







 本文讲述了在节能环保企业的项目中,利用图像识别技术,特别是LPRNet进行车牌识别,将其部署到边缘计算设备以实现无人值守洗车房的自动支付功能。通过迁移学习优化模型,以及整合YOLO定位和数据库验证,确保系统的准确性和安全性。
本文讲述了在节能环保企业的项目中,利用图像识别技术,特别是LPRNet进行车牌识别,将其部署到边缘计算设备以实现无人值守洗车房的自动支付功能。通过迁移学习优化模型,以及整合YOLO定位和数据库验证,确保系统的准确性和安全性。
项目背景
学电子信息的你加入了一家节能环保企业,公司的主营产品是节能型洗车房。由于节水节电而且可自动洗车,产品迅速得到了市场和资本的认可。公司决定继续投入研发新一代产品:在节能洗车房的基础上实现无人值守的功能。新产品需要通过图像识别检测出车牌号码,车主通过扫码支付后,洗车房的卷帘门自动开启。新产品的研发由公司总工亲自挂帅,他对团队寄予厚望,作为人工智能训练师,你被分在图像识别团队。项目经理为你提供了数百张原始车牌图片,并配备了一位资深算法工程师为你提供预训练模型,要求你在硬件设计定稿打样之前,完成车牌识别的模型训练,能够识别京牌车号,并部署到边缘计算设备上测试通过。为了给后续实际上线工作提供可靠的基础,你的工作需要在一周内完成,请尽快开始。
分析项目
项目中需要我们通过图像识别能够检测出京牌车号,既然是图像识别,那就离不了cnn,而且里面还有一个要求是部署到边缘计算设备上,那么我们的网络及模型对硬件算力的要求就不能太高。这里我先想到的了LeNet,它输入数据大小是32*32的,也就是说拿到一张车牌图片,需要有以下步骤:切分图片、依次传入网络识别、拼接输出结果。
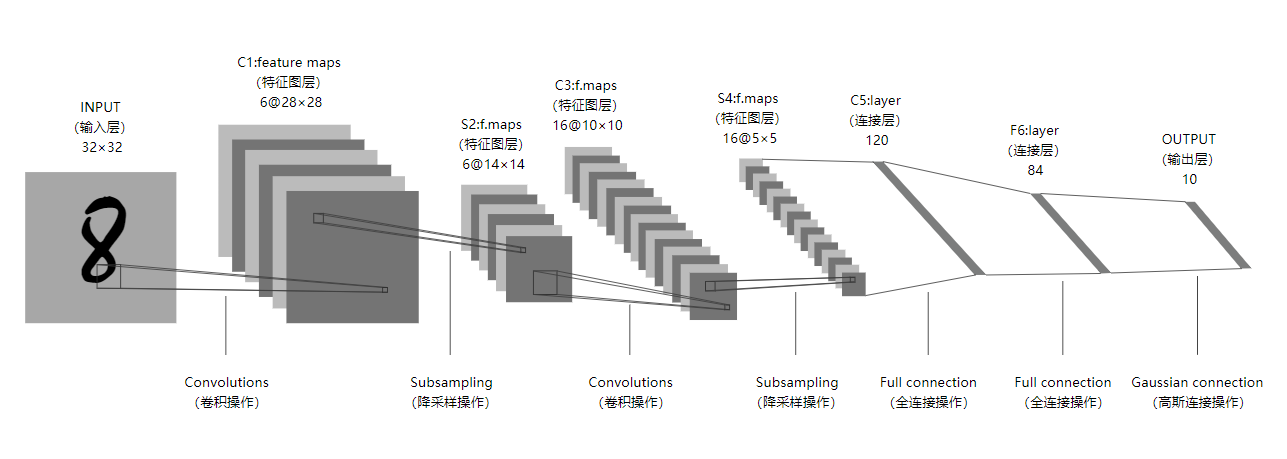 LeNet网络结构图
LeNet网络结构图
内心:“哦?就这三步骤?分分钟搞完。开始第一步:切分图片,好的第一步不会,项目崩溃“
后两步还好,难就难在切分图片,切分依据是什么?如何编写切分程序?切分程序能否在大多数据集上表现效果好?
🤔难道就要放弃了吗,要放弃了吗,真的要放弃了吗,不!我还有大招。之前参加过一个比赛也是关于车牌识别检测的,它给的数据集车牌图片是人在路边拍的,需要先裁剪出车牌图片再进行识别,记得当时做那个项目用了Yolo7 和 paddleocr这两个开源技术。不过这个洗车房项目里只要求了完成识别所以就免去第一步了,直接对车牌去进行识别。好的,识别这里我用LPRNet代替paddleocr
为什么要用LPRNet呢?原因如下:
- LPRNet模型大小仅有1.8兆,非常轻量
- LPRNet也是上次比赛中学习到的,那会我也去尝试了几遍,可是我测试集的识别准确率就是很低,那个博主的准确率高达97%,不服绝对不服,一定是我上次的打开方式不对哈哈哈哈,带着上次的不解与困惑让我再试一次
那最终就确立LPRNet为本次项目的主体
项目流程
搭建项目
1.部署LPRNet到本地
下载LPRNet
LPRNet下载地址 https://github.com/sirius-ai/LPRNet_Pytorch
https://github.com/sirius-ai/LPRNet_Pytorch
安装模块
README文件里有说

跑通测试代码
data文件夹下自带了1000张测试图片,运行项目根目下的 test_LPRNet.py 尝试跑通
test_LPRNet.py中的 show函数会起到一个阻塞作用,可以将参数show置为False

但直接将show置为False后,就不会展示以下每张图片的预测效果
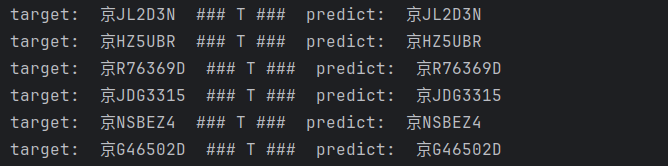
若想看到预测效果可以在show函数内部进行部分注释,show参数那要置为True
2.LPRNet项目分析
总的来看,这个项目是比较简单的,代码只有这4个文件
- load_data.py
- LPRNet.py
- test_LPRNet.py
- train_LPRNet.py
现在我想知道的是它的输入图片大小、标签格式
load_data.py中有resize方法,且与test_LPRNet.py、train_LPRNet.py相关联,表示当我的图片像素大小不为94*24的时候,会调用该方法重置图片大小。(它不会覆盖原有输入数据集的图片,只会使输入其他大小的图片不会报错)
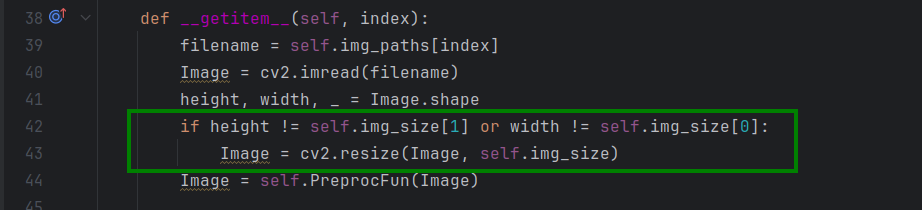
标签的格式即图片文件名
LPRNet网络结构,直接看代码会比较难理解,可以结合图片去看
使用以下代码得到可视化onnx模型,导入到网页 https://netron.app/
from LPRNet import build_lprnet
import torch
lprnet = build_lprnet(lpr_max_len=8, phase=True, class_num=68, dropout_rate=0.5)
device = torch.device("cuda:0" if torch.cuda else "cpu")
lprnet.to(device)
print("Successful to build network!")
inputs = (1, 3, 24, 94)
input_data = torch.randn(inputs).to(device)
torch.onnx.export(lprnet, input_data, 'lpr.onnx')3.准备数据集
我用的数据集是CBLPRD-330k,用代码将里面为京牌的图片提取出来,有9000多张
import logging
import random
import os
import shutil
# 需要修改为自己的实际路径
datas = open('../data.txt', 'r').readlines()
total = len(datas)
# random.shuffle(datas)
print('开始过滤数据····')
jing = []
blue = []
green = []
for data_txt in datas:
directory, licen, color = data_txt.split()
if licen[0] == '京':
if not licen[1].isdigit():
if not licen[-1] == '挂':
if not licen[-1] == '学':
print(licen)
if len(licen) == 7:
blue.append(licen)
elif len(licen) == 8:
green.append(licen)
else:
logging.warning(len(licen))
jing.append(licen)
new_dir = '京/' + licen + '.jpg'
shutil.copy(os.path.join('../', directory), new_dir)
print('total:', len(jing))
print('blue:', len(blue))
print('green:', len(green))
划分数据集(train、test)
import shutil
import random
from tqdm import tqdm
import os
directory = 'data'
datas = os.listdir(directory)
random.shuffle(datas)
total = len(datas)
# 90 10
train_data = datas[:int(0.9 * total)]
test_data = datas[int(0.9 * total):]
if not os.path.exists('train'):
os.mkdir('train')
if not os.path.exists('test'):
os.mkdir('test')
for data in tqdm(train_data):
licen, suffix = data.split('.')
new_dir = 'train/' + licen + '.' + suffix
shutil.copy(os.path.join(directory, data), new_dir)
print('exec train over')
for data in tqdm(test_data):
licen, suffix = data.split('.')
new_dir = 'test/' + licen + '.' + suffix
shutil.copy(os.path.join(directory, data), new_dir)
print('exec test over')4.训练模型
8000多张训练集,试着跑了一下,效果特别差,所以这里要用迁移学习思想
tips:比赛那次及刚刚尝试的识别度低的原因就是没有用迁移学习,全部参数传入,随着训练的进行,模型中的可学习参数层的参数都发生改变导致的🤧
- 将weights目录下自带的Final_LPRNet_model.pth重名为Pre_LPRNet_model.pth,将参数pretrained_model指定为预训练模型Pre_LPRNet_model.pth

- 冻结网络主干部分,仅训练输出层

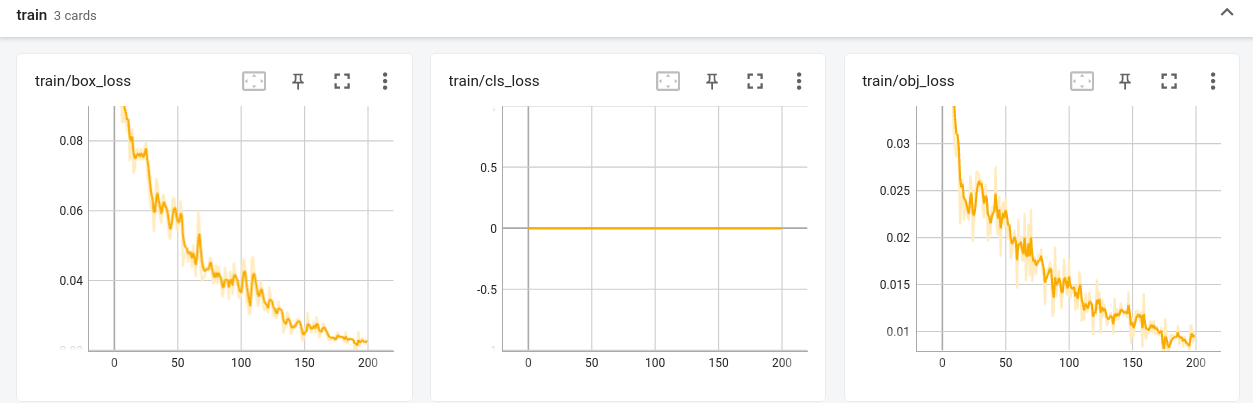
# 将不更新的参数的requires_grad设置为False for name, param in lprnet.backbone.named_parameters(): param.requires_grad = False # 仅把需要更新的模型参数传入optimizer optimizer = optim.RMSprop(lprnet.container.parameters(), lr=args.learning_rate, alpha=0.9, eps=1e-08,momentum=args.momentum, weight_decay=args.weight_decay) - (可选)使用tensorboard将训练过程可视化
from torch.utils.tensorboard import SummaryWriter # 加入到训练的地方(咱这只加入了loss,可以查看loss的变化图) writer.add_scalar('loss', scalar_value=loss.item(), global_step=epoch) writer.close() # 可以定义在 if __name__ == "__main__": 里 writer = SummaryWriter()
指定参数,绿色箭头表示一些常用的参数
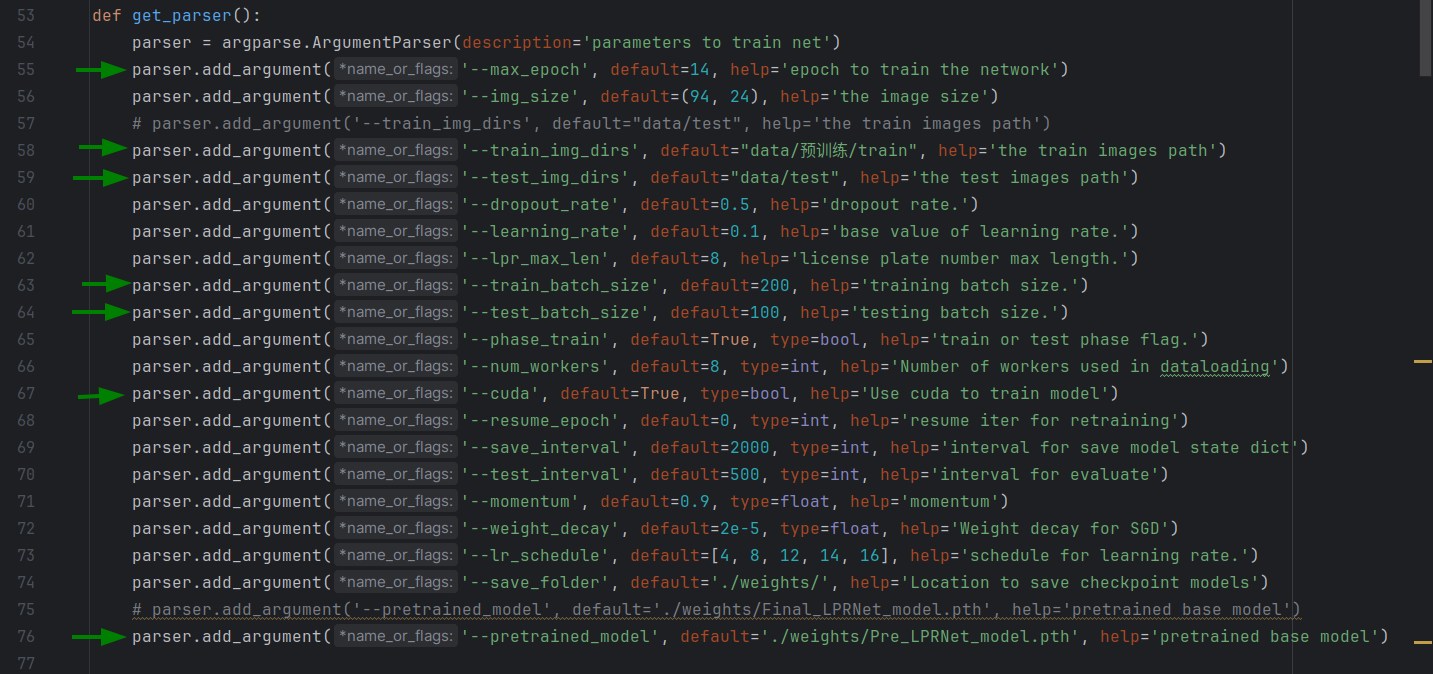
运行train_LPRNet.py进行训练
5.测试
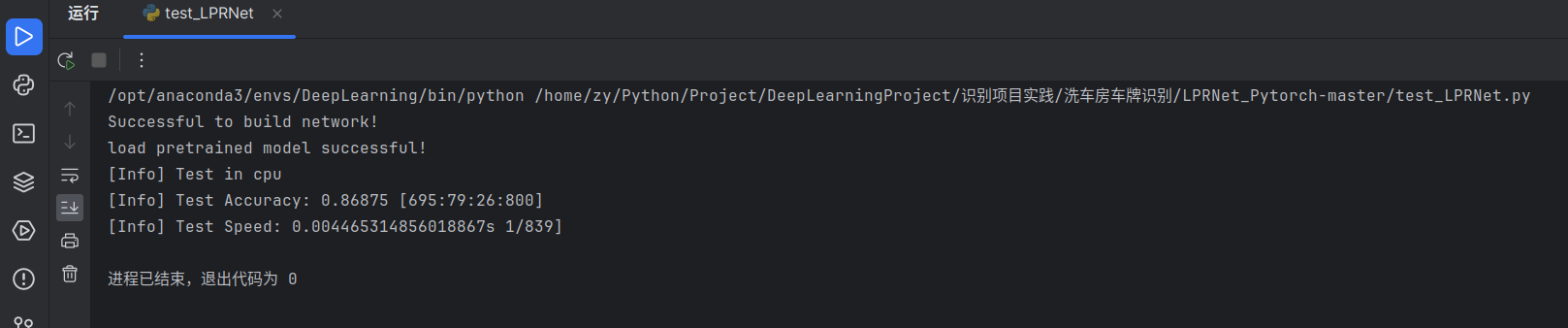
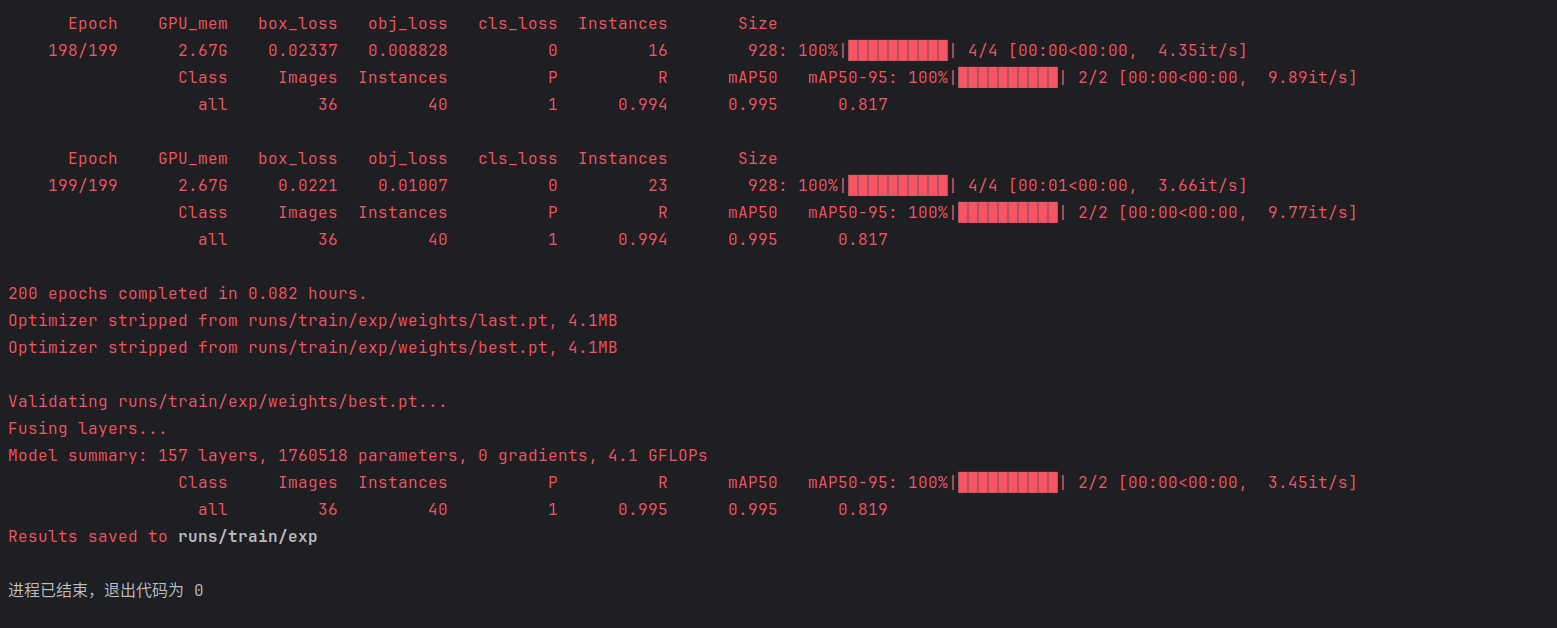
我这里训练了14轮
测试得到的效果:800多张图片总准确率在86%~87%,cpu上识别一张图片的速度为4~5毫秒
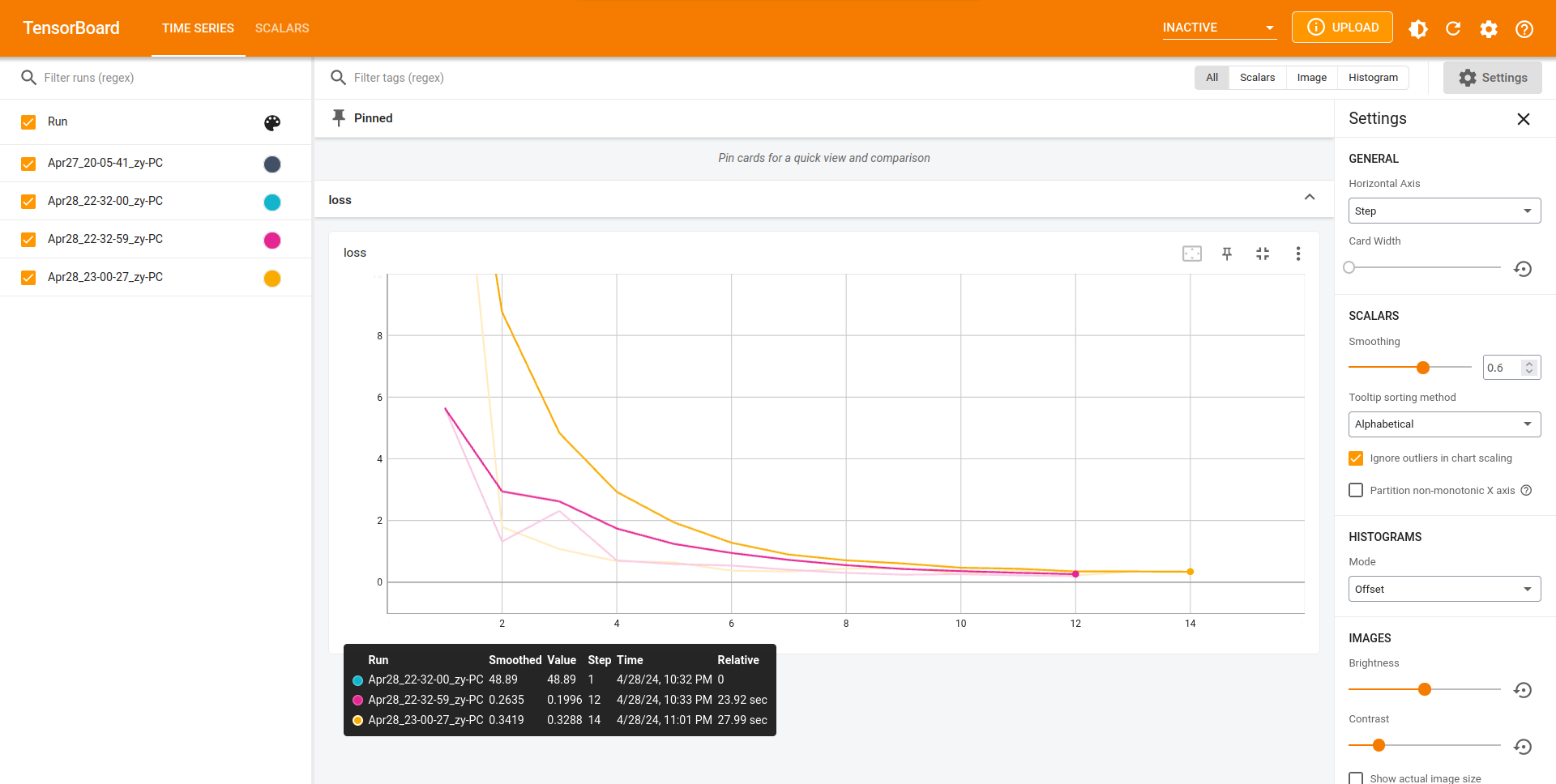
在15轮之后,loss值会反弹的很厉害,效果会变差
项目总结
通过这个项目,又学到了一些新的东西,巩固实践了旧的知识。还有就是写这个总结挺费劲的,写总结花费的时间比我做项目的时间还要久···· 开玩笑嘻嘻嘻~

项目拓展
以下是我在对该项目的理解基础上结合一些想法加以的改造
拓展一
洗车房项目所使用的数据集图像大小全部为128 * 48,这种图片相当于贴脸拍了

现在的需求:当给到一张大图片的时候,也能够识别出来、识别准确。
就是说,我现在拿自己手机去外面拍一张,只要这张照图片里有车牌都要能够识别到
这就需要使用YOLO先对目标(车牌)进行定位,再通过LPRNet识别,好!开整!
1.训练车牌识别模型
这次我用yolov5来做,就不写那么详细了,类似的训练详解我之前博客有可以去看
数据有限,网上找了36张图片标注训练,15张图片测试

测试图片

测试视频
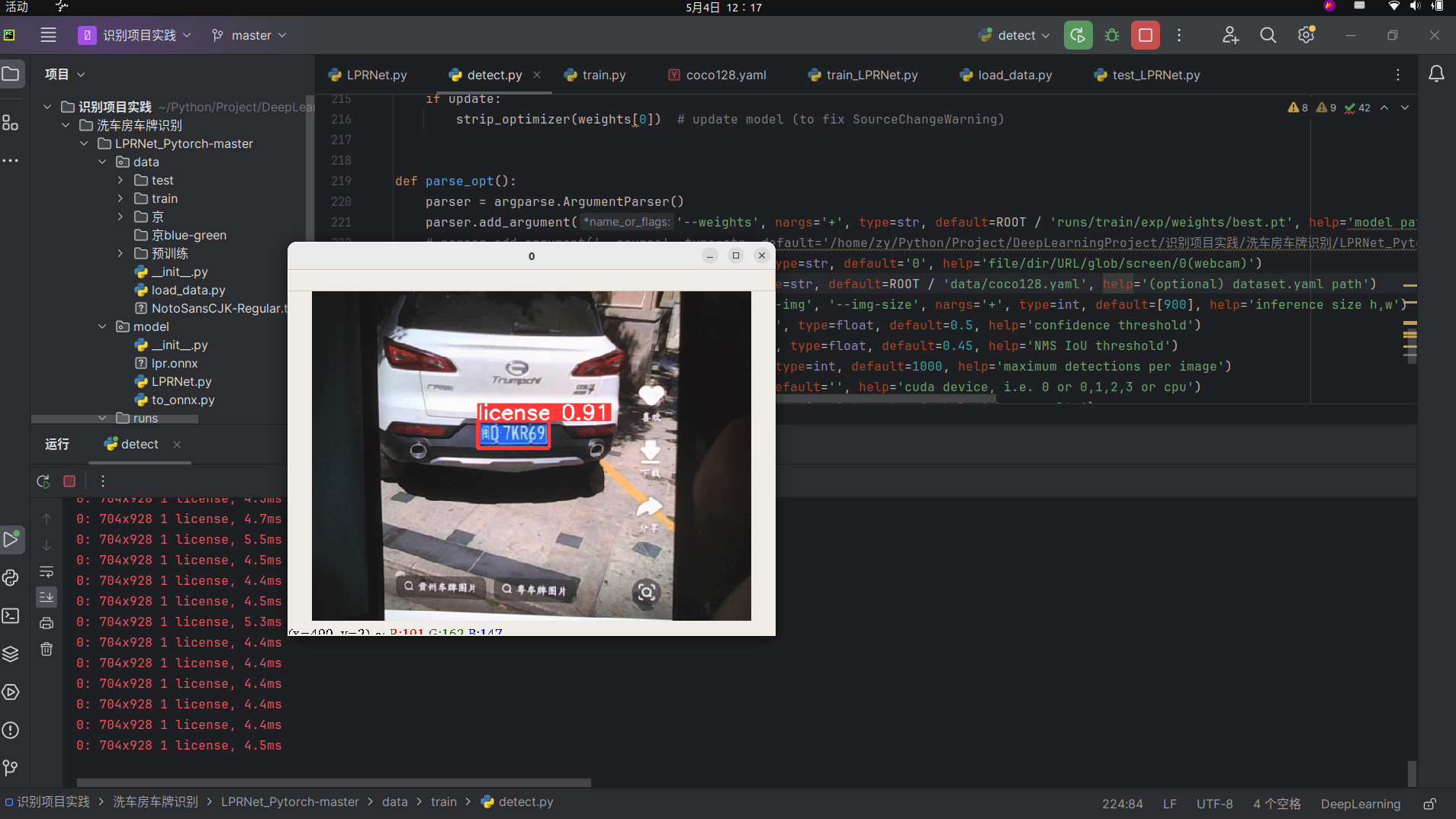
有车牌识别模型了,看上去效果还不错
2.把LPRNet加入到yolov5的detect.py中
改了一下午,此时00:10终于完成啦!现在可识别图片也可以识别视频流,而且可以显示中文哦!
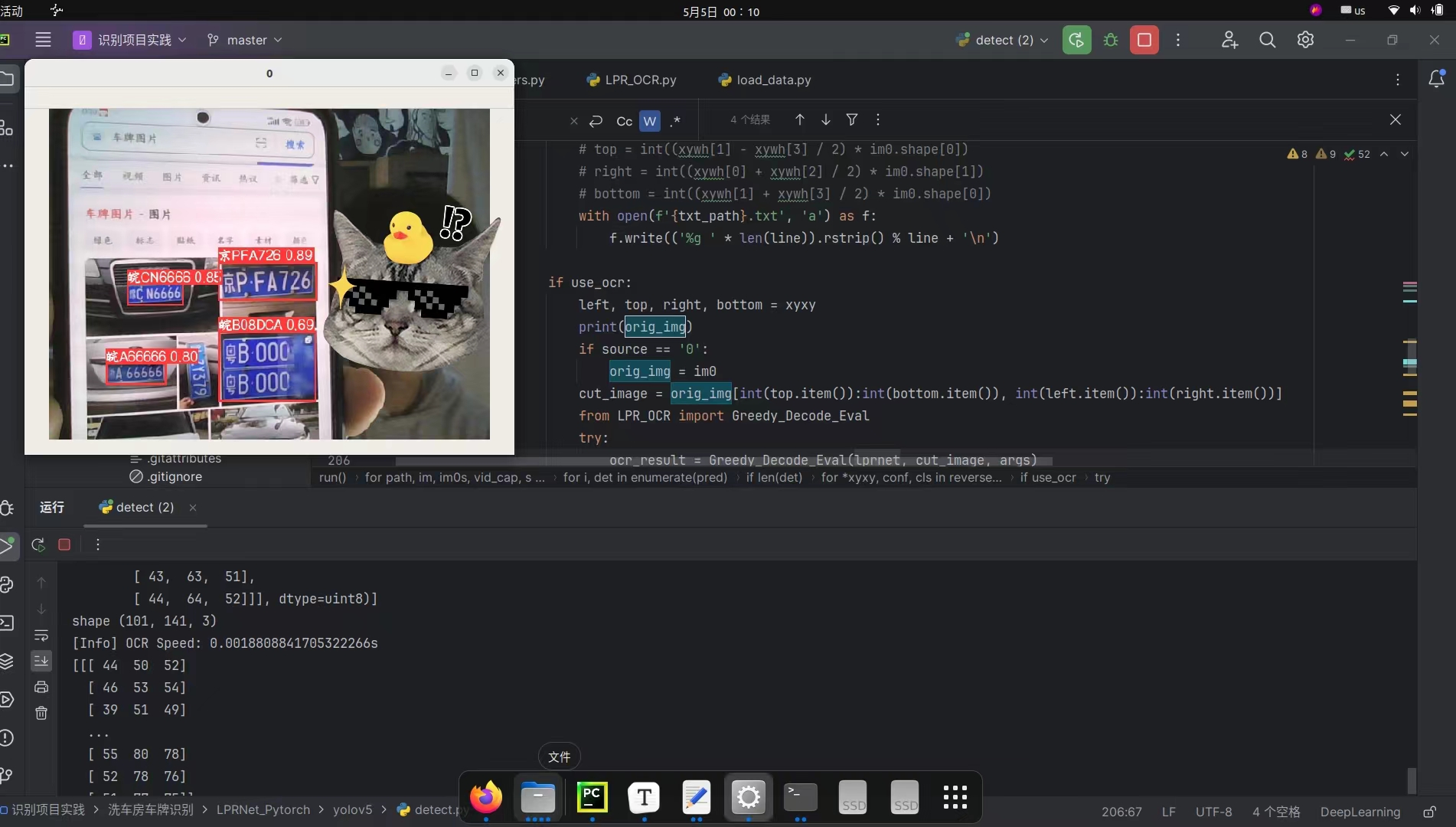
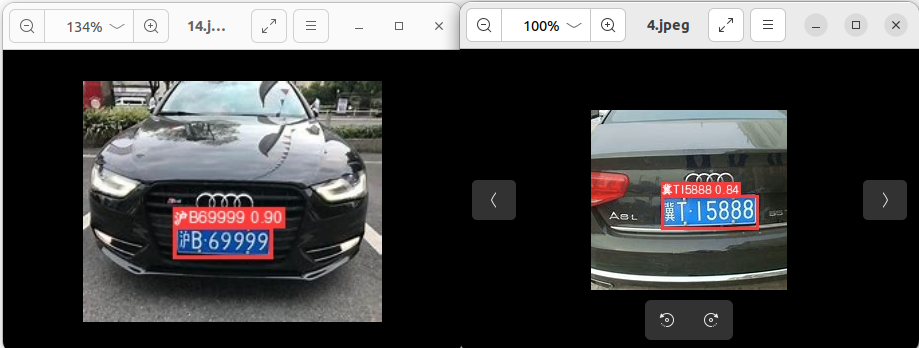
由于detect.py代码篇幅较长,改动的地方解释起来不是很好理解,也怕误导读者,所以就不在此解读了,如果你们对这个拓展感兴趣,等我整理好后会放到我的github主页
拓展二
既然是无人值守的洗车房,那应该也要具有一定的安全性
我有个想法是给它加一道“闸”,就是必须要同时识别到车牌和车身的情况下,才可以进入支付环节,继而打开卷帘门,而不是随便拿一张车牌图片就可以糊弄过去。好理解的说法就是:如果你没有开车来洗车,那咱洗车房就可以理解为你不是诚心来洗车的,继而不会产生订单、打开卷帘门
好,开整!
1.训练识别模型
和前面不同的是:
- 这次有两个类别
- 加入了一些噪声(增强模型鲁棒性)
- 数据集500张(train:401, val:99)
现在是5月17日 16:45分,开始上演狂飙(标)了
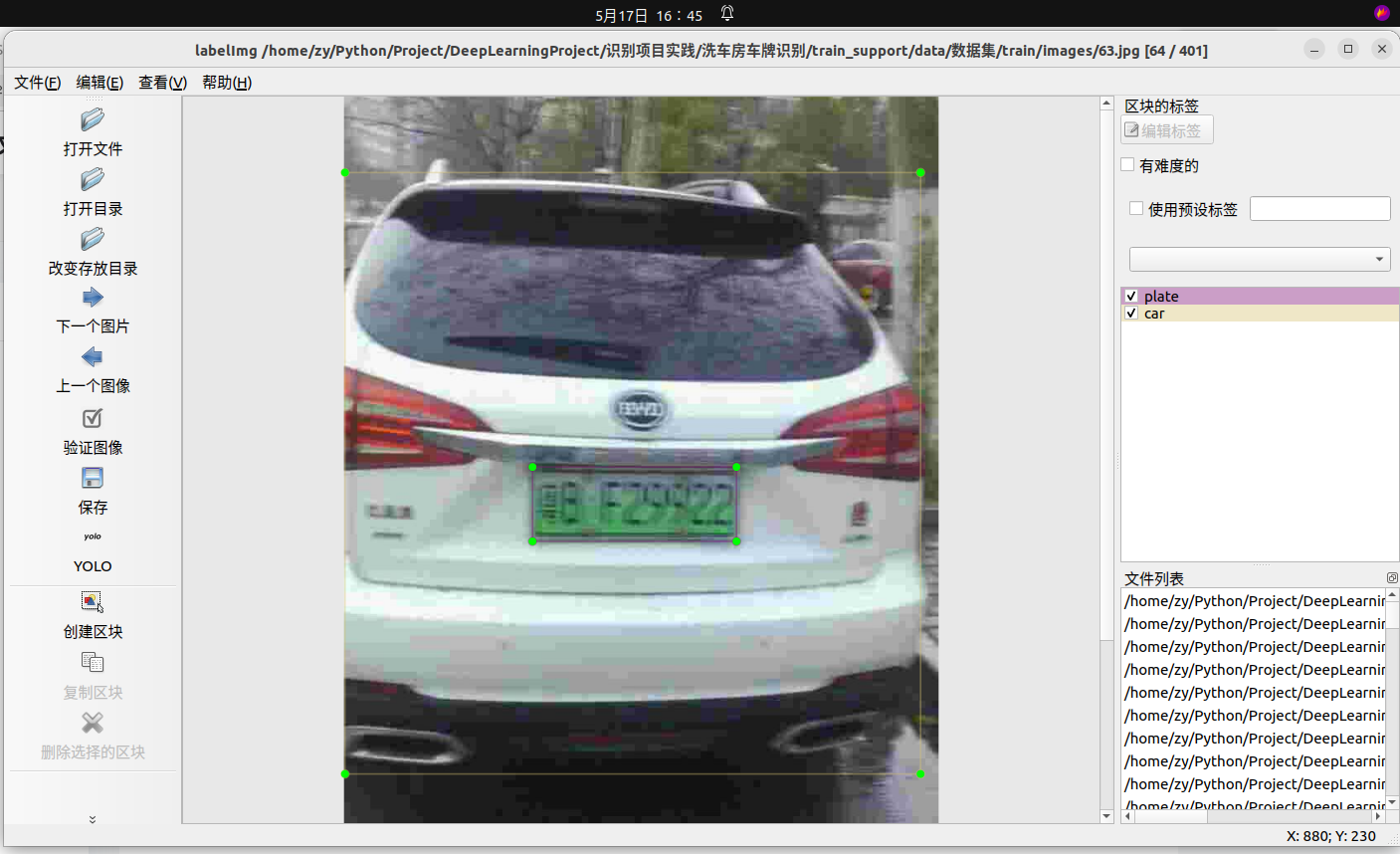
狂标中···

现在5月17日 20:59分,标注工作完了,中间还去吃了个饭嘻嘻,开始训练了,N卡加速中-->>>
训练的这50轮,咱来看下效果
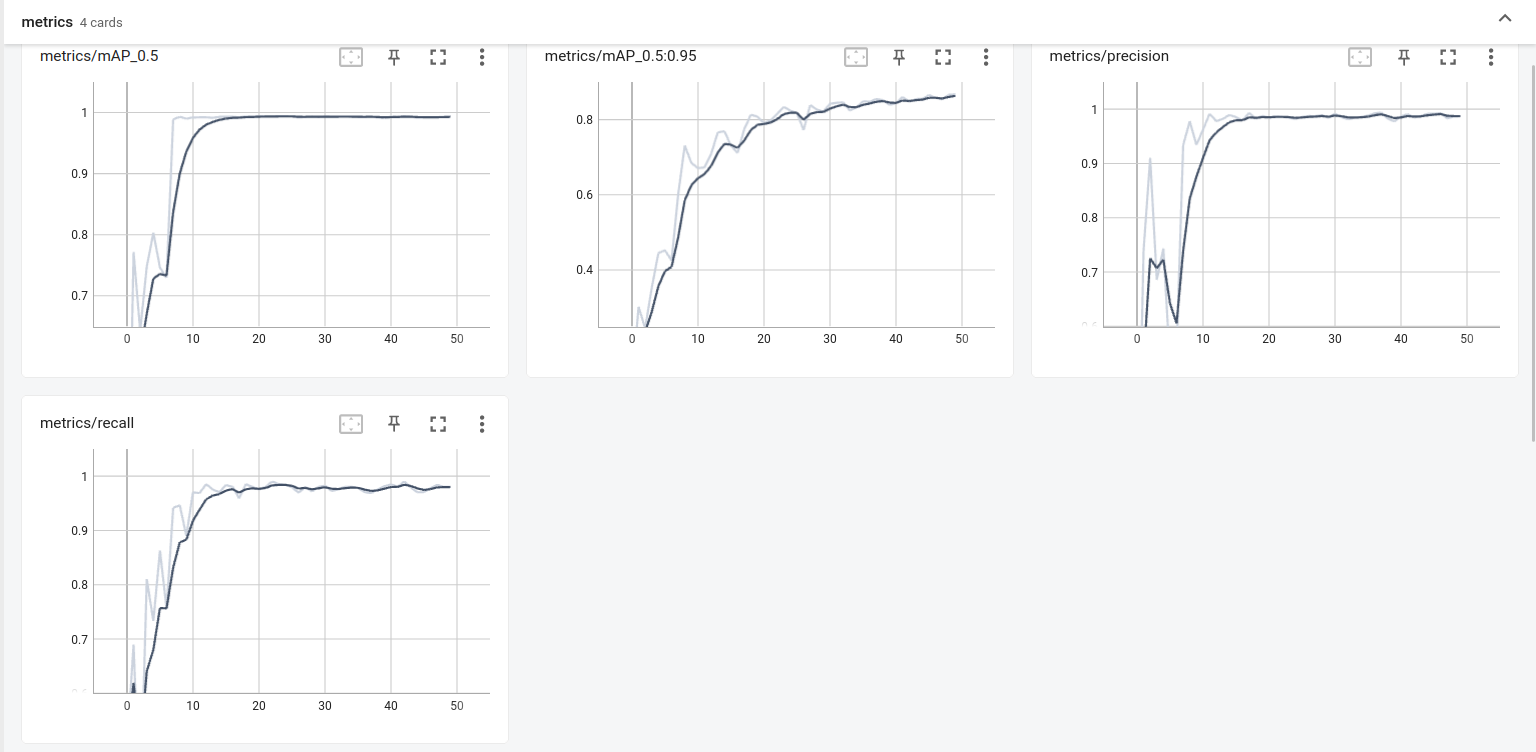
召回率、精度还是不错的

损失函数随着轮数的增加也在收敛,感觉还行哈
上测试集试一下
准备了400张测试图片,发现这类型的图片效果是好的,置信度都是比较高的

换张训练集里没有的拍摄角度的图片,置信度也还行



这种角度的图片置信度低了很多,不过没关系,咱洗车房主要是能识别正面抓拍的车身和车牌即可
现在把这个模型用到咱的项目里
测试一下,是这样的效果

正常,因为此时代码是把框出的所有图像都传入LPR,所以需要修改代码不传入类别为car的框
2.修改detect.py
推理部分大概在148行
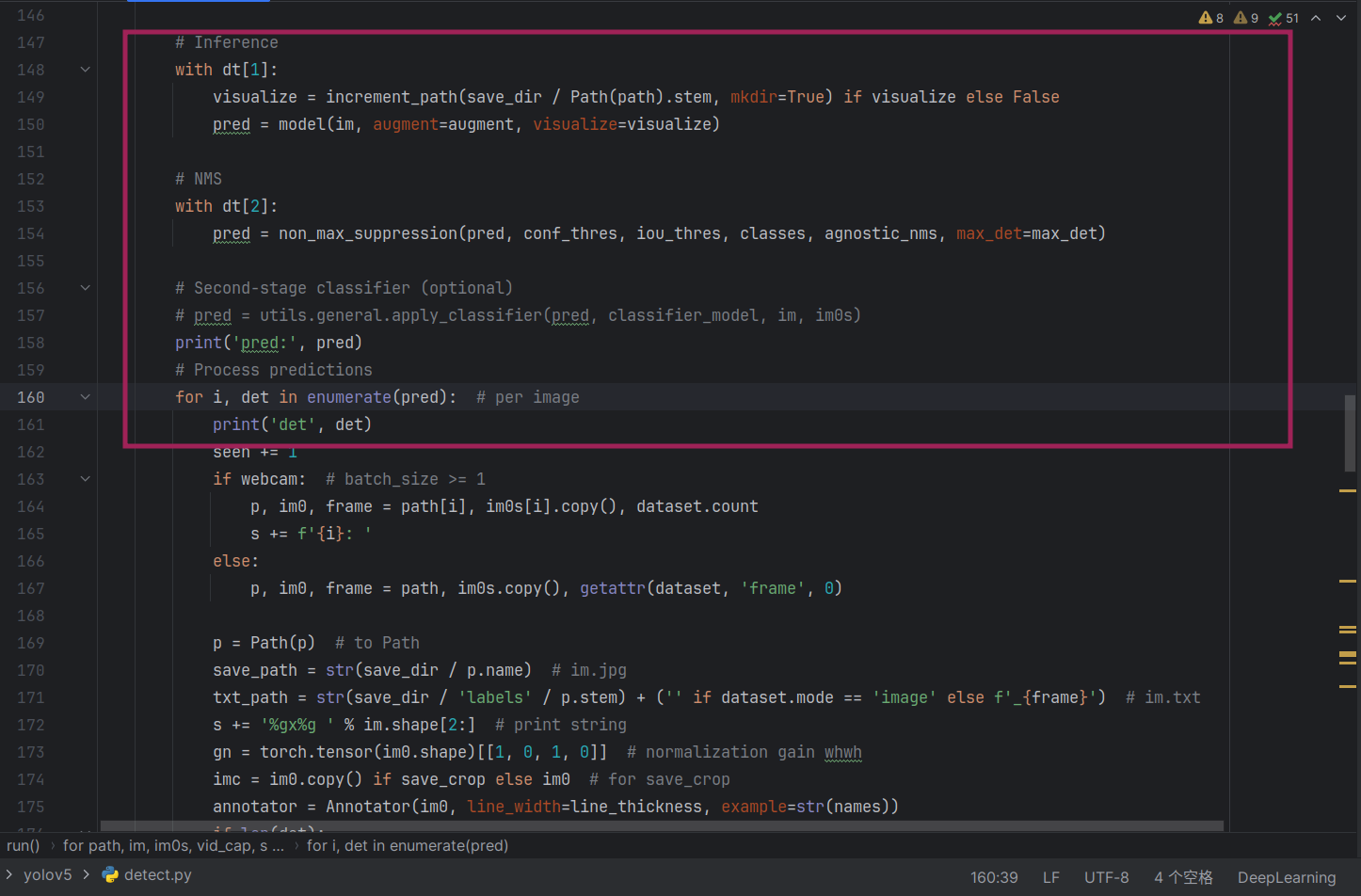
先来打印一些变量看看
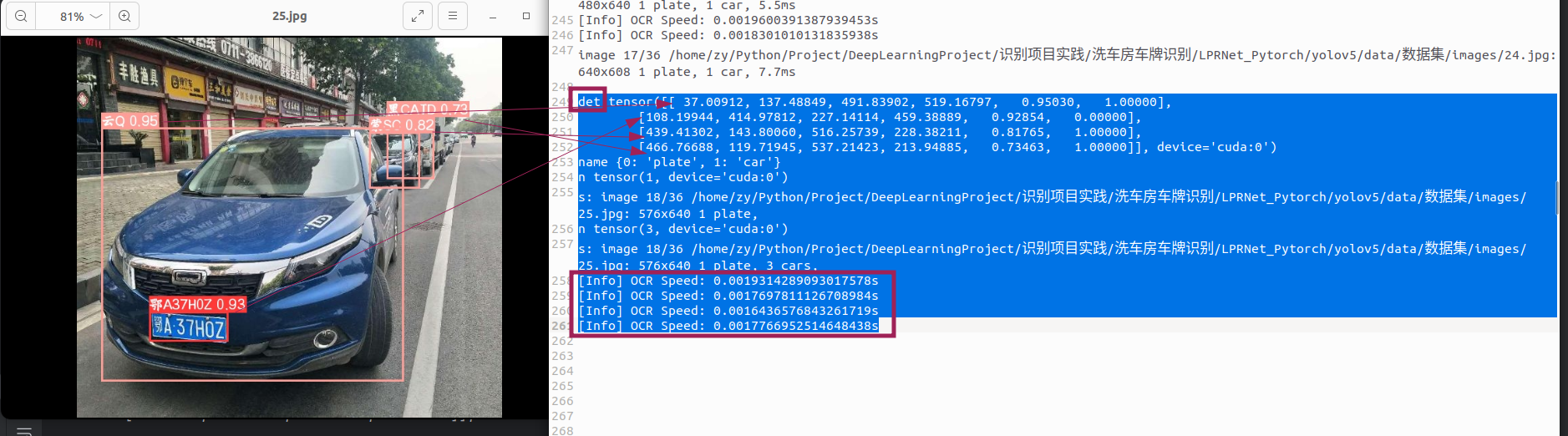
我把一个具有代表性的输出结果粘贴出来了,可以看到预测的结果被存在了一个名为det的tensor张量里(4行数据,对应图中的4个框,且lpr被调用了4次)咱的需求是不把类别为car的框传入lpr,只传入类别为plate的框。不过det里面结果的顺序好像跟识别类别没有关系,那再往后看看
OK就是这里了,先分析!!!
- 想要保留原来的单独识别框的功能
- 逻辑不要太复杂
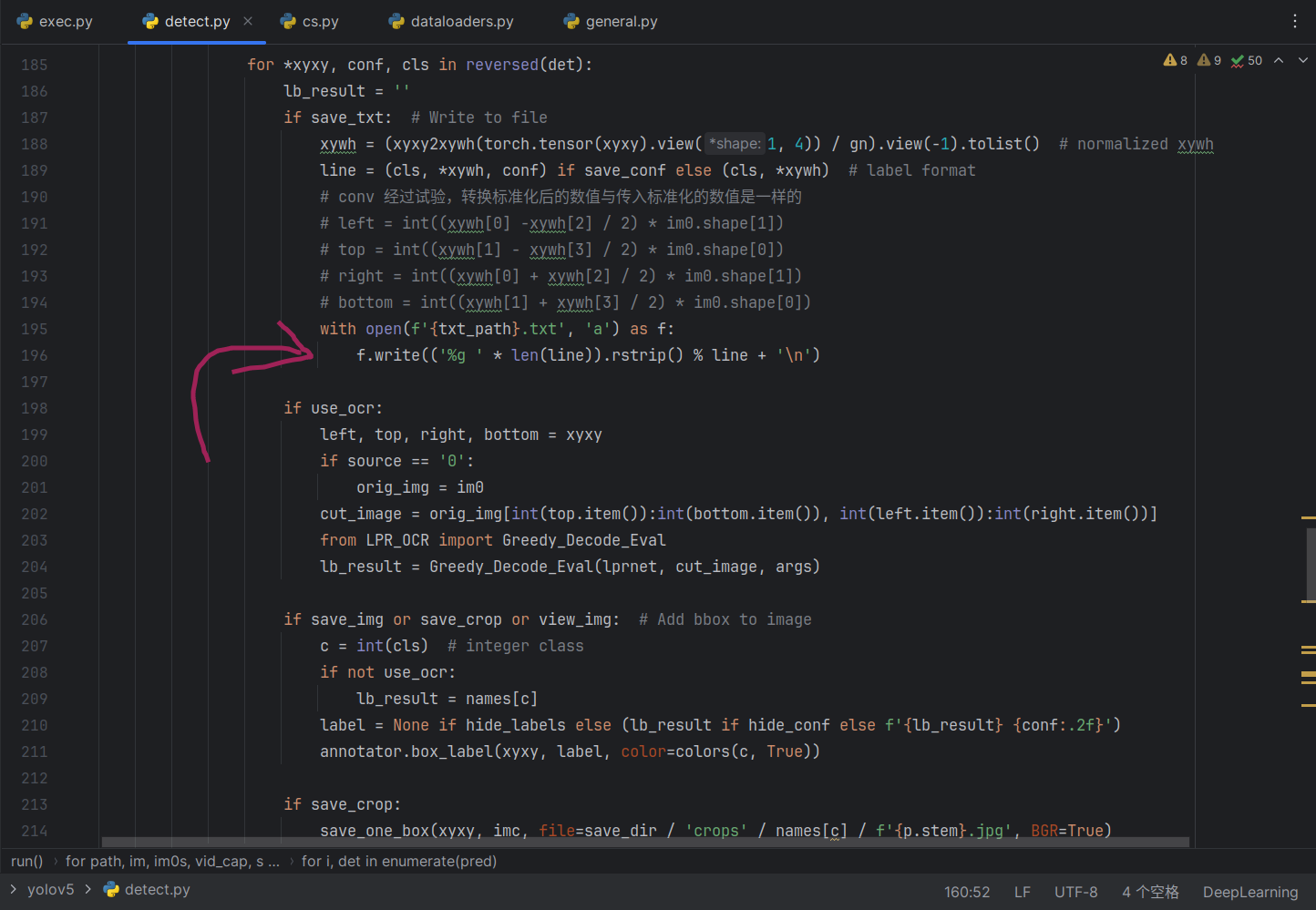
改完后的:
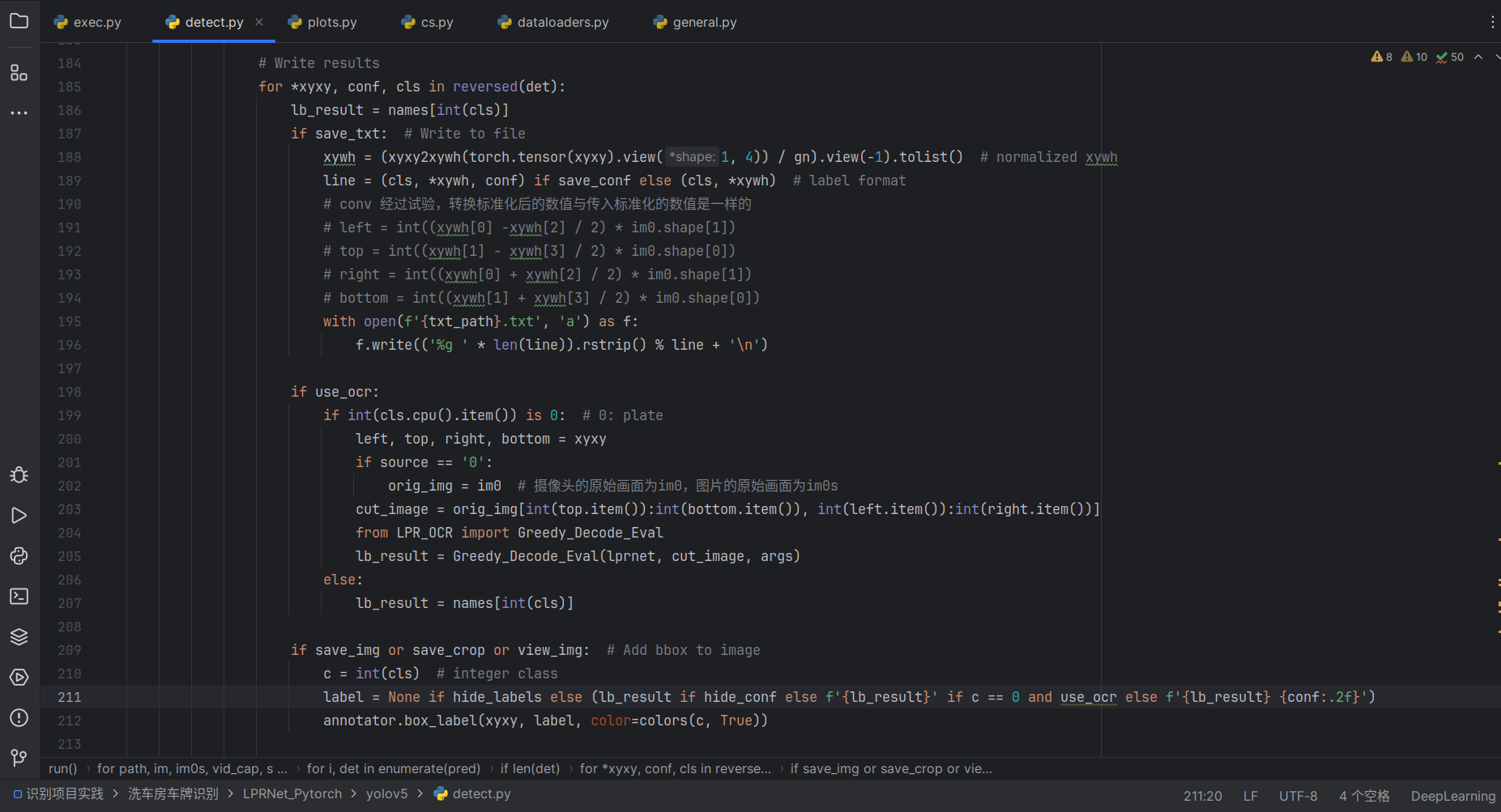
指定use_ocr为False:

指定use_ocr为True:

对比 图 2-9 我想在use_ocr的情况下不显示车牌字符后面的框的置信度,最后也是成功实现了,实践的过程遇到个问题,也是发现了我对某个知识点学习的不足
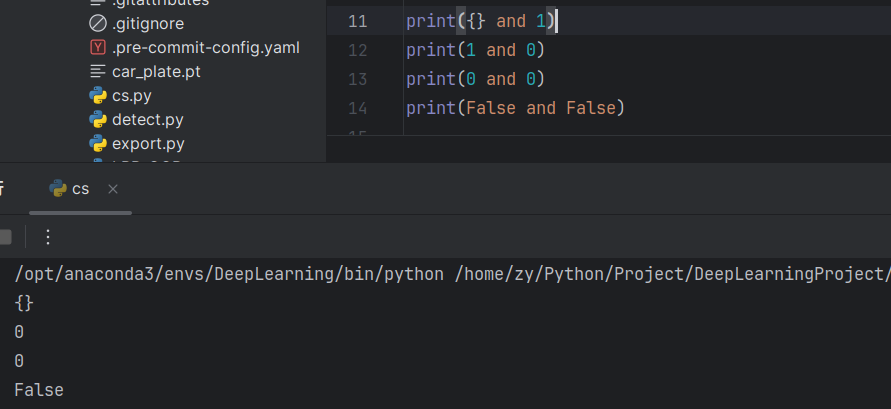
Python_短路计算
and bool计算中,遇到第一个为False会直接将第一个作为输出,遇到第一个True会直接将第二个
作为输出,示例如 图2-16
label = None if hide_labels else (lb_result if hide_conf else f'{lb_result}' if c == 0 and use_ocr else f'{lb_result} {conf:.2f}')最后用一个列表将识别类别存起来去重,只要这个列表长度等于2就可以表明car与plate都有被识别
bingo = []
...
for xxx, xxx, cls in det:
bing.append(int(cls))
...
if len(set(bingo)) == 2:
print('正在生成订单-->请支付-->开门!')
bingo.clear()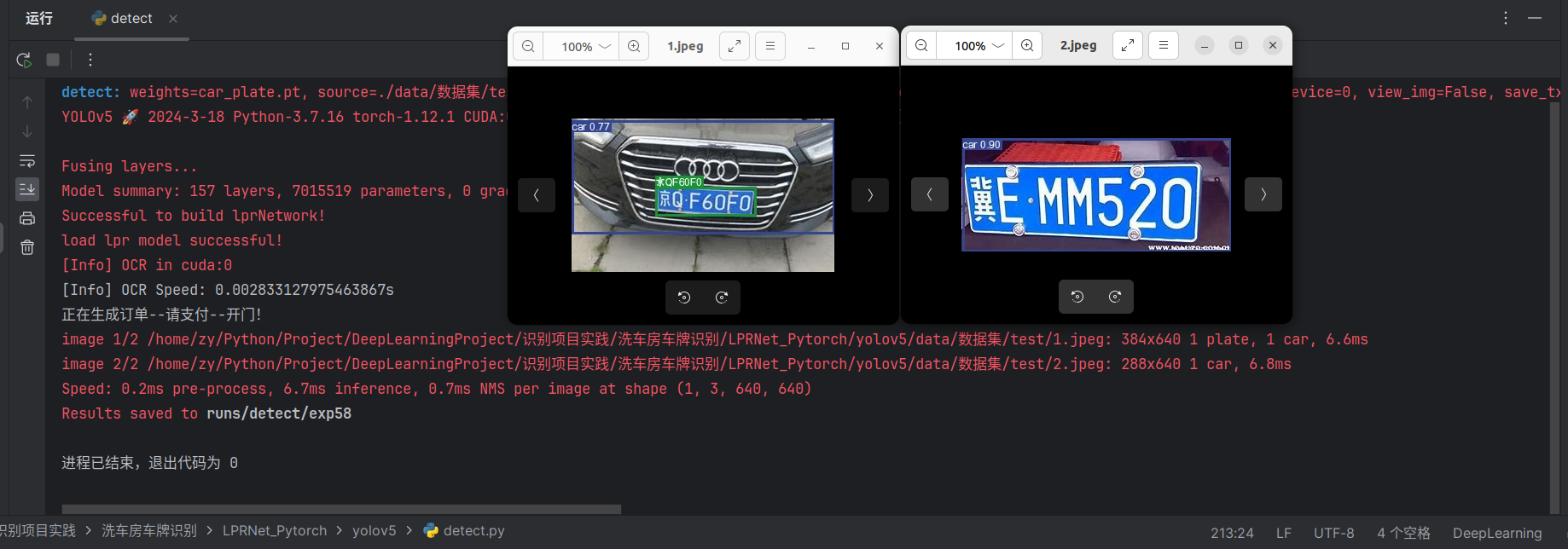
ok,效果达到了,但模型识别那块又有问题了,我感觉是标注时车框的主体里也包含了车牌,再加上数据集的车身图片不是太全导致的
拓展三
在拓展二的基础上加入数据库,使只允许注册的用户才能进入洗车
开整!
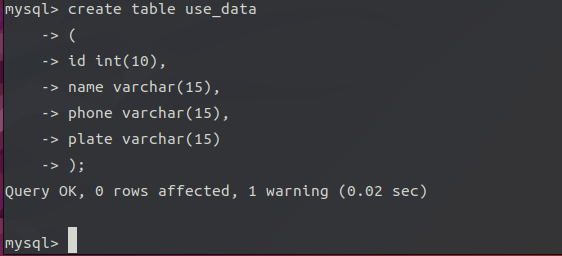
1.构建数据库
创建数据库、表,添加字段

构造一些数据
import mysql.connector
db = mysql.connector.connect(
host="localhost",
user="root",
password="123456",
database="Car_wash_room"
)
cursor = db.cursor()
sql = "INSERT INTO use_data (id, name, phone, plate) VALUES (%s, %s, %s, %s)"
names = ['小张', '小白', '小爱']
phones = ['332111', '1122334', '11334']
plates = ['京QF60F0', '京C77777', '皖AD08815']
for i in range(3):
values = (i+1, names[i], phones[i], plates[i])
print(values)
cursor.execute(sql, values)
db.commit()
print(f"插入了 {cursor.rowcount} 条记录")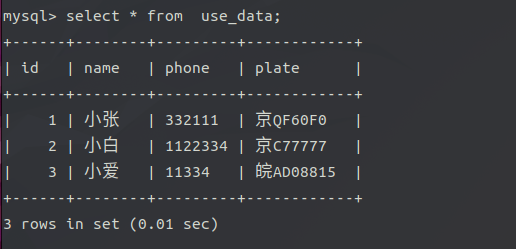
2.将数据库加入到项目
主要代码是这个
sql = "select exists (select 1 from use_data where plate = '京QF60F0') As is_exists"
cursor.execute(sql)
print(bool(cursor.fetchone()[0]))传入了6张图片,只输出了3行欢迎语,因为只有这三个车牌号在咱刚刚构建的数据库里
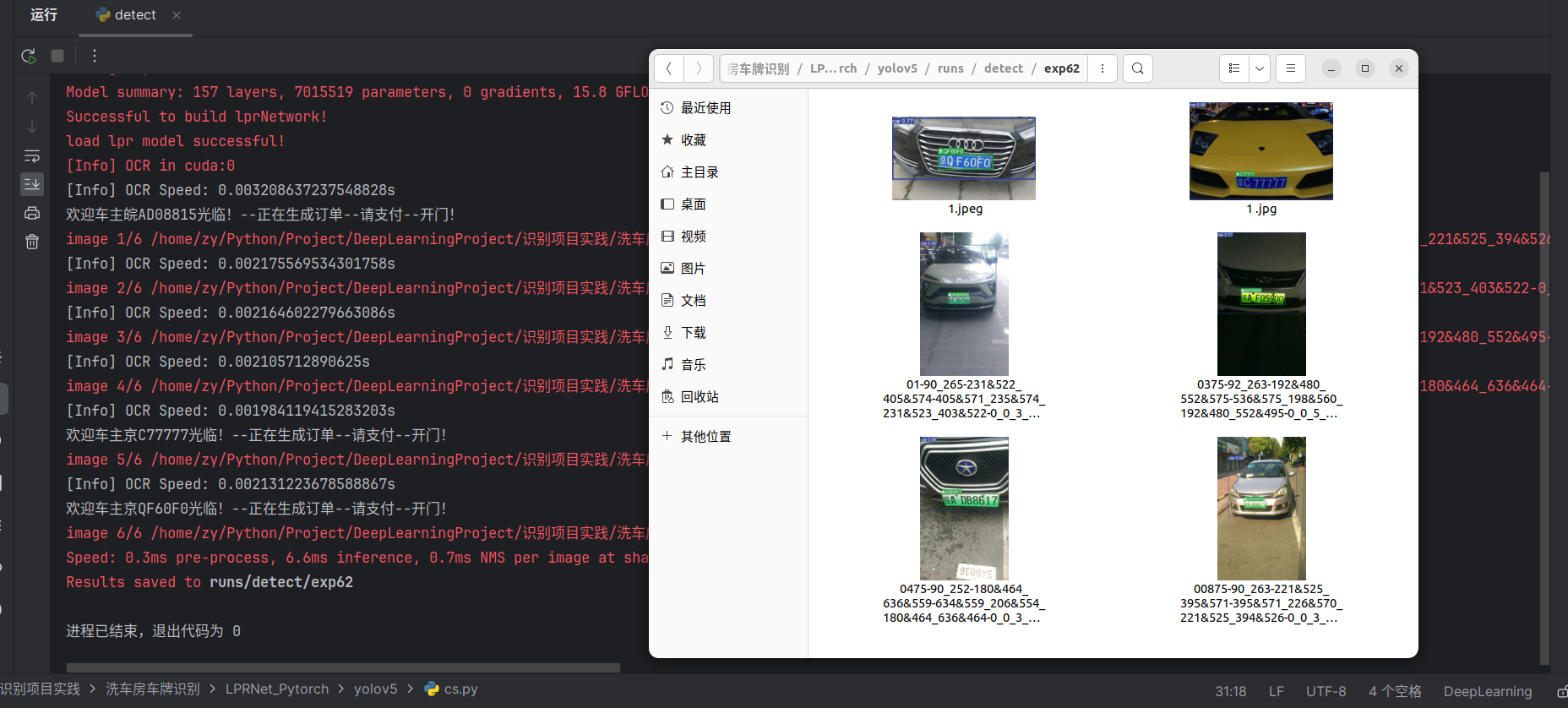
Over!
以上项目及拓展全部开源
第一次上传Github,研究了半天,最终还是成功了,纪念一下!!!

最后感谢阅读!如有解释错误的地方欢迎指正!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









