深入理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件
在求取有约束条件的优化问题时,拉格朗日乘子法(Lagrange Multiplier) 和KKT条件是非常重要的两个求取方法,对于等式约束的优化问题,可以应用拉格朗日乘子法去求取最优值;如果含有不等式约束,可以应用KKT条件去求取。当然,这两个方法求得的结果只是必要条件,只有当是凸函数的情况下,才能保证是充分必要条件。KKT条件是拉格朗日乘子法的泛化。之前学习的时候,只知道直接应用两个方法,但是却不知道为什么拉格朗日乘子法(Lagrange Multiplier) 和KKT条件能够起作用,为什么要这样去求取最优值呢?
本文将首先把什么是拉格朗日乘子法(Lagrange Multiplier) 和KKT条件叙述一下;然后开始分别谈谈为什么要这样求最优值。
一. 拉格朗日乘子法(Lagrange Multiplier) 和KKT条件
通常我们需要求解的最优化问题有如下几类:
(i) 无约束优化问题,可以写为:
min f(x);
(ii) 有等式约束的优化问题,可以写为:
min f(x),
s.t. h_i(x) = 0; i =1, ..., n
(iii) 有不等式约束的优化问题,可以写为:
min f(x),
s.t. g_i(x) <= 0; i =1, ..., n
h_j(x) = 0; j =1, ..., m
对于第(i)类的优化问题,常常使用的方法就是Fermat定理,即使用求取f(x)的导数,然后令其为零,可以求得候选最优值,再在这些候选值中验证;如果是凸函数,可以保证是最优解。
对于第(ii)类的优化问题,常常使用的方法就是拉格朗日乘子法(Lagrange Multiplier) ,即把等式约束h_i(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值。
对于第(iii)类的优化问题,常常使用的方法就是KKT条件。同样地,我们把所有的等式、不等式约束与f(x)写为一个式子,也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件。
(a) 拉格朗日乘子法(Lagrange Multiplier)
对于等式约束,我们可以通过一个拉格朗日系数a 把等式约束和目标函数组合成为一个式子L(a, x) = f(x) + a*h(x), 这里把a和h(x)视为向量形式,a是横向量,h(x)为列向量,之所以这么写,完全是因为csdn很难写数学公式,只能将就了.....。
然后求取最优值,可以通过对L(a,x)对各个参数求导取零,联立等式进行求取,这个在高等数学里面有讲,但是没有讲为什么这么做就可以,在后面,将简要介绍其思想。
(b) KKT条件
对于含有不等式约束的优化问题,如何求取最优值呢?常用的方法是KKT条件,同样地,把所有的不等式约束、等式约束和目标函数全部写为一个式子L(a, b, x)= f(x) + a*g(x)+b*h(x),KKT条件是说最优值必须满足以下条件:
1. L(a, b, x)对x求导为零;
2. h(x) =0;
3. a*g(x) = 0;
求取这三个等式之后就能得到候选最优值。其中第三个式子非常有趣,因为g(x)<=0,如果要满足这个等式,必须a=0或者g(x)=0. 这是SVM的很多重要性质的来源,如支持向量的概念。
二. 为什么拉格朗日乘子法(Lagrange Multiplier) 和KKT条件能够得到最优值?
为什么要这么求能得到最优值?先说拉格朗日乘子法,设想我们的目标函数z = f(x), x是向量, z取不同的值,相当于可以投影在x构成的平面(曲面)上,即成为等高线,如下图,目标函数是f(x, y),这里x是标量,虚线是等高线,现在假设我们的约束g(x)=0,x是向量,在x构成的平面或者曲面上是一条曲线,假设g(x)与等高线相交,交点就是同时满足等式约束条件和目标函数的可行域的值,但肯定不是最优值,因为相交意味着肯定还存在其它的等高线在该条等高线的内部或者外部,使得新的等高线与目标函数的交点的值更大或者更小,只有到等高线与目标函数的曲线相切的时候,可能取得最优值,如下图所示,即等高线和目标函数的曲线在该点的法向量必须有相同方向,所以最优值必须满足:f(x)的梯度 = a* g(x)的梯度,a是常数,表示左右两边同向。这个等式就是L(a,x)对参数求导的结果。(上述描述,我不知道描述清楚没,如果与我物理位置很近的话,直接找我,我当面讲好理解一些,注:下图来自wiki)。
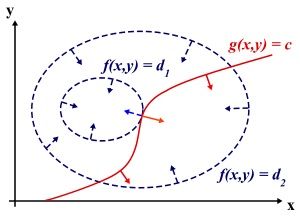
而KKT条件是满足强对偶条件的优化问题的必要条件,可以这样理解:我们要求min f(x), L(a, b, x) = f(x) + a*g(x) + b*h(x),a>=0,我们可以把f(x)写为:max_{a,b} L(a,b,x),为什么呢?因为h(x)=0, g(x)<=0,现在是取L(a,b,x)的最大值,a*g(x)是<=0,所以L(a,b,x)只有在a*g(x) = 0的情况下才能取得最大值,否则,就不满足约束条件,因此max_{a,b} L(a,b,x)在满足约束条件的情况下就是f(x),因此我们的目标函数可以写为 min_x max_{a,b} L(a,b,x)。如果用对偶表达式: max_{a,b} min_x L(a,b,x),由于我们的优化是满足强对偶的(强对偶就是说对偶式子的最优值是等于原问题的最优值的),所以在取得最优值x0的条件下,它满足 f(x0) = max_{a,b} min_x L(a,b,x) = min_x max_{a,b} L(a,b,x) =f(x0),我们来看看中间两个式子发生了什么事情:
f(x0) = max_{a,b} min_x L(a,b,x) = max_{a,b} min_x f(x) + a*g(x) + b*h(x) = max_{a,b} f(x0)+a*g(x0)+b*h(x0) = f(x0)
可以看到上述加黑的地方本质上是说 min_x f(x) + a*g(x) + b*h(x) 在x0取得了最小值,用fermat定理,即是说对于函数 f(x) + a*g(x) + b*h(x),求取导数要等于零,即
f(x)的梯度+a*g(x)的梯度+ b*h(x)的梯度 = 0
这就是kkt条件中第一个条件:L(a, b, x)对x求导为零。
而之前说明过,a*g(x) = 0,这时kkt条件的第3个条件,当然已知的条件h(x)=0必须被满足,所有上述说明,满足强对偶条件的优化问题的最优值都必须满足KKT条件,即上述说明的三个条件。可以把KKT条件视为是拉格朗日乘子法的泛化。
最优化理论与KKT条件
1. 最优化理论(Optimization Theory)
最优化理论是研究函数在给定一组约束条件下的最小值(或者最大值)的数学问题. 一般而言, 一个最优化问题具有如下的基本形式:
s.t.:gi(x)≤0,i=1,2,...,p,hj(x)=0,k=1,2,...,q,x∈Ω⊂Rn
其中.
f(x)
为目标函数,
gi(x)≤0,i=1,2,…,p
为不等式约束条件,
hj(x)=0,k=1,2,…,q
为等式约束条件.
在很多情况下, 不等式约束条件可以通过引入新的变量而转化为等式约束条件, 因此最优化问题的一般形式可以简化为仅仅包含等式约束条件的形式
最优化问题可以根据目标函数和约束条件的类型进行分类:
1). 如果目标函数和约束条件都为变量的线性函数, 称该最优化问题为线性规划;
2). 如果目标函数为变量的二次函数, 约束条件为变量的线性函数, 称该最优化问题为二次规划;
3). 如果目标函数或者约束条件为变量的非线性函数, 称该最优化问题为非线性规划.
2. KKT(Karush-Kuhn-Tucker)
KTT条件是指在满足一些有规则的条件下, 一个非线性规划(Nonlinear Programming)问题能有最优化解法的一个必要和充分条件. 这是一个广义化拉格朗日乘数的成果. 一般地, 一个最优化数学模型的列标准形式参考开头的式子, 所谓 Karush-Kuhn-Tucker 最优化条件,就是指上式的最优点
x∗
必须满足下面的条件:
1). 约束条件满足
gi(x∗)≤0,i=1,2,…,p
, 以及
,hj(x∗)=0,j=1,2,…,q
2).
∇f(x∗)+∑i=1pμi∇gi(x∗)+∑j=1qλj∇hj(x∗)=0
, 其中
∇
为梯度算子;
3).
λj≠0
且不等式约束条件满足
μi≥0,μigi(x∗)=0,i=1,2,…,p
KKT最优化条件是Karush[1939]以及Kuhn和Tucker[1951]先后独立发表出来的. 这组最优化条件在Kuhn和Tucker发表之后才逐渐受到重视, 因此许多书只记载成「Kuhn-Tucker 最优化条件 (Kuhn-Tucker conditions)」.
KKT条件第一项是说最优点
x∗
必须满足所有等式及不等式限制条件, 也就是说最优点必须是一个可行解, 这一点自然是毋庸置疑的. 第二项表明在最优点
x∗
,
∇f
必须是
∇gi
和
∇hj
的线性組合,
μi
和
λj
都叫作拉格朗日乘子. 所不同的是不等式限制条件有方向性, 所以每一个
μi
都必须大于或等于零, 而等式限制条件没有方向性,所以
λj
没有符号的限制, 其符号要视等式限制条件的写法而定.
3. 关于duality
一位博友对duality的总结很通俗易懂, http://blog.pluskid.org/?p=702 这里就不再重复复述了.
此条目由 jacoxu 发表在 Support Vector Machine 分类目录,并贴了 duality、KKT、最优化 标签。将固定链接加入收藏夹。
拉格朗日乘子法(Lagrange Multiplier)和KKT(Karush-Kuhn-Tucker)条件是求解约束优化问题的重要方法,在有等式约束时使用拉格朗日乘子法,在有不等约束时使用KKT条件。前提是:只有当目标函数为凸函数时,使用这两种方法才保证求得的是最优解。
对于无约束最优化问题,有很多经典的求解方法,参见无约束最优化方法。
拉格朗日乘子法
先来看拉格朗日乘子法是什么,再讲为什么。
minf(x)s.t.hi(x)=0i=1,2...,n
这个问题转换为
min[f(x)+∑i=1nλihi(x)](1)
其中
λi≠0
,称为拉格朗日乘子。
下面看一下wikipedia上是如何解释拉格朗日乘子法的合理性的。
现有一个二维的优化问题:
minf(x,y)s.t.g(x,y)=c
我们可以画图来辅助思考。

绿线标出的是约束
g(x,y)=c
的点的轨迹。蓝线是
f(x,y)
的等高线。箭头表示斜率,和等高线的法线平行。
从图上可以直观地看到在最优解处,f和g的斜率平行。
▽[f(x,y)+λ(g(x,y)−1)]=0λ≠0
一旦求出
λ
的值,将其套入下式,易求在无约束极值和极值所对应的点。
F(x,y)=f(x,y)+λ(g(x,y)−c)
新方程
F(x,y)
在达到极值时与
f(x,y)
相等,因为
F(x,y)
达到极值时
g(x,y)−c
总等于零。
(1)
取得极小值时其导数为0,即
▽f(x)+▽∑ni=1λihi(x)=0
,也就是说
f(x)
和
h(x)
的梯度共线。
KKT条件
先看KKT条件是什么,再讲为什么。
letL(x,μ)=f(x)+∑qk=1μkgk(x)
其中
μk≥0,gk(x)≤0
∵μk≥0gk(x)≤0}
=>
μg(x)≤0
∴
maxμL(x,μ)=f(x)(2)
∴
minxf(x)=minxmaxμL(x,μ)(3)
maxμminxL(x,μ)=maxμ[minxf(x)+minxμg(x)]=maxμminxf(x)+maxμminxμg(x)=minxf(x)+maxμminxμg(x)
又
∵μk≥0gk(x)≤0}
=>
minxμg(x)={0−∞ifμ=0org(x)=0ifμ>0andg(x)<0
∴maxμminxμg(x)=0
此时
μ=0org(x)=0
∴maxμminxL(x,μ)=minxf(x)+maxμminxμg(x)=minxf(x)(4)
此时
μ=0org(x)=0
联合
(3)
,
(4)
我们得到
minxmaxμL(x,μ)=maxμminxL(x,μ)
亦即
L(x,μ)=f(x)+∑qk=1μkgk(x)μk≥0gk(x)≤0⎫⎭⎬⎪⎪
=>
minxmaxμL(x,μ)=maxμminxL(x,μ)=minxf(x)
我们把
maxμminxL(x,μ)
称为原问题
minxmaxμL(x,μ)
的对偶问题,上式表明当满足一定条件时原问题、对偶的解、以及
minxf(x)
是相同的,且在最优解
x∗
处
μ=0org(x∗)=0
。把
x∗
代入
(2)
得
maxμL(x∗,μ)=f(x∗)
,由
(4)
得
maxμminxL(x,μ)=f(x∗)
,所以
L(x∗,μ)=minxL(x,μ)
,这说明
x∗
也是
L(x,μ)
的极值点,即
∂L(x,μ)∂x|x=x∗=0
。
最后总结一下:
L(x,μ)=f(x)+∑qk=1μkgk(x)μk≥0gk(x)≤0⎫⎭⎬⎪⎪
=>
⎧⎩⎨⎪⎪⎪⎪minxmaxμL(x,μ)=maxμminxL(x,μ)=minxf(x)=f(x∗)μkgk(x∗)=0∂L(x,μ)∂x|x=x∗=0
KKT条件是拉格朗日乘子法的泛化,如果我们把等式约束和不等式约束一并纳入进来则表现为:
L(x,λ,μ)=f(x)+∑ni=1λihi(x)+∑qk=1μkgk(x)λi≠0hi(x)=0μk≥0gk(x)≤0⎫⎭⎬⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪
=>
⎧⎩⎨⎪⎪⎪⎪minxmaxμL(x,λ,μ)=maxμminxL(x,λ,μ)=minxf(x)=f(x∗)μkgk(x∗)=0∂L(x,λ,μ)∂x|x=x∗=0
注:
x,λ,μ
都是向量。
∂L(x,λ,μ)∂x|x=x∗=0
表明
f(x)
在极值点
x∗
处的梯度是各个
hi(x∗)
和
gk(x∗)
梯度的线性组合。
原文来自:博客园(华夏35度)http://www.cnblogs.com/zhangchaoyang
网址:http://jacoxu.com/?p=78
网址:http://blog.csdn.net/xianlingmao/article/details/7919597























 43万+
43万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









