







目录
Message Passing Interface (MPI)
NVIDIA Collective Communication Library (NCCL)
针对分布式训练服务器的集群进行架构设计,是为了更好地解决机器学习中分布式训练中的通讯问题。目前机器学习中主要由两种分布式架构:
- 参数服务器架构(Parameter Server,PS)
- 去中心化架构(Decentralized Network)
其中,分布式训练通常在计算集群上进行,集群的每个节点分别执行一部分计算。不同节点的计算之间有数据依赖和共享,需要将数据在不同节点间传输,这就是通信。分布式的通信一般有两大类:
- 集合通信(Collective communication,CC):在一组节点内进行通信
- 点对点通信(Point to point communication,P2P):在两个节点之间进行通信
深度学习训练过程中因为需要传输大量的网络模型权重参数和训练过程中产生的大量临时变量等,因此主要使用集合通信的方式。可以理解为,机器学习/深度学习的分布式训练,主要是采用在PS架构下的集合通讯模式;而在大模型的分布式训练中,因为减少跟单点参数服务器统一更新,更多直接采用纯集合通讯模式。
在深度学习框架中,分布式训练的通讯原语和通讯实现方式对AI框架分布式训练起着非常重要的作用,如果想要训练大模型(Foundation Model)肯定离不开进行通讯操作,下面橙色标签的是分布式训练中通讯原语在AI框架中的的位置。

Parameter Server架构具有星状的拓扑结构,有一个或一组服务器来存储模型参数,众多worker服务器负责读取数据,执行前向和反向并计算梯度。通过网络连接,这些worker把自己的梯度上传(push)到参数服务器,参数服务器收集所有的worker的梯度并进行计算之后,各worker再下拉(pull)模型参数。
假设每个节点的数据量是M,在一次梯度同步过程中,N台worker节点都需要和中心PS进行一次通信,则PS节点总通信量为 N×M 。可以看出,这种架构总通信量与集群规模成线性关系。因此,当集群规模较大或模型较大时,参数服务器的带宽可能会成为瓶颈。
通讯原语操作
集合通讯中包含多个sender和多个receiver,一般的通信原语包括broadcast、gather、all-gather、scatter、reduce、all-reduce、reduce-scatter、all-to-all等通信操作进行数据传输,下面将会分别介绍其具体含义。
Broadcast
在集合通信中,如果某个节点想把自身的数据发送到集群中的其他节点,那么就可以使用广播Broadcast的操作。
如图所示,圆圈表示分布式系统中的独立节点,一共4个节点,小方块则代表了数据,颜色相同表示数据一样。Broadcast代表广播行为,执行Broadcast时,数据从主节点0广播至其他各个指定的节点(0~3)。

Broadcast操作是将某节点的输入广播到其他节点上,分布式机器学习中常用于网络参数的初始化。如图中,从单个sender数据发送到其他节点上,将0卡大小为1xN的Tensor进行广播,最终每张卡输出均为[1xN]的矩阵。

Scatter
Scatter操作表示一种散播行为,将主节点的数据进行划分并散布至其他指定的节点。

实际上,Scatter与Broadcast非常相似,都是一对多的通信方式,不同的是Broadcast的0号节点将相同的信息发送给所有的节点,而Scatter则是将数据的不同部分,按需发送给所有的节点。
如图所示,从单个sender数据发送到其他节点上。

Reduce
Reduce称为规约运算,是一系列简单运算操作的统称,细分可以包括:SUM、MIN、MAX、PROD、LOR等类型的规约操作。Reduce意为减少/精简,因为其操作在每个节点上获取一个输入元素数组,通过执行操作后,将得到精简的更少的元素。下面以Reduce sum为例子。

在NCCL中的Reduce,从多个sender那里接收数据,最终combine到一个节点上。

All Reduce
Reduce是一系列简单运算操作的统称,All Reduce则是在所有的节点上都应用同样的Reduce操作。以All Reduce Sum为例。

All Reduce操作可通过单节点上Reduce + Broadcast操作完成。在NCCL中的All Reduce中,则是从多个sender那里接收数据,最终合并和分发到每一个节点上。

Gather
Gather操作将多个sender上的数据收集到单个节点上,Gather可以理解为反向的Scatter。

Gather操作会从多个节点里面收集数据到一个节点上面,而不是从一个节点分发数据到多个节点。这个机制对很多平行算法很有用,比如并行的排序和搜索。

All Gather
很多时候发送多个元素到多个节点也很有用,即在多对多通信模式的场景。这个时候就需要 All Gather操作。

对于分发在所有节点上的一组数据来说,All Gather会收集所有数据到所有节点上。从最基础的角度来看,All Gather相当于一个Gather操作之后跟着一个Bcast操作。下面的示意图显示了All Gather调用之后数据是如何分布的。

Reduce Scatter
Reduce Scatter操作会将个节点的输入先进行求和,然后在第0维度按卡数切分,将数据分发到对应的卡上。例如上图所示,每卡的输入均为4x1的Tensor。Reduce Scatter先对输入求和得到[0, 4, 8, 12]的Tensor,然后进行分发,每卡获得1x1大小的Tensor。例如卡0对应的输出结果为[[0.0]],卡1对应的输出结果为[[4.0]]。

All to All
All to All作为全交换操作,通过All to All通信,可以让每个节点都获取其他节点的值。
在使用 All to All 时,每一个节点都会向任意一个节点发送消息,每一个节点也都会接收到任意一个节点的消息。每个节点的接收缓冲区和发送缓冲区都是一个分为若干个数据块的数组。All to All 的具体操作是:将节点i的发送缓冲区中的第j块数据发送给节点j,节点j将接收到的来自节点i的数据块放在自身接收缓冲区的第i块位置。
All to All 与 All Gather 相比较,区别在于:All Gather 操作中,不同节点向某一节点收集到的数据是完全相同的,而在 All to All 中,不同的节点向某一节点收集到的数据是不同的。在每个节点的发送缓冲区中,为每个节点都单独准备了一块数据。

AI框架中的通信实现
分布式集群的网络硬件多种多样,可以是Ethernet、InfiniBand 等,深度学习框架通常不直接操作硬件,而是使用通信库。之所以采用通信库屏,是因为其蔽了底层硬件细节,提供了统一封装的通信接口。其中MPI和NCCL是最常用的通讯库,MPI专注于CPU的并行通讯,NCCL则专注于GPU的通讯。
Message Passing Interface (MPI)
MPI 信息传递接口,是一个用于编写并行计算程序的编程接口。它提供了丰富全面的通信功能。
MPI 常用于在计算集群、超算上编写程序,比如很多传统科学计算的并行程序。MPI 接口的兼容性好,通信功能丰富,在深度学习框架中主要用于 CPU 数据的通信。
MPI是一个开放接口,有多种实现的库,一种广泛使用的开源实现是 Open MPI。一些硬件厂商也提供针对硬件优化的实现。
NVIDIA Collective Communication Library (NCCL)
NCCL 英伟达集合通信库,是一个专用于多个 GPU 乃至多个节点间通信的实现。它专为英伟达的计算卡和网络优化,能带来更低的延迟和更高的带宽。
NCCL 也提供了较丰富的通信功能,接口形式上与 MPI 相似,可满足大多数深度学习任务的通信需求。它在深度学习框架中专用于 GPU 数据的通信。因为NCCL则是NVIDIA基于自身硬件定制的,能做到更有针对性且更方便优化,故在英伟达硬件上,NCCL的效果往往比其它的通信库更好。
MPI和NCCL的关系
openMPI的通讯算法和通讯操作原语最晚在2009年就都已经成熟并开源了,而Nvidia在2015年下半年首次公开发布NCCL。
既然openMPI已经实现了这么多All Reduce算法,为什么英伟达还要开发NCCL?是不是从此只要NCCL,不再需要MPI了呢?
NO
从openMPI的源码里能看到,其完全没有考虑过深度学习的场景,基本没有考虑过GPU系统架构。很明显的一点,MPI中各个工作节点基本视为等同,并没有考虑节点间latency和带宽的不同,所以并不能充分发挥异构场景下的硬件性能。
Nvidia的策略还是比较聪明,不和MPI竞争,只结合硬件做MPI没做好的通信性能优化。在多机多卡分布式训练中,MPI还是广泛用来做节点管理,NCCL只做GPU的实际规约通信。NCCL可以轻松与MPI结合使用,将MPI用于CPU到CPU的通信,将NCCL用于GPU到GPU的通信。
而NCCL的优势就在于完全贴合英伟达自己的硬件,能充分发挥性能。但是基本的算法原理其实相比openMPI里实现的算法是没有太大变化。
NCCL1.x只能在单机内部进行通信,NCCL2.0开始支持多节点(2017年Q2)。所以在NCCL2之前大家还会依赖MPI来进行集合通信。
pytorch中的分布式训练之DP VS DDP
pytorch中的有两种分布式训练方式,一种是常用的DataParallel(DP),另外一种是DistributedDataParallel(DDP),两者都可以用来实现数据并行方式的分布式训练,DP采用的是PS模式,DDP采用的是ring-all-reduce模式,两种分布式训练模式主要区别如下:
1.DP是单进程多线程的实现方式,DDP是采用多进程的方式
2.DP只能在单机上使用,DDP单机和多机都可以使用
3DDP相比于DP训练速度要快
简要介绍一下PS模式和ring-all-reduce模式:

Parameter Server架构(PS模式)由server节点和worker节点组成
server节点的主要功能是初始化和保存模型参数、接受worker节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数(DP)
worker节点的主要功能是各自保存部分训练数据,初始化模型,从server节点拉取最新的模型参数(pull),再读取参数,根据训练数据计算局部梯度,上传给server节点(push)。
PS模式下的DP,会造成负载不均衡,因为充当server的GPU需要一定的显存用来保存worker节点计算出的局部梯度;另外server还需要将更新后的模型参数broadcast到每个worker,server的带宽就成了server与worker之间的通信瓶颈,server与worker之间的通信成本会随着worker数目的增加而线性增加,举个例子:
假设我们有一个300M参数量的模型,其所占内存大小为300M*sizeof(data_type),假设数据类型全都是float,也就是每个参数占用4个bytes,那么该模型所占用内存为300M*4=1.2GB,假设我们用网络带宽 1G bytes/s (万兆网卡),是当利用单机两卡进行训练的时候,同步参数所需要的时间为1.2s,当我们使用单机5卡进行训练,那么同步参数所需要的时间就需要1.2s*(5-1)=4.8s,这还仅仅是同步参数所需要的时间,还有考虑server接收worker梯度所需要的时间,在这种情况下,server与worker之间的通信时间大约为10s。而且在server与worker之间进行通信的时候,worker是没有在进行计算的,造成大量的计算资源浪费
ring-all-reduce模式
ring-all-reduce模式没有server节点,worker与worker之间的通信构成一个环

ring-all-reduce模式下,所有worker只和自己相邻的两个worker进行通信,该工作模式分为两个工作阶段:
1. Scatter Reduce:在这个 Scatter Reduce阶段,GPU 会逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分
2. Allgather:GPU 会逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的融合梯度
首先将模型的梯度按照集群中GPU数量进行分块,然后进行第一步scatter reduce,注意该过程中所有的GPU都是在进行通信的
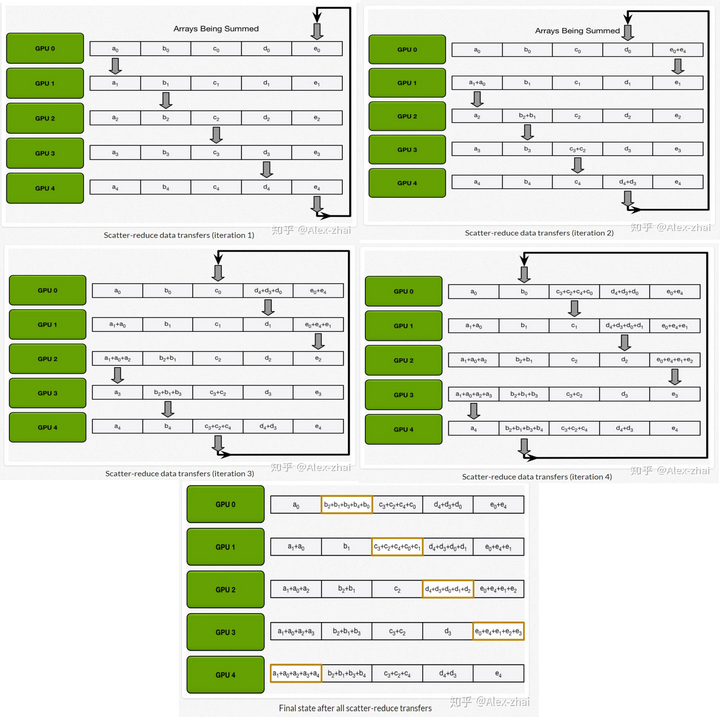
scatter-reduce工作全过程,图源见水印

allgather工作过程,图源见水印
ring all reduce模式不存在网络通信带宽的瓶颈,还是以上述300M参数量的模型为例:
scatter reduce阶段通信时长为:1.2s/5+1.2s/5+1.2s/5+1.2s/5=0.96s
allgather阶段通信时长为:1.2s/5*4=0.96s
总通信时长为0.96s*2=1.92s。
假设有N块GPU,所需传输数据总量为K,那么ring allreduce的数据传输总量为:(2(N−1)/N)*K,传输数据总量不会随着GPU的数量变换而变化。
(K/N是每次iteration要传输的数据量,scatter reduce阶段需要迭代N-1次,allgather阶段需要传输N-1次)
而PS模式下数据传输总量为:2(N-1)*K,其数据传输总量随着GPU的数量成线性增加
下面是将普通的单机单卡程序改成分布式训练程序所要做出的修改:
程序依赖的库:

程序需要输入的参数:

修改数据加载的方式,需要对数据进行手动shard,每个进程或者说GPU取一份数据进行训练:

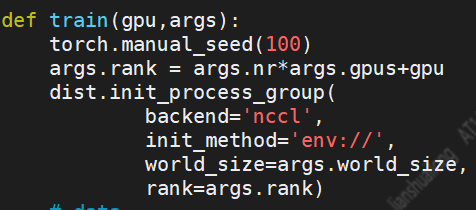
训练过程中,需要确定当前进程号,为了使得每个进程都有相同的初始化参数,我们需要torch.manual_seed(),另外还需要初始化进程组:
对模型进行wrap:

为了保证每个epoch对数据划分的方式不同,我们需要在每个epoch开启训练的时候:

设置分布式训练的参数:
world_size:指的是分布式训练使用的进程数或用gpus数
nodes:节点数,一般节点数是集群中机器的数目
gpus:每个节点中gpu数量
mp.spawn:torch.multiprocessing.spawn()要求提交的任务函数第一个参数是 gpu_id,并且启动多进程传参的时候不传入这个参数,是默认传入的,我们利用train函数的中的形参gpu用于接收这个参数;gpus作为spawn()中的nprocs参数,表示你要创建gpus个子进程,即为每个gpu分配一个进程

完整代码可参考(参考代码是单机多卡版本的):
关于DistributedDataParallel一些参数的理解可以参考:















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









