






本文是对OpenCV2.4.13文档的部分翻译,作个人学习之用,并不完整。
使用基于SVMs的CvSVM::train构建分类器、CvSVM::predict测试性能。
支持向量机(Support Vector Machine SVM)是用一个分离超平面(separating hyperplane)定义的一个差异性分类器。换句话说就是给定标记过的训练数据,算法对新的示例进行分类输出一个最佳的超平面。例如在一个二维点的线性离散集合中包含了两类点,需要找到一条直线将其分开。
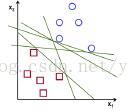
这个例子中我们在Cartesian平面而不是超平面中处理线和点,在高维空间中中处理向量,以此简化功能易于理解。这种概念同样适用于分类高于二维的空间的任务。
在上述图像中,可以看到存在多条线将两类点分开,我们凭直觉定义给出判断它们价值的标准:离点太近的线不好,因为可能会噪点敏感不能准确。因此我们的目标应该是找到离所有点都足够远的线。
SVM算法的执行过程就是基于找到超平面中对于给定的训练示例的最小距离的值最大的一个。另外,这个距离在SVM理论中叫做margin。所以最佳分离超平面将训练数据的margin最大化。

计算最佳超平面:
定义超平面: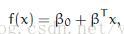


最佳超平面通过调整

现在,我们使用代数结果来给出点x和超平面(
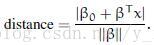
实际情况中,对于权威超平面,分子就等于1,所以支持向量的距离就是
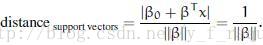
margin在这里记作M,是最近示例的距离的两倍:
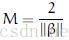
最后,M的最大化就等价于函数

这是一个Lagrangian优化的问题,可以用Lagrange因子来获得最佳超平面的权重向量
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/ml/ml.hpp>
using namespace cv;
int main()
{
// 可视化显示的数据
int width = 512, height = 512;
Mat image = Mat::zeros(height, width, CV_8UC3);
// 建立训练数据,由一个包含了两类的并标记了的二维点集组成,其中一类包含了一点,而另一类包含了三点
float labels[4] = {1.0, -1.0, -1.0, -1.0};
float trainingData[4][2] = { { 501, 10 }, { 255, 10 }, { 501, 255 }, { 10, 501 } };
// CvSVM::train需要训练数据保存在float类型的Mat对象中,我们从之前定义的数组创建对象
Mat labelsMat(4, 1, CV_32FC1, labels);
Mat trainingDataMat(4, 2, CV_32FC1, trainingData);
// 建立SVM参数,这里只介绍最简单的情况,即训练示例线性分为两类,SVM还可以用于更广泛的问题中(如非线性的离散数据,使用核函数来提高示例的维数)
// 所以我们要先定义一些单数,存储到CvSVMParams的对象中
CvSVMParams params;
params.svm_type = CvSVM::C_SVC;//SVM类型,C_SVC用于n类的分类(n>=2),这个参数在CvSVMParams.svm_type中定义(该类型的重要特性可以处理不完美分类如非线性离散,这一特性在这里并不重要因为数据是线性离散的并且我们选择最常用的SVM类型)
params.kernel_type = CvSVM::LINEAR;//SVM核,我们不关心要处理的训练数据所以不讨论核函数,但是需要简要解释一下核函数背后的核心思想。核函数有效执行了包含了数据的维度增长的映射。LINEAR类型表哦是没有进行映射。参数定义在CvSVMParams.kernel_type中
params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6);//算法的最终标准。SVM处理过程通过使用迭代方式解决受约束的二次优化问题来实现。这里我们指定了迭代的最大值和错误容忍度,所以允许即使超平面还没有能计算出来,算法也能够在更少的步骤中结束。这个参数定义在cvTermCriteria结构体中。
// 训练SVM,调用CvSVM::train函数来建立SVM模型
CvSVM SVM;
SVM.train(trainingDataMat, labelsMat, Mat(), Mat(), params);
// 显示SVM的决定区域
//predict方法用于使用SVM将输入的示例分类,这里使用这个方法来基于SVM的预估给区域填色。
//换句话说就是通过将图像像素理解为Cartesian平面上的点来穿透图像。每一点都基于SVM的分类预计来填色,如果是绿色表示是标签为1的一类,如果是蓝色表示是标签为-1的一类
Vec3b green(0,255,0), blue (255,0,0);
for (int i = 0; i < image.rows; ++i)
for (int j = 0; j < image.cols; ++j)
{
Mat sampleMat = (Mat_<float>(1,2) << j,i);
float response = SVM.predict(sampleMat);
if (response == 1)
image.at<Vec3b>(i,j) = green;
else if (response == -1)
image.at<Vec3b>(i,j) = blue;
}
// 显示训练数据
int thickness = -1;
int lineType = 8;
circle( image, Point(501, 10), 5, Scalar( 0, 0, 0), thickness, lineType);
circle( image, Point(255, 10), 5, Scalar(255, 255, 255), thickness, lineType);
circle( image, Point(501, 255), 5, Scalar(255, 255, 255), thickness, lineType);
circle( image, Point( 10, 501), 5, Scalar(255, 255, 255), thickness, lineType);
// 显示支持向量
// 这里使用了一对方法来获取支持向量的信息
// get_support_vector_count输出在问题中使用的支持向量的总数
// get_support_vector用下标获取每一个支持向量
// 这里使用这些方法来找到是支持向量的训练示例并将他们高亮显示
thickness = 2;
lineType = 8;
int c = SVM.get_support_vector_count();
for (int i = 0; i < c; ++i)
{
const float* v = SVM.get_support_vector(i);//获取并改变灰度高亮显示
circle( image, Point( (int) v[0], (int) v[1]), 6, Scalar(128, 128, 128), thickness, lineType);
}
imwrite("result.png", image); // 保存图片
imshow("SVM Simple Example", image); // 展示
waitKey(0);
}结果:
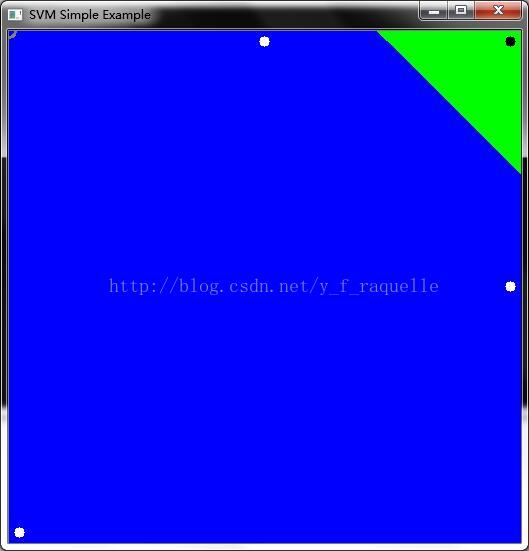
代码中打开图像并显示了两类训练示例,一类点表示为白色圆点,另一类表示为黑色圆点。
SVM被训练并用于将图像中的所有像素分类,致使了图像被分为蓝色和绿色两个区域,中间的边界就是最佳分离超平面。
最终,支持向量用灰色的圈标出来了。















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









