







Dify 是一个开源的大语言模型(LLM)应用开发平台。它拥有直观的界面,集成了智能体 AI 工作流、检索增强生成(RAG)流程、智能体能力、模型管理、可观测性功能等,能让你快速从原型阶段过渡到产品上线阶段。
GitHub Dify![]() https://github.com/langgenius/dify
https://github.com/langgenius/dify
一 .安装
提示:默认端口80,需要配置云服务器的安全策略,80端口的访问权限。
二.配置
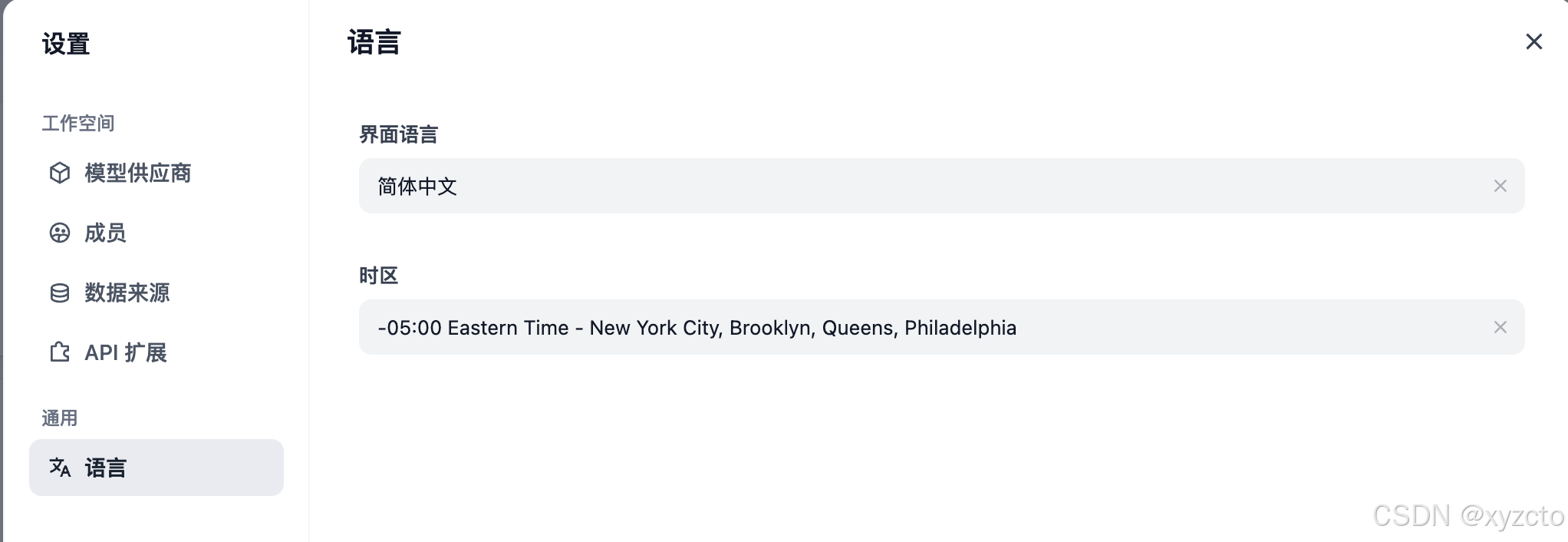
1.设置语言
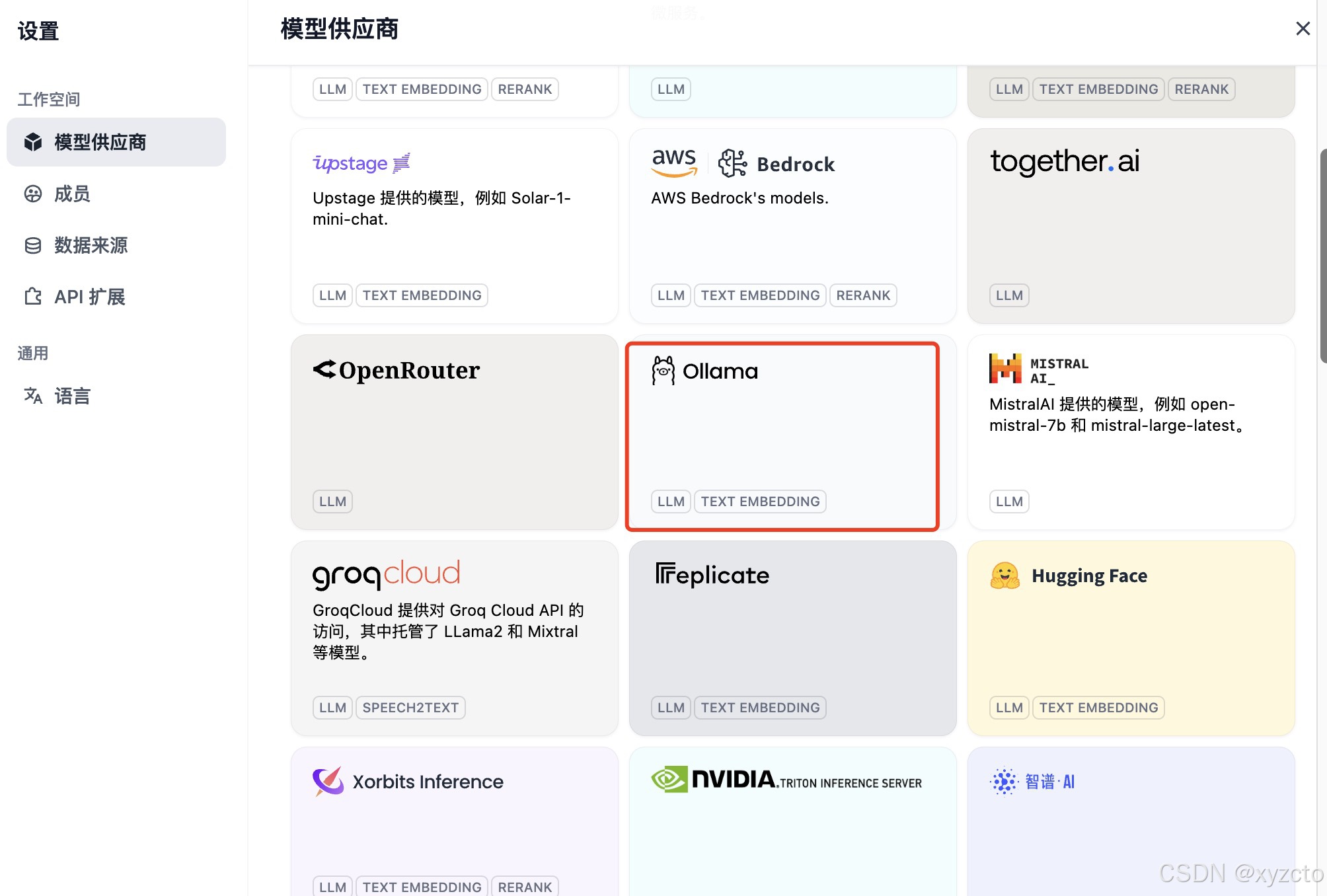
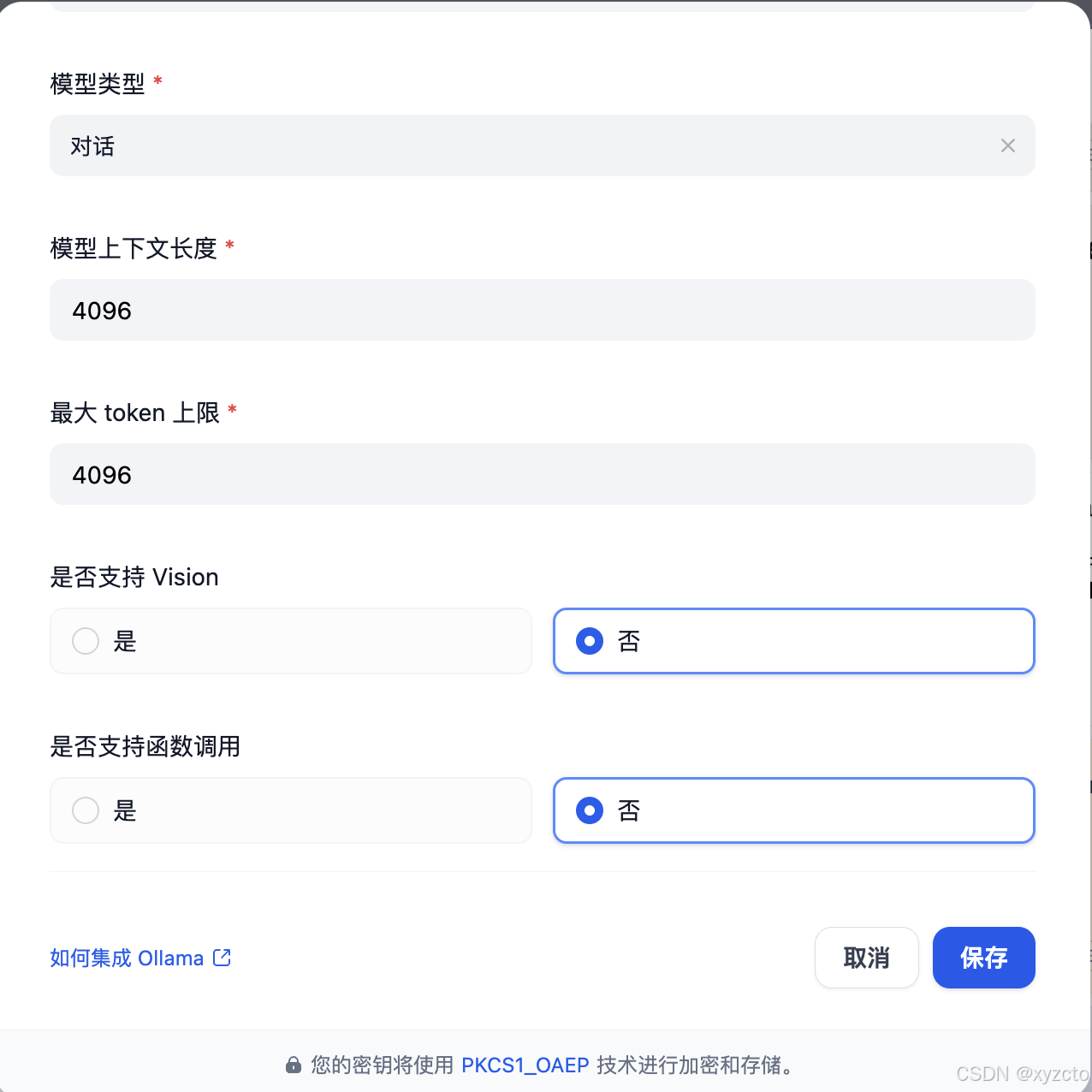
2. 配置模型供应商
这里以Ollama为例,安装参考:
Alibaba Cloud Linux 基于Ollama部署DeepSeek R1:7B版本
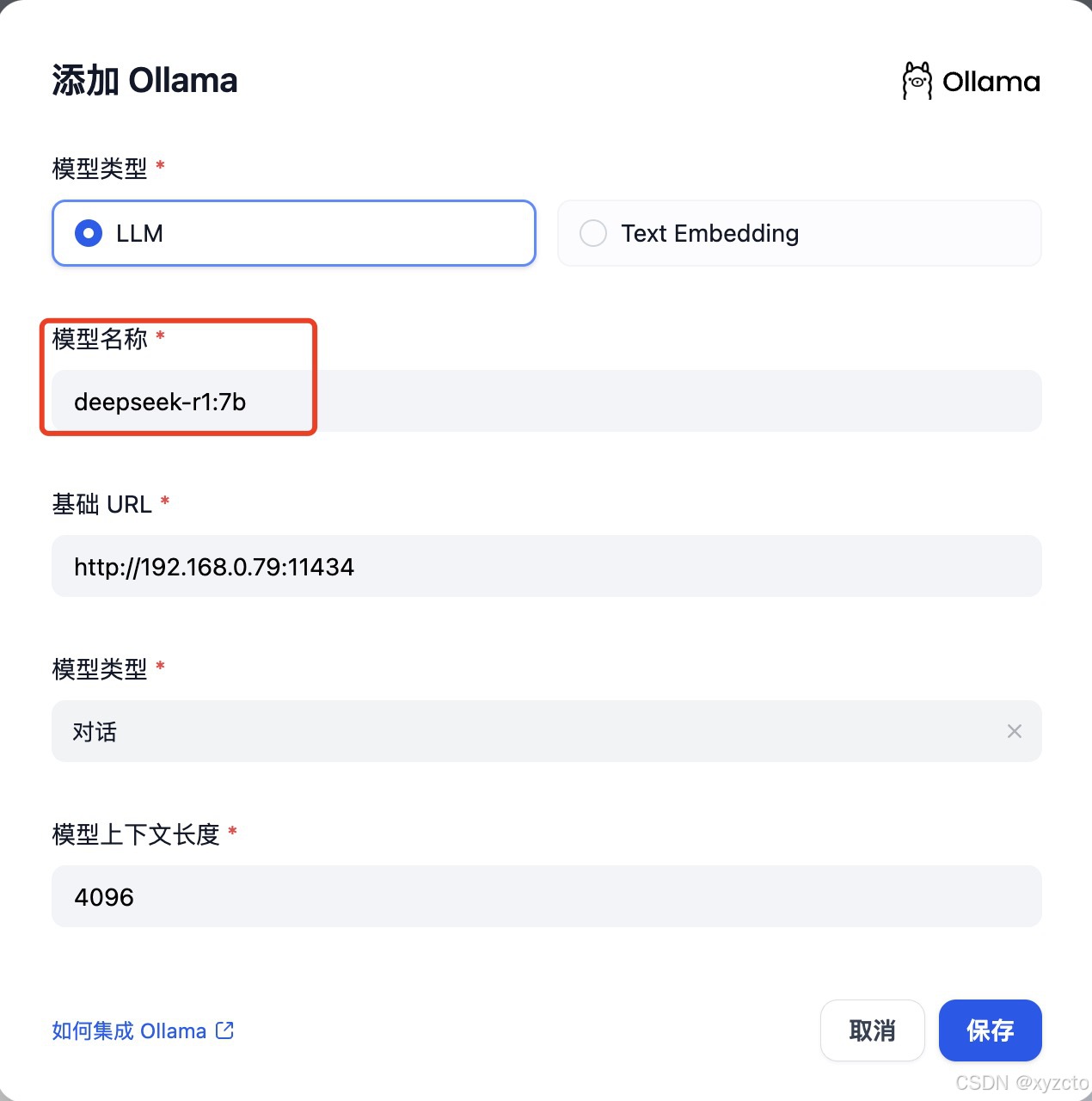
基础URL:填写安装的Ollama的,页面可以向下滚动
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3451
3451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











