






one-hot编码是将标记转换为向量的最常用、最基本的方法。它将每个单词与一个唯一的整数索引相关联,然后将这个整数索引 i 转换为长度为N的二进制向量(N是词表大小),这个向量只有第i个元素是1,其余元素都为0.
单词级的one-hot编码
import numpy as np
samples = ['This is a dog','The is a cat']
all_token_index = {} #构建一个字典来存储数据中的所有标记的索引
for sample in samples:
for word in sample.split(): #拆分每一个单词
if word not in all_token_index: #为每一个单词指定一个索引
all_token_index[word] = len(all_token_index) + 1
max_length = 10
result = np.zeros(shape=(len(samples), max_length, max(all_token_index.values()) + 1 ))
for i, sample in enumerate(samples): # 获取sample中的索引和值
for j, word in list(enumerate(sample.split()))[:max_length]: # 获取单词的索引和值
index = all_token_index.get(word)
result[i,j,index] = 1
结果:
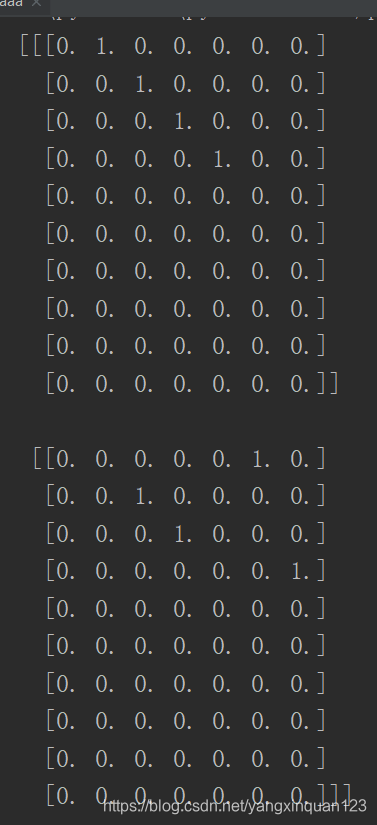
字符级的one-hot编码:
import string
import numpy as np
samples = ['This is a dog', 'The is a cat']
characters = string.printable # 包含所有可打印的ASCII字符
# 把所有可打印字符都装进字典中,从1开始索引
all_token_index = dict(zip(range(1, len(characters)+1), characters))
max_length = 50
result = np.zeros(shape=(len(samples), max_length, max(all_token_index.keys()) + 1))
for i, sample in enumerate(samples): # 获取sample中的索引和值
for j, character in enumerate(sample):
index = all_token_index.get(character)
result[i,j,index] = 1
上述代码均参考《python深度学习》,感觉书讲的挺好的,推荐一波。















 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









