







vs和qt环境配置好,编译示例,出现以下报错:

“无法打开包括文件 “stddf.h”,no such file or directory,
网上大部分教程都是临时解决方案,让把头文件目录添加到项目配置里面,但是这种方案实际上治标不治本,总不能以后每个项目都添加吧!
出现这种情况,再验证,vs直接新建控制台项目,继续报错如下:
 “无法打开包括文件 “crtdbg.h”,no such file or directory
“无法打开包括文件 “crtdbg.h”,no such file or directory
妥了,不要怀疑了,VS安装的本身问题!!!,需要按以下步骤,
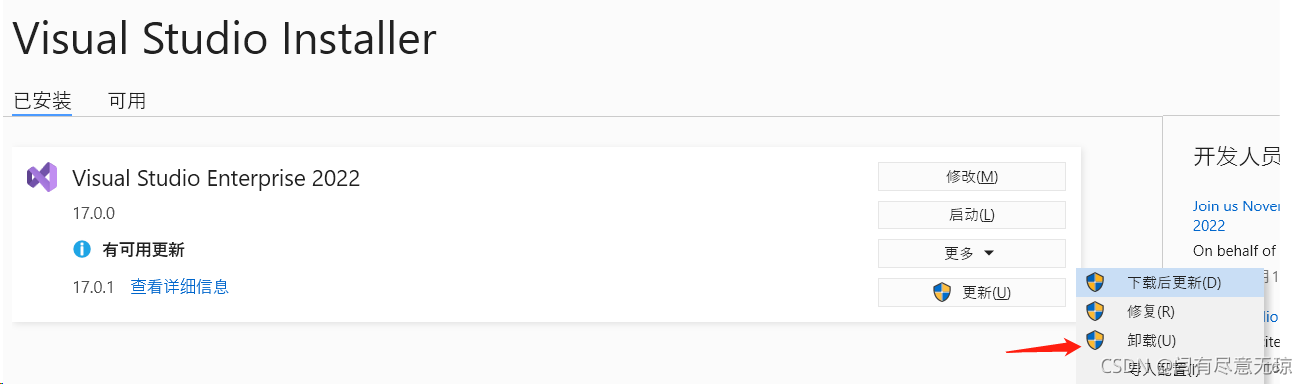
卸载,重启动电脑,重新安装vs,
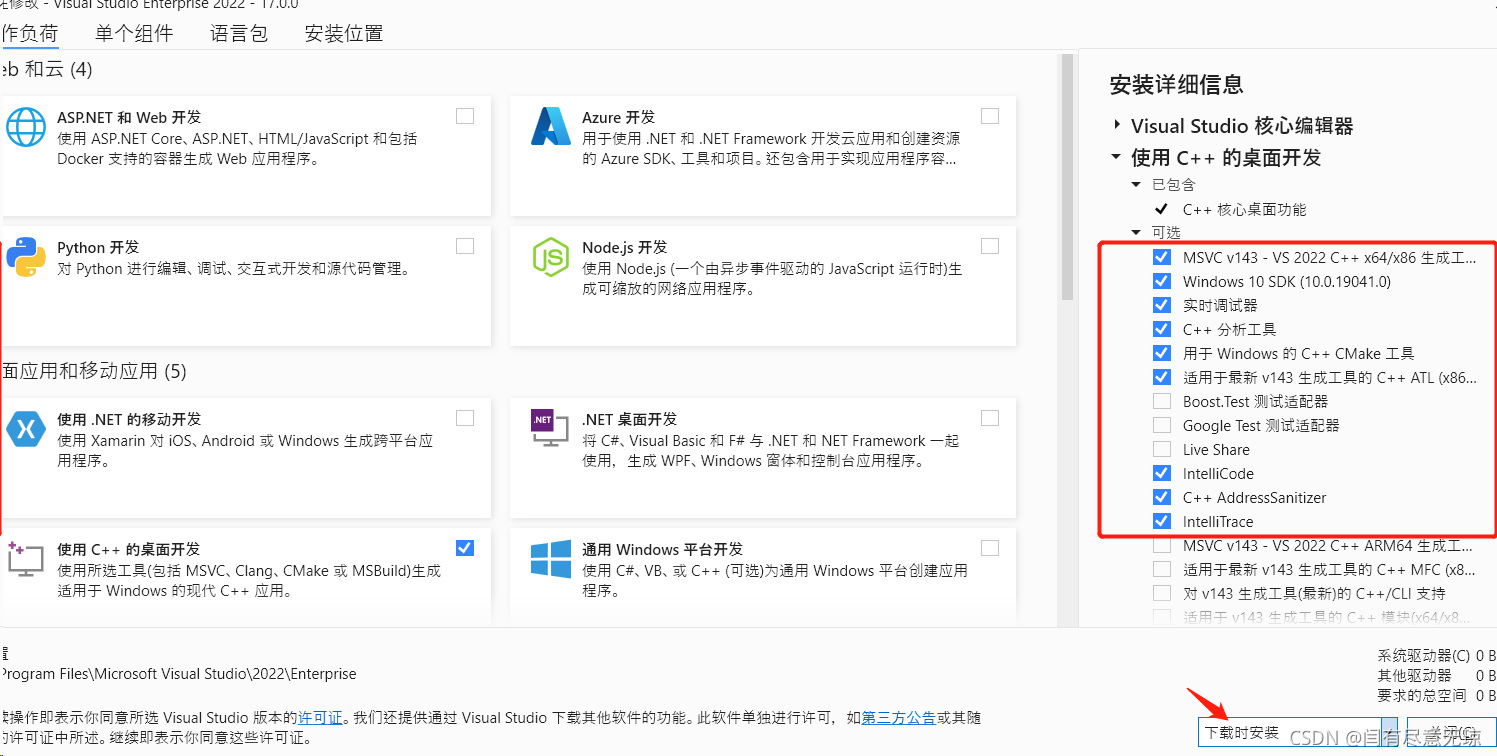
选择下载时安装即可,等待重新安装完成,安装vs qt tool后,自动识别出qt版本,即可顺利编译!


















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











