






在下载懂车帝视频的时候,我们需要实时进度条,这可以帮助我们更直观的看到视频的下载进度
正在上传…重新上传取消
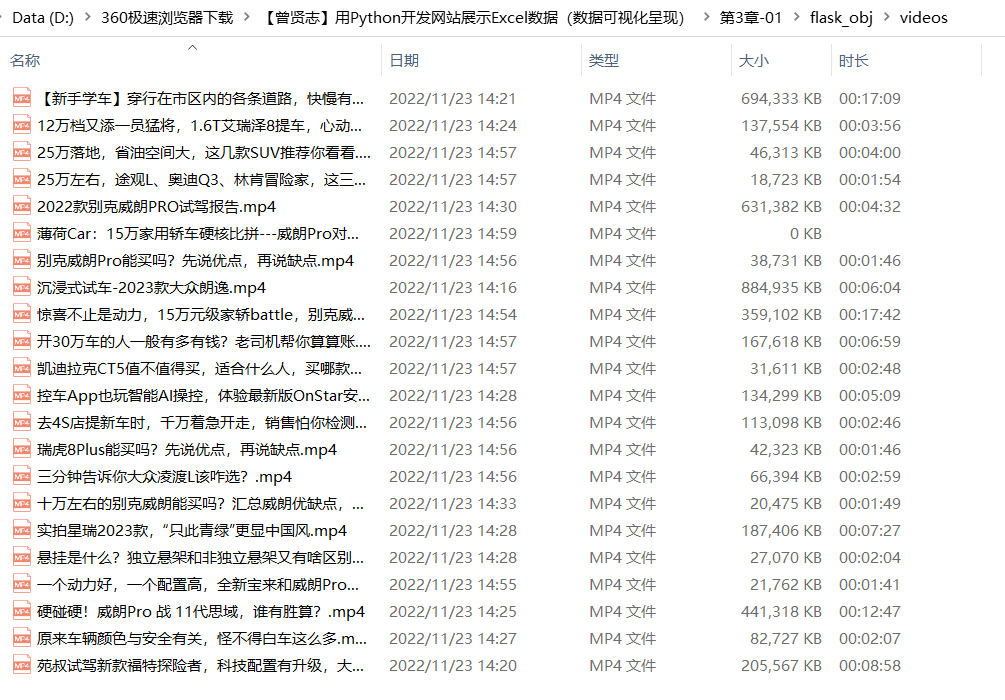
下载好的视频。如下图所示
具体实现步骤,概括起来主要有两点:
-
cookie绕过登录过程
-
tqdm可视化显示下载进度
进度条的文章python技术公众号我记得是发过的,但是半年前的文章了,怎么找方便呢?
这时我们上周爬的200篇公众号文章就发挥作用了:
http://ssw.fit/ 阅览室-公众号,搜索“进度条”
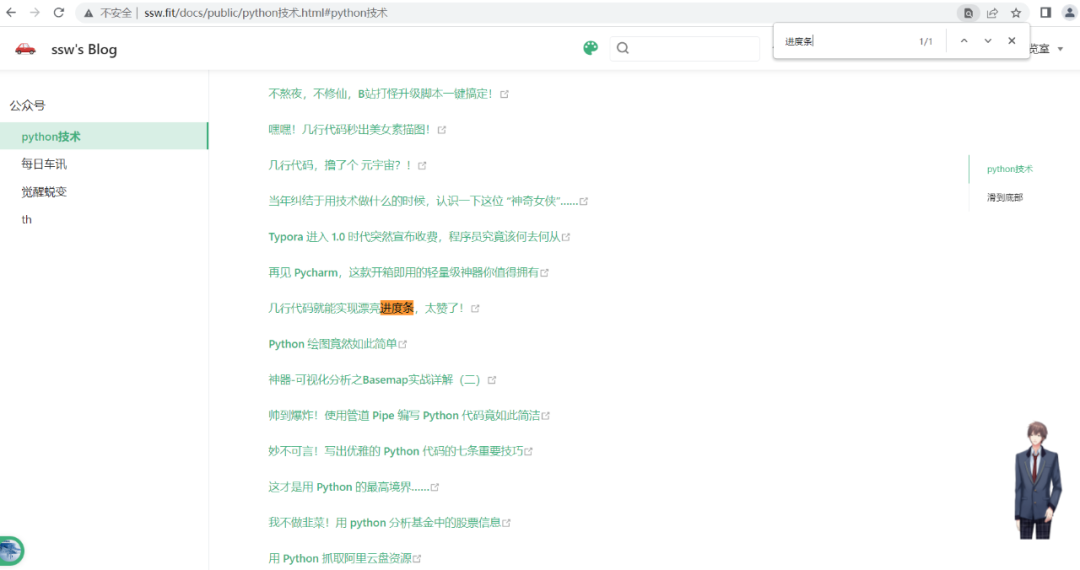
不难发现,《几行代码就能实现漂亮进度条,太赞了!》早已介绍过,有了这篇内容就好办了。
下面开始让python帮我们干活。
cookie绕过登录过程
按F12或通过鼠标右键检查,可以看到cookie

视频页面的唯一标识符,通过cookie获取,就是下面这串数字
正在上传…重新上传取消
代码如下
import requests
import json
headers = {
"cookie":"appmsglist_action_3889613222=card; ua_id=Q1Dfu2THA6T9Qr1HAAAAAN_KYa5xTwNmiuqj1Mkl6PY=",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"
}
def parser():
video_list = []
rep=requests.get('https://www.dongchedi.com/motor/pc/user/collect/list?count=40&cursor=0&content_type=1',timeout=5,headers=headers)
rep.encoding='utf-8'
for item in json.loads(rep.text)['data']['data']:
video_list.append('https://www.dongchedi.com/video/'+item['gid'])
print(video_list)
运行上面的脚本,得到收藏的视频url合集
['https://www.dongchedi.com/video/7150286063049802270', 'https://www.dongchedi.com/video/7161306839810998815',
...]
但它们并不是真正的视频地址,实际地址位于vedio标签的src属性
正在上传…重新上传取消
接下来就要去获取这些视频链接,我们用scrapy对这些url发送请求。
将url合集放到scrapy的start_urls中,通过xpath获取视频地址:
class VedioSpider(scrapy.Spider):
name = 'vedio'
start_urls = ['https://www.dongchedi.com/video/7150286063049802270', 'https://www.dongchedi.com/video/7161306839810998815',...]
def parse(self, response):
global vedio_dict
html =etree.HTML(response.text)
#视频标题
title = html.xpath('//*[@id="__next"]/div[1]/div/div/div/div[2]/div/div[1]/h1/text()')[0].strip()
#视频地址,@src获取vedio标签的src属性
x = html.xpath('//*[@id="__next"]/div[1]/div/div/div/div[1]/div[1]/div/div[1]/div/div/div/video/@src')
vedio_dict[title] = x[0]
print(vedio_dict)
输出得到标题和视频地址:
正在上传…重新上传取消
到这里我们已经成功了三分之二,接下来用一个炫酷的进度条
可视化显示下载进度
视频文件过大,立即下载会导致内存不足,设置requests的stream参数为True
设置成True时,它不会立即开始下载,使用iter_content或iter_lines遍历内容或访问内容属性时才开始下载。
import os
import requests
from tqdm import tqdm
VIDEO_PATH = r'videos'
def download(url,fname):
# 用流stream的方式获取url的数据
resp = requests.get(url, stream=True)
total = int(resp.headers.get('content-length', 0))
with open(fname, 'wb') as file, tqdm(
desc=fname,
total=total,
unit='iB',
unit_scale=True,
unit_divisor=1024,
) as bar:
for data in resp.iter_content(chunk_size=1024):
size = file.write(data)
bar.update(size)
if __name__ == "__main__":
vedio_dict = {'沉浸式试车-2023款大众朗逸': 'https://vxtos', '苑叔试驾新款福特探险者,科技配置有升级,大车也有操控感': 'https://v3-default',}
for video_name, url in vedio_dict.items():
video_full_path = os.path.join(VIDEO_PATH,"%s.mp4" % video_name)
download(url, video_full_path)
我的网速比较快,平均3M/s,5G视频很快就下载好了!















 4776
4776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









