








文章目录
一、机器学习与应用
1.“人工智能之父”–艾伦.图灵
图灵测试(1950)

2.人工智能的知识图谱
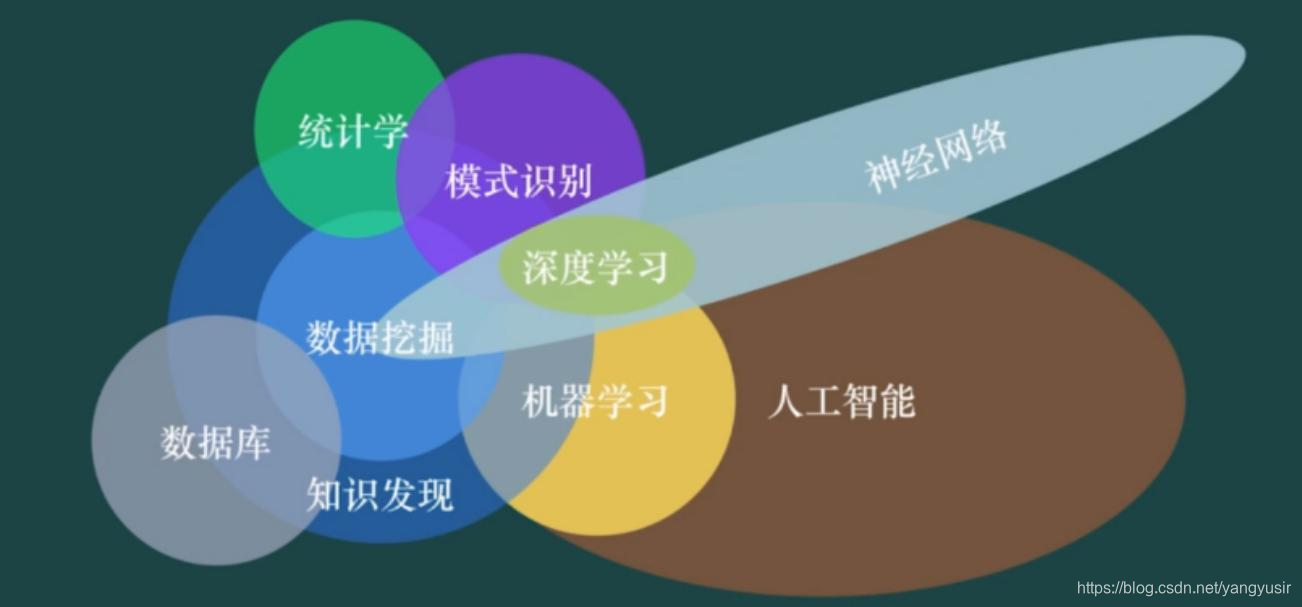
二、AI,ML,DL的关系
1.机器学习是实现人工智能的一种方法,深度学习是机器学习一个分支
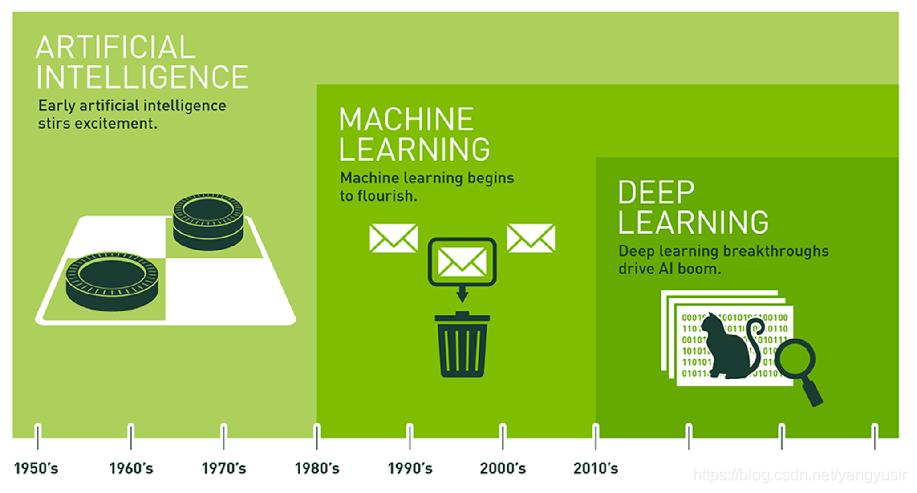
2.机器学习领域
自然语言处理
图像处理
传统预测
学习完之后可以干什么?
图像处理
图像识别
图像处理
人脸识别


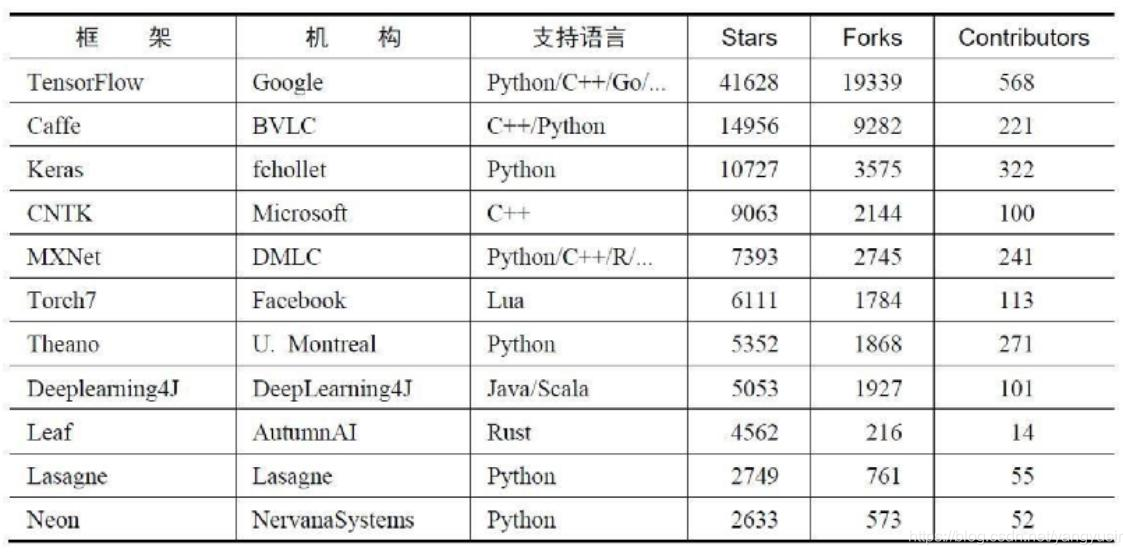
3.机器学习库和框架
4.什么是机器学习?
机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测


5.为什么需要机器学习?
5.1 解放生产力,智能客服
5.2 解决专业问题,ET医疗
5.3 提供社会便利,城市大脑
三、机器学习应用程序的步骤
1.收集数据
2.准备输入数据
3.分析输入数据
4.训练算法
5.测试算法
6.使用算法
四、数据来源与类型
1.数据来源
1.企业日益积累的大量数据(互联网公司更为显著)
2.政府掌握的各种数据
3.科研机构的实验数据
2.数据类型
离散型数据:由记录不同类别个体的数目所得到的数据,又称计数数据,所有这
些数据全部都是整数,而且不能再细分,也不能进一步提高他们的精确度。
连续型数据:变量可以在某个范围内取任一数,即变量的取值可以是连续的,如,
长度、时间、质量值等,这类整数通常是非整数,含有小数部分。
3.可用数据集
- Kaggle特点
(1)大数据竞赛平台
(2)80万科学家
(3)真实数据
(4)数据量巨大
(5)Kaggle网址:https://www.kaggle.com/datasets - scikit-learn特点(自带数据集,方便演示)
(1) 数据量较小
(2)方便学习
(3)scikit-learn网址:http://scikit-learn.org/stable/datasets - UCI特点
(1)收录了360个数据集
(2)覆盖科学、生活、经济等领域
(3)数据量几十万
(4)UCI数据集网址: http://archive.ics.uci.edu/ml/
4.常用数据集数据的结构组成
结构:特征值+目标值
五、数据的特征工程
1.特征工程是什么?
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的模型准确性
2.特征工程的意义?
直接影响预测结果














 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









