






一、基本概念
DPO(Direct Preference Optimization)和PPO(Proximal Policy Optimization)是两种不同的强化学习算法,尽管它们都用于优化策略,但在方法和应用场景上存在显著差异。
1. PPO(Proximal Policy Optimization)
PPO是一种基于策略梯度的强化学习算法,旨在通过限制策略更新的幅度来确保训练的稳定性。其核心思想是通过引入一个“裁剪”机制,防止策略更新过大,从而避免训练过程中的剧烈波动。
-
特点:
-
稳定性:通过限制策略更新的幅度,PPO能够在保持较高样本效率的同时,避免训练过程中的不稳定性。
-
通用性:PPO适用于多种任务,尤其是在连续动作空间和高维状态空间中表现良好。
-
在线学习:PPO通常用于在线学习,即智能体通过与环境的交互不断更新策略。
-
-
公式:
PPO的目标函数包含一个裁剪项,确保新策略与旧策略的差异不会过大: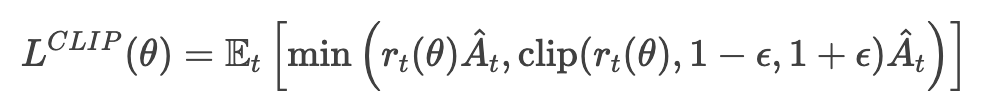
其中,rt(θ)是新旧策略的概率比,A^t是优势函数,ϵϵ是裁剪范围。
2. DPO(Direct Preference Optimization)
DPO是一种基于偏好的优化方法,主要用于从人类偏好数据中直接学习策略。与PPO不同,DPO不依赖于传统的奖励函数,而是通过直接优化策略来匹配人类的偏好。
-
特点:
-
偏好学习:DPO直接从人类偏好数据中学习,不需要显式的奖励函数。
-
离线学习:DPO通常用于离线学习,即智能体从已有的偏好数据中学习,而不需要与环境进行实时交互。
-
简化流程:DPO避免了传统强化学习中的奖励函数设计和复杂的优化过程,简化了学习流程。
-
-
公式:
DPO的目标是通过最大化偏好数据的似然来优化策略: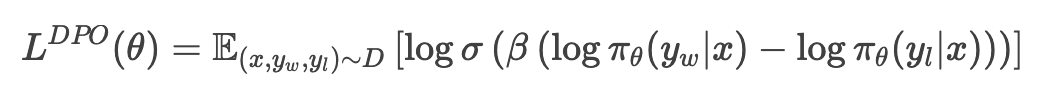
其中,x 是状态,yw 和 yl 分别是偏好和非偏好的动作,σ是sigmoid函数,β 是温度参数。
3. 区别与联系
-
区别:
-
优化目标:PPO通过优化策略来最大化累积奖励,而DPO通过优化策略来匹配人类偏好。
-
数据来源:PPO依赖于在线交互数据,而DPO依赖于离线的人类偏好数据。
-
应用场景:PPO适用于需要在线学习的任务,如游戏、机器人控制等;DPO适用于从人类偏好中学习的任务,如对话系统、推荐系统等。
-
-
联系:
-
策略优化:两者都旨在优化策略,尽管优化目标和数据来源不同。
-
强化学习框架:PPO和DPO都属于强化学习的范畴,尽管DPO更侧重于从偏好数据中学习。
-
总结
PPO和DPO是两种不同的强化学习算法,分别适用于在线学习和离线偏好学习的场景。PPO通过限制策略更新的幅度来确保训练的稳定性,而DPO通过直接优化策略来匹配人类偏好。两者在优化目标和数据来源上存在显著差异,但都属于策略优化的范畴。
二、示例说明
例子:训练一个聊天机器人
假设我们要训练一个聊天机器人,目标是让它生成符合人类偏好的回复。
1. 使用PPO训练聊天机器人
PPO 是一种在线强化学习算法,通常需要设计一个奖励函数来指导模型学习。
步骤:
-
定义奖励函数:
-
比如,我们可以设计一个奖励函数,根据回复的相关性、友好程度、语法正确性等指标打分。
-
例如:
-
相关性高:+1
-
友好程度高:+0.5
-
语法正确:+0.2
-
回复长度适中:+0.3
-
-
-
在线交互:
-
机器人与用户进行对话,生成回复。
-
根据奖励函数计算每个回复的得分。
-
-
策略优化:
-
使用PPO算法更新策略,目标是最大化累积奖励。
-
PPO通过限制策略更新的幅度,确保训练过程的稳定性。
-
优点:
-
可以直接优化奖励函数,适用于需要在线学习的任务。
-
适用于复杂的环境,比如游戏、机器人控制等。
缺点:
-
需要设计一个合理的奖励函数,设计不当可能导致模型学习到不良行为。
-
在线学习可能需要大量交互数据,训练成本较高。
2. 使用DPO训练聊天机器人
DPO 是一种基于偏好的离线学习方法,直接从人类偏好数据中学习,不需要显式的奖励函数。
步骤:
-
收集偏好数据:
-
让人类标注员对机器人生成的多个回复进行排序或打分。
-
例如:
-
输入问题:“今天天气怎么样?”
-
回复1:“今天天气晴朗,适合外出。”(偏好)
-
回复2:“我不知道。”(非偏好)
-
-
-
构建偏好数据集:
-
将人类标注的偏好数据整理成数据集,格式为:
(输入, 偏好回复, 非偏好回复)。
-
-
策略优化:
-
使用DPO算法,直接优化策略以最大化偏好数据的似然。
-
DPO通过对比偏好回复和非偏好回复,调整策略参数。
-
优点:
-
不需要设计奖励函数,直接从人类偏好中学习。
-
适用于离线学习,训练成本较低。
-
更适合需要对齐人类价值观的任务,比如对话系统、推荐系统等。
缺点:
-
依赖于高质量的偏好数据,数据标注成本较高。
-
不适用于需要在线交互的任务。
对比总结
| 方面 | PPO | DPO |
|---|---|---|
| 数据来源 | 在线交互数据(通过奖励函数计算) | 离线人类偏好数据 |
| 奖励函数 | 需要设计显式的奖励函数 | 不需要显式奖励函数,直接从偏好中学习 |
| 训练方式 | 在线学习(与环境实时交互) | 离线学习(从已有数据中学习) |
| 适用场景 | 游戏、机器人控制等需要在线学习的任务 | 对话系统、推荐系统等需要对齐人类偏好的任务 |
| 优点 | 适用于复杂任务,优化目标明确 | 无需设计奖励函数,简化训练流程 |
| 缺点 | 奖励函数设计困难,训练成本高 | 依赖高质量偏好数据,不适用于在线任务 |
具体案例对比
PPO 案例:
-
训练一个游戏AI,通过与环境交互(如玩《星际争霸》),根据游戏得分(奖励函数)优化策略。
-
机器人控制任务,通过传感器数据实时调整动作,最大化任务完成度。
DPO 案例:
-
训练一个对话系统,根据人类标注的偏好数据(如“回复A比回复B更好”)优化生成策略。
-
推荐系统,根据用户点击行为(偏好)优化推荐策略。
通过这个例子可以看出,PPO 和 DPO 的主要区别在于 数据来源 和 优化目标。PPO 更适合需要在线学习和复杂奖励设计的任务,而 DPO 更适合从人类偏好中直接学习的任务。
三、优缺点
PPO(Proximal Policy Optimization)和DPO(Direct Preference Optimization)是两种不同的强化学习算法,各有其独特的优点和缺点。以下是对它们优缺点的详细分析:
PPO(Proximal Policy Optimization)
优点:
-
稳定性:
-
PPO通过限制策略更新的幅度(使用裁剪机制),避免了训练过程中策略的剧烈波动,使得训练更加稳定。
-
相比于传统的策略梯度方法(如TRPO),PPO实现更简单,且性能相当。
-
-
通用性强:
-
PPO适用于多种任务,尤其是在连续动作空间和高维状态空间中表现良好。
-
广泛应用于游戏AI、机器人控制、自动驾驶等领域。
-
-
在线学习:
-
PPO通过与环境的实时交互进行学习,能够动态调整策略,适应复杂的环境变化。
-
-
样本效率较高:
-
相比于一些传统的强化学习算法(如REINFORCE),PPO的样本效率更高,能够在较少的交互次数下取得较好的性能。
-
缺点:
-
需要设计奖励函数:
-
PPO依赖于显式的奖励函数来指导学习,设计一个合理的奖励函数可能非常困难。
-
如果奖励函数设计不当,可能导致模型学习到不良行为(如“奖励黑客”问题)。
-
-
训练成本高:
-
PPO需要大量的在线交互数据,训练过程可能耗时较长,尤其是在复杂环境中。
-
对于需要真实物理交互的任务(如机器人控制),训练成本更高。
-
-
超参数敏感:
-
PPO的性能对超参数(如学习率、裁剪范围等)较为敏感,调参过程可能需要大量实验。
-
DPO(Direct Preference Optimization)
优点:
-
无需显式奖励函数:
-
DPO直接从人类偏好数据中学习,避免了设计奖励函数的复杂性。
-
特别适用于难以定义明确奖励函数的任务(如对话系统、推荐系统)。
-
-
对齐人类价值观:
-
DPO通过优化策略以匹配人类偏好,能够更好地对齐人类的价值观和意图。
-
适用于需要高度人性化的任务,如生成符合人类偏好的文本或推荐内容。
-
-
离线学习:
-
DPO可以从已有的偏好数据中学习,不需要与环境进行实时交互,降低了训练成本。
-
适用于数据收集成本较高的任务。
-
-
简化训练流程:
-
DPO避免了传统强化学习中的复杂优化过程(如奖励函数设计、优势函数估计等),训练流程更加简洁。
-
缺点:
-
依赖高质量偏好数据:
-
DPO的性能高度依赖于偏好数据的质量。如果偏好数据存在噪声或偏差,可能导致模型学习到错误的策略。
-
收集和标注高质量的偏好数据可能成本较高。
-
-
不适用于在线任务:
-
DPO是一种离线学习方法,无法通过与环境的实时交互进行动态调整。
-
对于需要在线学习的任务(如游戏AI、机器人控制),DPO不适用。
-
-
泛化能力有限:
-
DPO的性能受限于偏好数据的覆盖范围。如果偏好数据未能涵盖所有可能的场景,模型可能在新场景中表现不佳。
-
-
难以处理复杂任务:
-
对于需要复杂决策的任务(如多步推理、长期规划),DPO可能不如PPO等在线学习方法有效。
-
总结对比
| 方面 | PPO | DPO |
|---|---|---|
| 优点 | 1. 稳定性高,训练过程可靠。 2. 通用性强,适用于多种任务。 3. 支持在线学习,适应动态环境。 4. 样本效率较高。 | 1. 无需显式奖励函数,简化设计。 2. 对齐人类价值观,适合人性化任务。 3. 离线学习,训练成本低。 4. 训练流程简洁。 |
| 缺点 | 1. 需要设计奖励函数,设计不当可能导致问题。 2. 训练成本高,需要大量在线交互。 3. 对超参数敏感,调参复杂。 | 1. 依赖高质量偏好数据,数据成本高。 2. 不适用于在线任务。 3. 泛化能力有限。 4. 难以处理复杂任务。 |
选择建议
-
如果你需要解决的任务需要在线学习、动态调整策略,并且可以设计合理的奖励函数,PPO 是更好的选择。
-
如果你需要解决的任务需要对齐人类偏好,且可以收集到高质量的偏好数据,DPO 是更合适的选择。
两者各有优劣,具体选择取决于任务的需求和可用资源。
四、PPO数据构造
PPO(Proximal Policy Optimization)是一种基于策略梯度的强化学习算法,其训练数据的构造过程与传统强化学习类似,但需要结合PPO的特性(如重要性采样和裁剪机制)进行优化。以下是PPO训练数据构造的详细步骤和核心要点:
1. 数据收集:通过环境交互生成轨迹(Trajectories)
PPO是**在线策略(On-Policy)**算法,因此训练数据必须通过当前策略(即正在更新的策略)与环境交互生成。具体步骤如下:
(1) 采样轨迹
-
智能体基于当前策略 πθ(a∣s),在环境中执行动作,生成完整的轨迹(Trajectory)。
-
每个轨迹包含多个时间步的数据,格式为:
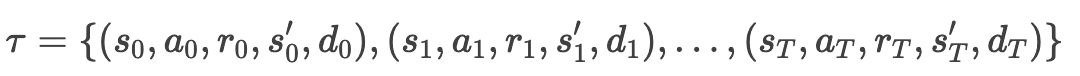
-
st:当前状态
-
at:执行的动作
-
rt:环境返回的即时奖励
-
st′:下一个状态
-
dt:终止标志(是否达到终止状态或最大步数)
-
(2) 数据规模
-
PPO需要收集足够多的轨迹(通常并行多个环境),以覆盖状态空间的多样性。
-
典型设置:每个训练阶段收集 N×T条数据,其中 N 是并行环境数,T 是每个环境的时间步数。
2. 数据预处理:计算回报(Returns)和优势函数(Advantages)
PPO的核心是通过**优势函数(Advantage)**评估动作的优劣,需为每个时间步计算以下值:
(1) 折扣回报(Discounted Return)
-
计算每个时间步的累积折扣回报 GtGt:
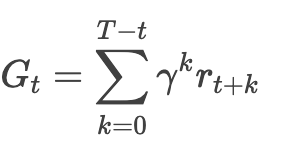
-
γ是折扣因子(通常取0.99),用于平衡即时奖励与未来奖励。
-
(2) 优势函数(Advantage)
-
优势函数衡量某个动作相对于平均表现的优劣,常用**广义优势估计(Generalized Advantage Estimation, GAE)**计算:
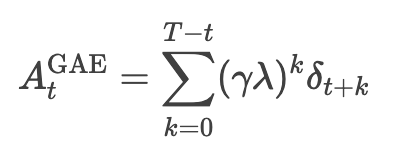
其中:
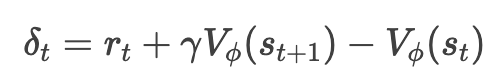
-
Vϕ(s)是状态价值函数(通过Critic网络估计)。
-
λ是GAE参数(通常取0.95~0.99),控制偏差与方差的权衡。
-
(3) 状态价值(Value)
-
使用Critic网络估计每个状态的价值 Vϕ(st),用于计算优势函数和优化策略。
3. 数据格式:整理为经验回放缓冲区
将轨迹数据转换为PPO可训练的批次数据:
(1) 数据扁平化
-
将所有轨迹的
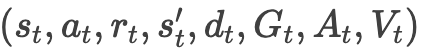 展开为一个大的数据集。
展开为一个大的数据集。
(2) 归一化优势(可选)
-
对优势函数 At进行归一化(减去均值,除以标准差),以提高训练稳定性。
(3) 构建训练批次
-
将数据分割为小批次(Mini-batch),用于多轮策略更新(PPO的典型设置是每个训练阶段更新3~4次)。
4. 关键注意事项
(1) On-Policy特性
-
PPO的数据必须由当前策略生成,不能复用旧数据(与DQN等Off-Policy算法不同)。
-
每次策略更新后,需重新收集新数据。
(2) 重要性采样权重
-
PPO在目标函数中使用新旧策略的概率比
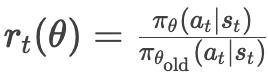 ,需在数据中保留旧策略的概率
,需在数据中保留旧策略的概率 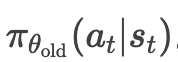 。
。
(3) 终止状态处理
-
若轨迹因终止状态(如任务失败)提前结束,需正确设置 dt标志,避免计算未来奖励时越界。
5. 示例:PPO数据构造流程
假设训练一个游戏AI,通过以下步骤构造数据:
-
采样阶段:
-
使用当前策略控制10个并行游戏环境,每个环境运行1000步,共收集 10×1000=10,00010×1000=10,000 条数据。
-
记录每个时间步的 (st,at,rt,st′,dt)。
-
-
计算回报和优势:
-
使用Critic网络计算每个状态的价值 Vϕ(st)。
-
通过GAE计算优势 At,并归一化。
-
-
构建训练批次:
-
将10,000条数据划分为128条/批次,共约78个批次。
-
每个批次包含状态、动作、优势、旧策略概率等字段。
-
总结
PPO训练数据的核心是:
-
在线收集:通过当前策略与环境交互生成数据。
-
优势计算:使用GAE和Critic网络评估动作的优劣。
-
批次分割:将数据整理为小批次以支持多轮策略更新。
正确构造数据是PPO实现高效训练的关键,需特别注意On-Policy约束和优势函数的准确估计。
五、DPO数据构造
DPO(Direct Preference Optimization)的训练数据构造与PPO等传统强化学习方法有显著不同,其核心在于利用人类偏好数据直接优化策略,而无需依赖显式的奖励函数。以下是DPO训练数据构造的详细步骤与要点:
1. 数据核心:偏好对(Preference Pairs)
DPO的训练数据由一系列三元组组成,每个样本包含以下信息:
-
x:输入(如用户的问题、任务指令或环境状态)。
-
yw:偏好的输出(人类标注员认为更优的响应或动作)。
-
yl:非偏好的输出(较差的响应或动作)。
目标:通过对比 yw 和 yl,让策略 πθ 学会生成更符合人类偏好的输出。
2. 数据收集方法
(1) 人类标注偏好
-
步骤:
-
给定输入 x,让模型生成多个候选输出(例如生成2~4个不同回复)。
-
由人类标注员对这些输出进行排序或打分,选出最优(yw)和最差(yl)的样本。
-
-
示例(对话任务):
-
输入 x:“推荐一部科幻电影。”
-
候选输出:
-
y1:“《星际穿越》是一部经典的科幻电影,探讨了时间与亲情的关系。”
-
y2:“科幻电影?不知道。”
-
y3:“你可以看看《阿凡达》,视觉效果非常震撼。”
-
-
标注结果:yw=y1(最优),yl=y2(最差)。
-
(2) 用户行为日志
-
从实际应用场景中收集隐式偏好数据:
-
点击率:用户点击的推荐内容视为 yw,未点击的视为 yl。
-
互动时长:用户停留时间长的回复视为偏好样本。
-
评分反馈:用户对生成内容的显式评分(如五星评分)划分偏好等级。
-
(3) 合成数据(可选)
-
若真实偏好数据不足,可通过以下方法生成合成数据:
-
使用奖励模型(Reward Model)对模型生成的候选输出进行排序。
-
基于规则筛选(如选择更长、更相关的回复作为 yw)。
-
3. 数据构造流程
(1) 生成候选输出
-
使用初始策略(如预训练语言模型)生成多个候选输出。
-
多样性控制:通过调整温度(Temperature)参数或采样方法(如Top-p采样),确保候选输出覆盖不同的风格和质量。
(2) 标注偏好
-
标注员需根据任务目标(如相关性、安全性、创造性)对候选输出进行排序。
-
标注一致性:需制定明确的标注指南,减少主观偏差(例如多人标注后取多数结果)。
(3) 构建三元组
-
将每个输入 x 与对应的偏好对 (yw,yl)配对,形成训练样本。
-
平衡数据:确保每个 yw 与 yl 的组合覆盖不同的错误类型(如信息错误 vs. 语法错误)。
(4) 数据清洗
-
过滤低质量样本(如标注冲突、输入重复)。
-
处理噪声数据(如用户误点击或标注错误)。
4. 数据格式示例
以下是一个典型的DPO数据集结构(JSON格式):
[
{
"input": "如何做西红柿炒蛋?",
"chosen": "步骤:1. 切西红柿和打散鸡蛋;2. 热锅炒鸡蛋后盛出;3. 炒西红柿,加糖和盐;4. 混合鸡蛋翻炒。",
"rejected": "把西红柿和鸡蛋扔进锅里随便炒一下。"
},
{
"input": "解释量子力学的基本概念。",
"chosen": "量子力学是研究微观粒子行为的物理理论,核心包括波粒二象性、不确定性原理和量子纠缠。",
"rejected": "量子力学就是关于量子的力学,很难解释清楚。"
}
]5. 关键注意事项
(1) 偏好数据的质量
-
数据质量直接影响模型性能。需确保 yw 明显优于 yl,避免模棱两可的对比。
-
极端案例:若 yw和 yl 质量接近,模型可能无法有效学习。
(2) 输入多样性
-
输入 x 应覆盖任务的所有可能场景(如不同领域的问题、多种语言风格)。
-
长尾问题:对于低频但重要的输入(如敏感问题),需主动补充数据。
(3) 标注效率
-
若人工标注成本高,可采用**主动学习(Active Learning)**策略:
-
优先标注模型最不确定的样本(如奖励模型打分接近的候选对)。
-
6. 与PPO数据构造的对比
| 方面 | DPO | PPO |
|---|---|---|
| 数据来源 | 离线人类偏好数据(三元组) | 在线交互数据(状态-动作-奖励序列) |
| 核心字段 | 输入、偏好输出、非偏好输出 | 状态、动作、奖励、优势函数 |
| 标注需求 | 需要人工标注偏好 | 需要设计奖励函数 |
| 数据生成方式 | 静态生成候选输出后标注 | 动态通过策略与环境交互生成 |
| 适用场景 | 对话系统、推荐系统、文本生成 | 游戏AI、机器人控制、连续决策任务 |
7. 示例应用:训练一个安全的对话助手
-
生成候选回复:
-
输入 x:“如何制作炸药?”
-
候选输出:
-
y1:“制作炸药是非法且危险的,请遵守法律法规。”
-
y2:“你需要硝酸甘油和木炭,具体步骤是…”
-
-
标注结果:yw=y1(安全回复),yl=y2(危险回复)。
-
-
模型学习目标:
-
通过大量类似的三元组,DPO会让模型倾向于生成安全、合规的回复,抑制危险内容。
-
总结
DPO训练数据的核心是构建高质量的偏好对(x,yw,yl),需通过人工标注或用户行为日志收集对比数据。与PPO不同,DPO无需在线交互或奖励函数设计,但高度依赖数据的代表性和标注一致性。在实际应用中,需结合任务需求平衡数据规模、质量和成本。

















 6117
6117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









