 理解PACF:Yule-Walker与OLS计算差异
理解PACF:Yule-Walker与OLS计算差异





 本文介绍了PACF(偏自相关函数)的计算方法,通过Yule-Walker方程和OLS(普通最小二乘法)进行对比。举例展示了第四阶PACF系数的计算,并探讨了两者在计算过程中的不同,特别是在数据点影响的理解上。Yule-Walker方程旨在优化计算,降低计算复杂度。
本文介绍了PACF(偏自相关函数)的计算方法,通过Yule-Walker方程和OLS(普通最小二乘法)进行对比。举例展示了第四阶PACF系数的计算,并探讨了两者在计算过程中的不同,特别是在数据点影响的理解上。Yule-Walker方程旨在优化计算,降低计算复杂度。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
plt.rcParams['font.family'] = 'Songti SC' # 显示中文标签
#from matplotlib.font_manager import FontProperties
#font =FontProperties(fname = '/Users/cloudwise/Documents/字体/simsun.ttf')
%matplotlib inline
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import pacf, pacf_ols, pacf_yw
import statsmodels as sm
from scipy.linalg import toeplitz
from statsmodels.regression.linear_model import OLS, yule_walker
公式
statsmodels.tsa.stattools.pacf的计算方式
参考:https://www.statsmodels.org/stable/_modules/statsmodels/regression/linear_model.html#yule_walker
Y u l e − W a l k e r 方 程 , 系 数 求 法 i n p u t 1 : t s i n p u t 2 : o r d e r n = l e n ( t s ) k ∈ [ 0 , 1 , 2 , 3 , . . . , o r d e r ] r k = t s 1 ∗ t s k + 1 + t s 2 ∗ t s k + 2 + t s 3 ∗ t s k + 3 + . . . + t s n − k ∗ t s n n − k Yule-Walker方程,系数求法 \\ input 1 : ts \\ input 2 : order \\ n = len(ts) \\ k \in [0,1,2,3,..., order] \\ r_{k} = \frac{ts_{1}*ts_{k+1} + ts_{2}*ts_{k+2} + ts_{3}*ts_{k+3} + ... +ts_{n-k}*ts_{n}}{n-k} Yule−Walker方程,系数求法input1:tsinput2:ordern=len(ts)k∈[0,1,2,3,...,order]rk=n−kts1∗tsk+1+ts2∗tsk+2+ts3∗tsk+3+...+tsn−k∗tsn
R = [ r 0 r 1 r 2 . . . r o r d e r − 1 r 1 r 0 r 1 . . . r o r d e r − 2 r 2 r 1 r 0 . . . r o r d e r − 3 . . . . . . . . . . . . r o r d e r − 1 r o r d e r − 2 r o r d e r − 3 . . . r 0 ] R= \left[ %左括号 \begin{array}{ccccc} %该矩阵一共3列,每一列都居中放置 r_{0} & r_{1} & r_{2} & ... & r_{order-1}\\ r_{1} & r_{0} & r_{1} & ... & r_{order-2}\\ r_{2} & r_{1} & r_{0} & ... & r_{order-3}\\ ... & & ... & ... & ...\\ r_{order-1} & r_{order-2} & r_{order-3} & ... & r_{0}\\ \end{array} \right] %右括号 R=⎣⎢⎢⎢⎢⎡r0r1r2...rorder−1r1r0r1rorder−2r2r1r0...rorder−3...............rorder−1rorder−2rorder−3...r0⎦⎥⎥⎥⎥⎤
R 为 t o e p l i t z 矩 阵 R为toeplitz矩阵 R为toeplitz矩阵
多
元
函
数
,
求
解
r
h
o
R
o
r
d
e
r
∗
o
r
d
e
r
∗
r
h
o
o
r
d
e
r
∗
1
T
=
[
r
1
,
r
2
,
r
3
,
.
.
.
,
r
o
r
d
e
r
]
o
r
d
e
r
∗
1
T
多元函数,求解rho\\ R_{order*order} * rho^T_{order*1} = [r_{1}, r_{2}, r_{3}, ..., r_{order}]^T_{order*1}\\
多元函数,求解rhoRorder∗order∗rhoorder∗1T=[r1,r2,r3,...,rorder]order∗1T
即
r
0
∗
r
h
o
0
+
r
1
∗
r
h
o
1
+
r
2
∗
r
h
o
2
+
.
.
.
+
r
o
r
d
e
r
−
1
∗
r
h
o
o
r
d
e
r
−
1
=
r
1
r
1
∗
r
h
o
0
+
r
0
∗
r
h
o
1
+
r
1
∗
r
h
o
2
+
.
.
.
+
r
o
r
d
e
r
−
2
∗
r
h
o
o
r
d
e
r
−
1
=
r
2
.
.
.
.
.
.
r
o
r
d
e
r
−
1
∗
r
h
o
0
+
r
o
r
d
e
r
−
2
∗
r
h
o
1
+
r
o
r
d
e
r
−
3
∗
r
h
o
2
+
.
.
.
+
r
r
0
∗
r
h
o
o
r
d
e
r
−
1
=
r
o
r
d
e
r
r_{0}*rho_{0} + r_{1}*rho_{1} + r_{2}*rho_{2} + ... + r_{order-1}*rho_{order-1} = r_{1} \\ r_{1}*rho_{0} + r_{0}*rho_{1} + r_{1}*rho_{2} + ... + r_{order-2}*rho_{order-1} = r_{2} \\ ......\\ r_{order-1}*rho_{0} + r_{order-2}*rho_{1} + r_{order-3}*rho_{2} + ... + r_{r0}*rho_{order-1} = r_{order} \\
r0∗rho0+r1∗rho1+r2∗rho2+...+rorder−1∗rhoorder−1=r1r1∗rho0+r0∗rho1+r1∗rho2+...+rorder−2∗rhoorder−1=r2......rorder−1∗rho0+rorder−2∗rho1+rorder−3∗rho2+...+rr0∗rhoorder−1=rorder
s i g m a s q = r 0 − ∑ i = 1 o r d e r ( r i ∗ r h o i − 1 ) sigmasq = r_{0} - \sum_{i=1}^{order}{(r_{i}*rho_{i-1})} sigmasq=r0−i=1∑order(ri∗rhoi−1)
第 o r d e r 阶 的 p a c f 值 : r h o o r d e r − 1 第order阶的pacf值:rho_{order-1} 第order阶的pacf值:rhoorder−1
示例
a = np.array([1,2,3,4,5])
#a = a - np.mean(a)
n = len(a)
plot_pacf(a)
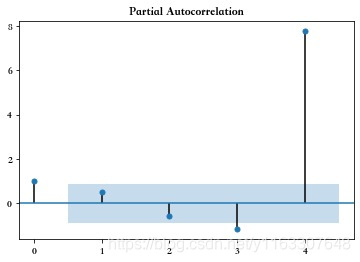
pacf_yw(a, nlags=4, method='unbiased')
order = 4
print(sm.regression.yule_walker(a, order=order))
a = a - np.mean(a)
adj_needed = 1
r = np.zeros(order+1, np.float64)
r[0] = (a ** 2).sum() / n
for k in range(1, order+1):
r[k] = (a[0:-k] * a[k:]).sum() / (n - k * adj_needed)
R = toeplitz(r[:-1])
rho = np.linalg.solve(R, r[1:])
print(rho, rho[-1])
(array([ 9. , -2.25, -2.25, 7.75]), 4.330127018922193)
[ 9. -2.25 -2.25 7.75] 7.749999999999999
第四阶的系数为:7.75
rho[-1]:7.749999999999999
相等
对比pacf中yule_walker 和 ols方法的差异
plot_pacf(a)
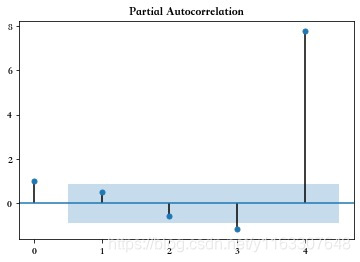
plot_pacf(a, method = 'ols')
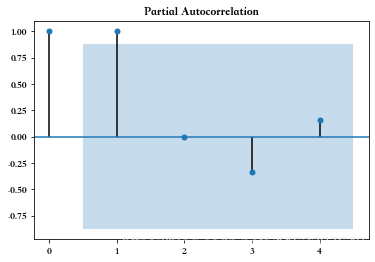
?plot_pacf
print(pacf_yw(a, nlags=4, method='unbiased'))
print(pacf_yw(a, nlags=4, method='mle'))
[ 1. 0.5 -0.55555556 -1.14285714 7.75 ]
[ 1. 0.4 -0.30952381 -0.29467085 -0.17966102]
print(pacf_ols(a, nlags=4, efficient=True, unbiased=True))
print(pacf_ols(a, nlags=4, efficient=True, unbiased=False))
print(pacf_ols(a, nlags=4, efficient=False, unbiased=True))
print(pacf_ols(a, nlags=4, efficient=False, unbiased=False))
[ 1.00000000e+00 1.25000000e+00 -2.60138922e-16 -8.33333333e-01
8.06451613e-01]
[ 1.00000000e+00 1.00000000e+00 -1.56083353e-16 -3.33333333e-01
1.61290323e-01]
[ 1. 2.5 0. -2.5 -3.33333333]
[ 1. 2. 0. -1. -0.66666667]
示例
from statsmodels.tsa.tsatools import lagmat
xlags, x0 = lagmat(a_mean, 4, original='sep', trim='both')
a_mean
array([-2., -1., 0., 1., 2.])
xlags
array([[ 1., 0., -1., -2.]])
x0
array([[2.]])
pacf_ols的计算
#使用最小二乘求1阶系数时
#结果与pacf_ols一阶系数不一致
np.linalg.lstsq(np.array([[-2],[-1],[0],[1]]), np.array([-1,0,1,2]), rcond=None)[0]
array([0.66666667])
#结果与pacf_ols一阶系数一致
np.linalg.lstsq(xlags[:, :1],x0, rcond=None)[0][-1]
array([2.])
#结果与pacf_ols 2阶系数一致
np.linalg.lstsq(xlags[:, :2],x0, rcond=None)[0][-1]
array([0.])
#结果与pacf_ols 3阶系数一致
np.linalg.lstsq(xlags[:, :3],x0, rcond=None)[0][-1]
array([-1.])
#结果与pacf_ols 4阶系数一致
np.linalg.lstsq(xlags[:, :4],x0, rcond=None)[0][-1]
array([-0.66666667])
np.linalg.lstsq([[1,0,-1,-2]],[[2]], rcond=None)[0][-1]
array([-0.66666667])
从 上 述 过 程 可 以 看 出 , 使 用 p a c f _ o l s 时 , 系 数 的 解 a k 来 自 : x t = a 1 ∗ x t − 1 + a 2 ∗ x t − 2 + a 3 ∗ x t − 3 + . . . + a k ∗ x t − k 而 非 : 从上述过程可以看出,使用pacf\_ols时,系数的解a_{k}来自: \\ x_{t} = a_{1}*x{t-1} + a_{2}*x{t-2} + a_{3}*x{t-3} + ... + a_{k}*x{t-k} \\ 而非:\\ 从上述过程可以看出,使用pacf_ols时,系数的解ak来自:xt=a1∗xt−1+a2∗xt−2+a3∗xt−3+...+ak∗xt−k而非:
x t = a 1 ∗ x t − 1 + a 2 ∗ x t − 2 + a 3 ∗ x t − 3 + . . . + a k ∗ x t − k x t − 1 = a 1 ∗ x t − 1 − 1 + a 2 ∗ x t − 1 − 2 + a 3 ∗ x t − 1 − 3 + . . . + a k ∗ x t − 1 − k x t − 2 = a 1 ∗ x t − 2 − 1 + a 2 ∗ x t − 2 − 2 + a 3 ∗ x t − 2 − 3 + . . . + a k ∗ x t − 2 − k . . . x k = a 1 ∗ x k − 1 + a 2 ∗ x k − 2 + a 3 ∗ x k − 3 + . . . + a k ∗ x 0 x_{t} = a_{1}*x_{t-1} + a_{2}*x_{t-2} + a_{3}*x_{t-3} + ... + a_{k}*x_{t-k} \\ x_{t-1} = a_{1}*x_{t-1-1} + a_{2}*x_{t-1-2} + a_{3}*x_{t-1-3} + ... + a_{k}*x_{t-1-k} \\ x_{t-2} = a_{1}*x_{t-2-1} + a_{2}*x_{t-2-2} + a_{3}*x_{t-2-3} + ... + a_{k}*x_{t-2-k} \\ ... \\ x_{k} = a_{1}*x_{k-1} + a_{2}*x_{k-2} + a_{3}*x_{k-3} + ... + a_{k}*x_{0} \\ xt=a1∗xt−1+a2∗xt−2+a3∗xt−3+...+ak∗xt−kxt−1=a1∗xt−1−1+a2∗xt−1−2+a3∗xt−1−3+...+ak∗xt−1−kxt−2=a1∗xt−2−1+a2∗xt−2−2+a3∗xt−2−3+...+ak∗xt−2−k...xk=a1∗xk−1+a2∗xk−2+a3∗xk−3+...+ak∗x0
pacf_ols的计算方式与http://www-stat.wharton.upenn.edu/~steele/Courses/956/ResourceDetails/YWSourceFiles/YW-Eshel.pdf 中描述的不同
pacf_yule的计算
pacf_yw(a_mean, nlags=1, method='mle')
array([1. , 0.4])
yule_walker(a_mean, 1, method='mle')
(array([0.4]), 1.296148139681572)
参考文献中:
一阶系数
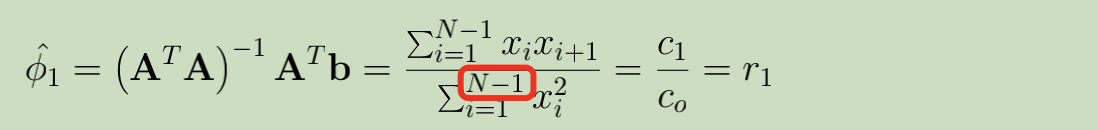
参考文献中,分母为
∑
i
=
1
N
−
k
x
i
2
\sum_{i=1}^{N-k}{x^2_{i}}
∑i=1N−kxi2
pacf_yule中分母为
∑
i
=
1
N
x
i
2
\sum_{i=1}^{N}{x^2_{i}}
∑i=1Nxi2
问题
相关资料上都有这样的描述:
”PACF相当于在计算X(t)和X(t-h)的相关性的时候,挖空在(t-h,t)上所有数据点对X(t)的影响,去反映X(t-h)和X(t)之间真正的相关性“
怎么理解𝑌𝑢𝑙𝑒−𝑊𝑎𝑙𝑘𝑒𝑟方程或最小二乘计算出来的系数是挖空了(t-h,t)上所有数据点对X(t)的影响的?
𝑌𝑢𝑙𝑒−𝑊𝑎𝑙𝑘𝑒𝑟或最小二乘的计算结果是一样的。𝑌𝑢𝑙𝑒−𝑊𝑎𝑙𝑘𝑒𝑟方程的提出为了优化计算过程,减少计算量
单从pacf的计算方式看,
p
a
c
f
k
pacf_{k}
pacfk就是第k阶的自回归系数。所谓的‘挖空了(t-h,t)上所有数据点对X(t)的影响’,指的是做自回归
x
i
+
1
=
φ
1
x
i
+
φ
2
x
i
−
1
+
⋅
⋅
⋅
+
φ
p
x
i
−
p
+
1
+
ξ
i
+
1
x_{i+1} = φ_{1}x_{i} + φ_{2}x_{i-1} + · · · + φ_{p}x_{i-p+1} + ξi+1
xi+1=φ1xi+φ2xi−1+⋅⋅⋅+φpxi−p+1+ξi+1 时,将x_{i-1}到x_{i-k}都视作因变量
p a c f k = φ k pacf_{k} = φ_{k} pacfk=φk
参考:
http://www-stat.wharton.upenn.edu/~steele/Courses/956/ResourceDetails/YWSourceFiles/YW-Eshel.pdf

















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









