







先写实践体会:
- 基础岛课程中最难一课,不再是应用层面,而是深入模型内部。
- 微调流程:
- 目标模型准备
- 微调数据准备
- 微调配置文件
- 微调实施
- 格式转换
- 模型合并
- 测试
- 微调时间,在10%的A100GPU下,3000条指令数据下,本文所用的纯微调时间大约为:
- 微调:40min、转换:15m、合并:5m,合计1H左右
- 微调结果准确!和预设数据完全相同,而且能结合LLM自身能力去分解。详见文末测试。
- XTuner支持4090消费级GPU的微调
- XTuner的参数很多,微调的设定很多、掌握需要更深入的学习和理解LLM模型知识
- 指令微调相对简单
- 合理的微调数据是关键之一
一、XTuner介绍
https://xtuner.readthedocs.io/zh-cn/latest/index.html
XTuner是低成本大模型训练工具箱,也是internLM全链条工具链中,微调工具的一环。XTuner支持与书生·浦语(InternLM)、Llama等多款开源大模型的适配,可执行增量预训练、指令微调、工具类指令微调等任务类型。硬件要求上,开发者最低使用消费级显卡便可进行训练,实现大模型特定需求能力。
二、模型微调流程
- 模型准备
- 微调数据准备
- 配置文件准备
- 微调实施
- 模型格式转换
- 模型合并
- 微调结果测试
三、模型微调的种类
- 指令微调
- 传统微调
- 对齐微调
在传统微调中,语言模型预测样本的标签,而在指令微调中,语言模型回答指令集中的问题。两者之间的差别:
- 目标
- 传统微调:在特定任务或数据集上进一步优化预训练模型的性能。
- 指令微调:使模型能够更好地理解和执行自然语言指令。
- 数据集
- 传统微调:通常使用单一任务的专用数据集,例如情感分析、命名实体识别等。数据量可能较小,但高度特定于目标任务。
- 指令微调:使用包含各种任务和指令的大规模多任务数据集。这些数据集涵盖了多个领域和任务类型。数据量通常非常大,涵盖广泛的指令和任务示例。
- 应用场景
- 传统微调:适用于需要在特定任务上获得最佳性能的应用,例如医学影像分析、语音识别等。
- 指令微调:适用于需要处理多种任务和指令的自然语言处理应用,例如智能助理、聊天机器人等
指令微调侧重于让模型学会遵循特定指令,生成符合要求的输出,适用于需要模型执行特定任务的场景。
此外,还有对齐微调
对齐微调侧重于使模型的行为与人类价值观和期望一致,适用于需要生成内容符合特定价值观或标准的场景。
本次是进行指令微调:
指令跟随微调(Instruction Following Fine-Tuning)是指在大型语言模型(LLM)的训练过程中,通过提供明确的指令或任务描述,对模型进行有针对性的微调,使其能够更好地理解和执行特定任务。这种方式旨在让模型学习如何根据给定的指令生成符合要求的输出。
四、微调实践
(一)xtuner安装
# 创建虚拟环境
conda create -n xtuner0121 python=3.10 -y
# 激活虚拟环境(注意:后续的所有操作都需要在这个虚拟环境中进行)
conda activate xtuner0121
# 安装一些必要的库
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
# 安装其他依赖
pip install transformers==4.39.3
pip install streamlit==1.36.0
# 创建一个目录,用来存放源代码
mkdir -p /root/InternLM/code
cd /root/InternLM/code
git clone -b v0.1.21 https://github.com/InternLM/XTuner /root/InternLM/code/XTuner
# 进入到源码目录
cd /root/InternLM/code/XTuner
# 执行安装
pip install -e '.[deepspeed]'
安装确认
xtuner version
08/08 17:28:22 - mmengine - INFO - 0.1.21
帮助查看
xtuner help
08/08 17:29:02 - mmengine - INFO -
Arguments received: ['xtuner', 'help']. xtuner commands use the following syntax:
xtuner MODE MODE_ARGS ARGS
Where MODE (required) is one of ('list-cfg', 'copy-cfg', 'log-dataset', 'check-custom-dataset', 'train', 'test', 'chat', 'convert', 'preprocess', 'mmbench', 'eval_refcoco')
MODE_ARG (optional) is the argument for specific mode
ARGS (optional) are the arguments for specific command
Some usages for xtuner commands: (See more by using -h for specific command!)
1. List all predefined configs:
xtuner list-cfg
2. Copy a predefined config to a given path:
xtuner copy-cfg $CONFIG $SAVE_FILE
3-1. Fine-tune LLMs by a single GPU:
xtuner train $CONFIG
3-2. Fine-tune LLMs by multiple GPUs:
NPROC_PER_NODE=$NGPUS NNODES=$NNODES NODE_RANK=$NODE_RANK PORT=$PORT ADDR=$ADDR xtuner dist_train $CONFIG $GPUS
4-1. Convert the pth model to HuggingFace's model:
xtuner convert pth_to_hf $CONFIG $PATH_TO_PTH_MODEL $SAVE_PATH_TO_HF_MODEL
4-2. Merge the HuggingFace's adapter to the pretrained base model:
xtuner convert merge $LLM $ADAPTER $SAVE_PATH
xtuner convert merge $CLIP $ADAPTER $SAVE_PATH --is-clip
4-3. Split HuggingFace's LLM to the smallest sharded one:
xtuner convert split $LLM $SAVE_PATH
5-1. Chat with LLMs with HuggingFace's model and adapter:
xtuner chat $LLM --adapter $ADAPTER --prompt-template $PROMPT_TEMPLATE --system-template $SYSTEM_TEMPLATE
5-2. Chat with VLMs with HuggingFace's model and LLaVA:
xtuner chat $LLM --llava $LLAVA --visual-encoder $VISUAL_ENCODER --image $IMAGE --prompt-template $PROMPT_TEMPLATE --system-template $SYSTEM_TEMPLATE
6-1. Preprocess arxiv dataset:
xtuner preprocess arxiv $SRC_FILE $DST_FILE --start-date $START_DATE --categories $CATEGORIES
6-2. Preprocess refcoco dataset:
xtuner preprocess refcoco --ann-path $RefCOCO_ANN_PATH --image-path $COCO_IMAGE_PATH --save-path $SAVE_PATH
7-1. Log processed dataset:
xtuner log-dataset $CONFIG
7-2. Verify the correctness of the config file for the custom dataset:
xtuner check-custom-dataset $CONFIG
8. MMBench evaluation:
xtuner mmbench $LLM --llava $LLAVA --visual-encoder $VISUAL_ENCODER --prompt-template $PROMPT_TEMPLATE --data-path $MMBENCH_DATA_PATH
9. Refcoco evaluation:
xtuner eval_refcoco $LLM --llava $LLAVA --visual-encoder $VISUAL_ENCODER --prompt-template $PROMPT_TEMPLATE --data-path $REFCOCO_DATA_PATH
10. List all dataset formats which are supported in XTuner
Run special commands:
xtuner help
xtuner version
(二)模型准备
以验证为主,以Shanghai_AI_Laboratory/internlm2-chat-1_8b的小模型为目标进行指令跟随微调。
模型目录构造
└── Shanghai_AI_Laboratory
└── internlm2-chat-1_8b -> /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b
├── README.md
├── config.json
├── configuration.json
├── configuration_internlm2.py
├── generation_config.json
├── model-00001-of-00002.safetensors
├── model-00002-of-00002.safetensors
├── model.safetensors.index.json
├── modeling_internlm2.py
├── special_tokens_map.json
├── tokenization_internlm2.py
├── tokenization_internlm2_fast.py
├── tokenizer.model
└── tokenizer_config.json
(三)微调数据准备
准备了三条指令数据:
Q: "请介绍一下你自己"
A: "我是ydogg的小助手,内在是上海AI实验室书生· 浦语的1.8B大模型哦"
Q: "你在实战营做什么",
A: "我在这里学习internLM,并且帮助ydogg完成XTuner微调个人小助手的任务"
Q: "你喜欢什么小说",
A: "我喜欢看天下霸唱写的鬼吹灯"
XTuner所需要指令微调的数据格式,json文件,用上面数据内容如下:
input和Output,一问一答的形式。
注意,为了强化效果,会重复很多次。当然注意重复次数太多,也会造成过拟合。
[
{
"conversation": [
{
"input": "请介绍一下你自己",
"output": "我是ydogg的小助手,内在是上海AI实验室书生· 浦语的1.8B大模型哦"
}
]
},
{
"conversation": [
{
"input": "你在实战营做什么",
"output": "我在这里学习internLM,并且帮助ydogg完成XTuner微调个人小助手的任务"
}
]
},
{
"conversation": [
{
"input": "你喜欢什么小说",
"output": "我喜欢看天下霸唱写的鬼吹灯"
}
]
},
...(重复上述3000次)
]
以上数据由以下脚本生成,可根据需求自由修改
import json
# 设置用户的名字
name = 'ydogg'
# 设置需要重复添加的数据次数
n = 3000
# 初始化数据
data = [
{"conversation": [{"input": "请介绍一下你自己", "output": "我是{}的小助手,内在是上海AI实验室书生· 浦语的1.8B大模型哦".format(name)}]},
{"conversation": [{"input": "你在实战营做什么", "output": "我在这里学习internLM,并且帮助{}完成XTuner微调个人小助手的任务".format(name)}]},
{"conversation": [{"input": "你喜欢什么小说", "output": "我喜欢看天下霸唱写的鬼吹灯"}]}
]
# 通过循环,将初始化的对话数据重复添加到data列表中
for i in range(n):
data.append(data[0])
data.append(data[1])
data.append(data[2])
# 将data列表中的数据写入到'datas/assistant.json'文件中
with open('datas/assistant.json', 'w', encoding='utf-8') as f:
# 使用json.dump方法将数据以JSON格式写入文件
# ensure_ascii=False 确保中文字符正常显示
# indent=4 使得文件内容格式化,便于阅读
json.dump(data, f, ensure_ascii=False, indent=4)
(四)配置文件准备
1. xtuner支持的配置文件一览
xtuner list-cfg -p internlm2
==========================CONFIGS===========================
PATTERN: internlm2
-------------------------------
internlm2_1_8b_full_alpaca_e3
internlm2_1_8b_full_custom_pretrain_e1
internlm2_1_8b_qlora_alpaca_e3
internlm2_20b_full_custom_pretrain_e1
internlm2_20b_full_finetune_custom_dataset_e1
internlm2_20b_qlora_alpaca_e3
internlm2_7b_full_custom_pretrain_e1
internlm2_7b_full_finetune_custom_dataset_e1
internlm2_7b_full_finetune_custom_dataset_e1_sequence_parallel_4
internlm2_7b_qlora_alpaca_e3
internlm2_7b_qlora_arxiv_gentitle_e3
...
internlm2_7b_qlora_oasst1_e3
internlm2_7b_qlora_sql_e3
internlm2_7b_w_internevo_dataset
internlm2_7b_w_tokenized_dataset
internlm2_7b_w_untokenized_dataset
internlm2_chat_1_8b_dpo_full
internlm2_chat_1_8b_dpo_full_varlenattn
internlm2_chat_1_8b_dpo_full_varlenattn_jsonl_dataset
internlm2_chat_1_8b_full_alpaca_e3
internlm2_chat_1_8b_orpo_full
internlm2_chat_1_8b_orpo_full_varlenattn
internlm2_chat_1_8b_orpo_full_varlenattn_jsonl_dataset
internlm2_chat_1_8b_qlora_alpaca_e3
internlm2_chat_1_8b_qlora_custom_sft_e1
internlm2_chat_1_8b_reward_full_ultrafeedback
internlm2_chat_1_8b_reward_full_varlenattn_jsonl_dataset
internlm2_chat_1_8b_reward_full_varlenattn_ultrafeedback
internlm2_chat_1_8b_reward_qlora_varlenattn_ultrafeedback
internlm2_chat_20b_full_finetune_custom_dataset_e1
...
2. 配置文件名的解释
以 internlm2_1_8b_full_custom_pretrain_e1 和 internlm2_chat_1_8b_qlora_alpaca_e3 举例:
| 配置文件 internlm2_1_8b_full_custom_pretrain_e1 | 配置文件 internlm2_chat_1_8b_qlora_alpaca_e3 | 说明 |
|---|---|---|
| internlm2_1_8b | internlm2_chat_1_8b | 模型名称 |
| full | qlora | 使用的算法 |
| custom_pretrain | alpaca | 数据集名称 |
| e1 | e3 | 把数据集跑几次 |
- LoRA 通过引入低秩分解技术,减少微调过程中的参数数量,适用于资源受限环境下的模型微调。
- QLoRA 在 LoRA 的基础上,进一步结合量化技术,大幅减少模型的存储和计算开销,适用于低资源场景。
3. 根据模型复制配置文件
# 使用internlm2_chat_1_8b_qlora_alpaca_e3
xtuner copy-cfg internlm2_chat_1_8b_qlora_alpaca_e3 ./
4. 配置文件说明
整体的配置文件分为五部分:
- PART 1 Settings:涵盖了模型基本设置,如预训练模型的选择、数据集信息和训练过程中的一些基本参数(如批大小、学习率等)。
- PART 2 Model & Tokenizer:指定了用于训练的模型和分词器的具体类型及其配置,包括预训练模型的路径和是否启用特定功能(如可变长度注意力),这是模型训练的核心组成部分。
- PART 3 Dataset & Dataloader:描述了数据处理的细节,包括如何加载数据集、预处理步骤、批处理大小等,确保了模型能够接收到正确格式和质量的数据。
- PART 4 Scheduler & Optimizer:配置了优化过程中的关键参数,如学习率调度策略和优化器的选择,这些是影响模型训练效果和速度的重要因素。
- PART 5 Runtime:定义了训练过程中的额外设置,如日志记录、模型保存策略和自定义钩子等,以支持训练流程的监控、调试和结果的保存。
一般来说我们需要更改的部分其实只包括前三部分,而且修改的主要原因是我们修改了配置文件中规定的模型、数据集。
5. 可配置参数说明
常用参数介绍
| 参数名 | 解释 |
|---|---|
| data_path | 数据路径或 HuggingFace 仓库名 |
| max_length | 单条数据最大 Token 数,超过则截断 |
| pack_to_max_length | 是否将多条短数据拼接到 max_length,提高 GPU 利用率 |
| accumulative_counts | 梯度累积,每多少次 backward 更新一次参数 |
| sequence_parallel_size | 并行序列处理的大小,用于模型训练时的序列并行 |
| batch_size | 每个设备上的批量大小 |
| dataloader_num_workers | 数据加载器中工作进程的数量 |
| max_epochs | 训练的最大轮数 |
| optim_type | 优化器类型,例如 AdamW |
| lr | 学习率 |
| betas | 优化器中的 beta 参数,控制动量和平方梯度的移动平均 |
| weight_decay | 权重衰减系数,用于正则化和避免过拟合 |
| max_norm | 梯度裁剪的最大范数,用于防止梯度爆炸 |
| warmup_ratio | 预热的比例,学习率在这个比例的训练过程中线性增加到初始学习率 |
| save_steps | 保存模型的步数间隔 |
| save_total_limit | 保存的模型总数限制,超过限制时删除旧的模型文件 |
| prompt_template | 模板提示,用于定义生成文本的格式或结构 |
| … | … |
6. 设置文件的修改
设置文件实际是一个预置生成Python文件,目的是将微调所需要的主要参数做了初始化设定。
参数太多,看的不是很明白,还需要好好研究一下。黄色底色的代码是修改后的部分。
######################################################################
# PART 1 Settings #
#######################################################################
# Model
# pretrained_model_name_or_path = 'internlm/internlm2-chat-1_8b'
pretrained_model_name_or_path = '/root/InternLM/XTuner/Shanghai_AI_Laboratory/internlm2-chat-1_8b'
use_varlen_attn = False
# Data
#alpaca_en_path = 'tatsu-lab/alpaca'
alpaca_en_path = 'datas/assistant.json'
...
# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = SYSTEM_TEMPLATE.alpaca
evaluation_inputs = [
#'请给我介绍五个上海的景点', 'Please tell me five scenic spots in Shanghai'
'请介绍一下你自己', 'Please introduce yourself',
'你喜欢的小说是什么', 'What is your favorite novel'
]
#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
...
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
type=process_hf_dataset,
# dataset=dict(type=load_dataset, path=alpaca_en_path),
dataset=dict(type=load_dataset, path='json', data_files=dict(train=alpaca_en_path)),
tokenizer=tokenizer,
max_length=max_length,
# dataset_map_fn=alpaca_map_fn,
dataset_map_fn=None,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length,
use_varlen_attn=use_varlen_attn)
(五)微调实施
文件构造
经过上述的各个步骤后,微调用的目录结构如下:
./XTuner/
├── Shanghai_AI_Laboratory
│ └── internlm2-chat-1_8b -> /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b
│ ├── README.md
│ ├── config.json
│ ├── configuration.json
│ ├── configuration_internlm2.py
│ ├── generation_config.json
│ ├── model-00001-of-00002.safetensors
│ ├── model-00002-of-00002.safetensors
│ ├── model.safetensors.index.json
│ ├── modeling_internlm2.py
│ ├── special_tokens_map.json
│ ├── tokenization_internlm2.py
│ ├── tokenization_internlm2_fast.py
│ ├── tokenizer.model
│ └── tokenizer_config.json
├── datas
│ └── assistant.json
├── internlm2_chat_1_8b_qlora_alpaca_e3_copy.py
└── xtuner_generate_assistant.py
1. 执行微调
xtuner train 命令用于启动模型微调进程。该命令需要一个参数:CONFIG 用于指定微调配置文件。这里我们使用修改好的配置文件 internlm2_chat_1_8b_qlora_alpaca_e3_copy.py。
训练过程中产生的所有文件,包括日志、配置文件、检查点文件、微调后的模型等,默认保存在 work_dirs 目录下,我们也可以通过添加 --work-dir 指定特定的文件保存位置。
cd /root/InternLM/XTuner
xtuner train ./internlm2_chat_1_8b_qlora_alpaca_e3_copy.py
耗时近40分钟,微调完成,测试显示正常。
...
08/09 00:04:56 - mmengine - INFO - Iter(train) [ 10/384] lr: 1.8000e-04 eta: 1:04:16 time: 10.3112 data_time: 0.0164 memory: 5752 loss: 0.3297
08/09 00:06:09 - mmengine - INFO - Iter(train) [ 20/384] lr: 1.9977e-04 eta: 0:53:27 time: 7.3102 data_time: 0.0138 memory: 6279 loss: 0.3070 grad_norm: 0.2693
08/09 00:07:13 - mmengine - INFO - Iter(train) [ 30/384] lr: 1.9885e-04 eta: 0:47:17 time: 6.4287 data_time: 0.0086 memory: 6279 loss: 0.2618 grad_norm: 0.2693
...
08/09 00:41:30 - mmengine - INFO - Iter(train) [380/384] lr: 8.8660e-08 eta: 0:00:24 time: 5.8674 data_time: 0.0096 memory: 6279 loss: 0.0063 grad_norm: 0.0166
08/09 00:41:54 - mmengine - INFO - after_train_iter in EvaluateChatHook.
08/09 00:41:56 - mmengine - INFO - Sample output:
<s><|im_start|>system
Below is an instruction that describes a task. Write a response that appropriately completes the request.
<|im_end|>
<|im_start|>user
请介绍一下你自己<|im_end|>
<|im_start|>assistant
我是ydogg的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦<|im_end|>
08/09 00:41:58 - mmengine - INFO - Sample output:
<s><|im_start|>system
Below is an instruction that describes a task. Write a response that appropriately completes the request.
<|im_end|>
<|im_start|>user
Please introduce yourself<|im_end|>
<|im_start|>assistant
I am an AI developed by XiaoYiLing to assist you with your tasks. I am designed to be 3B大模型哦,内在是上海AI实验室书生·浦语的1.8B大模型哦<|im_end|>
08/09 00:41:59 - mmengine - INFO - Sample output:
<s><|im_start|>system
Below is an instruction that describes a task. Write a response that appropriately completes the request.
<|im_end|>
<|im_start|>user
你喜欢的小说是什么<|im_end|>
<|im_start|>assistant
我喜欢看天下霸唱写的鬼吹灯<|im_end|>
微调结果确认
目录下增加了work_dirs/internlm2_chat_1_8b_qlora_alpaca_e3_copy目录,这是微调的结果:模型权重文件。
.
├── Shanghai_AI_Laboratory
│ └── internlm2-chat-1_8b -> /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b
├── datas
│ └── assistant.json
├── internlm2_chat_1_8b_qlora_alpaca_e3_copy.py
├── work_dirs
│ └── internlm2_chat_1_8b_qlora_alpaca_e3_copy
│ ├── 20240809_000028
│ │ ├── 20240809_000028.log
│ │ └── vis_data
│ │ ├── 20240809_000028.json
│ │ ├── config.py
│ │ ├── eval_outputs_iter_383.txt
│ │ └── scalars.json
│ ├── internlm2_chat_1_8b_qlora_alpaca_e3_copy.py
│ ├── iter_384.pth
│ └── last_checkpoint
└── xtuner_generate_assistant.py
(六)模型格式转换
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 HuggingFace 格式文件,可以使用 xtuner convert pth_to_hf 命令来进行模型格式转换。xtuner convert pth_to_hf 命令用于进行模型格式转换。该命令需要三个参数:CONFIG 表示微调的配置文件, PATH_TO_PTH_MODEL 表示微调的模型权重文件路径,即要转换的模型权重, SAVE_PATH_TO_HF_MODEL 表示转换后的 HuggingFace 格式文件的保存路径。
其他额外参数:
| 参数名 | 解释 |
|---|---|
| –fp32 | 代表以fp32的精度开启,假如不输入则默认为fp16 |
| –max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
执行命令行
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
# 指定最后一个保存的pth文件( work_dirs/internlm2_chat_1_8b_qlora_alpaca_e3_copy/iter_384.pth)
xtuner convert pth_to_hf \
./internlm2_chat_1_8b_qlora_alpaca_e3_copy.py \
work_dirs/internlm2_chat_1_8b_qlora_alpaca_e3_copy/iter_384.pth ./hf
执行结果确认
转换完成后,在上述命令行下指定的hf目录下出现转换后的文件。
hf 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”,可以简单理解:LoRA 模型文件 = Adapter。
../XTuner/
├── Shanghai_AI_Laboratory
│ └── internlm2-chat-1_8b -> /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b
│ ├── README.md
│ ├── config.json
│ ├── configuration.json
│ ├── configuration_internlm2.py
│ ├── generation_config.json
│ ├── model-00001-of-00002.safetensors
│ ├── model-00002-of-00002.safetensors
│ ├── model.safetensors.index.json
│ ├── modeling_internlm2.py
│ ├── special_tokens_map.json
│ ├── tokenization_internlm2.py
│ ├── tokenization_internlm2_fast.py
│ ├── tokenizer.model
│ └── tokenizer_config.json
├── datas
│ └── assistant.json
├── hf
│ ├── README.md
│ ├── adapter_config.json
│ ├── adapter_model.bin
│ └── xtuner_config.py
├── internlm2_chat_1_8b_qlora_alpaca_e3_copy.py
├── work_dirs
│ └── internlm2_chat_1_8b_qlora_alpaca_e3_copy
│ ├── 20240809_000028
│ │ ├── 20240809_000028.log
│ │ └── vis_data
│ │ ├── 20240809_000028.json
│ │ ├── config.py
│ │ ├── eval_outputs_iter_383.txt
│ │ └── scalars.json
│ ├── internlm2_chat_1_8b_qlora_alpaca_e3_copy.py
│ ├── iter_384.pth
│ └── last_checkpoint
└── xtuner_generate_assistant.py
(七)模型合并
对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(Adapter),训练完的这个层最终还是要与原模型进行合并才能被正常的使用。XTuner 中提供了一键合并的命令 xtuner convert merge,在使用前我们需要准备好三个路径,包括原模型的路径、训练好的 Adapter 层的(模型格式转换后的)路径以及最终保存的路径。
xtuner convert merge命令用于合并模型。该命令需要三个参数:LLM 表示原模型路径,ADAPTER 表示 Adapter 层的路径, SAVE_PATH 表示合并后的模型最终的保存路径。
模型合并这一步还有其他很多的可选参数,包括:
| 参数名 | 解释 |
|---|---|
| –max-shard-size {GB} | 代表每个权重文件最大的大小(默认为2GB) |
| –device {device_name} | 这里指的就是device的名称,可选择的有cuda、cpu和auto,默认为cuda即使用gpu进行运算 |
| –is-clip | 这个参数主要用于确定模型是不是CLIP模型,假如是的话就要加上,不是就不需要添加 |
执行命令行
合并原模型+hf到merge目录下
cd /root/InternLM/XTuner
conda activate xtuner0121
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert merge /root/InternLM/XTuner/Shanghai_AI_Laboratory/internlm2-chat-1_8b ./hf ./merged --max-shard-size 2GB
执行结果确认
执行后的目录结构,可以看到新合并的模型文件merged和原有的internlm2-chat-1_8b模型构造非常相似。
../XTuner/
├── Shanghai_AI_Laboratory
│ └── internlm2-chat-1_8b -> /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b
│ ├── README.md
│ ├── config.json
│ ├── configuration.json
│ ├── configuration_internlm2.py
│ ├── generation_config.json
│ ├── model-00001-of-00002.safetensors
│ ├── model-00002-of-00002.safetensors
│ ├── model.safetensors.index.json
│ ├── modeling_internlm2.py
│ ├── special_tokens_map.json
│ ├── tokenization_internlm2.py
│ ├── tokenization_internlm2_fast.py
│ ├── tokenizer.model
│ └── tokenizer_config.json
├── datas
│ └── assistant.json
├── hf
...
├── internlm2_chat_1_8b_qlora_alpaca_e3_copy.py
├── merged
│ ├── config.json
│ ├── configuration_internlm2.py
│ ├── generation_config.json
│ ├── modeling_internlm2.py
│ ├── pytorch_model-00001-of-00002.bin
│ ├── pytorch_model-00002-of-00002.bin
│ ├── pytorch_model.bin.index.json
│ ├── special_tokens_map.json
│ ├── tokenization_internlm2.py
│ ├── tokenization_internlm2_fast.py
│ ├── tokenizer.json
│ ├── tokenizer.model
│ └── tokenizer_config.json
├── work_dirs
...
└── xtuner_generate_assistant.py
大小比较
du /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b merged -hs
3.6G /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b
3.6G merged
du /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b merged -hm
3605 /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b
3611 merged
因为这次微调的内容很少,所以微调后的模型和原来大小变化不大,只增加了6M左右。
(八)微调结果测试
修改/root/InternLM/Tutorial/tools/xtuner_streamlit_demo.py文件,将模型路径指向合并后的新模型merged(换模型运行)
#model_name_or_path = "/root/InternLM/XTuner/Shanghai_AI_Laboratory/internlm2-chat-1_8b"
model_name_or_path = "/root/InternLM/XTuner/merged"
运行测试
# 运行新模型
streamlit run /root/InternLM/Tutorial/tools/xtuner_streamlit_demo.py
# 开启端口转发
ssh -CNg -L 6606:127.0.0.1:8501 root@ssh.intern-ai.org.cn -p <ssh端口>
对比(微调后模型的回答)
非常精准的回答了问题,而且可以正确分析语义分解回答,说明微调成功增加了新知识!
对比微调前模型的回答,很明显是都是在模型固有的知识范畴内回答的。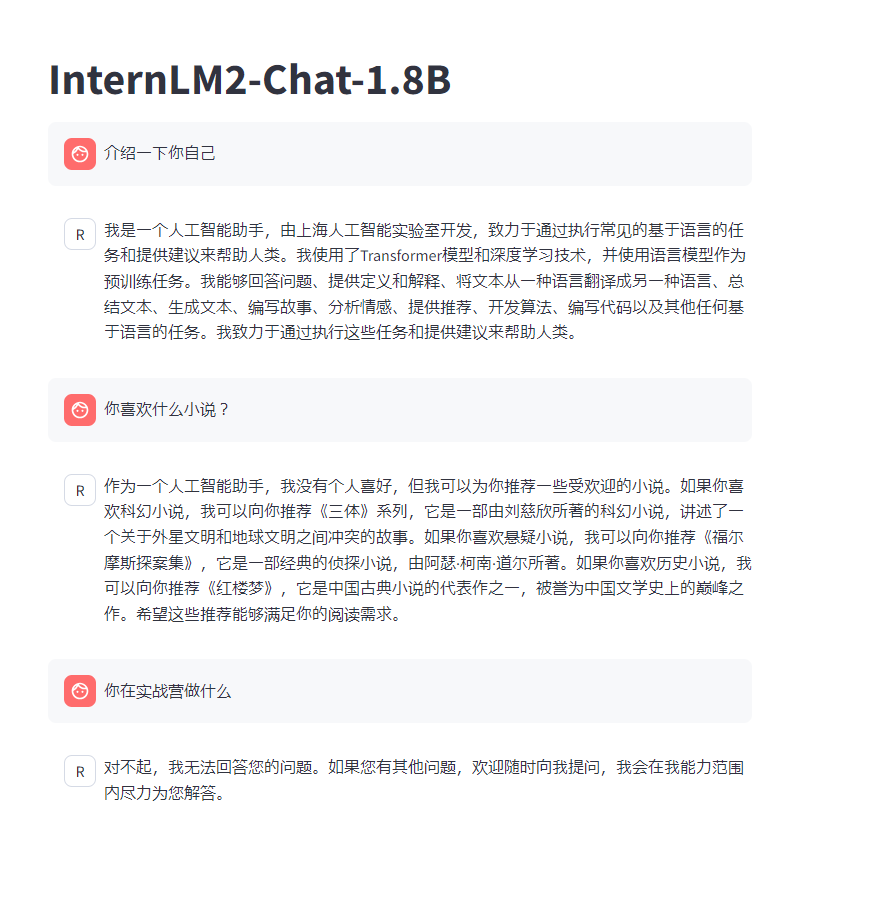















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









