利于剪枝,我们首先比较了仅剪枝、剪枝和提示的实验。与PWH框架不同,本节使用的剪枝和提示方法没有重建步骤。这是因为我们想要显示提示的有效性,而重建步骤是一个无关变量。在对比实验中,我们迭代地实现了剪枝和提示操作。为了公平地比较,在剪枝和提示方法中,我们用微调操作代替提示操作,得到只剪枝的方法。在图6中,我们观察到在少量迭代时,剪枝和提示方法与仅剪枝方法的性能相当。然而,随着迭代次数(修剪通道数)的增加,两种方法的余量越来越大。这种现象是由于在原始模型很小的情况下,剪枝操作的性能下降很大。小模型的冗余神经元不多,在剪枝时会破坏主体结构。提示可以缓解这一趋势,并有助于在剪枝模型中重建参数。
五、CONCLUSION
本文提出了一种用于模型加速的迭代框架——PWH框架。我们的框架同时利用了修剪和提示方法。据我们所知,这是第一个结合这两种模型加速方法的工作。此外,我们在提示和剪枝步骤之间以级联的方式进行重建操作。我们分析了这两种方法的性质,表明它们是互补的:剪枝法为学生模型提供了更好的初始化,提示法有助于剪枝模型的参数调整。在CIFAR-10、ImageNet和COCO数据集上的分类和姿态估计实验证明了PWH框架的优越性















 1192
1192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









