









 本文提供了一个难以访问的数据集PoseTrack的下载链接。该数据集对于姿态跟踪研究非常重要,包含2017年和2018年的版本,文件大小分别为30GB和80GB。文中还给出了正确的解压命令。
本文提供了一个难以访问的数据集PoseTrack的下载链接。该数据集对于姿态跟踪研究非常重要,包含2017年和2018年的版本,文件大小分别为30GB和80GB。文中还给出了正确的解压命令。
PoseTrack是姿态跟踪的标准数据集,最近想下载下来进行模型训练,但是发现PoseTrack官网的链接打不开了,不知道是咋回事。。。因此搜索了一下找到了该数据集的磁力链,但是迅雷下的也挺难受的,好不容易下下来了,上传到了百度网盘,有需要的朋友可以下载。
链接在文章最后。
跟human36数据集类似,它也是分卷压缩的,2017是30g,2018是80g,如下图所示:
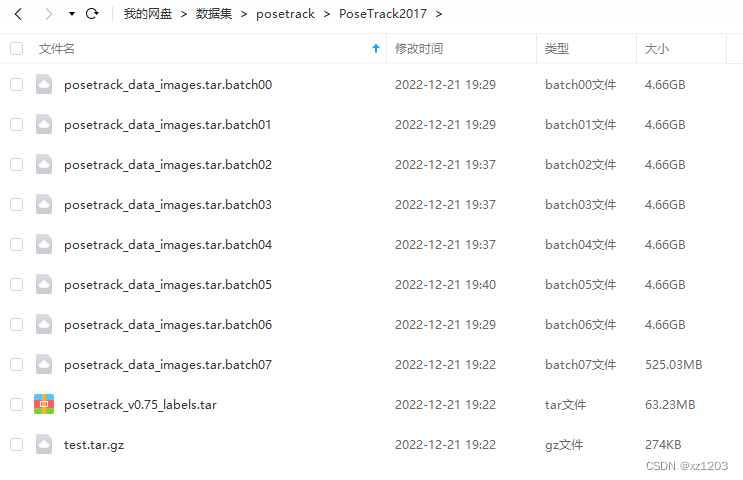
解压的时候采用以下命令(PoseTrack2018):
cat posetrack18_images.tar.a* | tar -x
一个个解压会报错:

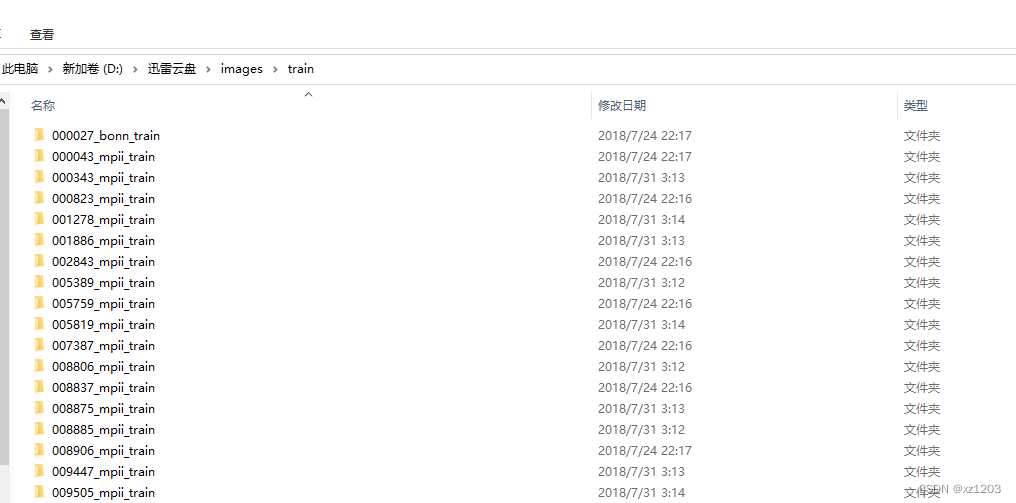
解压后如下:
百度网盘链接:
链接:https://pan.baidu.com/s/1qkiOiwbJurPAVXcogNWy-g?pwd=s4pt
提取码:s4pt


















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









