







文章目录

一、引言
在架构思维:通用架构模式_稳如老狗的SDK设计最佳实践中,介绍了构建稳健微服务的三条法则:防备上游、做好自己、怀疑下游,并深入探讨了“防备上游”的必要性及具体手段。
接下来将聚焦“做好自己”,即如何从自身设计和编码层面,预防和减少服务故障发生的概率。
二、案例:CPU 被打满
线上环境中,“CPU 飙升”是最常见的性能异常面试高频题。下面按步骤详解排查流程:
-
识别进程
- 使用
top命令,按 CPU 占用排序,快速定位高耗进程及其 PID 和名称。
- 使用
-
锁定线程
- 运行
top -Hp <PID>,查看该进程内部各线程的 CPU 占用,获取高耗线程的 TID(十进制编号)。
- 运行
-
导出线程栈
- 对于 Java 应用,执行
jstack <PID> > thread_dump.txt,在输出中查找对应 TID(转换为十六进制),精准发现是哪行代码导致高 CPU。
- 对于 Java 应用,执行
-
分析与修复
- 根据线程栈定位的代码位置,结合业务与日志,修复热点代码或添加限流等保护措施。
三、部署层面:提升容灾与隔离能力
为减少代码缺陷带来的全局影响,推荐以下部署策略:
3.1 双机房部署
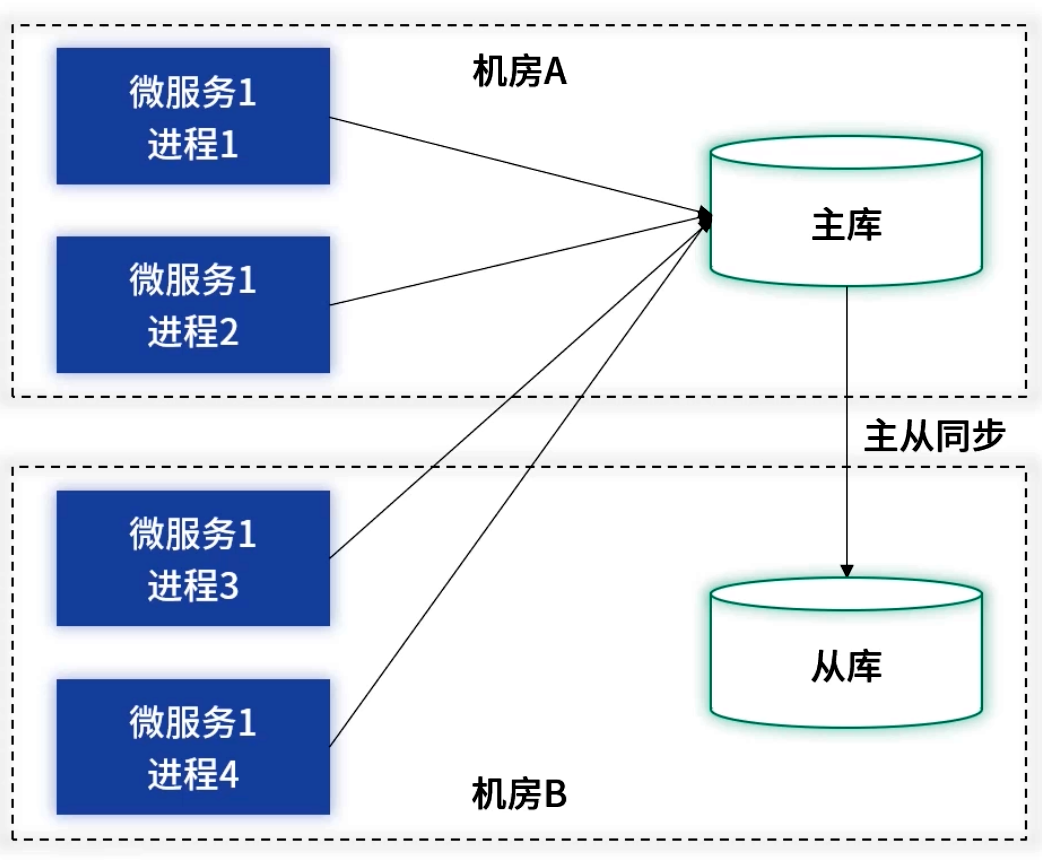
- 架构示意:每个机房部署至少两台微服务实例,数据库主从分别跨机房。
- 故障切换:网络或机房级别故障时,从注册中心摘除故障实例,数据库由 DBA 在秒级完成主从切换。
3.2 单元化多地部署
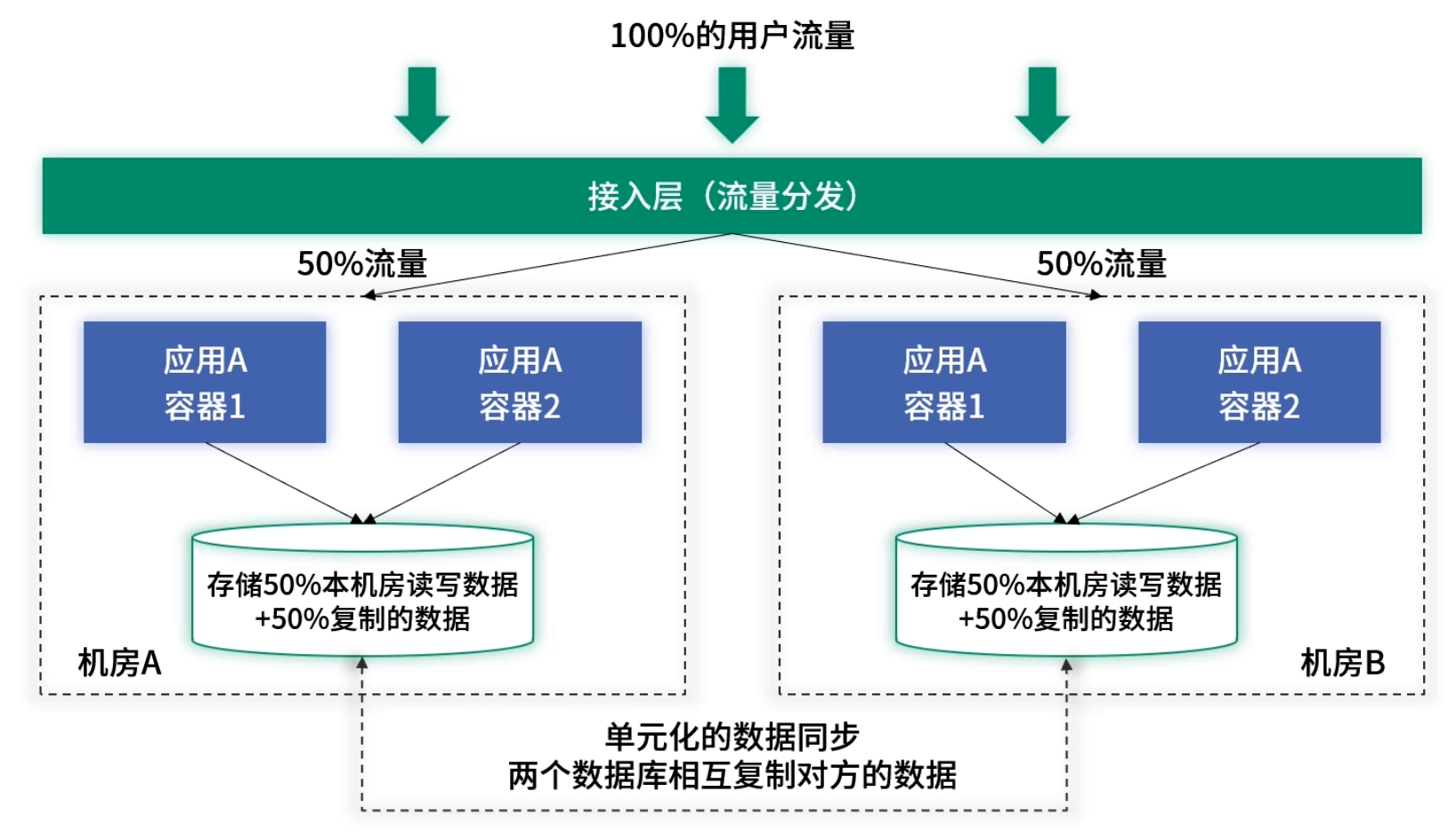
- 核心思想:每个机房数据库均为主库,承担读写流量。网关层按用户或流量比例分发至机房 A/B。
- 实时同步:建立跨机房主库互同步模块,保证数据一致并缩短故障恢复时间。
3.3 机房内多机冗余
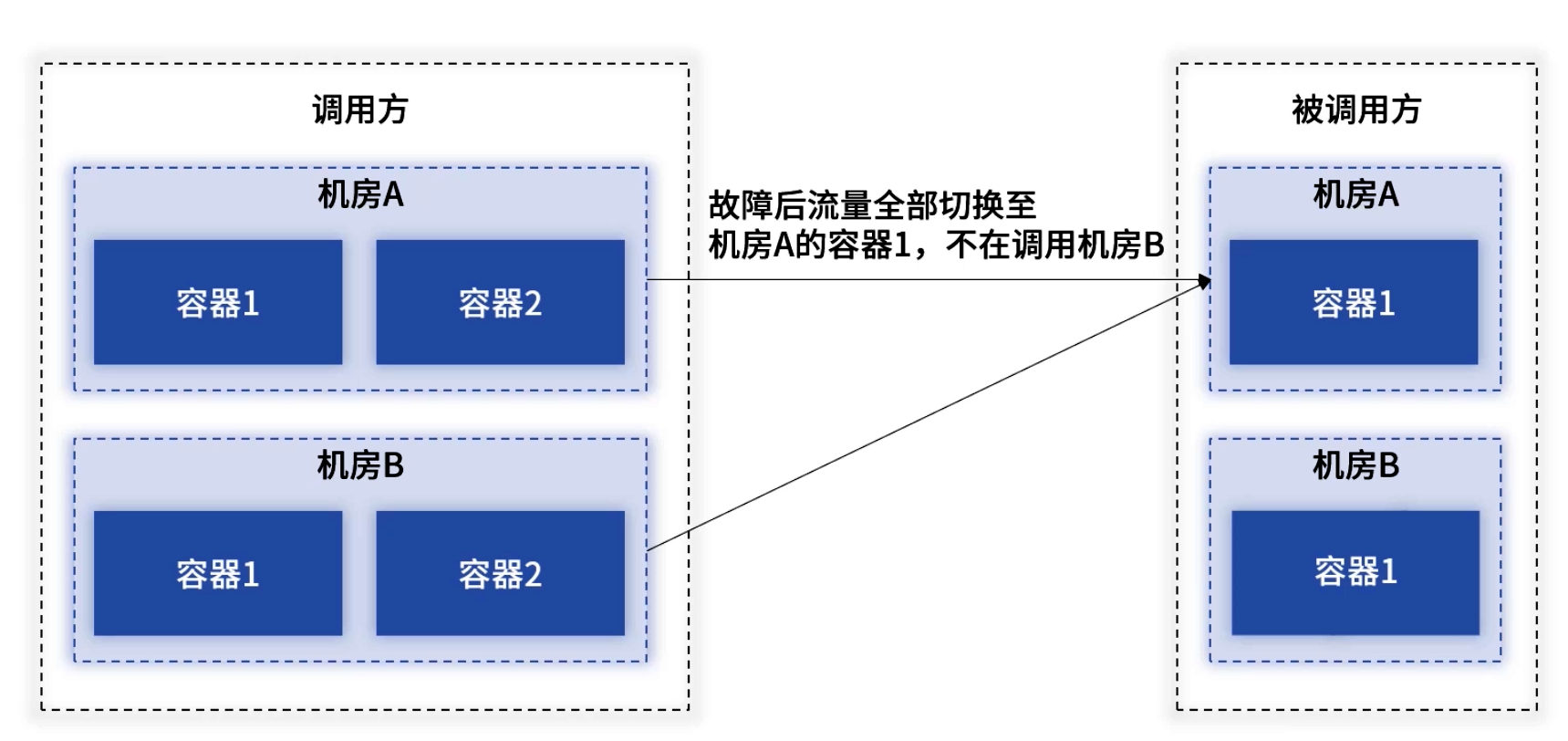
- 避免单机房单点:同一机房至少两台实例,防止单机故障导致跨机房调用而带来性能抖动。
3.4 读写分离部署
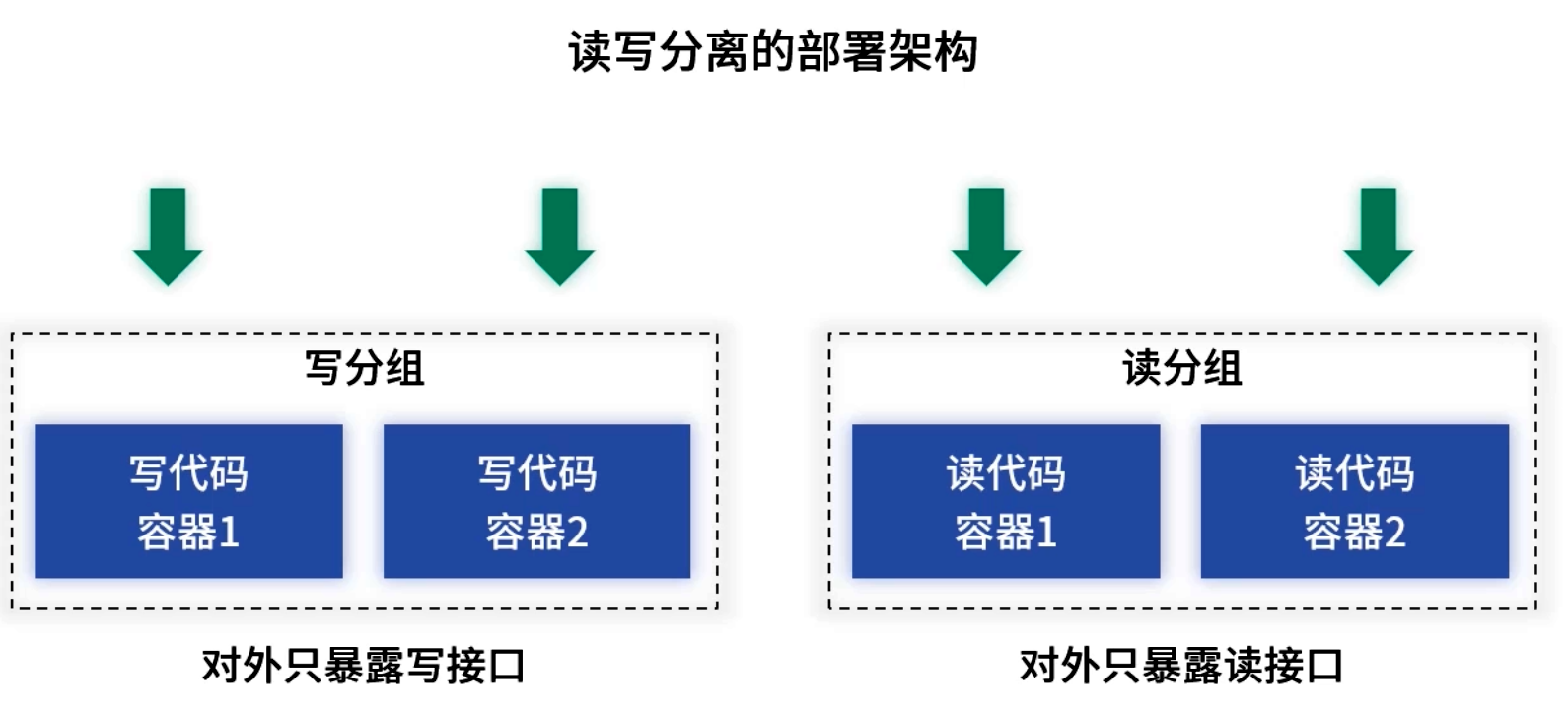
- 独立工程与资源:分别部署读服务与写服务,读高并发场景不会影响写服务的稳定性;写服务专用资源保障核心业务。
3.5 线程池隔离
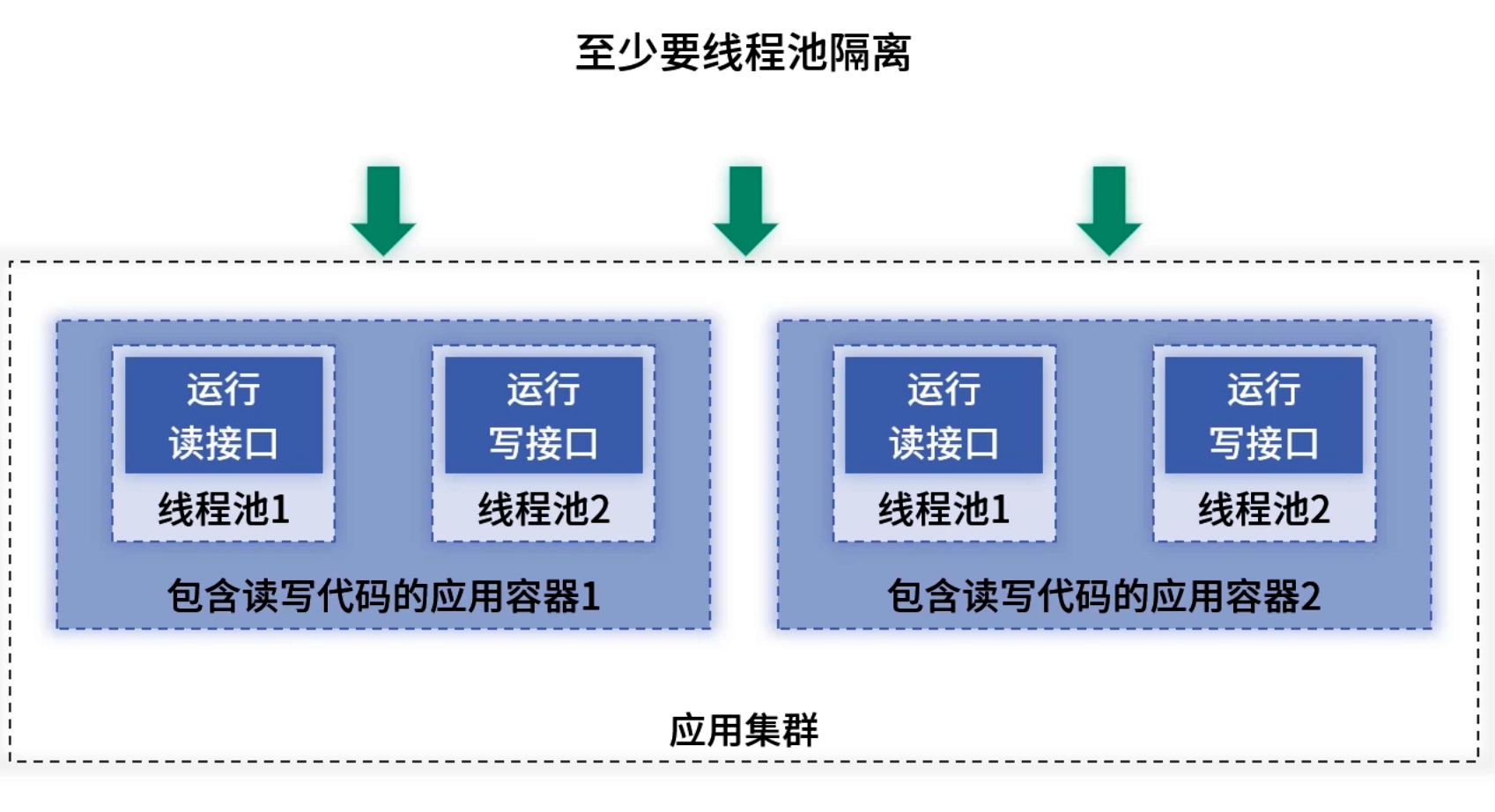
- 框架支持:当机器资源有限、无法物理隔离时,利用框架的接口级线程池配置,实现逻辑隔离,防止线程资源争抢。
四、代码层面:五大编码准则
-
避免 JSON 序列化大对象到日志
-
大对象
JSON.toJson(obj)会消耗大量 CPU,建议按需输出关键字段:logger.info("userId={},orderId={}", userId, orderId);
-
-
动态日志级别降级
-
在日志输出前检查:
if (logger.isInfoEnabled()) { logger.info(JSON.toJson(obj)); } -
结合配置中心,实现线上动态调节日志级别,无需重启。
-
-
限制嵌套循环层数
- 尽量避免超过三层嵌套,极端数据量会导致 O(n³) 级别的执行次数爆炸,分分钟“挂掉”。
-
多层嵌套的动态降级开关
- 当业务无法避免深度嵌套时,增加开关或阈值检测,在数据规模超限时主动跳出,保障可控。
-
本地缓存容量上限
- 显式配置缓存(如 Caffeine、Guava)的最大容量,防止缓存膨胀引起 OOM。
五、小结
我们以“CPU 被打满”故障为例,展示了高效的定位方法,并从部署层面(双机房、单元化、隔离)与代码层面(日志、循环、缓存)提出多种防护策略。通过这些“做好自己”的手段,可以大幅降低微服务线上故障发生概率。




















 68
68

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











