









scrapy是一个python爬虫框架。我们自己用requests也能写爬虫(GET某个URL,然后Parse网页的内容),那么,问题来了,scrapy高明在哪些地方呢?下面就来讨论下这个话题,看看业界通用的爬虫是怎么设计的。
从[1]可得scrapy架构图。它由5个核心模块组成。
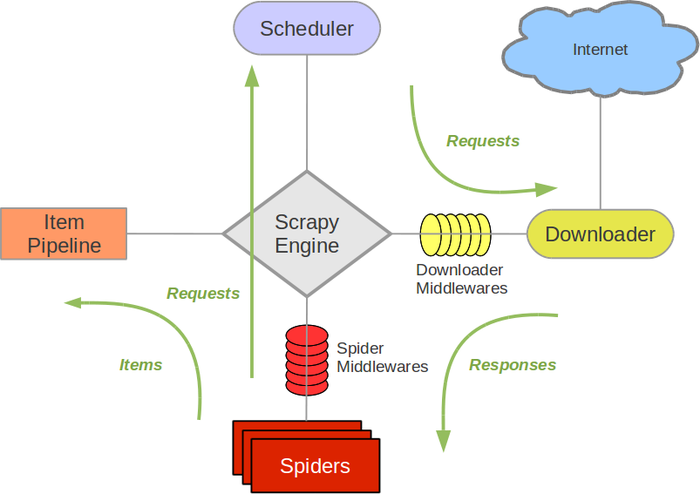
5个模块功能
- (1) 最重要的模块是Engine:它是数据流的指挥官,负责控制数据流(控制各个模块之间的通信);
- (2) scheduler:负责将Engine提交的URL排成一个队列;
- (3) spider:用户自己写的代码放在spider。主要负责HTTP response的解析,从回复的HTML中提取关键数据。
- (4) downloader:负责跟URL对应的server通信,并获取返回的内容。
- (5) item pipeline:负责处理spider提取出来的信息,一般用于做跟DB相关的操作。
2个中间件
中间件是处于两个模块之间的一种特殊hook,它的目的是提供一种简易的机制,通过插拔用户自己写的代码,来扩展新功能。
典型的数据流
- (1) Engine启动,从spider中读出要爬的第一个URL
- (2) Engine将读到的第一个URL送给scheduler
- (3) Engine向scheduler请求下一个要爬的URL
- (4) scheduler从队列中读出一个URL,送给Engine,Engine将这个URL送到downloader
- (5) downloader去GET这个URL,并将HTTP response生成一个Response对象。downloader将生成的Response返回给Engine
- (6) Engine将这个Response对象发给spider
- (7) spider处理这个Response对象,提取其中的信息,生成item。还会生成新的请求。并将item和请求送给Engine
- (8) Engine将收到的请求送给scheduler,将收到的item送给item pipline
- (9) 重复步骤(2),直到没有URL需要继续处理
架构评价
上面讲了scrapy的架构设计。那么,这样的设计好在哪呢?从功能上看:
* (1) 模块划分清晰,各模块之间无功能重叠,各模块合起来也能表示常用的爬虫功能
* (2) 功能可通过中间件进行扩展
* (3) scheduler可设置调度策略,并发爬多个URL
* (4) 各模块之间不能独立通信,必须由Engine控制,不会出现混乱
* (5) Pipeline模块只处理爬到的关键信息(item),不用处理不关注的大量HTML数据
* (6) 用户只需要关注HTTP response的解析,从回复的HTML中提取关键数据
关于怎么评价一个软件架构,理论派[3]列举了很多要考虑的点,比如质量、功能、性能、可测试、安全性。但从一个架构图,是看不出那么多的,理论派的做法在这里不够practice。来看看微软是怎么看一个架构好不好的[2]。
* (1) Separation of concerns: 各模块功能划分合理,不要有功能交叉。
* (2) Single Responsibility:功能高内聚
* (3) Principle of Least Knowledge:一个模块不需要知道另一个模块的内部细节
* (4) Don’t repeat yourself (DRY).
* (5) Minimize upfront design:每一个模块都是需要的,不要过分设计过多模块
归根结底,好的架构就是要做到模块设计恰到好处,各模块之间高内聚,低耦合。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









