






索引:
**MySql底层的数据结构主要是基于Hash 和 B+Tree**
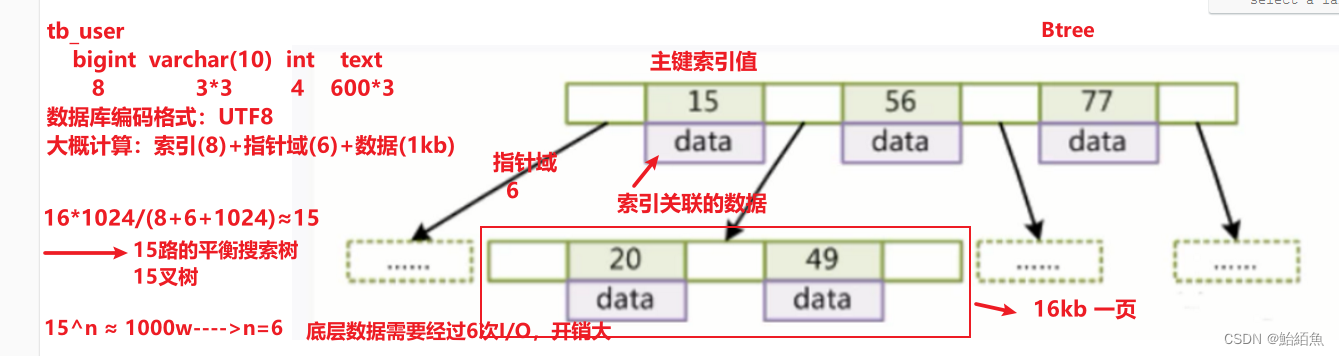
如果一个B+tree的树高时3的话,那么非叶子节点2层,叶子节点1层;
非叶子节点:16*1024/(8+6)=1170
非叶子节点两层:1170个元素,如果是两层,那么元素数量:1170*1170=1,368,900
叶子节点:因为包含索引+指针+数据 -----16*1.24/(8+6+1025)=15
总共:1,368,900*15=20,533,500
B+Tree索引:
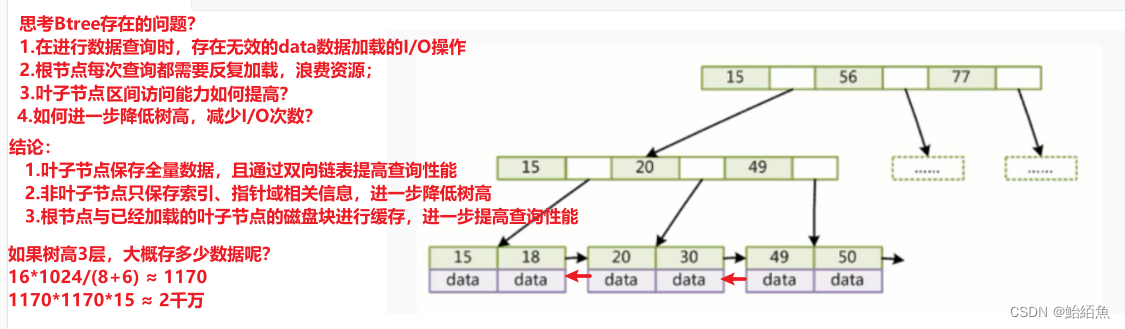
B+Tree的度非常高,因此h非常小 (一般为3到5之间),性能就会非常稳定
B+Tree叶子节点有顺序指针,更容易做范围查询
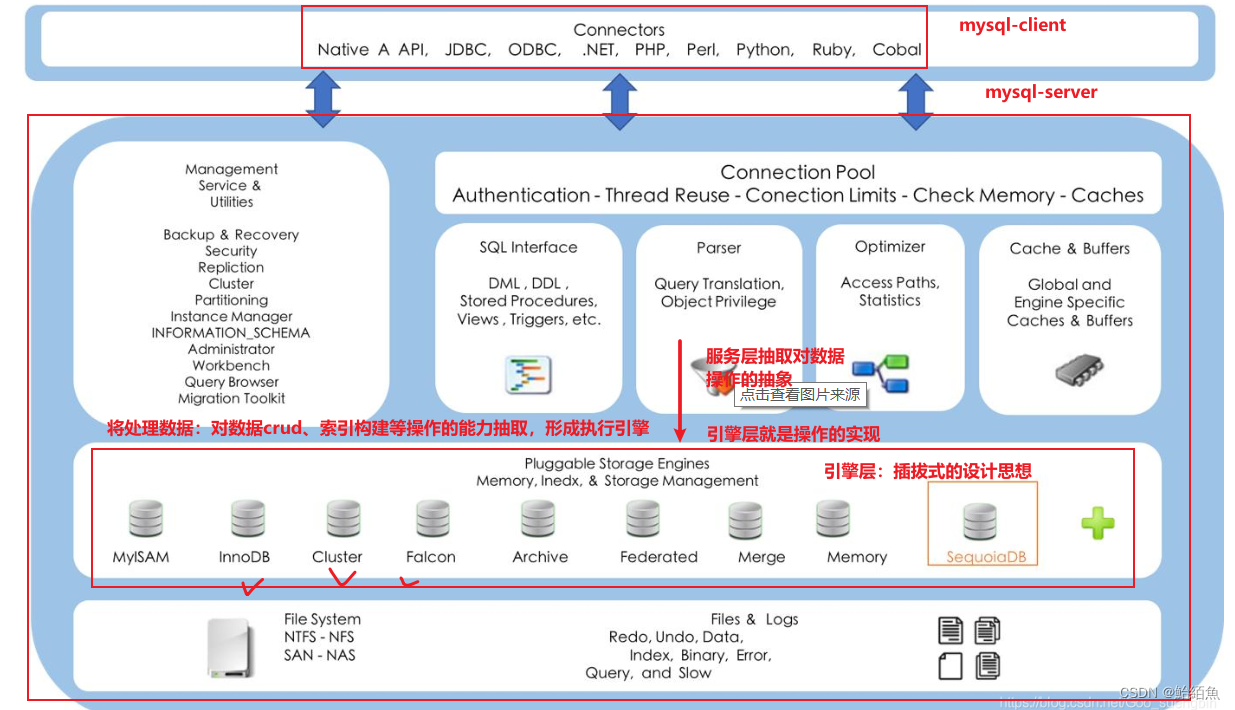
存储引擎:
如果你在研究大量的临时数据,你也许需要使用内存存储引擎。内存存储引擎能够在内存中存储所有的表格数据。
也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力) 选择支持事务的存储引擎
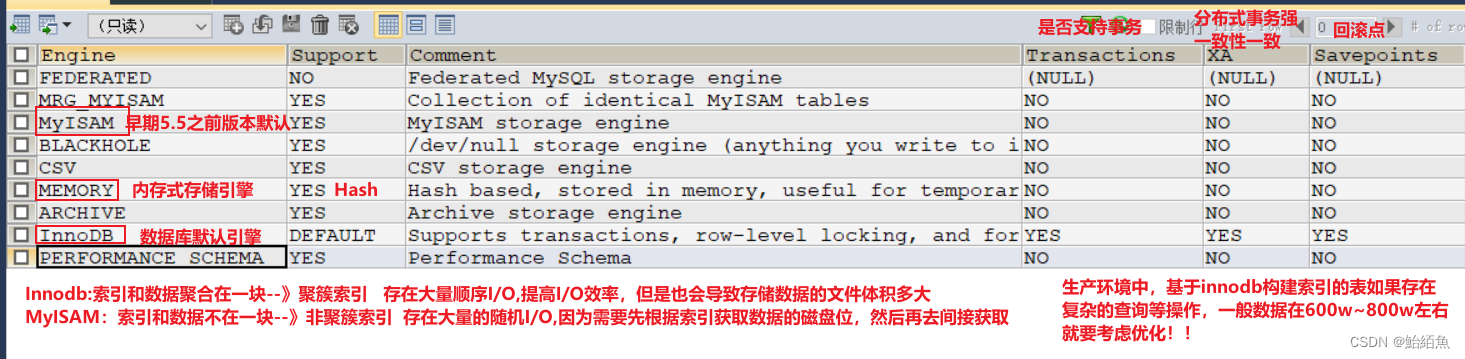
默认的引擎是innodb 可通过 SET default_storage_engine=< 存储引擎名 >更改
MyISAM 和 innoDB引擎 这两种引擎都是采用B+Tree和hash 数据结构实现的索引
MyISAM:不支持事务,不支持外键,支持表锁,支持缓冲索引,非聚簇索引
innoDB:支持事务,支持外键,支持行锁和表锁,支持缓冲索引和数据,聚簇索引
总的来说:
需要事务: 那肯定用innoDB
不需要事务:
myisam的查询效率高,内存要求低, 但因为采用表锁, 不适合并发写操作, 读多写少选它
innoDB采用行锁,适合处理并发写操作, 写多读少选它
索引特点:非聚簇索引
采用B+Tree 作为数据结构
MyISAM 索引文件和数据文件是分离的(非聚簇)
叶子节点存储的是数据的磁盘地址
非主键索引和主键索引类似
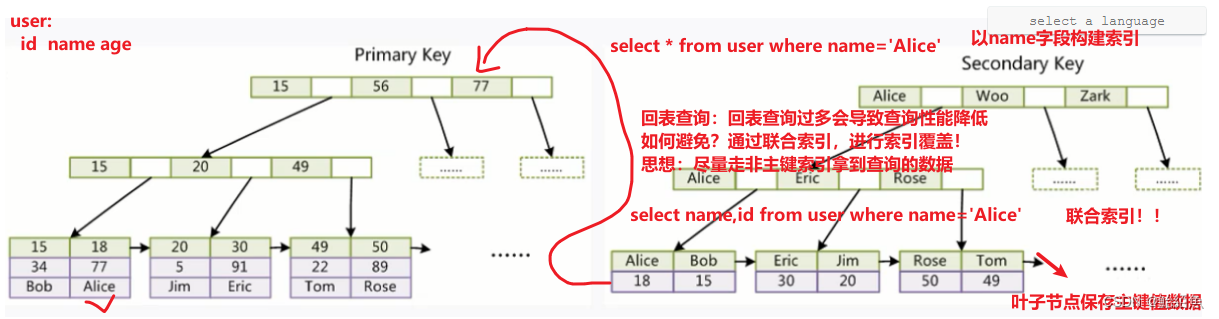
索引的分类:mysql中表必须维护一个B+tree索引树,如果在表中没有指定主键列,数据库会通过一个隐藏列作为索引字段构建B+tree
1.主键索引:unique:加速查找+约束 (唯一)
2.普通索引index:加速查找
3.唯一索引:unique:加速查找+约束 (唯一)
4.联合索引:最左匹配原则
5.全文索引fulltext:用于搜索很长一篇文章的时候,效果最好
创建索引
create [UNIQUE|primary|fulltext] index 索引名称 ON 表名(字段(长度))
查看索引
show index from 表名
删除索引
drop index[索引名称] on 表名
**更改索引**
-- 添加一个主键,索引必须是唯一索引,不能为NULL
alter table tab_name add unque index_name(column_list)
-- 创建的索引是唯一索引,可以为NULL
alter table tab_name add index index_name(column_list)
索引优势:
1.可以通过建立唯一索引或者主键索引,保证数据库表中每一行数据的唯一性.
2.建立索引可以大大提高检索的数据,以及减少表的检索行数
3.在表连接的连接条件 可以加速表与表直接的相连
employee dep_id deparment
4.在分组和排序字句进行数据检索,可以减少查询时间中 分组 和 排序时所消耗的时间(数据库的记录会重新排序)
5.建立索引,在查询中使用索引 可以提高性能
索引劣势:
1.索引文件会占用物理空间,除了数据表需要占用物理空间之外,每一个索引还会占用一定的物理空间
2.在创建索引和维护索引 会耗费时间,随着数据量的增加而增加
3.当对表的数据进行INSERT,UPDATE,DELETE 的时候,索引也要动态的维护,这样就会降低数据的维护速度
**不适合建立索引**
1.记录比较少
2.where on 条件里用不到的字段不建立索引
3.经常增删改的表
4.数据重复的表字段-辨识度低
5. 字段特别大不适合(text blob varcher)
索引失效:
1.查询条件没有用索引;
2.1 对索引字段进行数学运算
2.2 对索引字段进行函数处理
2.3 对索引字段类型转换
3.左侧模糊匹配查询 like '%三'
4.数据频繁的增删:频繁的增删数据,导致叶子节点分裂与合并,重新构建的过程,索引会失效
5.or关键字可能导致索引失效
6.联合索引不遵循最左匹配原则
7.查询的列为空;--》为空的列不参与索引的构建!
















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









