







本文探讨了 LLM 在软件开发中的有效性,特别关注错误解决。根据我在 Raygun 从事 AI 错误解决工作期间对整个行业的观察和见解,我将分析 LLM 的当前功能及其对未来开发实践的影响。
本文对软件开发领域的法学硕士学位进行了评估,重点关注其解决错误的有效性,这是软件开发人员工作流程中的一项关键任务。
大型语言模型 (LLM) 正在日益塑造软件开发的未来,为代码生成、调试和错误解决提供了新的可能性。这些人工智能驱动工具的最新进展促使人们更深入地研究它们的实际应用及其对开发人员工作流程的潜在影响。
本文探讨了 LLM 在软件开发中的有效性,特别关注错误解决。根据我在 Raygun 从事 AI 错误解决工作期间对整个行业的观察和见解,我将分析 LLM 的当前功能及其对未来开发实践的影响。讨论将权衡这些技术融入我们日常工作时出现的有希望的进步和挑战。
一、用于软件开发的 OpenAI 模型
OpenAI 已成功发布了更新、更快、据称更智能的模型。虽然基准测试网站证实了这些结果,但我们看到越来越多的轶事数据声称这些模型感觉更笨。
大多数现有基准测试仅关注这些模型的逻辑推理方面,例如完成 SAT 问题,而不是关注定性响应,尤其是在软件工程领域。我的目标是使用错误解决作为基准对这些模型进行定量和定性评估,因为它在开发人员的工作流程中很常见。
我们的全面评估将涵盖多个模型,包括 GPT-3.5 Turbo、GPT-4、GPT-4 Turbo、GPT-4o 和 GPT-4o mini。我们将使用真实的堆栈跟踪和发送给我们的相关信息来评估这些模型如何处理错误解决。我们将彻底检查响应速度、答案质量和开发人员偏好等因素。此分析将提供从这些模型中提取最佳响应的建议,例如提供更多上下文(如源映射和源代码)对其有效性的影响。
二、实验方法
如上所述,我们将评估以下模型:GPT-3.5 Turbo、GPT-4、GPT-4 Turbo、GPT-4o 和 GPT-4o Mini。使用的具体变体是截至 2024 年 7 月 30 日 OpenAI API 提供的默认模型。
为了进行评估,我们从各种编程语言(包括 Python、TypeScript 和 .NET)中选择了 7 个实际错误,每种语言都与不同的框架结合使用。我们通过从我们的帐户和个人项目中抽取现有错误作为代表性样本来选择这些错误。暂时性错误或未指向直接原因的错误未被选中。
| 姓名 | 语言 | 解决方案 | 困难 |
| Android 缺少文件 | .NET 核心 | 尝试读取的 .dll 文件不存在 | 简单的 |
| 除以零 | Python | 空数组导致除以零的错误 - 没有错误检查 | 简单的 |
| 站点 ID 无效 | TypeScript | 从 Alexa 请求信封中提取的停止 ID 无效 - Alexa 模糊测试发送了无效的 xyzxyz 值 | 难的 |
| IRaygunUserProvider 未注册 | .NET 核心 | IRaygunUserProvider 未在 DI 容器中注册,导致无法在 MAUI 中创建 MainPage | 中等的 |
| JSON 序列化错误 | .NET 核心 | 强类型对象映射与提供的 JSON 对象不匹配,这是由于 Raygun 客户端发送了不合规的错误负载造成的 | 难的 |
| 主页未注册 ILogger | .NET 核心 | 添加了 ILogger,但是没有将 MainPage 作为单例添加到 DI 容器中,导致 ILogger<MainPage> 在创建 MainPage 时出错 | 中等的 |
| Postgres 缺少表 | .NET 核心/Postgres | Postgres 在被 C# 程序调用时缺少表,导致堆栈跟踪混乱 | 简单 - 中等 |
然后,我们使用了 Raygun 的 AI Error Resolution 中的模板系统提示,该提示整合了发送给我们的崩溃报告中的信息。我们通过 OpenAI 的 API 在所有模型上直接测试了这一点。此过程生成了 35 个 LLM 错误响应对。然后,这些对被随机分配给我们的工程师,他们根据准确性、清晰度和实用性按 1 到 5 的等级对它们进行评分。我们抽样了 11 名工程师,包括软件工程师和数据工程师,他们的经验水平各不相同,从拥有几年经验的工程师到拥有几十年经验的工程师都有。
除了偏好评分之外,我们还将对模型的性能进行分析。该分析将重点关注两个关键方面:响应时间和响应长度,然后我们将利用这两个方面得出这些模型有效性的多项指标。
三、开发人员偏好:定性结果
1.一般观察
我们根据工程师的评分绘制了图表。虽然该分析侧重于错误解决上,但将这些发现与此前讨论的其他动机因素进行比较是必不可少的。例如,模型在错误解决方面的有效性可能与它们在代码生成或调试等任务中的表现不同,这可能会影响整体的结论。这种更广泛的视角有助于我们了解大型语言模型对开发人员工作流程不同方面的不同影响。
2.意外的发现
我们假设 GPT-4 是最好的模型,但我们的软件工程师给它的评分最差。我们可以使用软件工程师的反馈和一些分析数据来为这个结果提供可能的解释,我们将在下一节中展示这些数据。这些假设来自我与另一位密切关注这项研究的工程师的讨论。
GPT-4 Turbo 及以后的模型在建议更改时会包含代码片段,工程师们报告说这让他们更好地理解了解决方案。GPT-4 没有生成代码片段,并且解决方案比 GPT-3.5 Turbo 更长,这表明工程师不喜欢不包含补充资源的较长响应。
3.错误模式
我们还观察到,JSON 验证错误在所有模型变体中的排名始终很低,因为单独的堆栈跟踪无法为该错误提供良好的解决方案;这促使我们及时进行工程设计,并了解在向 LLM 寻求帮助时哪些信息是有帮助的。
4.上下文影响
(1)对于 .NET 错误
.NET 错误包括所有这些测试用例,除了除以zero error和invalid stop ID,如上表所述。结果是,LLM 和工程师唯一知道的上下文是堆栈跟踪、标签、breadcrumbs和自定义数据。我们看到这些错误的报告分数较高,可能是因为 Raygun 的工程师主要使用 .NET。然而,在我们测试不同语言的情况下,我们仍然观察到了良好的结果。
(2)其他语言
根据工程师的评论,原因在于,在 Python 和 TypeScript 两种情况下,堆栈跟踪都带有周围的代码上下文。在 Python 中,周围的代码上下文是堆栈跟踪的一部分,而在 TypeScript 错误中,它来自包含源代码的源映射。有了这些附加信息,LLM 可以生成直接解决错误的代码片段,这也有助于对后续一系列 GPT-4 变体进行评级。
5.性能评定
(1)GPT-4 Turbo 后性能下降
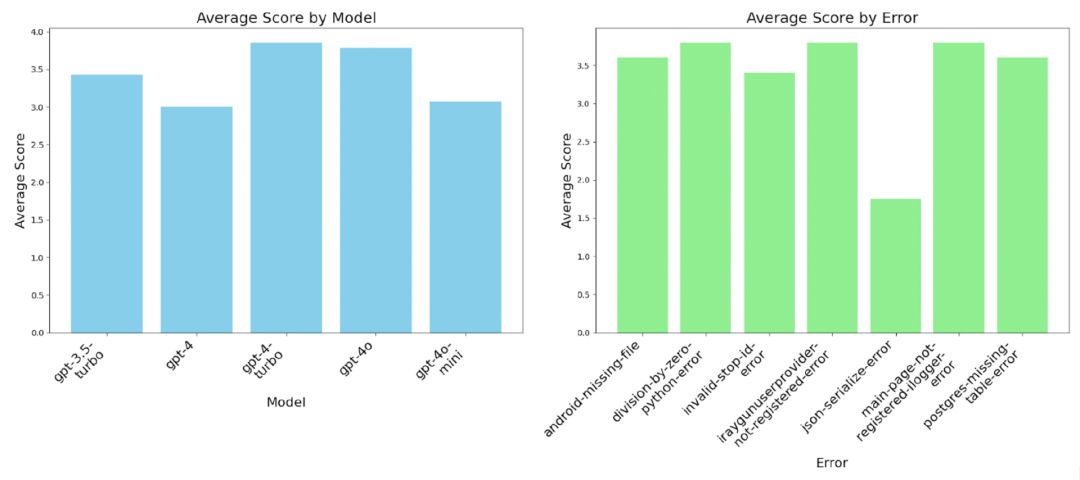
图片
从 GPT-4 Turbo 及以后的评分来看,我们发现评分有所下降,尤其是在达到 GPT-4o 之后,尽管这些结果仍然比 GPT-4 更好,而且大多数都比 GPT-3.5 Turbo 更好。如果我们将 JSON 序列化错误作为异常值删除,我们仍然可以观察到 GPT-4 Turbo 之后性能的下降。这个结果清楚地表明,GPT-4 系列的性能在 GPT-4 Turbo 时达到顶峰,随后下降。
(2)上下文对于非描述性堆栈跟踪的重要性
JSON 序列化错误导致的这种糟糕表现可能是由于需要有关底层问题的支持信息。仅查看堆栈跟踪很难确定错误,因为存在多个故障点。同样,这涉及到包含更多上下文(例如源代码和变量值)的主题,以提示问题可能出在哪里。这里的增强功能可能是对源代码进行 RAG 查找实现,因此可以将堆栈跟踪与相应的代码关联起来。
(3)响应长度对性能的影响
后期模型性能下降的一个原因是响应长度增加。这些模型在处理逻辑性更强的问题时可能会表现更好,但这些较长的响应在日常对话中并不受欢迎。我在询问有关 Python 库的问题时遇到过这种情况,我希望得到直接的答案。每次,它都会重复一整段关于设置库的介绍部分以及与我的问题有关的无用信息。
如果是这样的话,我们希望在 GPT-5 和其他竞争对手等新模型问世时看到对此进行一些修正,但就目前而言,这些模型的冗长之处仍将存在。
四、分析:定量结果
1.响应时间和内容生成
虽然对 LLM 响应进行定性评估至关重要,但响应时间/生成速度和生成的内容量也会显著影响这些工具的实用性。下图显示了创建错误响应对的聊天完成的平均响应时间。
有趣的是,GPT-4 Turbo 是生成聊天完成的平均响应时间最慢的模型。这是一个令人惊讶的结果,因为一般理解认为 GPT-4 Turbo 应该比 GPT-4 更快。
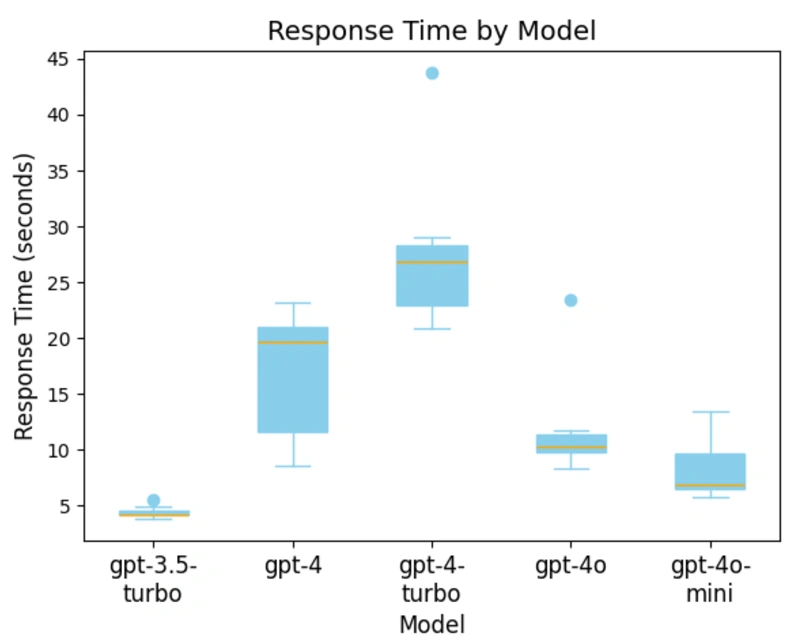
图片
2.Token生成和模型性能
下图通过测量每个模型生成的平均 token 数量解释了这一令人惊讶的结果。这表明 GPT-4 Turbo 平均生成的 token 数量明显多于 GPT-4。有趣的是,上图显示 GPT-4o 生成的 token 数量最多,但速度仍然比 GPT-4 Turbo 快得多。
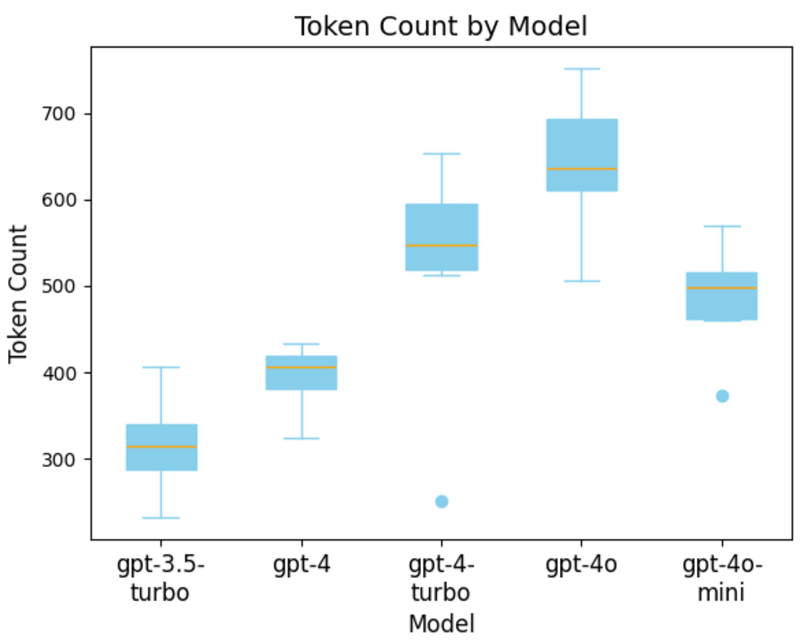
图片
我们还发现,这种代币数量增加的趋势并没有在 OpenAI 的最新模型 GPT-4o mini 中延续。与 GPT-4 Turbo 相比,平均代币数量有所减少,但仍远高于 GPT-4。生成代币数量最少的模型是 GPT-3.5 Turbo,这与定性分析结果一致,工程师更喜欢较短的响应,而不是较长的响应且没有补充解释。
3.每个Token的响应时间
检查完模型的响应时间和平均令牌数后,我们可以确定每个模型在响应时间和令牌生成方面的速度。
下面是按模型显示每个 token 响应时间的图表。在这里,我们看到 GPT-4 比 GPT-4 Turbo 更快,但这是由于数据中的异常值。鉴于它倾向于生成更长的输出,其整体响应时间仍然比 GPT-4 更长。这可能意味着当 GPT-4 Turbo 生成的内容过多时,它就不是一个理想的模型。
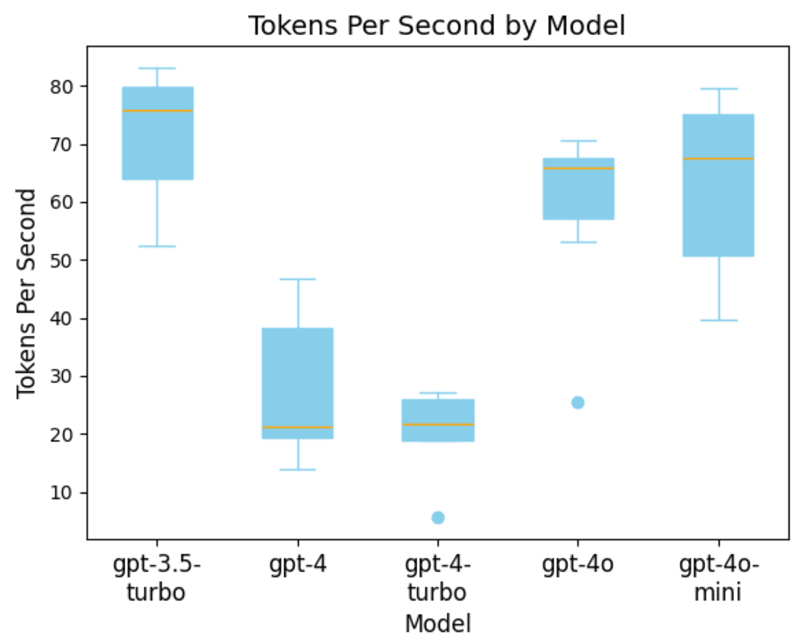
图片
注意:GPT-3.5、GPT 4 和 GPT-4o 模型使用不同的标记器。
4.GPT-4o 与 GPT-4o Mini 的比较
有趣的是,数据显示 GPT-4o 和 GPT-4o mini 的响应速度相似,这与其他来源的发现形成鲜明对比。这种差异表明,可能需要更大的样本量才能揭示它们性能上更明显的差异。另一种解释是,鉴于我们是通过总响应时间来衡量每秒的令牌数,由于第一个令牌时间 (TTFT) 和其他与网络相关的瓶颈,我们稍微将值偏低。
5.扩展模式
按模型分组绘制响应时间与令牌数的关系图,可以揭示这些模型扩展的不同模式。对于 GPT-3.5、GPT-4o 和 GPT-4o Mini,扩展大多是线性的,令牌数的增加会导致响应时间相应增加。
然而,这种模式并不适用于 GPT-4 系列中较大和较旧的模型,因为这两个变量没有一致的关系。这种不一致可能是由于样本量较小或专用于这些请求的资源较少,导致响应时间不同。考虑到在其他模型中观察到的线性关系,后一种解释更有可能。
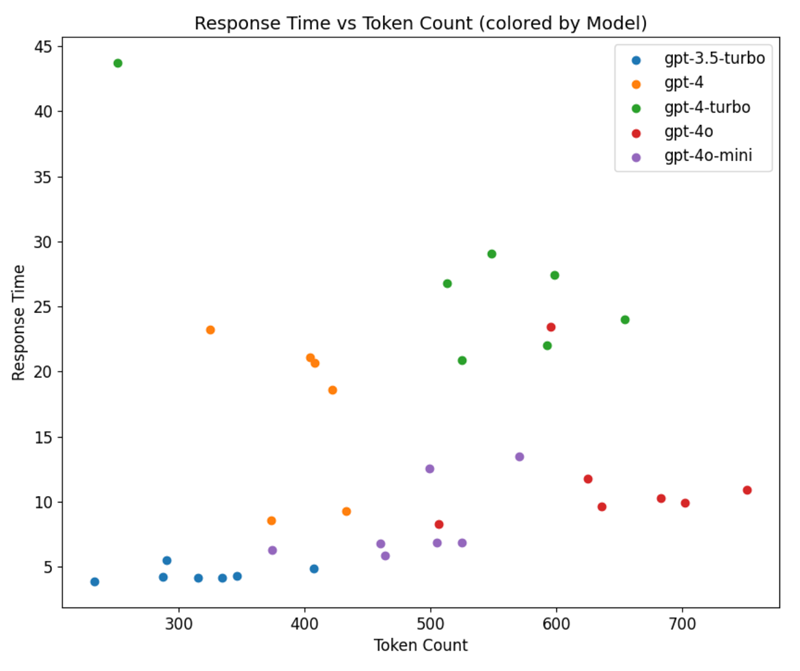
图片
6.GPT-4 上下文限制
生成这些错误-响应对后,我们得出了最后一个分析结论。虽然 GPT-4 模型很有能力,但其上下文长度对于需要长输入的任务(例如堆栈跟踪)而言受到很大限制。因此,无法生成一个错误-响应对,因为组合的输入和输出将超出模型的 8192 个 token 上下文窗口。
7.综合来看
在评估定性数据后,很明显 GPT-4 Turbo 是这项任务的最佳模型。但是,将其与定量数据进行比较会引入响应时间和成本考虑因素。新的 GPT-4o 模型比所有其他模型都快得多,而且便宜得多,这是一个权衡。如果需要稍微好一点的性能,GPT-4 Turbo 是首选。但是,如果成本和速度是优先考虑因素,GPT-4o 和 GPT-4o mini 是更好的选择。
五、结论
总之,我们的研究提供了有关后期模型性能的混合证据。虽然一些较新的模型(如 GPT-4 Turbo 和 GPT-4o)由于能够包含简洁的代码片段而有所改进,但其他模型(如 GPT-4)由于响应冗长且不太实用而未能达到要求。
六、关键要点
- 代码片段很重要:提供代码片段和解释的模型更有效,也更受开发人员的青睐。
- 上下文至关重要:添加周围代码或源映射可显著提高响应的质量。
- 平衡回复长度:较短、简洁的回复通常比较长、冗长的回复更有帮助。
- 定期评估:持续评估模型性能,以确保您使用最有效的工具来满足您的需求。
- 注意上下文限制:了解上下文长度限制并据此制定计划。
通过关注这些因素,开发人员可以更好地利用 LLM 来解决错误,最终提高他们的工作效率和解决方案的准确性。
未来可以补充这项研究的实验可能包括对代码生成的更深入的分析,如引言中所述。一个可能的实验可能涉及从错误解决中获取建议并为 LLM 提供额外的背景信息。理想情况下,如果要重做这项研究,最好包括更广泛的错误类型,包括更具挑战性的错误,并从更多样化的工程师那里收集评级。
















 121
121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











