






tag:图像旋转,任意角度,图像缩放,速度优化,定点数优化,近邻取样插值,二次线性插值,
三次卷积插值,MipMap链,三次线性插值,MMX/SSE优化,CPU缓存优化,AlphaBlend,颜色混合,并行
摘要: 该文章是《任意角度的高质量的快速的图像旋转》的一些高级补充话题;
给出了一个完整的Alpha混合的插值旋转实现;并尝试将旋转函数并行化,从而在多核电脑上获得更快的速度;
任意角度的高质量的快速的图像旋转 全文 分为:
上篇 纯软件的任意角度的快速旋转
中篇 高质量的旋转
下篇 补充话题
正文:
为了便于讨论,这里只处理32bit的ARGB颜色;
代码使用C++;涉及到汇编优化的时候假定为x86平台;使用的编译器为vc2005;
为了代码的可读性,没有加入异常处理代码;
测试使用的CPU为AMD64x2 4200+;
(基础代码参考《图形图像处理-之-任意角度的高质量的快速的图像旋转》系列前面的文章)
A:完整的Alpha混合的双线性插值旋转实现
《高质量的旋转》中已经涉及到了边界的AlphaBlend的问题,这里顺水推舟的实现一个支持全图片Alpha通道Blend混合的双线性插值旋转函数;
首先给出带完整Alpha通道的源图片:

这张图片是带有8比特Alpha的32比特RGB真彩bmp图片;
带的Alpha通道在工具里可能显示不出来,单独提取出来的图示:

函数实现:
void BilInear_BlendBorder_MMX(const TPicRegion& pic,const long x_16,const long y_16,TARGB32* result)
{
unsigned long x0=(x_16>>16 );
unsigned long y0=(y_16>>16 );
TARGB32 pixel[4 ];
bool IsInPic;
pixel[0]= Pixels_Bound(pic,x0,y0,IsInPic);
if (!IsInPic) pixel[0].a=0 ;
pixel[2]=Pixels_Bound(pic,x0,y0+1 ,IsInPic);
if (!IsInPic) pixel[2].a=0 ;
pixel[1]=Pixels_Bound(pic,x0+1 ,y0,IsInPic);
if (!IsInPic) pixel[1].a=0 ;
pixel[3]=Pixels_Bound(pic,x0+1,y0+1 ,IsInPic);
if (!IsInPic) pixel[3].a=0 ;
TPicRegion npic;
npic.pdata =&pixel[0 ];
npic.byte_width=2*sizeof (TARGB32);
// npic.width =2;
//npic.height =2;
BilInear_Fast_MMX(npic,(unsigned short)x_16,(unsigned short )y_16,result);
}
void PicRotary_BilInear_BlendLine_MMX(TARGB32* pDstLine,long dst_border_x0,long dst_in_x0,long dst_in_x1,long dst_border_x1,
const TPicRegion& SrcPic,long srcx0_16,long srcy0_16,long Ax_16,long Ay_16)
{
long x;
for (x=dst_border_x0;x<dst_in_x0;++ x)
{
TARGB32 src_color;
BilInear_BlendBorder_MMX(SrcPic,srcx0_16,srcy0_16,& src_color);
if (src_color.a>0 )
pDstLine[x]= AlphaBlend_MMX(pDstLine[x],src_color);
srcx0_16+= Ax_16;
srcy0_16+= Ay_16;
}
for (x=dst_in_x0;x<dst_in_x1;++ x)
{
TARGB32 src_color;
BilInear_Fast_MMX(SrcPic,srcx0_16,srcy0_16,& src_color);
if (src_color.a==255 )
pDstLine[x]= src_color;
else if (src_color.a>0 )
pDstLine[x]= AlphaBlend_MMX(pDstLine[x],src_color);
srcx0_16+= Ax_16;
srcy0_16+= Ay_16;
}
for (x=dst_in_x1;x<dst_border_x1;++ x)
{
TARGB32 src_color;
BilInear_BlendBorder_MMX(SrcPic,srcx0_16,srcy0_16,& src_color);
if (src_color.a>0 )
pDstLine[x]= AlphaBlend_MMX(pDstLine[x],src_color);
srcx0_16+= Ax_16;
srcy0_16+= Ay_16;
}
asm emms
}
void PicRotaryBlendBilInear_MMX(const TPicRegion& Dst,const TPicRegion& Src,double RotaryAngle,double ZoomX,double ZoomY,double move_x,double move_y)
{
if ( (fabs(ZoomX*Src.width)<1.0e-4) || (fabs(ZoomY*Src.height)<1.0e-4) ) return; //太小的缩放比例认为已经不可见
double tmprZoomXY=1.0/(ZoomX* ZoomY);
double rZoomX=tmprZoomXY* ZoomY;
double rZoomY=tmprZoomXY* ZoomX;
double sinA,cosA;
SinCos(RotaryAngle,sinA,cosA);
long Ax_16=(long)(rZoomX*cosA*(1<<16 ));
long Ay_16=(long)(rZoomX*sinA*(1<<16 ));
long Bx_16=(long)(-rZoomY*sinA*(1<<16 ));
long By_16=(long)(rZoomY*cosA*(1<<16 ));
double rx0=Src.width*0.5; //(rx0,ry0)为旋转中心
double ry0=Src.height*0.5 ;
long Cx_16=(long)((-(rx0+move_x)*rZoomX*cosA+(ry0+move_y)*rZoomY*sinA+rx0)*(1<<16 ));
long Cy_16=(long)((-(rx0+move_x)*rZoomX*sinA-(ry0+move_y)*rZoomY*cosA+ry0)*(1<<16 ));
TRotaryClipData rcData;
rcData.Ax_16= Ax_16;
rcData.Bx_16= Bx_16;
rcData.Cx_16= Cx_16;
rcData.Ay_16= Ay_16;
rcData.By_16= By_16;
rcData.Cy_16= Cy_16;
rcData.dst_width= Dst.width;
rcData.dst_height= Dst.height;
rcData.src_width= Src.width;
rcData.src_height= Src.height;
if (!rcData.inti_clip(move_x,move_y,1)) return ;
TARGB32* pDstLine= Dst.pdata;
((TUInt8*&)pDstLine)+=(Dst.byte_width* rcData.out_dst_down_y);
while (true) //to down
{
long y= rcData.out_dst_down_y;
if (y>=Dst.height) break ;
if (y>=0 )
{
PicRotary_BilInear_BlendLine_MMX(pDstLine,rcData.out_dst_x0_boder,rcData.out_dst_x0_in,
rcData.out_dst_x1_in,rcData.out_dst_x1_boder,Src,rcData.out_src_x0_16,rcData.out_src_y0_16,Ax_16,Ay_16);
}
if (!rcData.next_clip_line_down()) break ;
((TUInt8*&)pDstLine)+= Dst.byte_width;
}
pDstLine= Dst.pdata;
((TUInt8*&)pDstLine)+=(Dst.byte_width* rcData.out_dst_up_y);
while (rcData.next_clip_line_up()) //to up
{
long y= rcData.out_dst_up_y;
if (y<0) break ;
((TUInt8*&)pDstLine)-= Dst.byte_width;
if (y< Dst.height)
{
PicRotary_BilInear_BlendLine_MMX(pDstLine,rcData.out_dst_x0_boder,rcData.out_dst_x0_in,
rcData.out_dst_x1_in,rcData.out_dst_x1_boder,Src,rcData.out_src_x0_16,rcData.out_src_y0_16,Ax_16,Ay_16);
}
}
}
效果图:
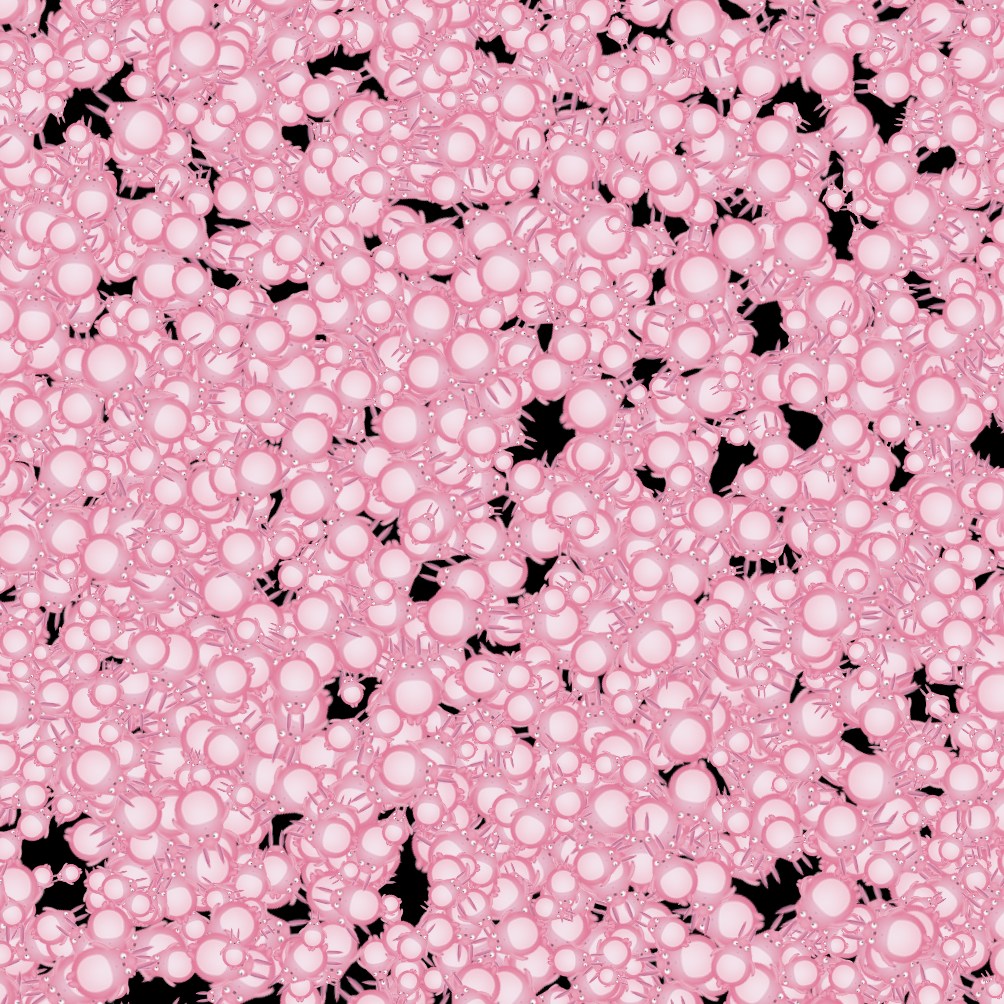
B:在双核上并行三次卷积插值旋转的一个简单实现
(假设图片旋转绘制到目的图片的中间)
这里利用CWorkThreadPool来并行执行任务;
(参见我的文章《并行计算简介和多核CPU编程Demo》,里面有CWorkThreadPool类的完整源代码)
最容易想到的方案就是分成上下两部分分别调用PicRotaryThreeOrder_MMX,从而并行执行;
{
const TPicRegion* Dst;
const TPicRegion* Src;
double RotaryAngle;
double ZoomX;
double ZoomY;
double move_x;
double move_y;
};
void RotaryThreeOrder_callback(void* wd)
{
TRotaryThreeOrder_WorkData* WorkData=(TRotaryThreeOrder_WorkData* )wd;
PicRotaryThreeOrder_MMX(*WorkData->Dst,*WorkData->Src,WorkData->RotaryAngle,WorkData->ZoomX,WorkData->ZoomY,WorkData->move_x,WorkData-> move_y);
}
void PicRotaryThreeOrder_MMX_parallel2(const TPicRegion& Dst,const TPicRegion& Src,double RotaryAngle,double ZoomX,double ZoomY,double move_x,double move_y)
{
TRotaryThreeOrder_WorkData work_list[2 ];
TRotaryThreeOrder_WorkData* pwork_list[2 ];
for (long i=0;i<2;++ i)
{
work_list[i].Src=& Src;
work_list[i].RotaryAngle= RotaryAngle;
work_list[i].ZoomX= ZoomX;
work_list[i].ZoomY= ZoomY;
work_list[i].move_x= move_x;
work_list[i].move_y= move_y;
pwork_list[i]=& work_list[i];
}
TPicRegion dst_up= Dst;
dst_up.height=Dst.height/2 ;
work_list[0].Dst=& dst_up;
TPicRegion dst_down= Dst;
dst_down.pdata=&Pixels(Dst,0 ,dst_up.height);
dst_down.height=Dst.height- dst_up.height;
work_list[1].Dst=& dst_down;
work_list[1].move_y=move_y-Dst.height/2 ;
CWorkThreadPool::work_execute(RotaryThreeOrder_callback,(void**)&pwork_list,2 );
}
//注:测试图片都是800*600的图片旋转到1004*1004的图片中心 测试成绩取各个旋转角度的平均速度值
//CPU: AMD64x2 4200+
//速度测试:
//==============================================================================
// PicRotaryThreeOrder_MMX_parallel2 68.1 fps
并行化的实现PicRotaryThreeOrder_MMX_parallel2比PicRotaryThreeOrder_MMX的34.4fps快了98.0%!
在双核CPU上执行速度几乎是单核上的2倍!
C:一个通用的针对任意多核并行的一个简单实现
有了上面的并行基础,我们来实现一个更加通用一些的版本;根据CPU核心数来动态分配任务;
实现方式为直接按照扫描行来分配(但这样处理可能不利于内存的高效访问),就懒得去估算任务量了:)
{
if ( (fabs(ZoomX*Src.width)<1.0e-4) || (fabs(ZoomY*Src.height)<1.0e-4) ) return; //太小的缩放比例认为已经不可见
double tmprZoomXY=1.0/(ZoomX* ZoomY);
double rZoomX=tmprZoomXY* ZoomY;
double rZoomY=tmprZoomXY* ZoomX;
double sinA,cosA;
SinCos(RotaryAngle,sinA,cosA);
long Ax_16=(long)(rZoomX*cosA*(1<<16 ));
long Ay_16=(long)(rZoomX*sinA*(1<<16 ));
long Bx_16=(long)(-rZoomY*sinA*(1<<16 ));
long By_16=(long)(rZoomY*cosA*(1<<16 ));
double rx0=Src.width*0.5; //(rx0,ry0)为旋转中心
double ry0=Src.height*0.5 ;
long Cx_16=(long)((-(rx0+move_x)*rZoomX*cosA+(ry0+move_y)*rZoomY*sinA+rx0)*(1<<16 ));
long Cy_16=(long)((-(rx0+move_x)*rZoomX*sinA-(ry0+move_y)*rZoomY*cosA+ry0)*(1<<16 ));
TRotaryClipData rcData;
rcData.Ax_16= Ax_16;
rcData.Bx_16= Bx_16;
rcData.Cx_16= Cx_16;
rcData.Ay_16= Ay_16;
rcData.By_16= By_16;
rcData.Cy_16= Cy_16;
rcData.dst_width= Dst.width;
rcData.dst_height= Dst.height;
rcData.src_width= Src.width;
rcData.src_height= Src.height;
if (!rcData.inti_clip(move_x,move_y,2)) return ;
TARGB32* pDstLine= Dst.pdata;
((TUInt8*&)pDstLine)+=(Dst.byte_width* rcData.out_dst_down_y);
long run_part_i=0 ;
while (true) //to down
{
long y= rcData.out_dst_down_y;
if (y>=Dst.height) break ;
if (y>=0 )
{
if (run_part_i%part_count== part_i)
PicRotary_ThreeOrder_CopyLine_MMX(pDstLine,rcData.out_dst_x0_boder,rcData.out_dst_x0_in,
rcData.out_dst_x1_in,rcData.out_dst_x1_boder,Src,rcData.out_src_x0_16,rcData.out_src_y0_16,Ax_16,Ay_16);
++ run_part_i;
}
if (!rcData.next_clip_line_down()) break ;
((TUInt8*&)pDstLine)+= Dst.byte_width;
}
pDstLine= Dst.pdata;
((TUInt8*&)pDstLine)+=(Dst.byte_width* rcData.out_dst_up_y);
while (rcData.next_clip_line_up()) //to up
{
long y= rcData.out_dst_up_y;
if (y<0) break ;
((TUInt8*&)pDstLine)-= Dst.byte_width;
if (y< Dst.height)
{
if (run_part_i%part_count== part_i)
PicRotary_ThreeOrder_CopyLine_MMX(pDstLine,rcData.out_dst_x0_boder,rcData.out_dst_x0_in,
rcData.out_dst_x1_in,rcData.out_dst_x1_boder,Src,rcData.out_src_x0_16,rcData.out_src_y0_16,Ax_16,Ay_16);
++ run_part_i;
}
}
}
struct TRotaryThreeOrder_part_WorkData
{
const TPicRegion* Dst;
const TPicRegion* Src;
double RotaryAngle;
double ZoomX;
double ZoomY;
double move_x;
double move_y;
long part_i;
long part_count;
};
void RotaryThreeOrder_part_callback(void* wd)
{
TRotaryThreeOrder_part_WorkData* WorkData=(TRotaryThreeOrder_part_WorkData* )wd;
PicRotaryThreeOrder_MMX_part(*WorkData->Dst,*WorkData->Src,WorkData->RotaryAngle,WorkData->ZoomX,WorkData-> ZoomY,
WorkData->move_x,WorkData->move_y,WorkData->part_i,WorkData-> part_count);
}
void PicRotaryThreeOrder_MMX_parallel(const TPicRegion& Dst,const TPicRegion& Src,double RotaryAngle,double ZoomX,double ZoomY,double move_x,double move_y)
{
long work_count= CWorkThreadPool::best_work_count();
std::vector<TRotaryThreeOrder_part_WorkData> work_list(work_count);
std::vector<TRotaryThreeOrder_part_WorkData*> pwork_list(work_count);
long i;
for (i=0;i<work_count;++ i)
{
work_list[i].Dst=& Dst;
work_list[i].Src=& Src;
work_list[i].RotaryAngle= RotaryAngle;
work_list[i].ZoomX= ZoomX;
work_list[i].ZoomY= ZoomY;
work_list[i].move_x= move_x;
work_list[i].move_y= move_y;
work_list[i].part_i= i;
work_list[i].part_count= work_count;
pwork_list[i]=& work_list[i];
}
CWorkThreadPool::work_execute(RotaryThreeOrder_part_callback,(void**)&pwork_list[0 ],work_count);
}
//注:测试图片都是800*600的图片旋转到1004*1004的图片中心 测试成绩取各个旋转角度的平均速度值
//CPU: AMD64x2 4200+
//速度测试:
//==============================================================================
// PicRotaryThreeOrder_MMX_parallel 65.2 fps
这个实现能应付大多数时候的并行需求了,包括以后的4核8核...;
要是谁有4核CPU来跑一下,速度应该能达到120多fps .
(注意:这里的并行任务分割方案仅仅是简单的举例(用了代码改动最小的方案),你应该根据你的需求来更好的并行化你的任务; 如果分割后的单个任务太小,并行的优势可能就体现不出来,甚至于更慢;)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









