







《Contrastive Code Representation Learning》 (EMNLP 2021)
现有代码表征学习方法最大的缺点是对源代码的编辑非常敏感,即编辑的代码不改变语义。因此提出一种对比学习预训练方法ContraCode,学习的是代码的功能性,而不是形式。
文章举个例子,现有方法对于代码编辑是不鲁棒的,对代码进行超过3个单词的对抗攻击改动,code clone检测的准确度就已经低于随机猜了。
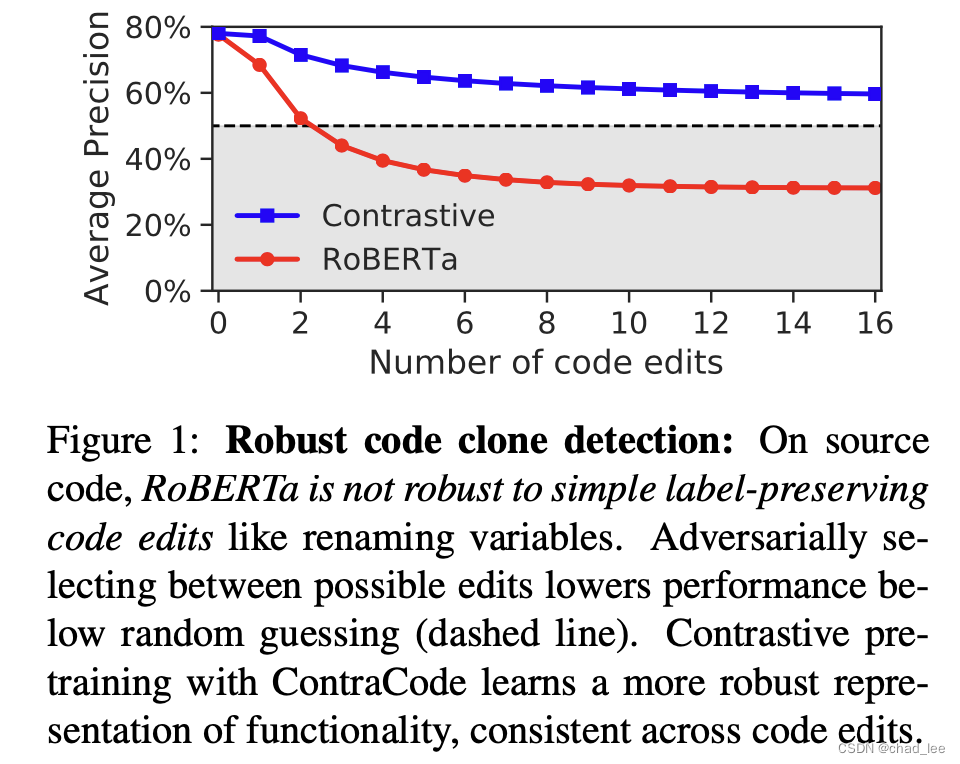
很自然的对比学习方法就是最大化功能相同的代码表征相似度,最小化功能不同的代码表征相似度:
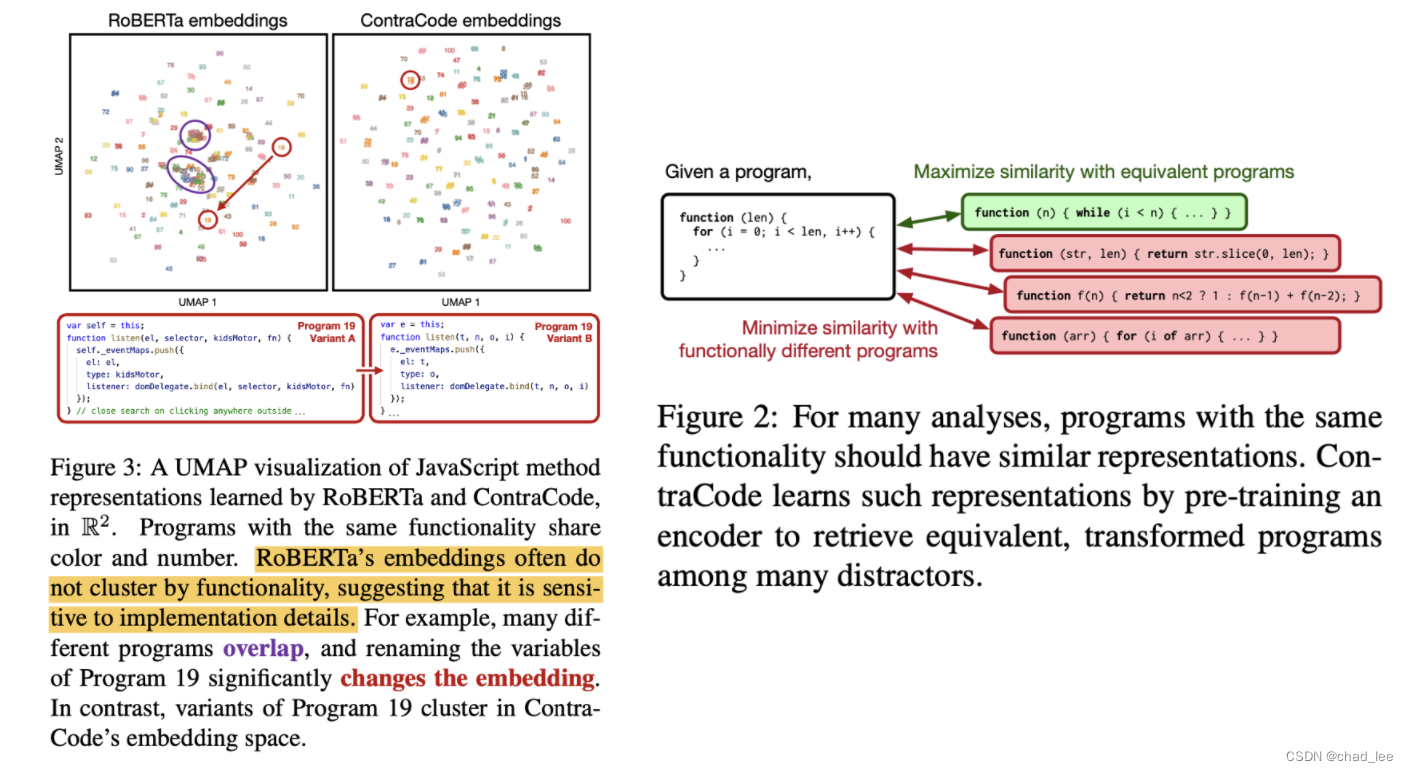
扩增方法
文章的核心思想就是对code进行不改变功能的扩增,然后对比学习。
文章不是人工标注的做这件事,而是巧妙的利用编译器来source2source的实现这件事。只要编译器认为这两个代码相同,那么就是不改变功能的扩增

基于编译器的扩增方法主要可以分为三大类:
- code compression:提前计算表达式、改变代码格式、删除空格、删除Dead-Code等
- Identifier modification:变量重命名等
- Regularization:插入Dead-Code等,其中0.9的Line subsampling是一种改变功能的扩增,用于提高泛化性。
为了提高多样性,对于每段代码,会随机选取一个扩增方法子集进行扩增。
训练方法
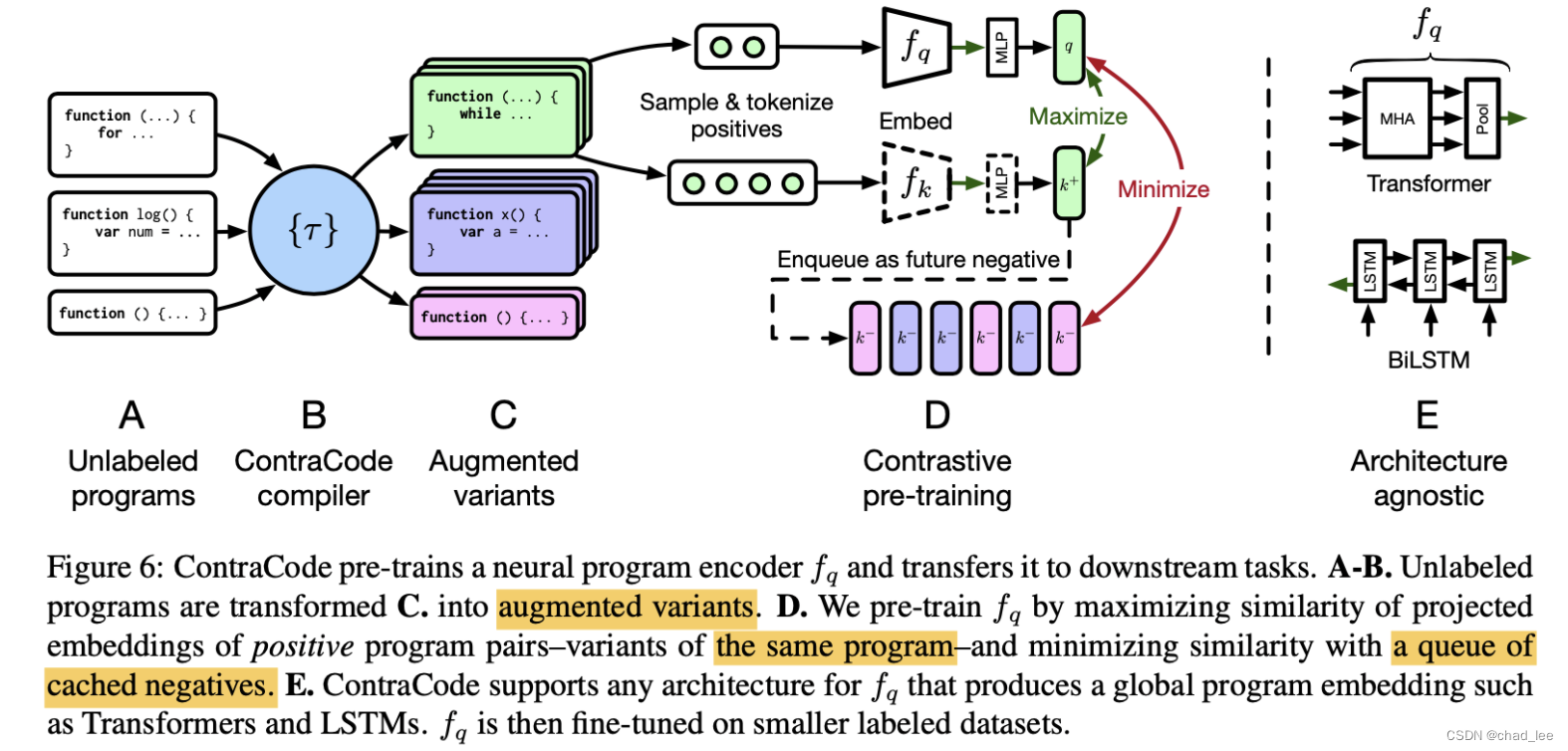
训练用的是 伪孪生网络,基本和He Kaiming的MOCO一样,两个encoder+MLP,输出带入InfoNCE的对比学习loss,也维护了负样本队列。
− log exp ( q
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









