









情感分析:又称为倾向性分析和意见挖掘,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,其中情感分析还可以细分为情感极性(倾向)分析,情感程度分析,主客观分析等。
情感极性分析的目的是对文本进行褒义、贬义、中性的判断。在大多应用场景下,只分为两类。例如对于“喜爱”和“厌恶”这两个词,就属于不同的情感倾向。
背景交代:爬虫京东商城某一品牌红酒下所有评论,区分好评和差评,提取特征词,用以区分新的评论【出现品牌名称可以忽视,本文章不涉及打广告哦 o(╯□╰)o】。
示例1(好评)

示例2(差评)

读取文本文件
def text():
f1 = open('E:/工作文件/情感分析案例1/good.txt','r',encoding='utf-8')
f2 = open('E:/工作文件/情感分析案例1/bad.txt','r',encoding='utf-8')
line1 = f1.readline()
line2 = f2.readline()
str = ''
while line1:
str += line1
line1 = f1.readline()
while line2:
str += line2
line2 = f2.readline()
f1.close()
f2.close()
return str
把单个词作为特征
def bag_of_words(words):
return dict([(word,True) for word in words])
print(bag_of_words(text()))

import nltk
from nltk.collocations import BigramCollocationFinder
from nltk.metrics import BigramAssocMeasures
把双个词作为特征,并使用卡方统计的方法,选择排名前1000的双词
def bigram(words,score_fn=BigramAssocMeasures.chi_sq,n=1000):
bigram_finder=BigramCollocationFinder.from_words(words) #把文本变成双词搭配的形式
bigrams = bigram_finder.nbest(score_fn,n) #使用卡方统计的方法,选择排名前1000的双词
newBigrams = [u+v for (u,v) in bigrams]
return bag_of_words(newBigrams)
print(bigram(text(),score_fn=BigramAssocMeasures.chi_sq,n=1000))

把单个词和双个词一起作为特征
def bigram_words(words,score_fn=BigramAssocMeasures.chi_sq,n=1000):
bigram_finder=BigramCollocationFinder.from_words(words)
bigrams = bigram_finder.nbest(score_fn,n)
newBigrams = [u+v for (u,v) in bigrams]
a = bag_of_words(words)
b = bag_of_words(newBigrams)
a.update(b) #把字典b合并到字典a中
return a
print(bigram_words(text(),score_fn=BigramAssocMeasures.chi_sq,n=1000))

结巴分词工具进行分词及词性标注
三种分词模式 :
A、精确模式:试图将句子最精确地切开,适合文本分析。默认是精确模式。
B、全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
C、搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
注:当指定jieba.cut的参数HMM=True时,就有了新词发现的能力。
import jieba
def read_file(filename):
stop = [line.strip() for line in open('E:/工作文件/情感分析案例1/stop.txt','r',encoding='utf-8').readlines()] #停用词
f = open(filename,'r',encoding='utf-8')
line = f.readline()
str = []
while line:
s = line.split('\t')
fenci = jieba.cut(s[0],cut_all=False) #False默认值:精准模式
str.append(list(set(fenci)-set(stop)))
line = f.readline()
return str
安装nltk,pip3 install nltk
from nltk.probability import FreqDist,ConditionalFreqDist
from nltk.metrics import BigramAssocMeasures
获取信息量最高(前number个)的特征(卡方统计)
def jieba_feature(number):
posWords = []
negWords = []
for items in read_file('E:/工作文件/情感分析案例1/good.txt'):#把集合的集合变成集合
for item in items:
posWords.append(item)
for items in read_file('E:/工作文件/情感分析案例1/bad.txt'):
for item in items:
negWords.append(item)
word_fd = FreqDist() #可统计所有词的词频
cond_word_fd = ConditionalFreqDist() #可统计积极文本中的词频和消极文本中的词频
for word in posWords:
word_fd[word] += 1
cond_word_fd['pos'][word] += 1
for word in negWords:
word_fd[word] += 1
cond_word_fd['neg'][word] += 1
pos_word_count = cond_word_fd['pos'].N() #积极词的数量
neg_word_count = cond_word_fd['neg'].N() #消极词的数量
total_word_count = pos_word_count + neg_word_count
word_scores = {}#包括了每个词和这个词的信息量
for word, freq in word_fd.items():
pos_score = BigramAssocMeasures.chi_sq(cond_word_fd['pos'][word], (freq, pos_word_count), total_word_count) #计算积极词的卡方统计量,这里也可以计算互信息等其它统计量
neg_score = BigramAssocMeasures.chi_sq(cond_word_fd['neg'][word], (freq, neg_word_count), total_word_count)
word_scores[word] = pos_score + neg_score #一个词的信息量等于积极卡方统计量加上消极卡方统计量
best_vals = sorted(word_scores.items(), key=lambda item:item[1], reverse=True)[:number] #把词按信息量倒序排序。number是特征的维度,是可以不断调整直至最优的
best_words = set([w for w,s in best_vals])
return dict([(word, True) for word in best_words])
调整设置,分别从四种特征选取方式开展并比较效果
def build_features():
#feature = bag_of_words(text())#第一种:单个词
#feature = bigram(text(),score_fn=BigramAssocMeasures.chi_sq,n=500)#第二种:双词
#feature = bigram_words(text(),score_fn=BigramAssocMeasures.chi_sq,n=500)#第三种:单个词和双个词
feature = jieba_feature(300)#第四种:结巴分词
posFeatures = []
for items in read_file('E:/工作文件/情感分析案例1/good.txt'):
a = {}
for item in items:
if item in feature.keys():
a[item]='True'
posWords = [a,'pos'] #为积极文本赋予"pos"
posFeatures.append(posWords)
negFeatures = []
for items in read_file('E:/工作文件/情感分析案例1/bad.txt'):
a = {}
for item in items:
if item in feature.keys():
a[item]='True'
negWords = [a,'neg'] #为消极文本赋予"neg"
negFeatures.append(negWords)
return posFeatures,negFeatures
获得训练数据
posFeatures,negFeatures = build_features()
from random import shuffle
shuffle(posFeatures)
shuffle(negFeatures) #把文本的排列随机化
train = posFeatures[300:]+negFeatures[300:]#训练集(70%)
test = posFeatures[:300]+negFeatures[:300]#验证集(30%)
data,tag = zip(*test)#分离测试集合的数据和标签,便于验证和测试
def score(classifier):
classifier = SklearnClassifier(classifier)
classifier.train(train) #训练分类器
pred = classifier.classify_many(data) #给出预测的标签
n = 0
s = len(pred)
for i in range(0,s):
if pred[i]==tag[i]:
n = n+1
return n/s #分类器准确度
这里需要安装几个模块:scipy、numpy、sklearn
scipy及numpy模块需要访问http://www.lfd.uci.edu/~gohlke/pythonlibs,找到scipy、numpy,下载对应版本的whl
import sklearn
from nltk.classify.scikitlearn import SklearnClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
from sklearn.naive_bayes import MultinomialNB, BernoulliNB
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
print('BernoulliNB`s accuracy is %f' %score(BernoulliNB()))
print('MultinomiaNB`s accuracy is %f' %score(MultinomialNB()))
print('LogisticRegression`s accuracy is %f' %score(LogisticRegression()))
print('SVC`s accuracy is %f' %score(SVC()))
print('LinearSVC`s accuracy is %f' %score(LinearSVC()))
print('NuSVC`s accuracy is %f' %score(NuSVC()))
检测结果输出1(单个词:每个字为特征)
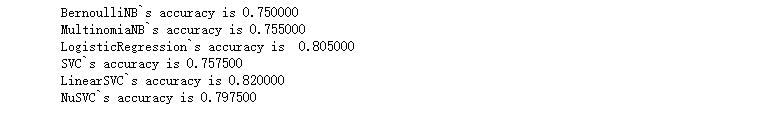
检测结果输出2(词[俩字]:2个字为特征,使用卡方统计选取前n个信息量大的作为特征)
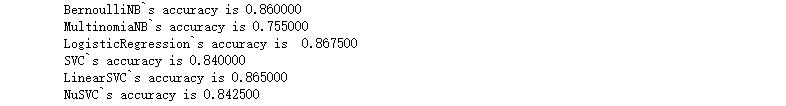
检测结果输出3(单个词和双词:把前面2种特征合并之后的特征)

检测结果输出4(结巴分词:用结巴分词外加卡方统计选取前n个信息量大的作为特征)
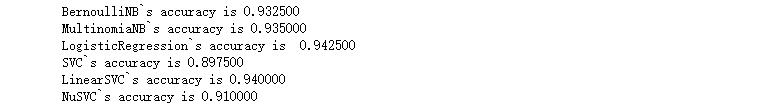
对比四种特征选取方式可以看出,单字 - 词 - 单字+词 - 结巴分词,效果是越来越好的。



















 6261
6261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











