







论文链接:https://arxiv.org/abs/2111.02387
代码链接:GitHub - zdou0830/METER: METER: A Multimodal End-to-end TransformER Framework
Vision-and-language预训练模型(VLP)总览
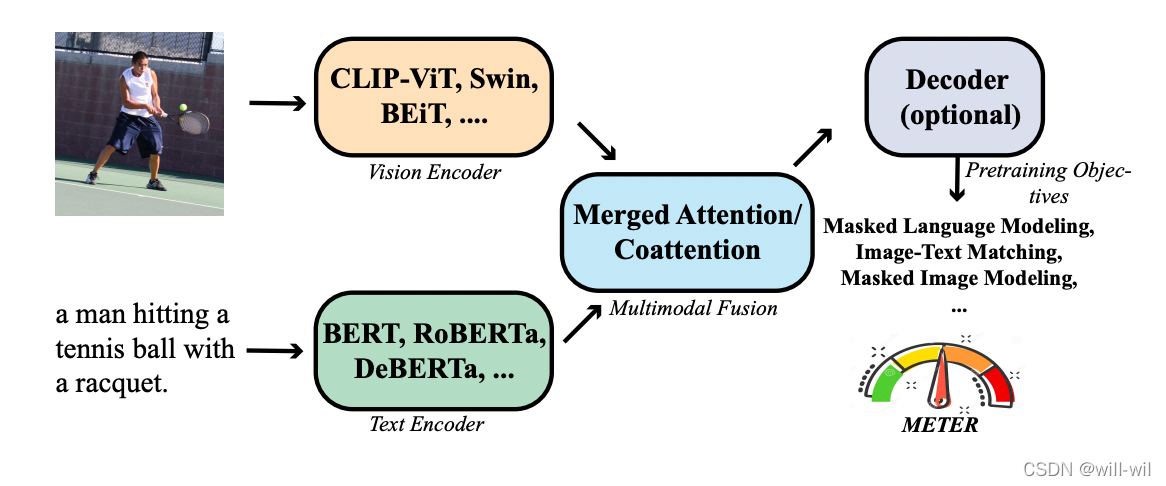
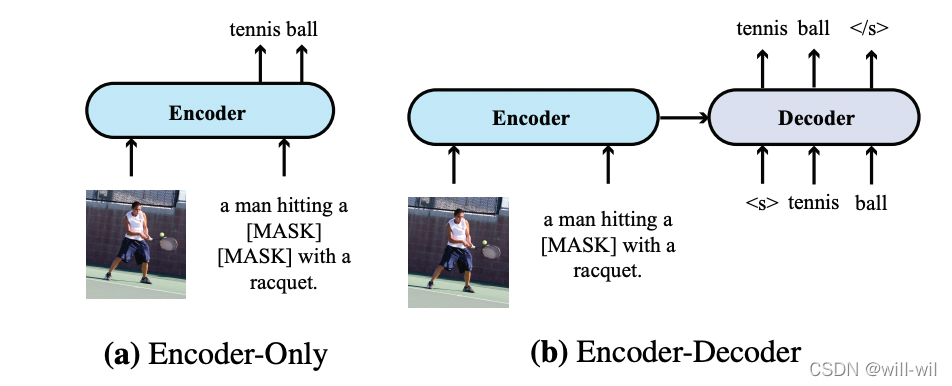
基本流程:
- 输入图片,通过Vision Encoder模块抽取图像特征
- 输入文本,通过Text Endocer模块抽取文本特征
- 输入图像、文本特征,通过Multimodal Fusion模块融合跨模态特征,得到cross-modal representations。
- cross-modal representations经过Decoder得到最终结果(可选),如右图所示,例如分类任务,信息输入encoder,然后feed分类token到decoder最终生成分类结果。
previous研究提取特征部分的不足
- Region Features:图像端采用object detectors抽取图像区域特征,作为图像端embedding,该方法存在的问题
- 原始detectors并不完美,但是在VLP过程中经常是作为第一阶段抽取图像embedding,模型并不训练更新,从而限制了VLP模型的能力。
- 抽取图像区域特征相当耗时。
- CNN-based Grid Features:尝试用端到端的形式解决1中的两个问题,采用CNN获取图像特征。该方法存在的问题
- 文本端用transformer编码,图像端用CNN编码,但是两种方法的优化方法不一致,前者AdamW,后者为SGD。
- 最近的工作证明采用vision transformers(ViT)编码会优于CNN编码,具有更高的准确性。
METER模型框架
模型架构探索:
- Vision Encoder:采用ViT架构,将图像分割成块,经由embedding层得到词向量feed入transformer模型。针对目前存在的不同ViT架构综合分析,以求得到最适合VLP的ViT结构,如original ViT、Swin Transformer、CLIP-ViT等。
- Text Encoder:采用类BERT模型架构,将输入句子分词feed得到文本embedding。针对目前存在的BERT以及BERT的衍生模型综合分析,如BERT、RoBERTa、ELECTRA、ALBERT等。
- Multimodal Fusion:多模态融合方式有两种,co-attention和merged attention。co-attention-两种特征分别独立feed进不同transformer,采用cross-attn交互;merged attention-拼接两种特征feed进transformer。
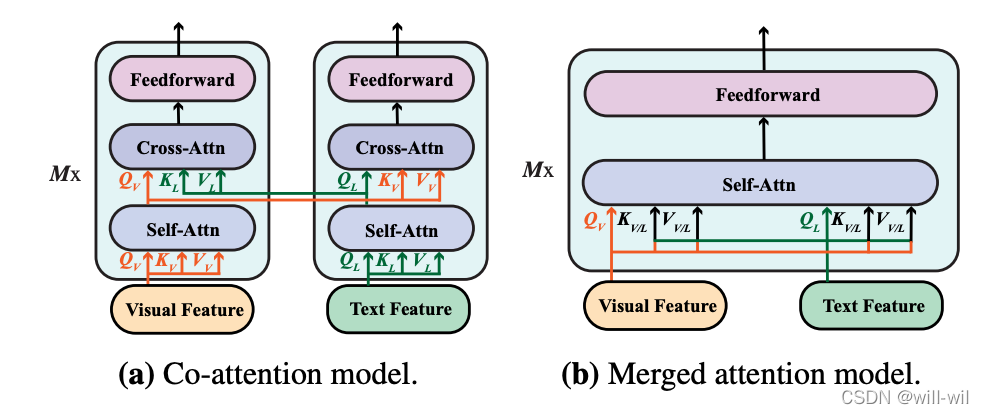
预训练任务探索:
- Masked Language Modeling:对于image-caption pair,对输入的token随机mask,训练模型重构masked token。
- Image-Text Matching:提供matched or mismatched image-caption pairs,训练模型识别image和caption是否对应,二分类任务。
- Masked Image Modeling:与MLM相似,输入的图像特征为v = <v1,· · · , vn>,其中v1为region特征,随机对其进行mask,训练模型重建特征Ov复原,loss采用
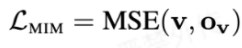 但是最近的sorta模型并不采用该训练任务,改进任务进行测试验证该任务是否有效。
但是最近的sorta模型并不采用该训练任务,改进任务进行测试验证该任务是否有效。
- 模仿MLM采用text vocabulary的形式,构建动态image patch bocabulary,构建的候选词表来源于batch image-caption pairs中images的patches。
Experiments:
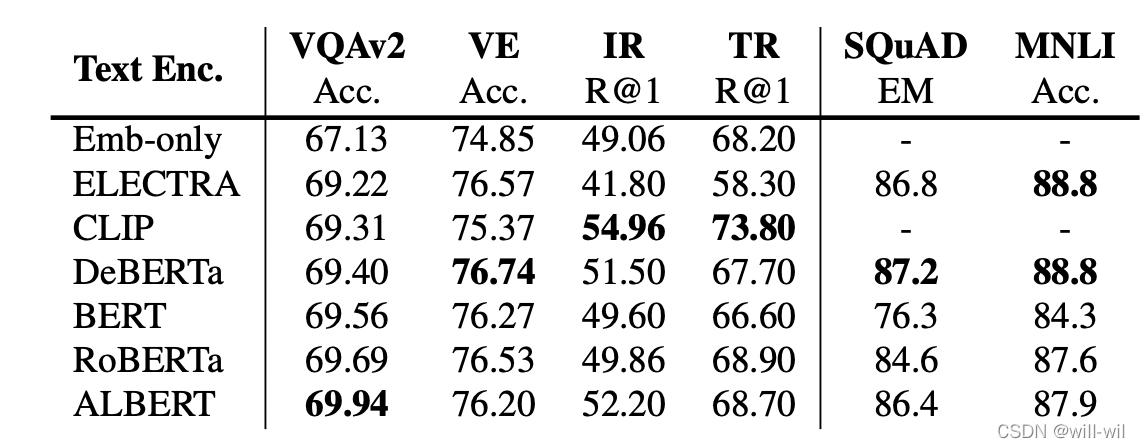
- Impact of Text Encoders(without VLP),得出 RoBERTa模型效果最好,理由:性能鲁棒性最强。
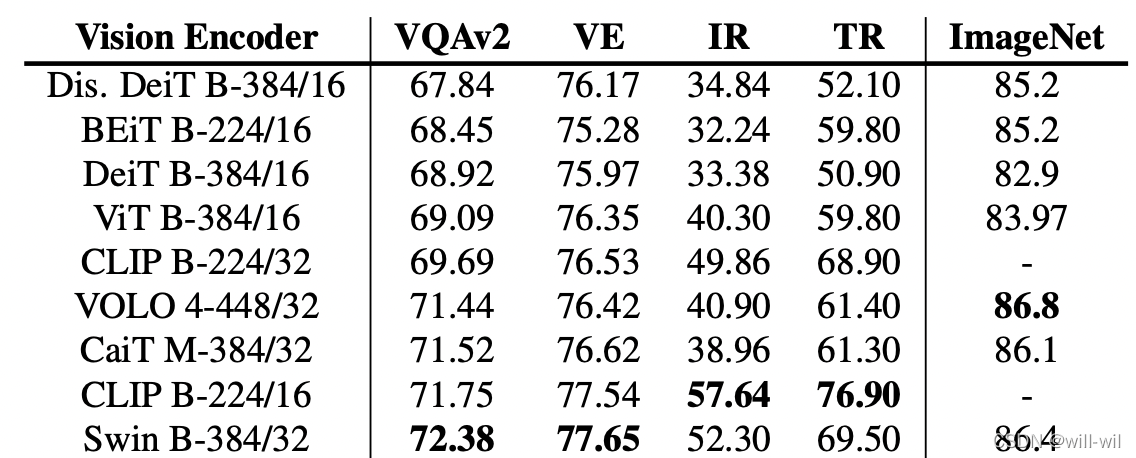
- Impact of Vision Encoders(without VLP),得出CLIP-ViT-224/16 and Swin Transformer模型效果最好。
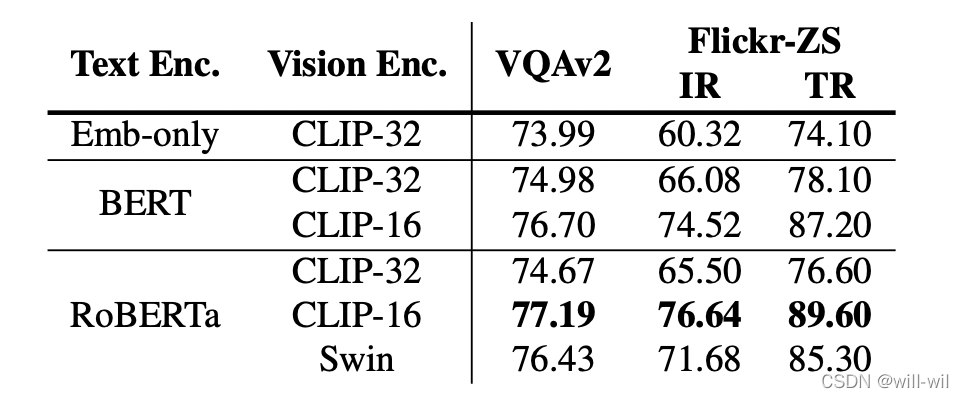
- Result with VLP
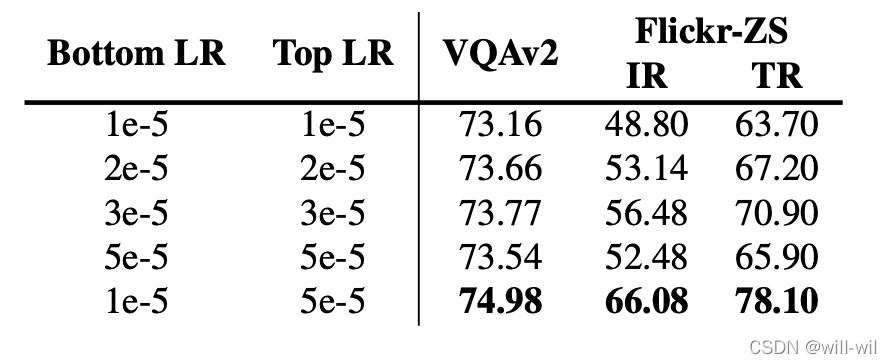
- Useful Trick
- 预训练模型参数初始化的模型小学习率较优,随机初始化参数的模型大学习率较优。
- 模型效果与图像的分辨率成正相关,越大效果越好
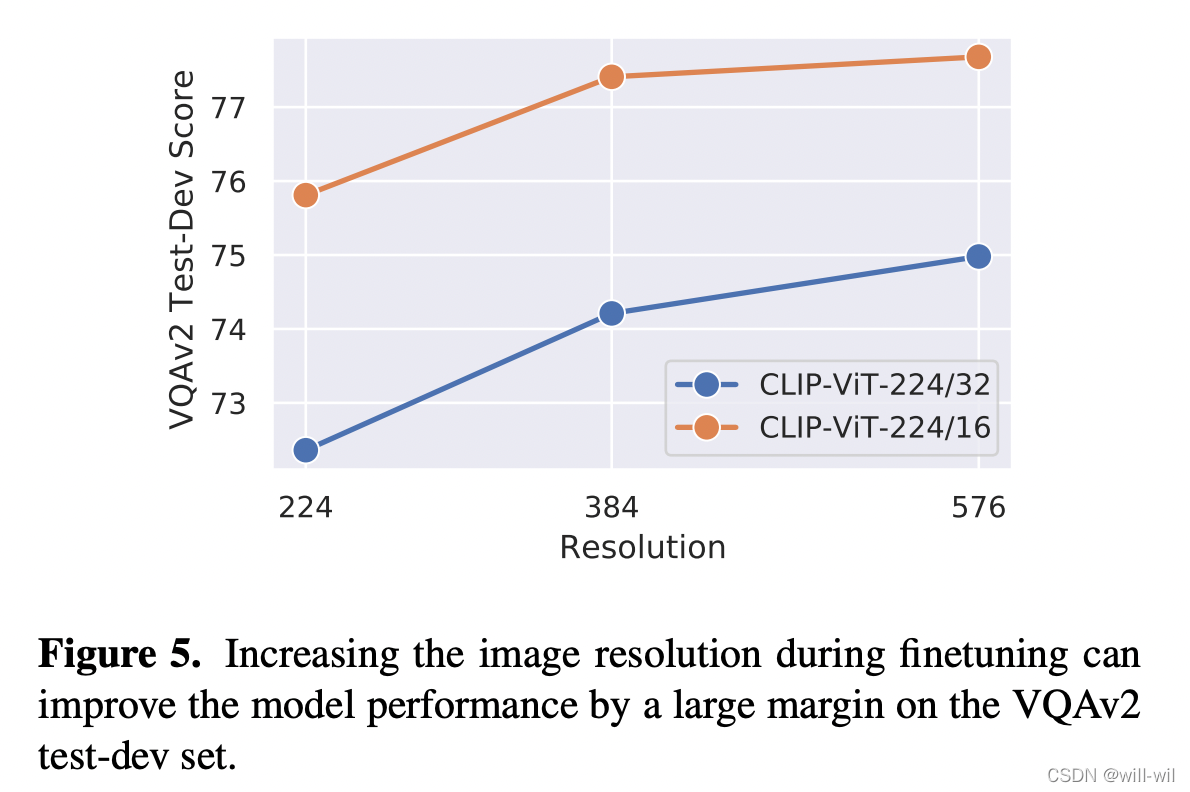
- 预训练模型参数初始化的模型小学习率较优,随机初始化参数的模型大学习率较优。
- experiment of Multimodal Fusion Modules

- 融合策略上:co-attention model > the merged attention model
- 解码端部分: encoder-only model > encoder-decoder model(生成任务上则不一定)
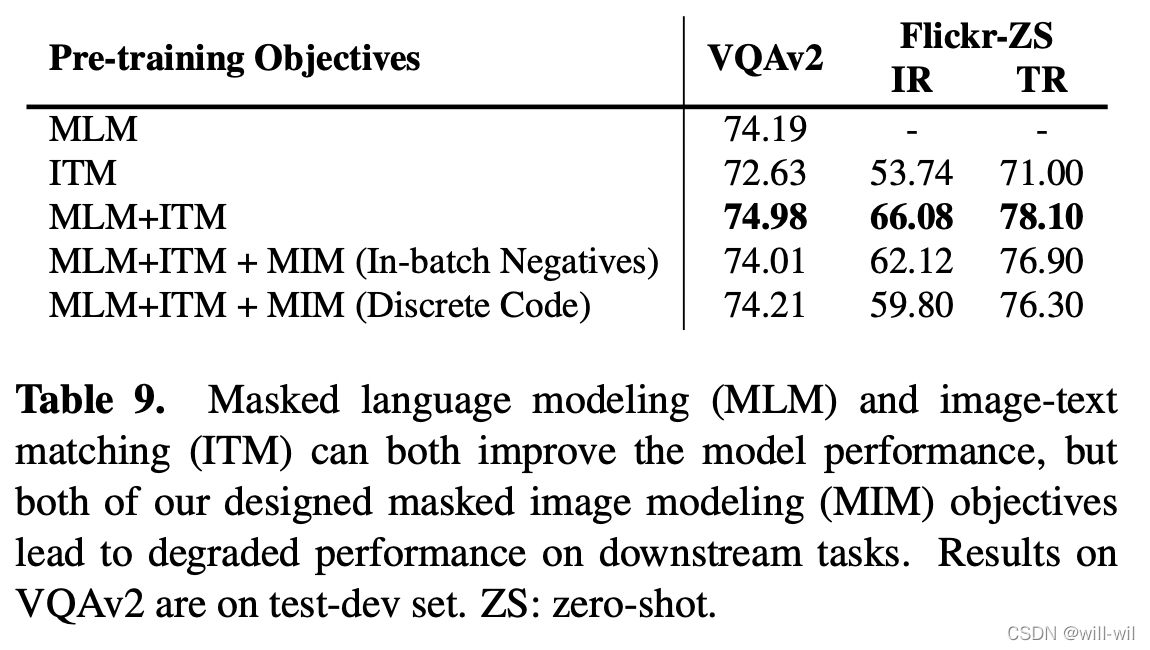
- Impact of Pre-training Object,得出结论MLM+ITM预训练任务最优,MIM任务对预训练模型起反作用。
模型最终结果实验
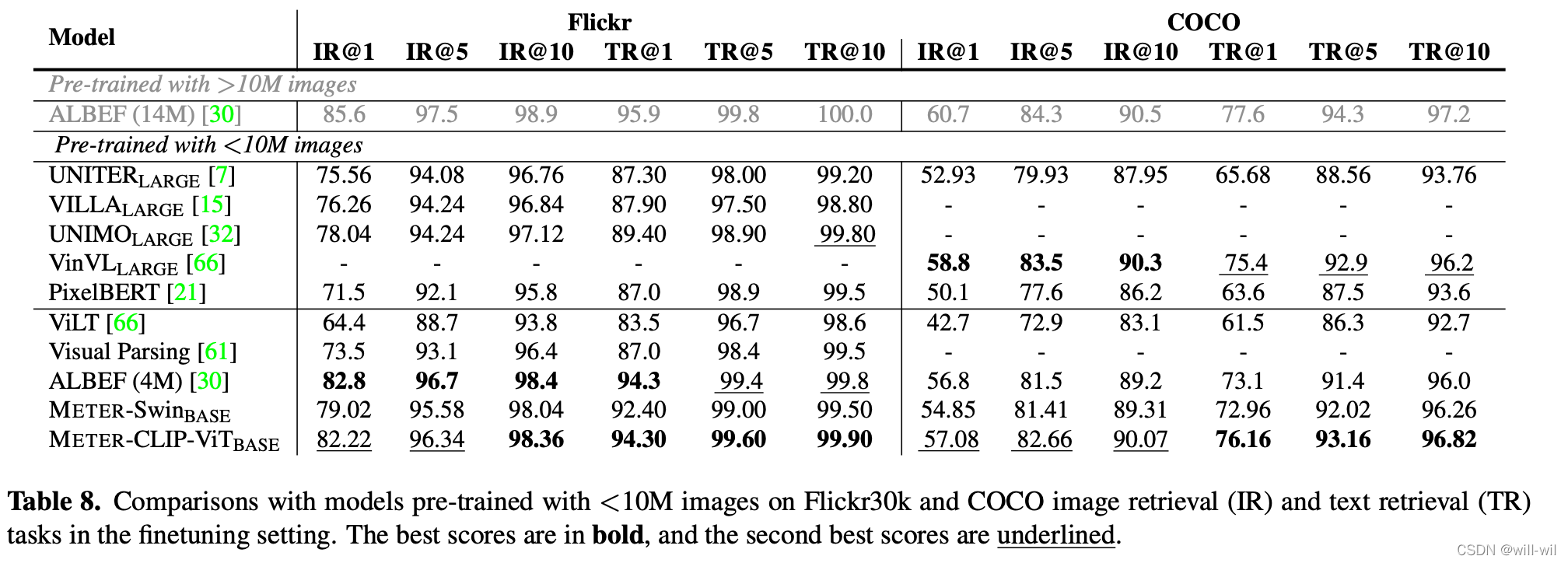
最终结论:模型结构上Roberta+CLIP-ViT+Merged attention,预训练任务上MLM+ITM的VLP组合能达到目前的SOTA。(作者强调论文模型只用了4M的图像预训练数据)

















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









