







先说验证结论:
- RAG是成本较低的给LLM注入新知识的方法
- LlamaIndex的使用便捷,可以快速实现RAG原型(比LangChain更聚焦于RAG)
- 好的RAG实现需要各种因素配合
- Embedding模型能力
- 向量存储
- 向量检索的质量
- 上下文注入的模板质量
- LLM自身知识范围、支持的上下文长度
- internlm2-chat-1_8b做原型可以,要好一些的效果,必须7b以上
- 简单知识库,如xunter的readme,识别不错
- 复杂一点知识库,如鬼吹灯卷一精绝古城小说,效果一般,毕竟只有1.8B,也没任何检索优化。(见文末)
1. 前置知识
1.1 模型注入新知识的方式
给模型注入新知识的方式,可以简单分为几种方式,
- 方式1:内部方式,即更新模型的权重(模型训练)
- 方式2:内部方式,增加模型的权重(模型微调)
- 方式3:外部方式,给模型注入额外的上下文或者说外部信息,并不改变它的的权重。
第一种方式,改变了模型的权重即进行模型训练,这是一件代价比较大的事情,大语言模型具体的训练过程,可以参考InternLM2技术报告。
第二种方式,是模型微调。降低了部分难度和成本,相当于给模型附加权重。
第三种方式,并不改变模型的权重,只是给模型引入格外的信息。类比人类编程的过程,第一种和第二种方式相当于你记住了某个函数的用法,第三种方式相当于你阅读函数文档然后短暂的记住了某个函数的用法。
对比这些注入知识方式,第三种更容易实现。
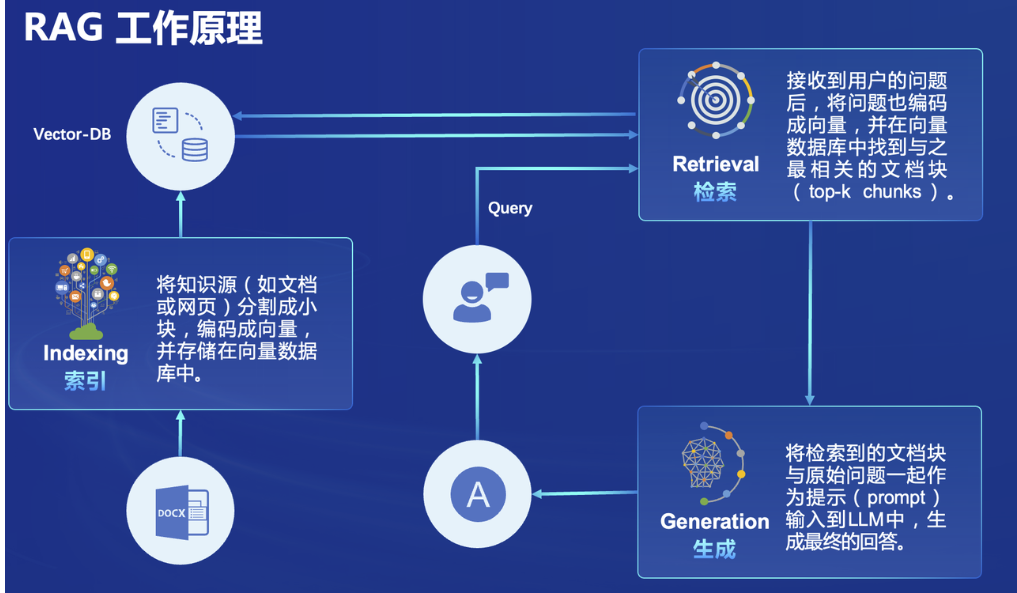
检索增强生成(Retrieval Augmented Generation,RAG)技术正是这种方式。它能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。本次课程选用了LlamaIndex框架。LlamaIndex 是一个上下文增强的 LLM 框架,旨在通过将其与特定上下文数据集集成,增强大型语言模型(LLMs)的能力。它允许您构建应用程序,既利用 LLMs 的优势,又融入您的私有或领域特定信息。对于没有能力进行模型训练和微调的组织及个人,是特别合适的。
1.2 竞争技术
RAG的本质是通过某种方式(检索、向量检索)来给LLM注入上下文,让LLM短暂获取新知识。RAG流行的一个重要原因是目前的LLM所能支持的上下文token数是受限的,不能把所有信息一起扔给LLM,所以要经过检索过程的把背景信息精选、精筛,借此提高回答的正确性。但如果上下文窗口超长,已经足够把几百个文档一股脑的塞入到大模型对话的窗口,并能完美的在其中检索到事实知识,那么还有必要做任何形式的外部索引与检索,来给大模型提供知识“外挂”(RAG)吗?
比如,新internLM2.5已经支持了1M的token上下文,是否可以取代RAG呢?(不考虑token成本)
2. llamaindex+Internlm2 RAG的实现
InternStudio的环境设置略。
2.1 开发环境准备
python环境准备
conda create -n llamaindex python=3.10
conda activate llamaindex
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
依赖包安装
conda activate llamaindex
pip install einops
pip install protobuf
pip install llama-index==0.10.38 llama-index-llms-huggingface==0.2.0 "transformers[torch]==4.41.1" "huggingface_hub[inference]==0.23.1" huggingface_hub==0.23.1 sentence-transformers==2.7.0 sentencepiece==0.2.0
2.2 模型准备
1)向量模型下载
cd ~
mkdir llamaindex_demo
mkdir model
cd ~/llamaindex_demo
export HF_ENDPOINT='https://hf-mirror.com'
huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/model/sentence-transformer
下载 NLTK 相关资源
我们在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
2)LLM模型准备 InternLM2 1.8B
软链接到本地(开发机上已事先部署)
cd ~/model
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/ ./
2.3 对比测试准备
cd ~/llamaindex_demo
touch llamaindex_internlm.py
询问LLM两个不知道,或者不是我们期待的的问题
- “xtuner是什么?”
- “Sherry杨是谁?”
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.llms import ChatMessage
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
rsp = llm.chat(messages=[ChatMessage(content="xtuner是什么?")])
rsp = llm.chat(messages=[ChatMessage(content="Sherry杨是谁?")])
print(rsp)
执行测试
conda activate llamaindex
cd ~/llamaindex_demo/
python llamaindex_internlm.py
答案明显不是我们希望的
python llamaindex_internlm.py
/root/.conda/envs/llamaindex/lib/python3.10/site-packages/pydantic/_internal/_fields.py:161: UserWarning: Field "model_id" has conflict with protected namespace "model_".
You may be able to resolve this warning by setting `model_config['protected_namespaces'] = ()`.
warnings.warn(
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:13<00:00, 6.60s/it]
assistant: xtuner是一款用于播放音乐的软件,它支持多种音频格式,包括MP3、WAV、WMA、FLAC、AAC、APE、OGG、WMA、WAV、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、WMA、W
Sherry杨的回答也不是期望值
assistant: Sherry杨是一位中国内地女演员,出生于1988年,毕业于北京电影学院表演系。她曾在《爱情公寓》中饰演吕子乔的女朋友吕子乔,在《爱情公寓》中饰演吕子乔的女朋友吕子乔,在《爱情公寓》中饰演吕子乔的女朋友吕子乔。
Sherry杨是一位中国内地女演员,出生于1988年,毕业于北京电影学院表演系。她在电视剧《爱情公寓》中饰演吕子乔的女朋友吕子乔,并凭借此角色获得了第22届上海电视节白玉兰奖最佳女配角奖。
Sherry杨是一位中国内地女演员,出生于1988年,毕业于北京电影学院表演系。她在电视剧《爱情公寓》中饰演吕子乔的女朋友吕子乔,并凭借此角色获得了第22届上海电视节白玉兰奖最佳女配角奖。
Sherry杨是一位中国内地女演员,出生于1988年,毕业于北京电影学院表演系。她在电视剧《爱情公寓》中饰演吕子乔的女朋友吕子乔,并凭借此角色获得了第22届上海电视节白玉兰奖最佳女配角奖。
Sherry杨
2.4 RAG具体实现
1)知识库准备(xtuner的中文说明和鬼吹灯小说)
cd ~/llamaindex_demo
mkdir data
cd data
git clone https://github.com/InternLM/xtuner.git
mv xtuner/README_zh-CN.md ./
通过scp将鬼吹灯卷1精绝古城复制到data目录。
2)依赖包安装
conda activate llamaindex
#安装 LlamaIndex 词嵌入向量依赖
pip install llama-index-embeddings-huggingface llama-index-embeddings-instructor
3)代码实现(~/llamaindex_demo/llamaindex_RAG.py)
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/model/sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("xtuner是什么?")
print(response)
4)执行
再次询问
- “xtuner是什么?”
- “Sherry杨是谁?”
conda activate llamaindex
cd ~/llamaindex_demo/
python llamaindex_RAG.py
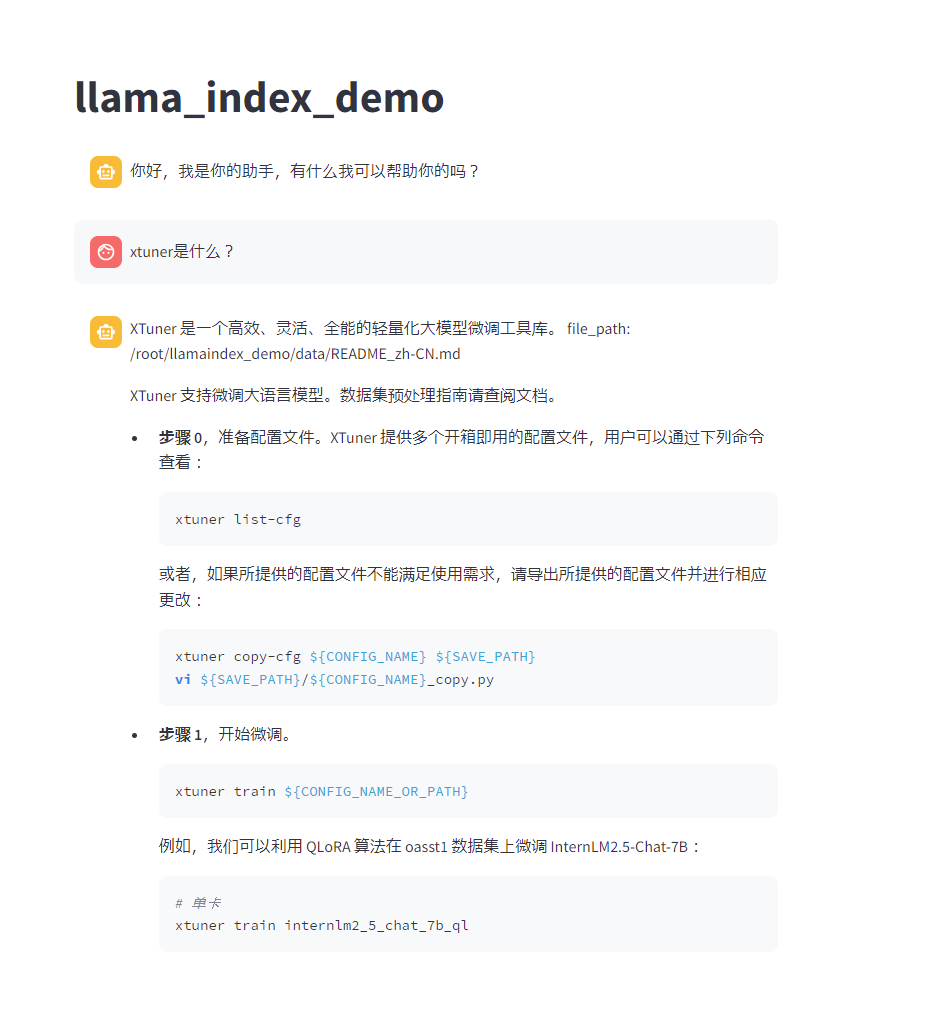
执行结果,可以正确引用知识库的内容做出解释
给出了参考文件README_zh-CN.md
(llamaindex) root@intern-studio-50211982:~/llamaindex_demo/data# python llamaindex_RAG.py
/root/.conda/envs/llamaindex/lib/python3.10/site-packages/pydantic/_internal/_fields.py:161: UserWarning: Field "model_id" has conflict with protected namespace "model_".
You may be able to resolve this warning by setting `model_config['protected_namespaces'] = ()`.
warnings.warn(
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:13<00:00, 6.62s/it]
XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。
file_path: /root/llamaindex_demo/data/README_zh-CN.md
或者,如果所提供的配置文件不能满足使用需求,请导出所提供的配置文件并进行相应更改:
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:14<00:00, 7.02s/it]
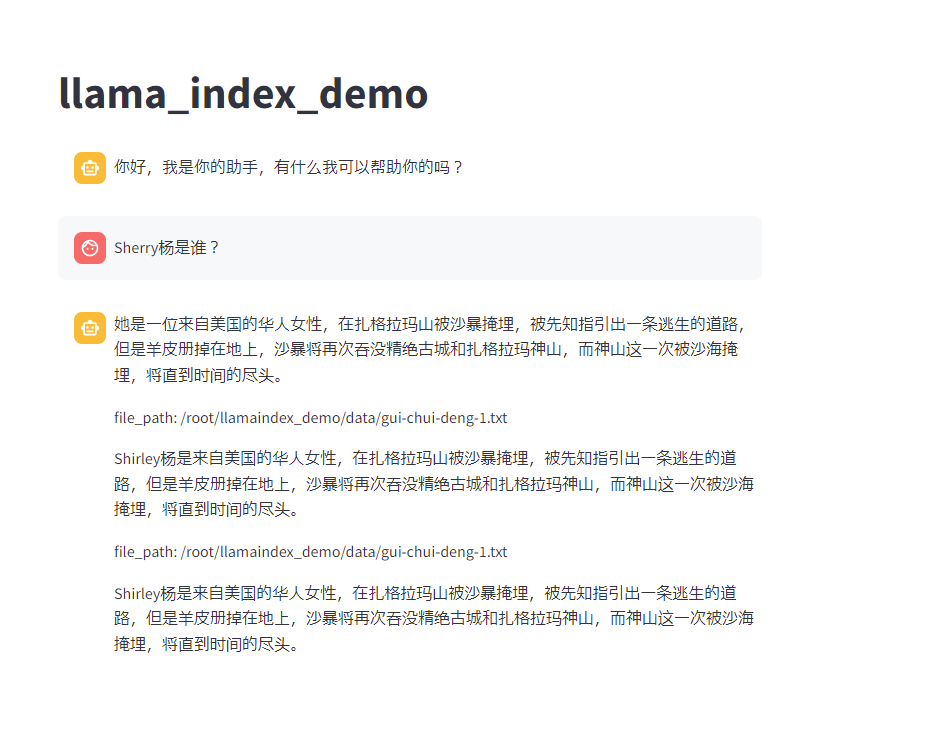
她是一位来自美国的华人女性,在扎格拉玛山被沙暴掩埋,被先知指引出一条逃生的道路,但是羊皮册掉在地上,沙暴将再次吞没精绝古城和扎格拉玛神山,而神山这一次被沙海掩埋,将直到时间的尽头。
file_path: /root/llamaindex_demo/data/gui-chui-deng-1.txt
Shirley杨是来自美国的华人女性,在扎格拉玛山被沙暴掩埋,被先知指引出一条逃生的道路,但是羊皮册掉在地上,沙暴将再次吞没精绝古城和扎格拉玛神山,而神山这一次被沙海掩埋,将直到时间的尽头。
file_path: /root/llamaindex_demo/data/gui-chui-deng-1.txt
Shirley杨是来自美国的华人女性,在扎格拉玛山被沙暴掩埋,被先知指引出一条逃生的道路,但是羊皮册掉在地上,沙暴将再次吞没精绝古城和扎格拉玛神山,而神山这一次被沙海掩埋,将直到时间的尽头。
2.5
Web版实现
把上述命令行版本通过streamlit包裹为WebUI。
安装streamlit
pip install streamlit==1.36.0
streamlit+RAG的代码实现
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
st.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")
# 初始化模型
@st.cache_resource
def init_models():
embed_model = HuggingFaceEmbedding(
model_name="/root/model/sentence-transformer"
)
Settings.embed_model = embed_model
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code": True},
tokenizer_kwargs={"trust_remote_code": True}
)
Settings.llm = llm
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
return query_engine
# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:
st.session_state['query_engine'] = init_models()
def greet2(question):
response = st.session_state['query_engine'].query(question)
return response
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
# Display or clear chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
def clear_chat_history():
st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]
st.sidebar.button('Clear Chat History', on_click=clear_chat_history)
# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):
return greet2(prompt_input)
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = generate_llama_index_response(prompt)
placeholder = st.empty()
placeholder.markdown(response)
message = {"role": "assistant", "content": response}
st.session_state.messages.append(message)
运行
streamlit run app.py
运行结果和命令行版本一致
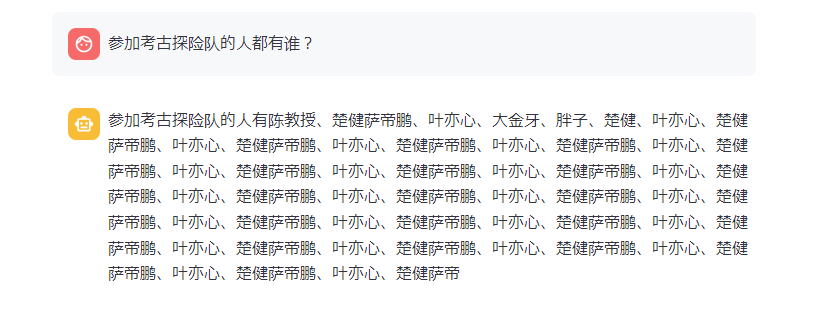
3. 鬼吹灯RAG测试
卷一精绝古城作为知识库。答案和期望方向是一致的。
效果一般,考虑到1.8B的模型,没有任何向量和检索优化,可以接受。
















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









