







 本文是关于scikit-learn库中四种特征缩放方法的个人学习笔记,包括StandardScaler、MinMaxScaler、RobustScaler和MaxAbsScaler。StandardScaler通过居中和缩放数据实现单位方差;MinMaxScaler将数据缩放至0-1范围;RobustScaler利用四分位数进行缩放,适用于存在异常值的情况;MaxAbsScaler则保留数据的稀疏性,常用于稀疏矩阵的缩放。
本文是关于scikit-learn库中四种特征缩放方法的个人学习笔记,包括StandardScaler、MinMaxScaler、RobustScaler和MaxAbsScaler。StandardScaler通过居中和缩放数据实现单位方差;MinMaxScaler将数据缩放至0-1范围;RobustScaler利用四分位数进行缩放,适用于存在异常值的情况;MaxAbsScaler则保留数据的稀疏性,常用于稀疏矩阵的缩放。
【机器学习个人笔记】scikit-learn的四种特征缩放方式
在运用一些机器学习算法的时候不可避免地要对数据进行特征缩放(feature scaling),比如:在随机梯度下降(stochastic gradient descent)算法中,特征缩放有时能提高算法的收敛速度。
特征缩放还可以使机器学习算法工作的更好。比如在K近邻算法中,分类器主要是计算两点之间的欧几里得距离,如果一个特征比其它的特征有更大的范围值,那么距离将会被这个特征值所主导。因此每个特征应该被归一化,比如将取值范围处理为0到1之间。
先来看看原始数据集
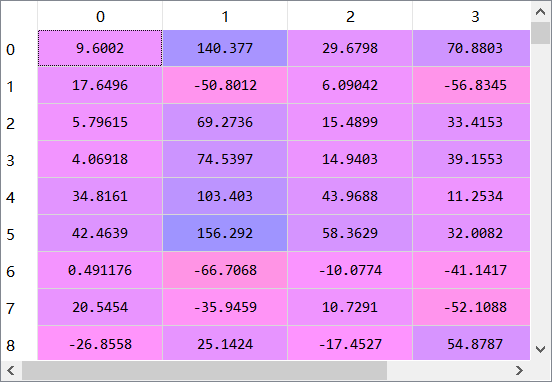
接下来我将介绍我在学习过程中遇到的三种特征缩放的方法:
1.preprocessing.StandardScaler(X)
copy : boolean, optional, 默认为True
如果为False,请尝试避免复制并改为进行缩放。 这并不能保证始终在原地工作; 例如 如果数据不是NumPy数组或scipy.sparse CSR矩阵,则仍可能返回副本。
with_mean : boolean, 默认为True
如果为True,则在缩放之前将数据居中。 当在稀疏矩阵上尝试时,这不起作用(并且会引发异常),因为它们的居中需要构建一个密集矩阵,在常见的情况下,该矩阵可能太大而不适合存储器。
with_std : boolean, 默认为True
如果为True,则将数据缩放为单位方差(或等效地,单位标准差)。
from sklearn.preprocessing import StandardScaler
sc  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









