







本文主要结合了两篇文章,并做了稍微的修改,原文出处:
1、http://blog.csdn.net/a819825294/article/details/51206410
2、https://zhuanlan.zhihu.com/p/28672955
1.xgboost vs gbdt
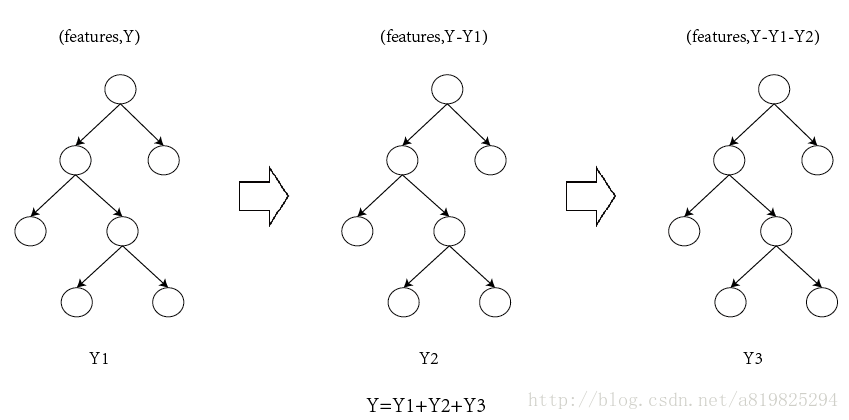
说到xgboost,不得不说gbdt,两者都是boosting方法(如图1所示),关于gbdt可以看我这篇文章 地址。
如果不考虑工程实现、解决问题上的一些差异,xgboost与gbdt比较大的不同就是目标函数的定义。
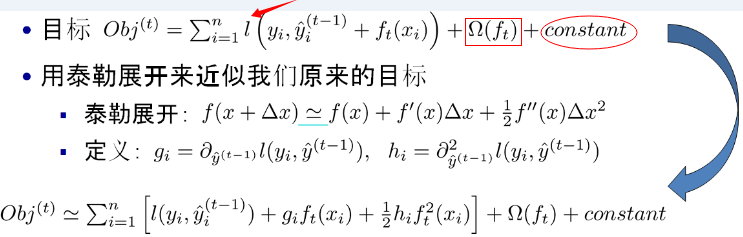
注:红色箭头指向的l即为损失函数;红色方框为正则项,包括L1、L2;红色圆圈为常数项。xgboost利用泰勒展开三项,做一个近似,我们可以很清晰地看到,最终的目标函数只依赖于每个数据点的在误差函数上的一阶导数和二阶导数。
2.原理
对于上面给出的目标函数,我们可以进一步化简
(1)定义树的复杂度
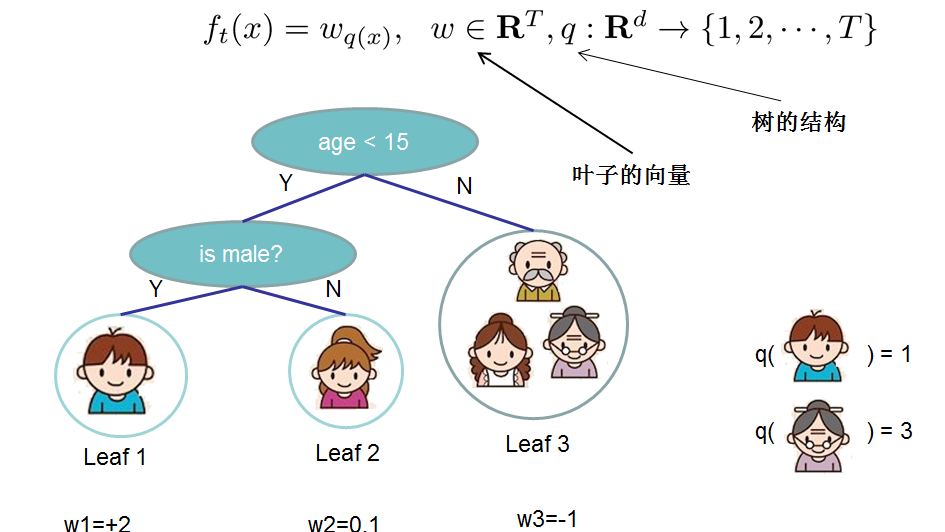
对于f的定义做一下细化,把树拆分成结构部分q和叶子权重部分w。下图是一个具体的例子。结构函数q把输入映射到叶子的索引号上面去,而w给定了每个索引号对应的叶子分数是什么。
定义这个复杂度包含了一棵树里面节点的个数,以及每个树叶子节点上面输出分数的L2模平方。当然这不是唯一的一种定义方式,不过这一定义方式学习出的树效果一般都比较不错。下图还给出了复杂度计算的一个例子。
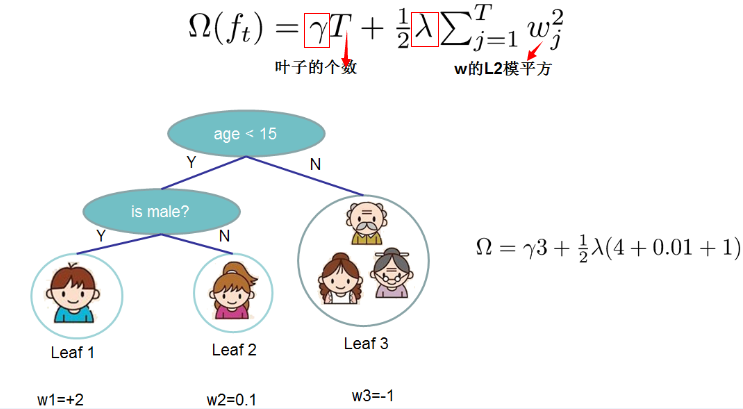
注:方框部分在最终的模型公式中控制这部分的比重,对应模型参数中的lambda ,gamma
在这种新的定义下,我们可以把目标函数进行如下改写,其中I被定义为每个叶子上面样本集合 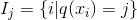
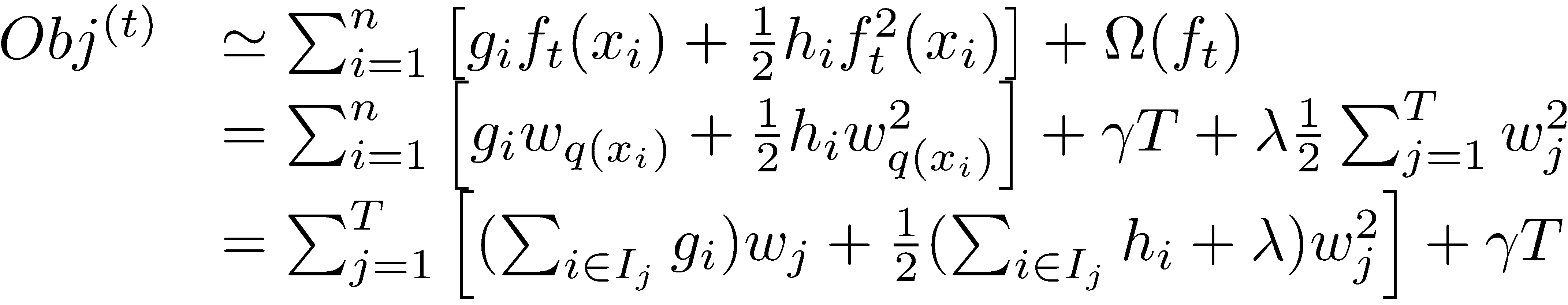
这一个目标包含了T个相互独立的单变量二次函数。我们可以定义
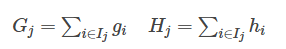
最终公式可以化简为
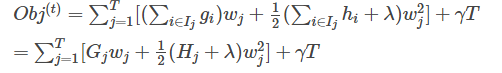
通过对
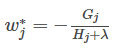
然后把
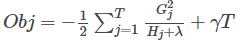
(2)打分函数计算示例
Obj代表了当我们指定一个树的结构的时候,我们在目标上面最多减少多少。我们可以把它叫做结构分数(structure score)
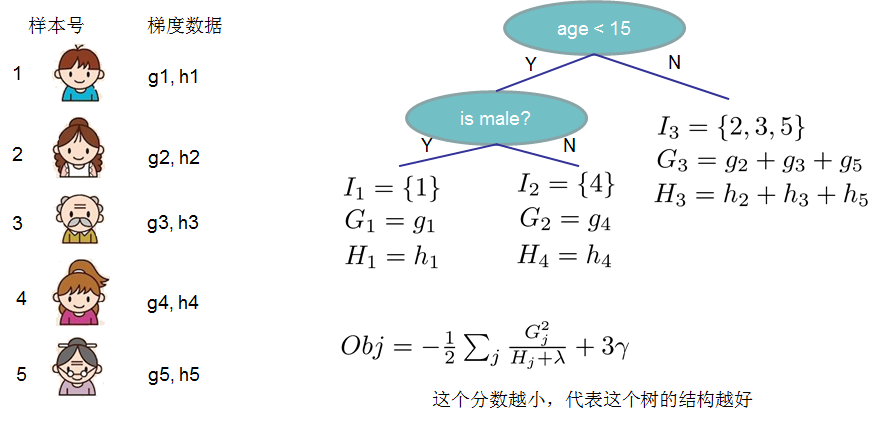
(3)分裂节点
论文中给出了两种分裂节点的方法
(1)贪心法:
每一次尝试去对已有的叶子加入一个分割
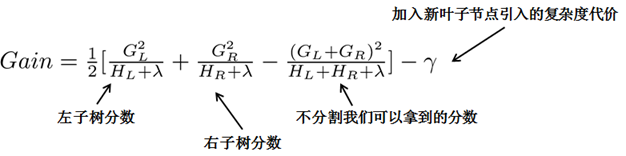
对于每次扩展,我们还是要枚举所有可能的分割方案,如何高效地枚举所有的分割呢?我假设我们要枚举所有x < a 这样的条件,对于某个特定的分割a我们要计算a左边和右边的导数和。
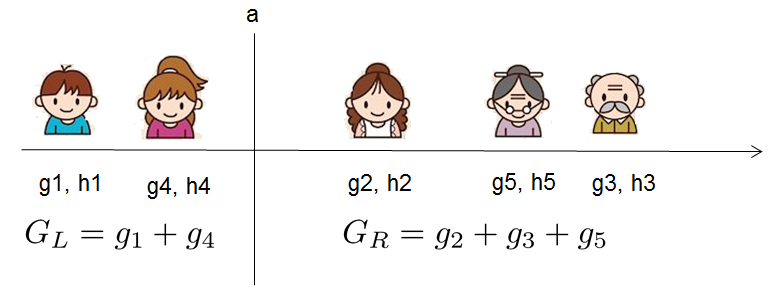
我们可以发现对于所有的a,我们只要做一遍从左到右的扫描就可以枚举出所有分割的梯度和GL和GR。然后用上面的公式计算每个分割方案的分数就可以了。
观察这个目标函数,大家会发现第二个值得注意的事情就是引入分割不一定会使得情况变好,因为我们有一个引入新叶子的惩罚项。优化这个目标对应了树的剪枝, 当引入的分割带来的增益小于一个阀值的时候,我们可以剪掉这个分割。大家可以发现,当我们正式地推导目标的时候,像计算分数和剪枝这样的策略都会自然地出现,而不再是一种因为heuristic(启发式)而进行的操作了。
下面是论文中的算法

(2)近似算法:
主要针对数据太大,不能直接进行计算

3.自定义损失函数(指定grad、hess)
(1)损失函数
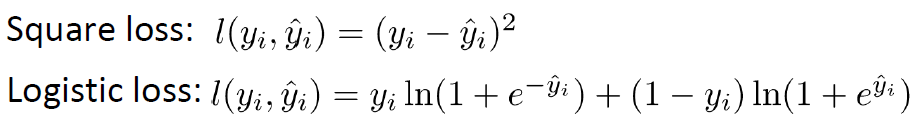
(2)grad、hess推导
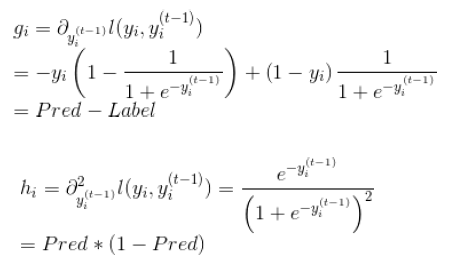
(3)官方例子:https://github.com/dmlc/xgboost/blob/master/demo/guide-python/custom_objective.py
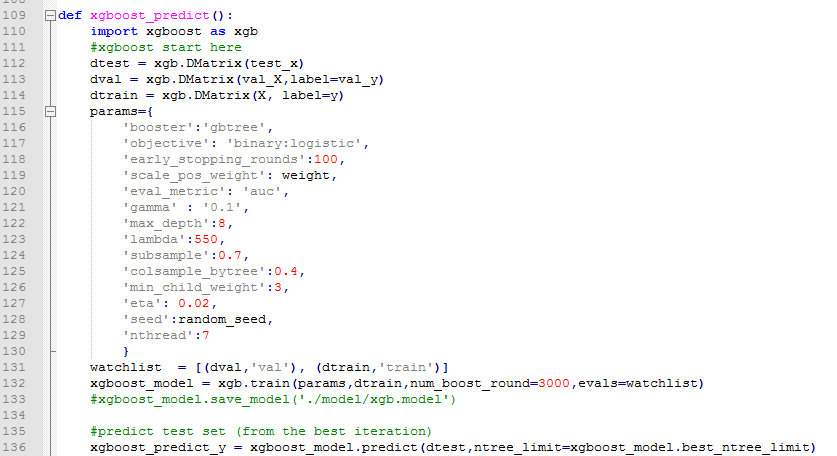
4.python、R对于xgboost的简单使用
任务:二分类,存在样本不均衡问题(scale_pos_weight可以一定程度上解读此问题)
【python】
【R】
5.xgboost中比较重要的参数介绍
5.1 XGBoost的参数主要分为三种:
- General Parameters: 控制总体的功能
- Booster Parameters: 控制单个学习器的属性
- Learning Task Parameters: 控制调优的步骤
5.2 XGBoost的参数详情
(1)General Parameters:
- booster [default=gbtree]
- 选择每一次迭代中,模型的种类. 有两个选择:
- gbtree: 基于树的模型
- gblinear: 线性模型
- silent [default=0]:
- 设为1 则不打印执行信息
- I设为0打印信息
- nthread [default to maximum number of threads available if not set]
- 这个是设置并发执行的信息,设置在几个核上并发
- 如果你希望在机器的所有可以用的核上并发执行,则采用默认的参数
(2)Booster Parameters
有2种booster,线性的和树的,一般树的booster较为常用。
- eta [default=0.3]
- 类似于GBM里面的学习率
- 通过在每一步中缩小权重来让模型更加鲁棒
- 一般常用的数值: 0.01-0.2
- min_child_weight [default=1]
- Defines the minimum sum of weights of all observations required in a child.
- Used to control over-fitting. Higher values prevent a model from learning relations which might be highly specific to the particular sample selected for a tree.
- 这个参数用来控制过拟合
- Too high values can lead to under-fitting hence, it should be tuned using CV.
- 如果数值太大可能会导致欠拟合
- max_depth [default=6]
- The maximum depth of a tree, same as GBM.
- 控制子树中样本数占总的样本数的最低比例
- 设置树的最大深度
- Used to control over-fitting as higher depth will allow model to learn relations very specific to a particular sample.
- 控制过拟合,如果树的深度太大会导致过拟合
- Should be tuned using CV.
- 应该使用CV来调节。
- Typical values: 3-10
- max_leaf_nodes
- The maximum number of terminal nodes or leaves in a tree.
- 叶子节点的最大值
- Can be defined in place of max_depth. Since binary trees are created, a depth of ‘n’ would produce a maximum of 2^n leaves.
- 也是为了通过树的规模来控制过拟合
- If this is defined, GBM will ignore max_depth.
- 如果叶子树确定了,对于2叉树来说高度也就定了,此时以叶子树确定的高度为准
- gamma [default=0]
- A node is split only when the resulting split gives a positive reduction in the loss function. Gamma specifies the minimum loss reduction required to make a split.
- 如果分裂能够使loss函数减小的值大于gamma,则这个节点才分裂。gamma设置了这个减小的最低阈值。如果gamma设置为0,表示只要使得loss函数减少,就分裂
- Makes the algorithm conservative. The values can vary depending on the loss function and should be tuned.
- 这个值会跟具体的loss函数相关,需要调节
- max_delta_step [default=0]
- In maximum delta step we allow each tree’s weight estimation to be. If the value is set to 0, it means there is no constraint. If it is set to a positive value, it can help making the update step more conservative.
- 如果参数设置为0,表示没有限制。如果设置为一个正值,会使得更新步更加谨慎。(关于这个参数我还是没有完全理解透彻。。。)
- Usually this parameter is not needed, but it might help in logistic regression when class is extremely imbalanced.
- 不是很经常用,但是在逻辑回归时候,使用它可以处理类别不平衡问题。
- subsample [default=1]
- Same as the subsample of GBM. Denotes the fraction of observations to be randomly samples for each tree.
- 对原数据集进行随机采样来构建单个树。这个参数代表了在构建树时候 对原数据集采样的百分比。eg:如果设为0.8表示随机抽取样本中80%的个体来构建树。
- Lower values make the algorithm more conservative and prevents overfitting but too small values might lead to under-fitting.
- 相对小点的数值可以防止过拟合,但是过小的数值会导致欠拟合(因为采样过小)。
- Typical values: 0.5-1
- 一般取值 0.5 到 1
- colsample_bytree [default=1]
- Similar to max_features in GBM. Denotes the fraction of columns to be randomly samples for each tree.
- 创建树的时候,从所有的列中选取的比例。e.g:如果设为0.8表示随机抽取80%的列 用来创建树
- Typical values: 0.5-1
- colsample_bylevel [default=1]
- Denotes the subsample ratio of columns for each split, in each level.
- I don’t use this often because subsample and colsample_bytree will do the job for you. but you can explore further if you feel so.
- lambda [default=1]
- L2 regularization term on weights (analogous to Ridge regression)
- L2正则项,类似于Ridge Regression
- This used to handle the regularization part of XGBoost. Though many data scientists don’t use it often, it should be explored to reduce overfitting.
- 可以用来考虑降低过拟合,L2本身可以防止过分看重某个特定的特征。尽量考虑尽量多的特征纳入模型。
- alpha [default=0]
- L1 regularization term on weight (analogous to Lasso regression)
- L1正则。 类似于lasso
- Can be used in case of very high dimensionality so that the algorithm runs faster when implemented
- L1正则有助于产生稀疏的数据,这样有助于提升计算的速度
- scale_pos_weight [default=1]
- A value greater than 0 should be used in case of high class imbalance as it helps in faster convergence.
(3)Learning Task Parameters
These parameters are used to define the optimization objective the metric to be calculated at each step.
- objective [default=reg:linear]
- This defines the loss function to be minimized. Mostly used values are:
- binary:logistic –logistic regression for binary classification, returns predicted probability (not class)
- multi:softmax –multiclass classification using the softmax objective, returns predicted class (not probabilities)
- you also need to set an additional num_class (number of classes) parameter defining the number of unique classes
- multi:softprob –same as softmax, but returns predicted probability of each data point belonging to each class.
- eval_metric [ default according to objective ]
- The metric to be used for validation data.
- The default values are rmse for regression and error for classification.
- 对于回归问题默认采用rmse,对于分类问题一般采用error
- Typical values are:
- rmse – root mean square error
- mae – mean absolute error
- logloss – negative log-likelihood
- error – Binary classification error rate (0.5 threshold)
- merror – Multiclass classification error rate
- mlogloss – Multiclass logloss
- auc: Area under the curve
- seed [default=0]
- The random number seed.
- Can be used for generating reproducible results and also for parameter tuning.
- 为了产生能过重现的结果。因为如果不设置这个种子,每次产生的结果都会不同。
6.Xgboost调参
由于xgboost的参数过多,这里介绍三种思路
(1)GridSearch
(2)Hyperopt
(3)老外写的一篇文章,操作性比较强,推荐学习一下。地址
7.Tip
(1)含有缺失进行训练
dtrain = xgb.DMatrix(x_train, y_train, missing=np.nan)
8.参考文献
(1)xgboost导读和实战
(2)xgboost
(3)自定义目标函数
(4)机器学习算法中GBDT和XGBOOST的区别有哪些?
(5)https://www.kaggle.com/anokas/sparse-xgboost-starter-2-26857/code/code
(6)XGBoost: Reliable Large-scale Tree Boosting System
(7)XGBoost: A Scalable Tree Boosting System














 1261
1261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









