







上一篇详细的介绍了python的几个有深度的知识点,本篇我想再升华到一个高度,python开发中到底要遵守哪些原则。
1 可读性:
我把可读性放在python原则第一位,是因为python太大的灵活性,导致了每个人的代码风格天马行空。像Java那种语言规定的很严谨,虽然代码相对较长,但是通过变量定义、函数出入参、接口类型等都可以猜得出代码要做什么。但是python却不一样,不review玩全部代码根本没把握知道函数或类到底要达到什么目的。所以在编写代码时尽量用一些别人看得懂的写法。
例如list[::-1]和reversed(list)虽然都可以让list倒转,但是明显后者的可读性要好得多。你可能说前者的代码更简洁,但是我们要追求的简洁是从函数设计层面来说的,而不是牺牲可读性的细节层面上。
2 尽量用函数思想去编程
例如:
def numSwitch(x) :
return{
0 : 'value is 0',
1 : 'value is 1',
2 : 'value is 2'
}.get(x,'No match x value')
if __name__ == '__main__':
print(numSwitch(2))
print(numSwitch(4))
尽量不要用if elsif elsif else这样去写,会让可读性变很差,维护性和扩展性也不好。
3 注解注解注解,重要的事情说3遍。
虽然所有语言的代码都需要注解,但是python我认为更需要注解,因为它太灵活了,谁知道你的函数里添加或者删除了什么新的变量,Java看一眼接口方法和出入参能明白里面在干什么,但是python做不到,没有注解的话需要别人review完一遍你的代码才能搞明白在干啥。
做了10年的开发,我理想中的最好的代码就是只看注解就能明白代码。所以在某种程度上来讲,注解比代码本身还要重要。
4尽量用import a,有节制的用from a import A,不要用from a import *
Python的内存中维护着一批内建模块,存放在sys.modules中。
from a会让a保存到sys.modules中,这样会造成相互干扰和污染,例如a和b中都有functionA这样会让调用者对functionA的使用带来困扰,到底用的哪一个。
当然直接import a也有缺点,要想使用a中的functionA时每次都要a.functionA这样来使用。
5 降低算法的复杂度
算法的复杂度主要从时间复杂度和空间复杂度两个维度来衡量,我前面有篇介绍八大排序算法的博文中有详细介绍过复杂度的问题《排序算法的详解与总结》
我们来看下复杂度之间的大小关系:
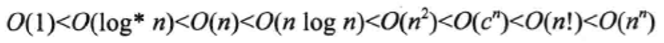
你可能说将,难道我没写一行代码或者算法,我都要计算下它的复杂度然后再去想下有没有更好的算法,那每天都不要干活了。是的,这样确实烧脑而且影响开发效率,所以我给出的建议是,当代码中涉及到
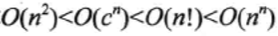
这几层复杂度时需要考虑下优化的问题,其它的情况可以忽略,优化效果不明显。
既然谈到优化,我们就需要掌握一些计算程序执行速率的小技巧。
运行时间分析推荐使用time.time()、cProfile、pstats,其中前者用在简单的小模块代码监控,后两者用于深层次的全面的分析。
代码如下:
def foo(num):
x = 0
for i in range(num):
x += i**2
return x
if __name__ == '__main__' :
import cProfile
cProfile.run('print(foo(10000))',filename='C:\\python\\tmp\\report.txt',sort='tottime')
import pstats
p = pstats.Stats('C:\\python\\tmp\\report.txt')
p.sort_stats('tottime').print_stats()
import time
t1 = time.time()
foo(10000)
print('time wast : %f' %(time.time()-t1))
输出如下:
5 function calls in 0.004 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.004 0.004 0.004 0.004 C:/python/work/smart/pyart/yieldtest.py:1(foo)
1 0.000 0.000 0.004 0.004 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {built-in method builtins.print}
1 0.000 0.000 0.004 0.004 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
0.0040225982666015625
一般只用cProfile也可以,其中输出文件地址和排序是可选的;pstats比cProfile分析的更全面。
6 做好单元测试
单元测试在我眼里有两点作用,第一,可以保证程序的可用性,这一点不需要解释,是单元测试的根本目的;第二,可以作为程序的另一种API,好的单元测试可以引导调用者如何来使用你的程序。
Python自带的单元测试模块是unittest,使用起来很简单,我们从浅入深来了解它。
Unittest最重要的是TestCase,每一个最简单验证单元被称为一个case;
执行测试的对象叫TestRunner,它相当于一个容器,来加载和执行测试任务;
TestSuite可以把多个case组装起来形成一个相对较复杂的测试用例。
了解了TestCase、TestRunner、TestSuite的定义和关系,我们来看下我的案例。
我的目录结构是这个样子的:
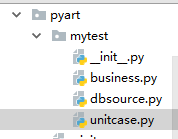
business.py里是我的业务逻辑,里面是个业务类以及testcase
dbsource.py里是我的数据库交互逻辑,里面是几个函数以及testcase
unitcase.py里是我想整合业务与数据编排更复杂的测试。
business.py代码如下:
import unittest
class Business(object):
def __init__(self,x,y):
self.x = x
self.y = y
def sum(self):
return self.x+self.y
def mult(self):
return self.x * self.y
class BuninessTest(unittest.TestCase):
# 实体级的预处理
@classmethod
def setUpClass(cls):
print('Invoke setup class function')
# 实体级的结束回收
@classmethod
def tearDownClass(cls):
print('Invoke tearDown class function')
#函数级的预处理
def setUp(self):
print('Invoke setup function')
self.business = Business(2,3)
#函数级的结束回收
def tearDown(self):
print('Invoke tearDown function')
self.business = None
def test_1_sum(self):
print('Invoke test_sum function')
self.assertEqual(5,self.business.sum())
def test_2_mult(self):
print('Invoke test_mult function')
self.assertEqual(6, self.business.mult())
if __name__ == '__main__':
unittest.main()测试用例类必须继承Testcase;setUp()和tearDown()是非必需的,如果自己实现了就是覆盖了父类中的函数,这两个函数在每个测试方法执行前后被调用;setUpClass()和tearDownClass()也是非必需的,在每个测试实体执行前后被调用;所有的测试用例方法必须以test开头,我之所以给他们加了数字是因为如果不经过编排它们的执行顺序是按照函数名称的大小从小到大来执行的,也就说通过添加数字我想控制它们的默认的执行顺序。
如果还不是很清楚,对照着单独执行business.py的输出结果:
Ran 2 tests in 0.002s
OK
Invoke setup class functionInvoke setup function
Invoke test_sum function
Invoke tearDown function
Invoke setup function
Invoke test_mult function
Invoke tearDown function
Invoke tearDown class function
dbsource.py代码如下:
import unittest
class DBManager(object):
pass
#连接数据库
def connect():
print('DB connected')
return True
#关闭数据库
def drop():
print('DB droped')
manager = None
return True
class DBmanagerTest(unittest.TestCase):
def test_1_connect(self):
print('Invoke test_connect function')
self.assertEqual(True,connect())
def test_2_drop(self):
print('Invoke test_drop function')
self.assertEqual(True, drop())
if __name__ == '__main__':
unittest.main()对比business来说简单多了,不再做详细说明,我这里只是为了演示单元测试可以测类中的方法,也可以直接测函数。
unitcase.py代码如下:
import unittest
import pyart.mytest.business as business
import pyart.mytest.dbsource as dbsource
if __name__ == '__main__':
suite = unittest.TestSuite()
suite.addTest(dbsource.DBmanagerTest('test_1_connect'))
suite.addTest(business.BuninessTest('test_2_mult'))
suite.addTest(business.BuninessTest('test_1_sum'))
suite.addTest(dbsource.DBmanagerTest('test_2_drop'))
with open('C:\\python\\tmp\\UnittestTextReport.txt', 'a') as f:
runner = unittest.TextTestRunner(stream=f, verbosity=2)
runner.run(suite)
#unittest.TextTestRunner().run(suite)
unitcase.py中对前面两个模块里的testcase做了集成,并且将测试结果输出到文件中,verbosity代表着case一旦不通过堆栈等内容的详细程度,默认为1,0最简单,2最详细。
当然本地调测可以用最后注释的那一行,不一定非要输出到文件中。
结果如下:
Invoke test_connect function
DB connected
Invoke setup class function
Invoke setup function
Invoke test_mult function
Invoke tearDown function
Invoke setup function
Invoke test_sum function
Invoke tearDown function
Invoke tearDown class function
Invoke test_drop function
DB droped除开unittest模块,我们还可以通过pip安装一个叫nose的测试组件

nose可以在指定的目录下遍历test开头的模块,自动执行里面的test开发的函数,我们可以将模块或者子包里的unittest测试与nose结合起来,就组成了更大目录的直到全项目的自动测试了。
例如我对unitcase.py做如下改动:
先把模块名改成test.py
再把里面单元测试的内容封装在一个test开头的函数内,代码如下:
import unittest
import pyart.mytest.business as business
import pyart.mytest.dbsource as dbsource
def testfunction():
suite = unittest.TestSuite()
suite.addTest(dbsource.DBmanagerTest('test_1_connect'))
suite.addTest(business.BuninessTest('test_2_mult'))
suite.addTest(business.BuninessTest('test_1_sum'))
suite.addTest(dbsource.DBmanagerTest('test_2_drop'))
unittest.TextTestRunner().run(suite)
if __name__ == '__main__':
testfunction()
这样我就可以用nose来测试该package了:
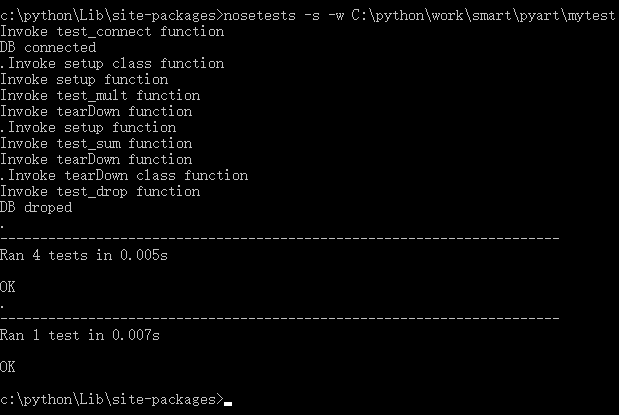
设想如果我规定项目中所有package都按照此要求来开发,那么我可以直接node我整个项目做全内容的单元测试了。
7 借助风格检查工具
一个项目同一个team最好是规定一种写作风格,我推荐使用pep8
安装:pip install –U pep8
检索风格错误:pep8 –first optparse.py
详细检索,甚至可以给出修改意见:pep8 –show-source –show-pep8 testsuite/E40.py
类似的还有Pyflakes、Pylint等,自己可以去了解下。
8 纠结
原则基本总结那么多吧,我对python的了解目前也只有这么些,以后持续努力。不过在写python的过程中也有很纠结的时候,例如我们要计算对从1到100求和。
一般我们会这么写:
def mySum1(n) :
sum = 0
for i in range(n):
sum += i
return sum
但是如果1到1亿呢?是不是这样写执行效率更高:
def mySum2(n) :
return (n * (n + 1) / 2)
但这就涉及到一个性能与可读性的取舍问题,我也不知道哪种写法更好,可能给第二种加上注释更好一些吧。
作为python之美的Ending,我最后说一点python的不足吧。
第一:版本迭代对语法冲击很大,作为开发人员不仅需要知识上的更新,还需要对现有代码进行改造。
第二:CPU密集型高并发支撑能力太差了,虽然有多进程但是进程数太可怜了,而且进程往往没有线程来的快,这方面一直被Java碾压。
可能python还是太年轻了吧,目前只到第三个版本,Java也是到了JDK1.4才出露锋芒,5.0开始大放异彩,相信再给它点时间,它能带给我们更多的惊喜。















 1912
1912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









